
- 주소공간이 더 커지면 페이지 테이블을 2단계가 아닌 그 이상의 단계로도 쓸 수 있다.
- 하지만 페이지 테이블이 여러개 만들어지면 주소변환을 위해 메모리에 여러번 접근해야 한다. 시간 오버헤드가 걸릴 수 있다.
- 그러나 대부분의 주소변환이 TLB에 있는 캐싱 정보를 통해 직접 이루어지므로 시간이 지나치게 오래걸리지 않는다.
- 위의 식은 TLB를 사용하면 그 시간이 얼마 걸리지 않음을 나타낸다. 2퍼센트는 TLB가 안되고 98퍼센트는 TLB가 된다. 결과적으로 주소변환을 위해 28ns만 소요된다.
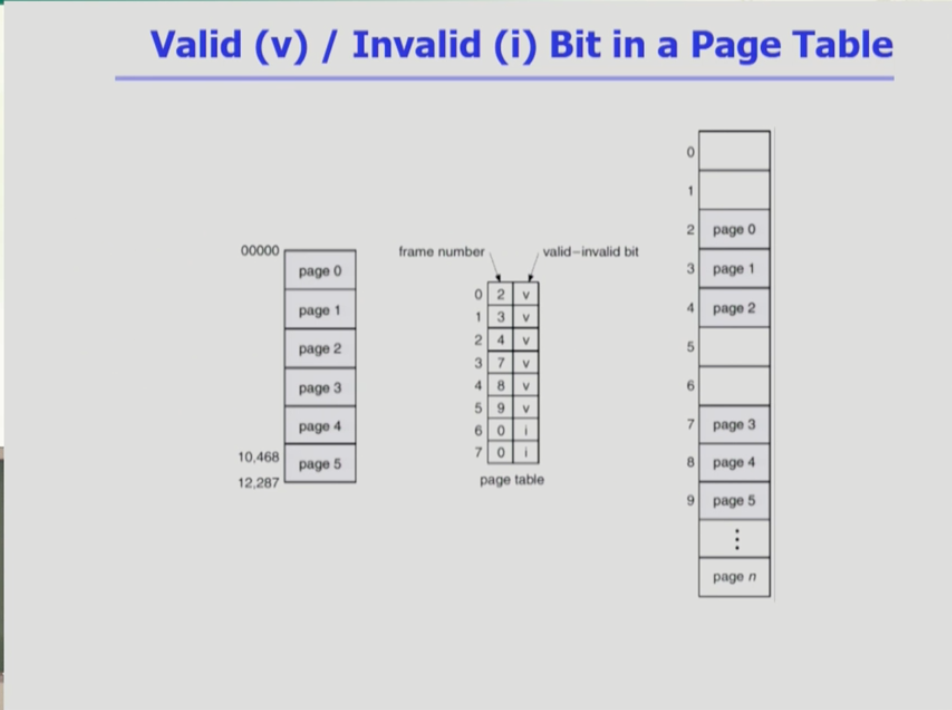
- 프로그램마다 주어지는 로지컬 메모리가 왼쪽, 가운데는 페이지 테이블, 오른쪽은 피지컬 메모리다. 페이지 테이블에는 Valid(v)/invalid(i) 정보가 적혀 있다. v로 적힌 엔트리는 메모리에 올라와 현재 사용되는 영역, i로 적힌 사용되지만 메모리에 올라와있지 않고 swap area(백킹 스토어)에 있는 경우, 엔트리는 존재하지만 사용되지 않는 영역을 의미한다. 프로그램이 가진 주소공간 만큼 페이지 테이블이 존재하기 때문에 사용하지 않는 영역도 엔트리가 만들어지는데, 이를 표시하기 위해서다.

- 위에 설명한 내용과 같다

- 또 프로텍션 비트라는 것이 존재한다. 어떤 페이지에 대한 접근 권한을 표시하는 비트다. 코드는 내용이 바뀌면 안되므로 read only, 데이터나 스택 영역은 중간에 데이터 업데이트가 가능하므로 read/write 권한을 모두 준다.

- 인버티드 페이지 테이블은 페이지 테이블의 공간 오버헤드를 막고자한 것이다
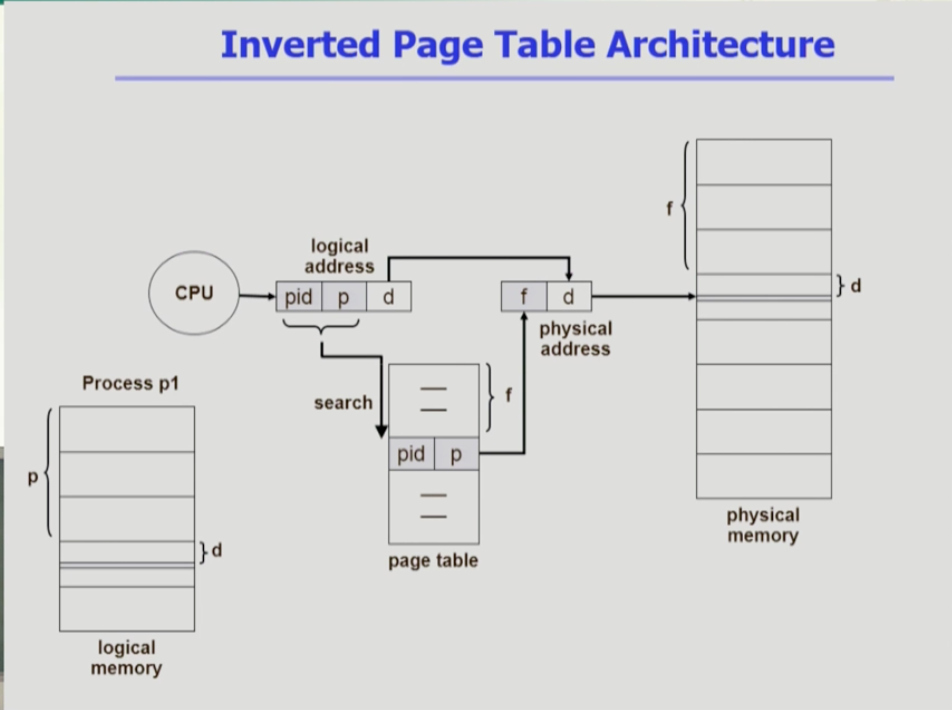
- 원래는 페이지 테이블이 프로세스마다 존재했지만, 인버티드 페이지 테이블은 시스템에 페이지 테이블이 하나 존재한다. 페이지 테이블의 엔트리가 프로세스가 아닌 물리적 메모리의 페이지 프레임 갯수만큼 존재한다. 이곳에서는 이전과 반대로 피지컬 엔트리를 보고 이에 따라 논리적 메모리를 찾는다. 페이지 테이블의 엔트리를 전부 검색해야만 찾을 수 있다. 시스템의 공간을 줄이기 위한 것인데 반대로 시간의 오버헤드가 든다.
- 또 논리적 페이지 번호뿐이 아닌, 어떤 프로세스의 p번째 페이지인지, 프로세스의 id(pid)까지 페이지 테이블에 같이 저장해야 한다.

- 다른 프로세스와 공유할 수 있는 페이지가 있다.
- 프로세스끼리 같은 목적으로 공유할 수 있는 코드를 shared code(=pure code=re-entrant code)라 부른다.
- read-only로 하여 프로세스 간에 하나의 물리적 메모리 code만 올린다.
- shared code는 모든 프로세스의 동일한 논리적 주소에 위치해야 한다.
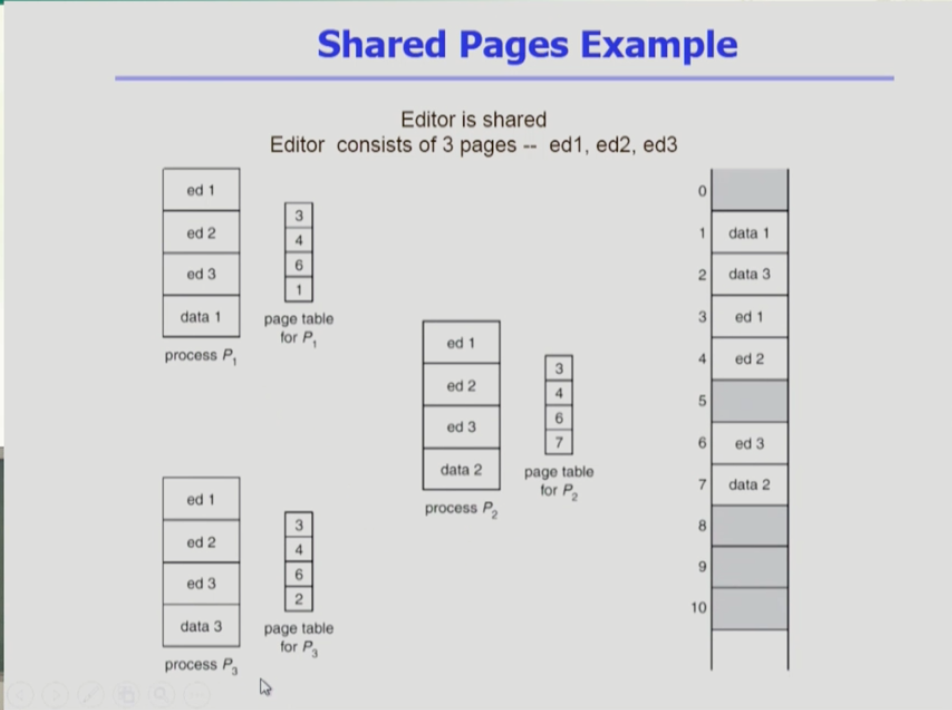
- 프로세스 1,2,3이 있다. 세 프로세스 모두 같은 내용을 실행하는 것이라면 프로그램의 코드는 공유하고 나머지 데이터 부분만 따로 저장하면 된다.
- 그림의 세 프로세스 모두 3,4,6 프레임으로 매핑되어 있다. 공유할 수 있는 코드를 같은 프레임에 1 copy만 매핑해 올린다.
- 프로세스 3개에서 shared code에 해당하는 페이지 ed1,ed2,ed3이 동일한 논리적 주소(같은 순서(1페이지:ed1,2페이지:ed2,3페이지:ed3))을 갖고 있다. 물리적 주소 또한 당연히 같다(3,4,6)

- 세그멘테이션 기법은 프로세스를 구성하는 주소공간을 의미 단위로 자른 것이다.

- 세그멘테이션 기법에서 주소변환은 페이징 기법과 비슷하게, 세그먼트 넘버와 세그먼트 안에서 얼마나 떨어졌는지를 나타내는 offset이 있다.
- 또 세그먼트의 주소변환을 위한 세그먼트 테이블을 사용하며, 주소변환 용도의 레지스터는 세그먼트 테이블 위치를 나타내는 STBR과 프로그램이 사용하는 세그먼트 갯수를 나타내는 STLR을 사용한다.
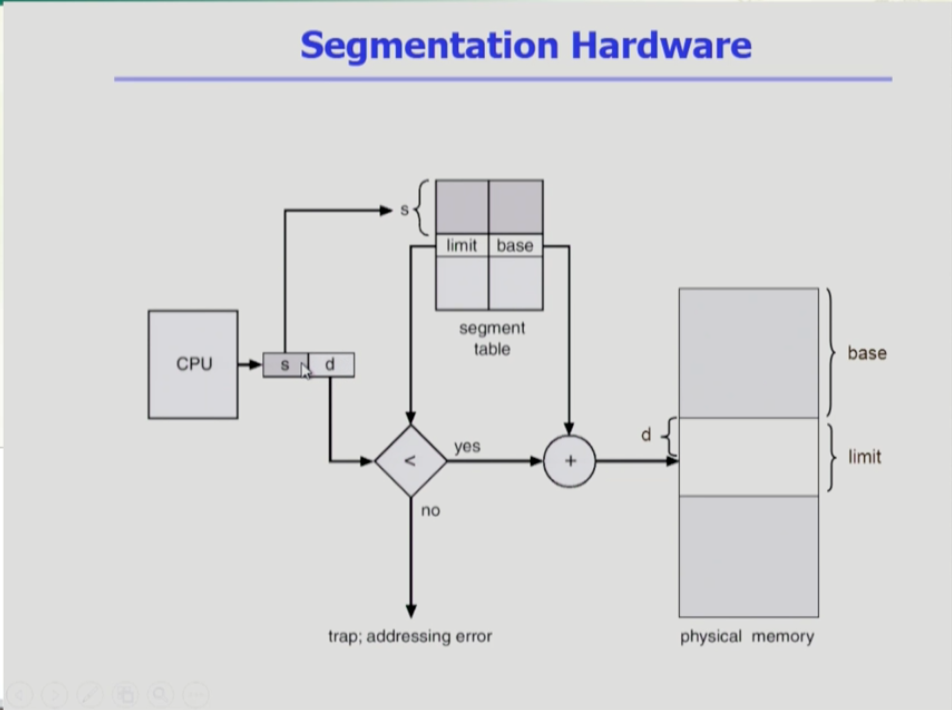
- CPU가 논리주소를 주면 이를 세그먼트 넘버와 오프셋으로 나눈다. 세그먼트 테이블이 물리적 메모리를 매핑해주는데, 세그먼트 테이블은 페이징과 다른 정보를 갖는다.
- 페이징과 달리 세그먼트의 길이는 일정하지 않으므로 세그먼트의 길이를 나타내는 limit정보를 테이블 엔트리에 유지한다. 또 base정보는 세그먼트의 시작 정보이다.
- 논리적인 세그먼트 넘버가 STLR보다 작은 지를 확인하고, 주소변환시 세그먼트의 길이보다 오프셋의 값이 작은지를 확인해야 한다.

- 세그멘테이션 기법은 메모리 크기가 일정하지 않아 퍼스트핏과 베스트핏만을 사용해야 하고 외부조각이 발생하는 문제가 있다.
- 반면 장점은 의미 단위로 권한을 부여하는 등의 일을 할 때(코드는 read-only,데이터/스택은 read/write...) 세그멘테이션이 효과적이다. 이는 페이징 기법에서는 힘들다.

하마드