
- 버츄얼 메모리에 대해 알아보겠다.

- 버츄얼 메모리 기법은 전적으로 운영체제가 관리한다.
- 디멘드 페이징은 요청이 있으면 페이지를 메모리에 올리는 것이다.
- 이 경우 필요한 것만 메모리에 올리므로 i/o 양이 상당히 줄어들고, 메모리 사용량이 감소하며, 응답 시간이 빠르고, 더 많은 사용자 수용이 가능하다.
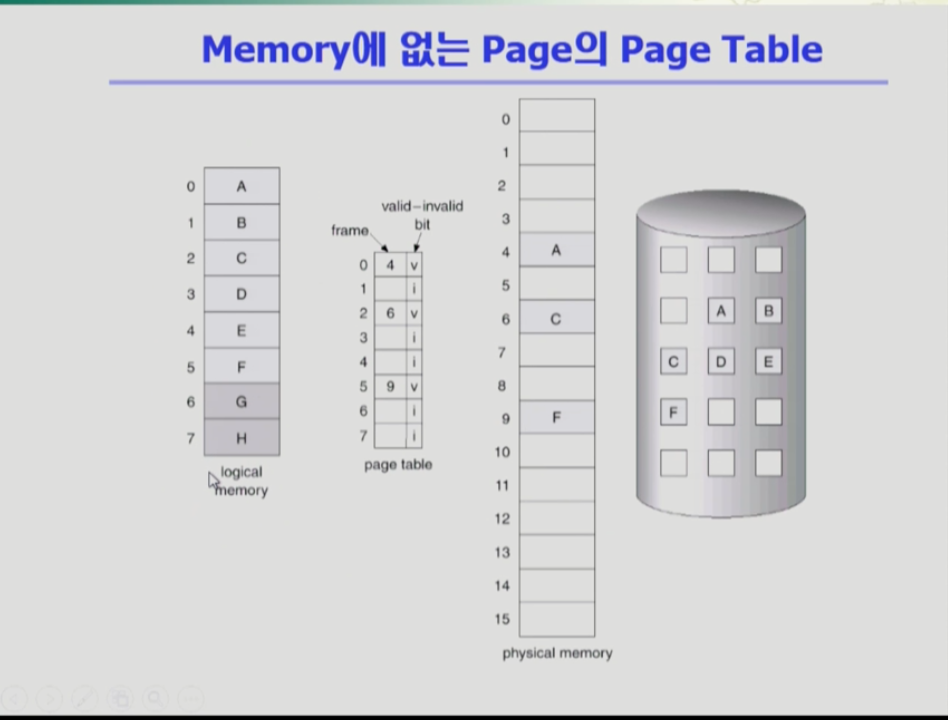
- 다음 프로그램은 여러개의 페이지와 페이지 테이블을 통해 주소변환 정보를 담고, 물리적 메모리가 있다. 여기에 추가로 맨 오른쪽에 백킹 스토어, 즉 스왑 에리어가 있다. 당장 필요한 부분은 물리적 메모리에 필요없는 부분은 스왑 에리어에 있다.
- 따라서 valid,invalid bit의 의미는 페이지가 물리적 메모리에 올라오면 valid, 사용하지 않거나 백킹 스토어에 내려가 있으면 invalid다.
- cpu가 페이지 주소변환을 하려고 봤더니 invalid인 경우, 페이지를 메모리로 올려야 하는데 이때 page fault를 발생 시켜 cpu를 운영체제로 넘긴다. 운영체제가 해당 페이지를 메모리로 올려준다.

- 페이지 폴트의 과정이다. 인밸리드 페이지를 접근하면 주소변환 하드웨어가 트랩을 발생시켜 cpu를 운영체제에 넘기고, 운영체제의 페이지 폴트 핸들러가 실행된다.
- 페이지 폴트 처리는 잘못된 요청인지를 판단하고, 물리적 디스크의 빈 페이지 공간을 획득하고 없으면 이미 있는 페이지를 쫓아낸다.
- 해당 페이지를 디스크에서 메모리로 읽어오는데, 이는 매우 느린 작업이므로 cpu를 해당 프로세스가 아닌 당장 사용할수 있는 프로세스에게 넘기고 현재 프로세스는 block을 건다. disk i/o가 끝나면 해당 프레임 번호를 페이지 테이블 엔트리에 적고 해당 페이지를 valid로 바꾸고 block된 프로세스가 cpu를 잡아 메모리 주소변환을 한다.

- 위의 과정을 그림으로 그린 예시다.

- 페이지 폴트는 매우 오래 걸리는 작업이므로 페이지 폴트가 얼마나 나느냐에 따라 디스크 접근시간이 바뀔 수 있다.
- (1-p)는 페이지 폴트가 안 나는 시간이다. 이 시간은 메모리 접근시간만 걸리고, p(페이지 폴트가 나는 시간)은 위 빨간 글씨와 같이 수많은 과정이 걸린다.

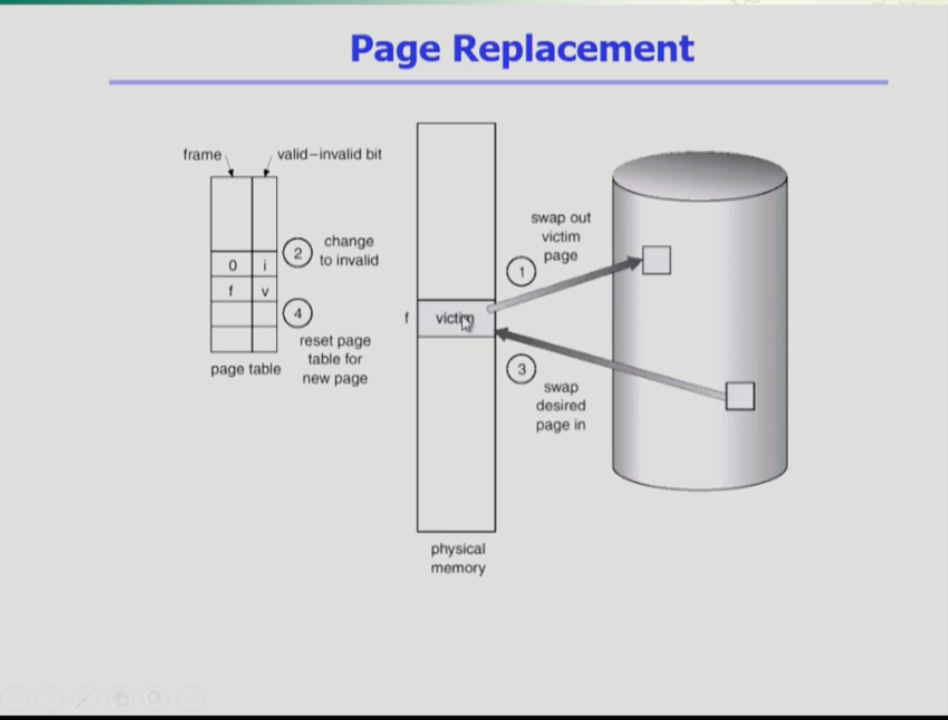
- 빈 물리적 메모리 공간이 없을 때 기존 페이지중 어떤 것을 쫒아내고 공간을 확보할지 결정하는 것을 page replacement라 한다.
- page replacement를 수행하는 알고리즘이 replacement 알고리즘이다. 이 알고리즘은 가능하면 페이지 폴트가 나지 않도록 하는것이 좋다.
- reference string은 페이지들이 참조된 순서가 나열된 것이다.
- page replacement순서를 나타낸 그림이다.
- 어떤 것을 쫓아낼지(victim)을 결정하는 것이 중요한데, 만약 victim이 디스크에서 메모리로 내려간 이후에 페이지의 내용이 변경되면 변경 내용을 백킹 스토어에 써줘야 한다.

- 알고리즘에서 페이지 폴트를 가장 적게 내는 알고리즘을 optimal 알고리즘이라 한다. 옵티멀 알고리즘은 미래에 참조되는 페이지들을 모두다 안다고 가정하는 것이다(Offrine 알고리즘).
- 옵티멀 알고리즘은 가장 먼 미래에 참조되는 페이지를 쫓아낸다. 그림과 같은 경우 5번이 들어가려 할 때 메모리가 꽉차있어 하나를 쫓아내야 한다. 이 때 4번이 현재에서 맨 마지막에 참조되므로 4번을 쫓아내고 그 자리에 5번을 넣는다.
- 이는 실제로 사용할 수 없는 알고리즘(Offrine)이지만 다른 알고리즘의 성능을 측정하는 최대치(upper bound)로 쓴다. 옵티멀의 성능과 얼마나 가까운지를 보는 것이다.

- 실제 시스템에서 사용하는, 미래를 모른다고 가정할 때의 알고리즘이다. 미래를 모를 때 참고할 만한 중요한 단서는 과거다.
- FIFO알고리즘은 먼저 들어온 페이지를 먼저 쫓아내는 방식이다. 그림에서 4가 들어올 때 먼저 들어온 1이 나가는 것을 확인할 수 있다.
- FIFO알고리즘은 메모리 크기를 늘려도 성능이 나빠지는, 페이지 폴트가 더 나는 현상이 발생한다. 이를 FIFO Anomaly라 한다.

- 가장 많이 사용되는 알고리즘은 LRU알고리즘이다. 이는 가장 덜 최근에 사용된 페이지를 쫓아내는 알고리즘이다.
- 위 그림에서 5가 들어갈때 3이 제일 오래 전에 참조됐으므로 3이 쫓겨난다.

- LFU 알고리즘은 가장 덜 참조된 페이지를 쫓아내는 알고리즘이다.
- 만약 덜 참조된 페이지가 여러개 있을 경우 임의로 하나로 결정하는데, 마지막 참조 시점이 오래된 페이지를 사용할 수도 있다.

- LRU와 LFU의 장단점이 있다.
- 레퍼런스 스트링이 참조되는 순서를 나타내고 오른쪽은 각 페이지가 참조된 시기를 보여준다.
- 현재 5번이 참조되어야 하는 상황에서 LRU는 1번을 삭제(가장 오래전 참조), LFU는 4번을 삭제(가장 덜 참조)한다.
- LRU는 한 시점만 보므로 이전의 기록을 고려하지 않는 것이 단점이다. 반대로 LFU는 횟수만을 보므로 미래의 상황을 고려하지 않는다는 단점이 있다.
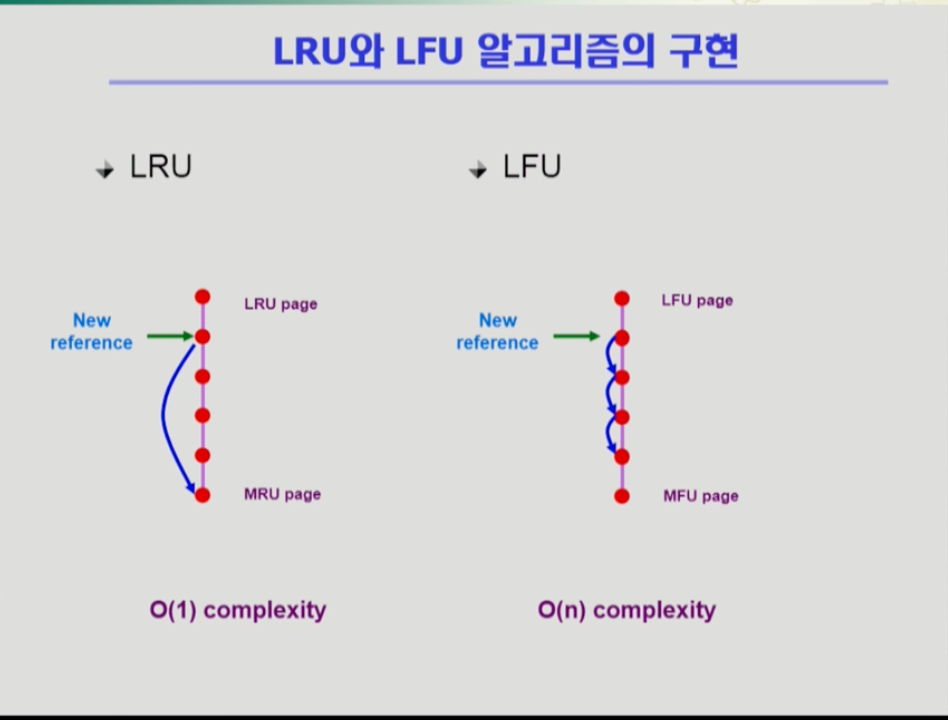
- 두 알고리즘은 어떻게 구현되는가
- LRU 알고리즘은 메모리 안의 페이지를 참조시간순서에 따라 한 줄로 줄세운다. 아래로 갈 수록 최근에 참조된 페이지다. 링크드 리스트 형태로 관리되는 것이다. 이미 안에 있었던 어떤 페이지가 메모리에 들어가면 그 페이지가 맨 밑으로 이동한다. 또 새로운 페이지가 들어가면 맨 위의 페이지가 쫓겨난다. LRU 알고리즘은 위처럼 리스트 형태로 구현하면 시간 복잡도가 O(1)시간이다. 즉 비교가 필요 없다.
- 만약 LFU 알고리즘을 비슷하게 한 줄로 줄세울 경우, 가장 참조횟수가 적은 페이지가 맨 위에 있고 밑으로 갈 수록 참조횟수가 많다. 그러나 위에 있는 어떤 페이지가 참조횟수가 1 늘어난다고 LRU처럼 맨 밑으로 갈 수 없다. 따라서 아래 페이지와 비교하여 어디까지 내려갈 수 있는지 확인해야 하고, 최악의 경우 모든 페이지가 참조횟수가 같아, 한번 참조횟수 추가시 구현 시간복잡도가 O(N)이나 결리게 된다.
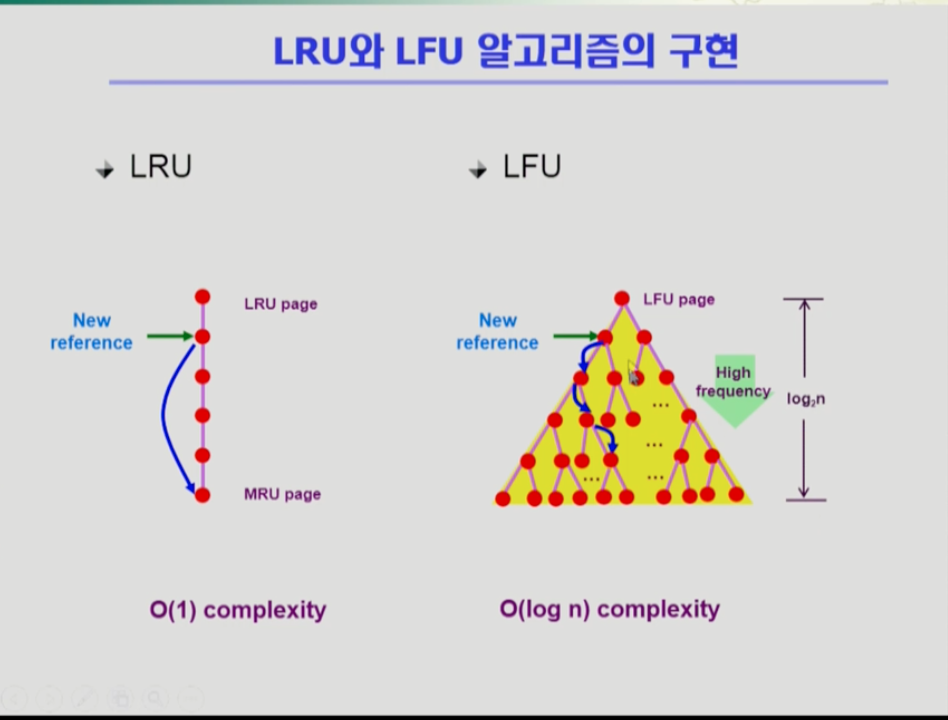
- 따라서 LFU 알고리즘은 다음과 같이 heap을 이용해 구현하여 O(log n)시간에 구현한다. 위 그림처럼 자식이 두개 씩 있는 이진 트리형태인 heap은 맨 위는 참조횟수가 가장 적은 페이지, 부모보다는 자식이 참조횟수가 많은 형태로 밑으로 갈 수록 참조횟수가 늘어난다. 이 상황에서 위의 화살표에 해당하는 페이지가 새로 참조되면 위의 화살표 페이지에서 직계 자식 둘과만 비교를 한다. 만약 자식과 비교하여 참조횟수가 많아져 자리를 바꾸면, 또 그 밑의 자식과 비교로 더 내려갈 수 있는지 판단한다. 따라서 자식보다 참조횟수가 많지 않을 때 까지 내려간다. 페이지 전체가 n개 라고 하면 이진 트리의 높이는 log small2(N)이다. 그래서 비교 횟수가 많아봐야 log n이 되는 것이다.

- 알고리즘은 항상 적어도 O(1)에서 O(log N)정도까지만 허용한다. O(N)은 허용할 수 없다.

하마드