
- 파일 시스템에 대해서 이야기하겠다
- 메모리는 주소를 통해서 접근하지만, 파일은 이름을 통해서 접근한다. 관련 정보를 이름으로 저장하는 것이다.
- 비휘발성의 보조기억장치에 저장된다
- 운영장치는 다양한 저장 장치를 서로 다른 파일로 관리함
- 파일에서 정의되는 연산은 생성, 삭제, 읽기, 변경, reposition(파일을 읽고 있던 위치를 수정해주는 연산), 파일 open/close 가 있다.
- open의 역할은 파일의 메타 데이터를 메모리로 올리는 것이다.
- 파일을 관리하기 위한 정보가 있다. 이름 File attribute(속성)(=meta date)이라 한다. 이름, 유형, 사이즈, 접근 권한와 같은 것이다.
- 파일 시스템은 파일과 파일의 메타데이터, 디렉토리 정보 등을 관리한다.

- 디렉토리 역시 하나의 파일이다. 파일의 메타데이터 중 일부를 보관한다.
- 디렉토리에서 정의되는 연산은 그 디렉토리의 파일을 보고, 파일을 찾고, 파일을 만들고 지우는 연산, 이름 재정의, 파일 시스템 전체 탐색 등이 있다.
- 논리적 디스크와 물리적 디스크가 있는데 운영체제는 논리적 디스크(=파티션)을 본다. 디스크 하나의 파티션을 나누면 논리적 디스크 여러개가 만들어지고, 물리적 디스크 여러개를 합쳐 하나의 논리적 디스크로 만들 수 있다. 파티션에 파일 시스템을 설치할 수도, 버츄얼 메모리의 스와핑 영역으로 사용할 수도 있다.
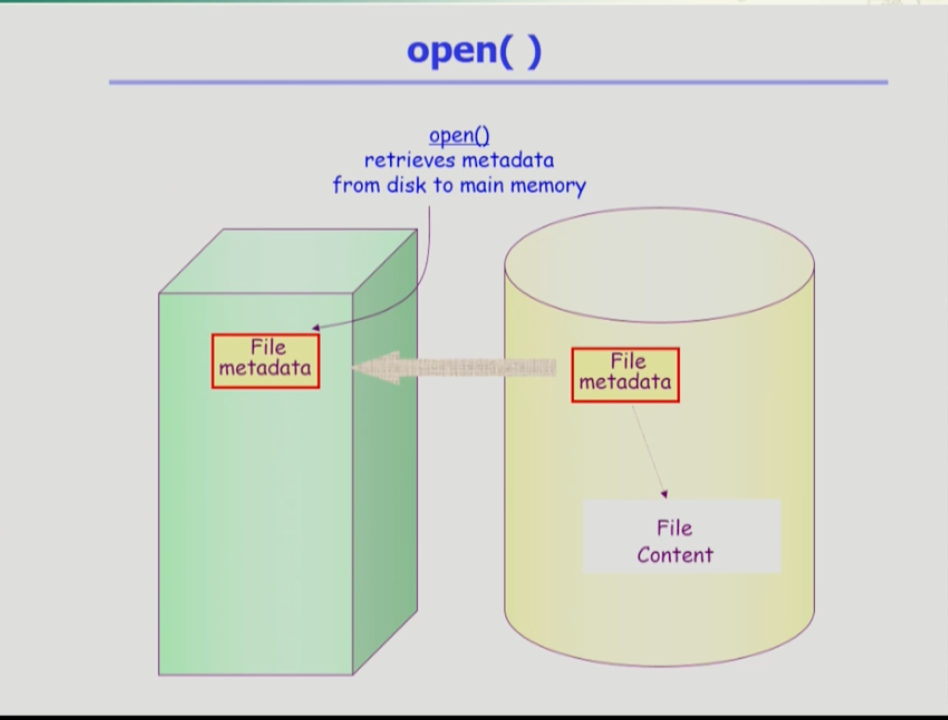
- open은 파일의 메타 데이터를 메모리에 올리는 것이다.

- open("a/b/c")연산을 하는 경우다.
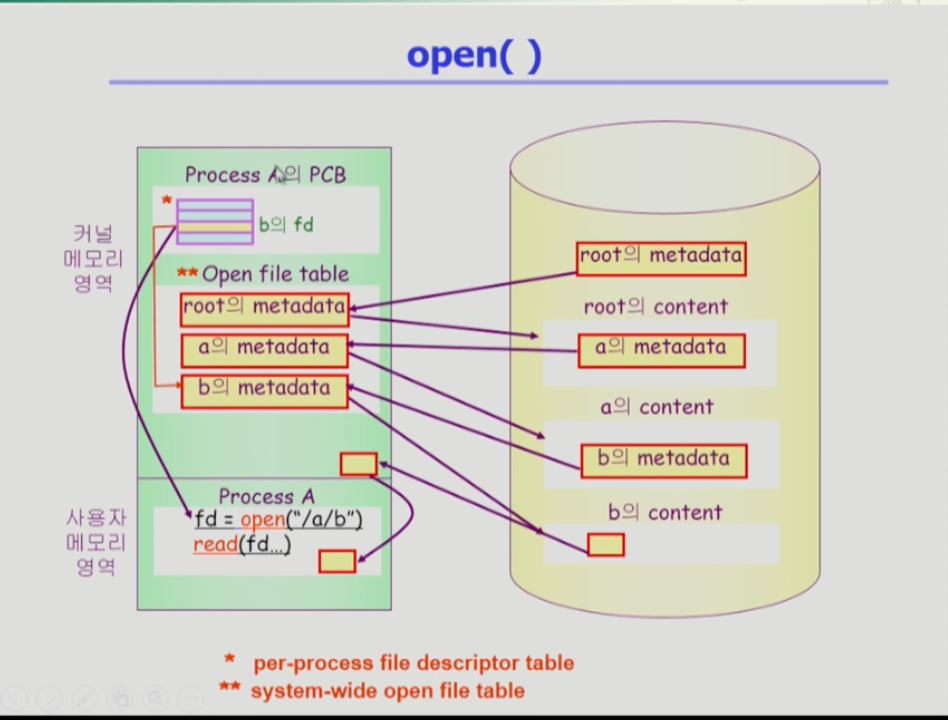
- open("a/b")연산을 하는 경우다. 사용자 프로그램이 open 하겠다는 시스템 콜을 한다. cpu 제어권이 운영체제로 넘어가 운영체제가 루트 디렉토리의 메타데이터를 커널 메모리 영역에 올린다. 메타데이터에는 파일의 위치정보가 있으므로 루트 디렉토리에서 실제 내용이 어디 있는지 알 수 있다. 그곳에서 a의 메타데이터를 찾아 이를 메모리에 올린다. 그곳에서 a의 내용 위치정보를 알 수 있다. 다시 a 디렉토리의 내용에서 b의 메타데이터를 찾을 수 있다. 그러면 이를 또 메모리에 올려 놓는다. open이 끝나고 결과값을 리턴 하는데, 각 프로세스마다 프로세스가 오픈한 파일에 대한 메타데이터 포인터를 가진 배열이 있는데 여기서 b에 해당하는 인덱스의 값을 사용자 프로세스에 리턴한다.
- 사용 디렉토리는 배열의 인덱스를 통해 read/write 요청을 할 수 있다. 그럼 cpu가 다시 운영체제로 넘어가서, 위와 같은 과정을 통해 b의 메타데이터에서 b의 위치정보를 찾아 b의 내용을 읽어와 운영체제가 자신의 메모리 공간에 그 내용을 읽어 두고 그 다음 사용자 프로그램에 그 내용을 카피해 전달한다.
- 만약 프로그램이 이후에 동일한 내용을 요청하면 자신의 메모리에 읽어둔 내용을 리턴하여 디스크까지 가지 않고도 전달 가능하다. 이것이 버퍼 캐싱이다. 이 환경에서는 LRU나 LFU 알고리즘을 사용 가능하다.
- 위의 pcb 테이블은 per process file descriptor table, 아래의 오픈 파일 테이블은 system-wide open file table이라 부른다.

- 파일의 접근 권한에 관한 내용이다.
- 메모리는 read/write 연산권한에 대한 내용만 있었지만, 파일은 파일을 여러 프로그램이 같이 사용할 수 있으므로, 접근 권한이 누구에게 있는지, 접근 연산이 무엇이 가능한지에 대한 두 정보를 같이 가져야 한다.
- 총 세 가지의 권한 제어 방법이 있다.
- 첫 번째는 엑세스 컨트를 매트릭스, 즉 행렬에 사용자와 파일 이름을 나열하고 각각의 사용자가 파일에 대해 있는 권한을 표시한 것이다. 이 방법은 파일은 많은데 특정 사용자 한명이 사용하기 위해 수많은 파일에 대한 테이블을 모두 만드므로 낭비가 있다. 따라서 링크드 리스트 형태로 만들 수 있는데, 첫번째는 액세스 컨트롤 리스트로, 파일을 주체로 하여 각각의 파일에 대해 접근 권한이 있는 사용자끼리의 리스트를 만드는 것이다. 두 번째는 Capability로 사용자를 주체로하여 가각의 사용자별로 가진 접근 권한을 가진 파일을 묶은 리스트를 만드는 것이다. 그러나 이 경우에도 오버해드는 여전히 존재한다.
- Grouping은 일반적으로 쓰는 방법으로, 모든 사용자가 아닌 전체 유저를 owner group public의 세 그룹으로 구별하여, 각 파일에 대해 세 그룹의 접근 권한을 3비트씩으로 표시해 놓는다. 이를 이용해 파일 하나의 접근 권한을 나타내기 위해 9개의 비트만 필요하다. 따라서 액세스 컨트롤 매트릭스에 비해 낭비가 적다.
- 마지막은 패스워드를 거는 방법이다. 모든 파일 또는 디렉토리 마다 패스워드를 둔다. 또는 접근 권한 전체에 대해 하나의 패스워드를 둘 수도 있다. 혹은 접근 권한 별로 패스워드를 둔다. 그러나 이 경우 암기나 관리적으로 문제가 생길 수 있다.
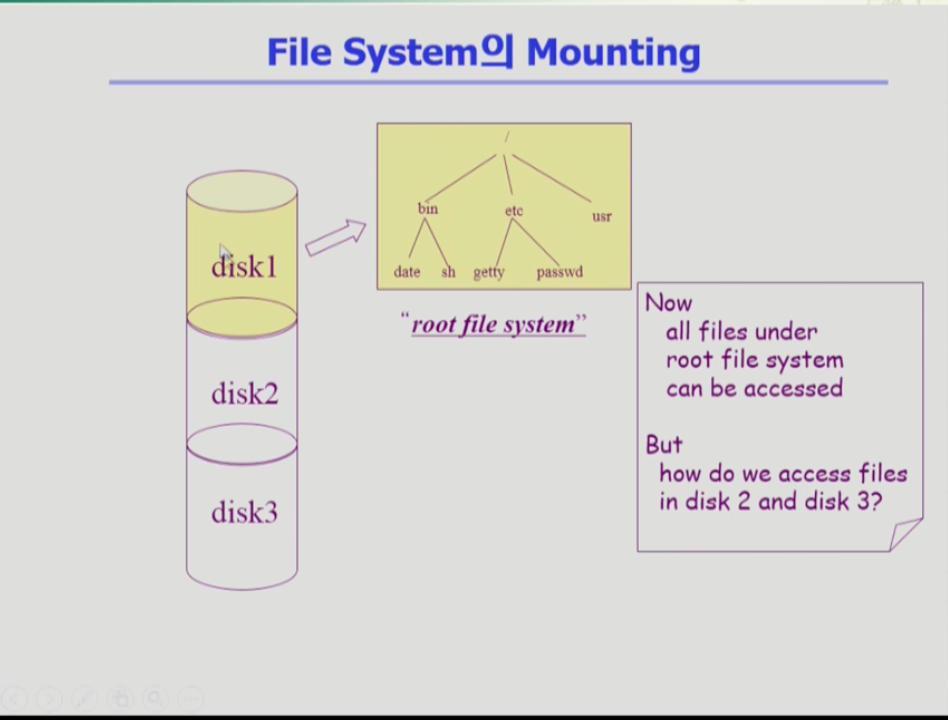
- 하나의 물리적인 디스크를 파티션으로 1,2,3으로 나누어 각각의 디스크에 파일 시스템을 설치한다. 이는 루트 파일 시스템이라 하여 어떤 운영체제에 대해 파일 시스템 하나가 접근이 가능하다. 만약 다른 파티션에 설치된 파일 시스템에는 어떻게 접근할까?
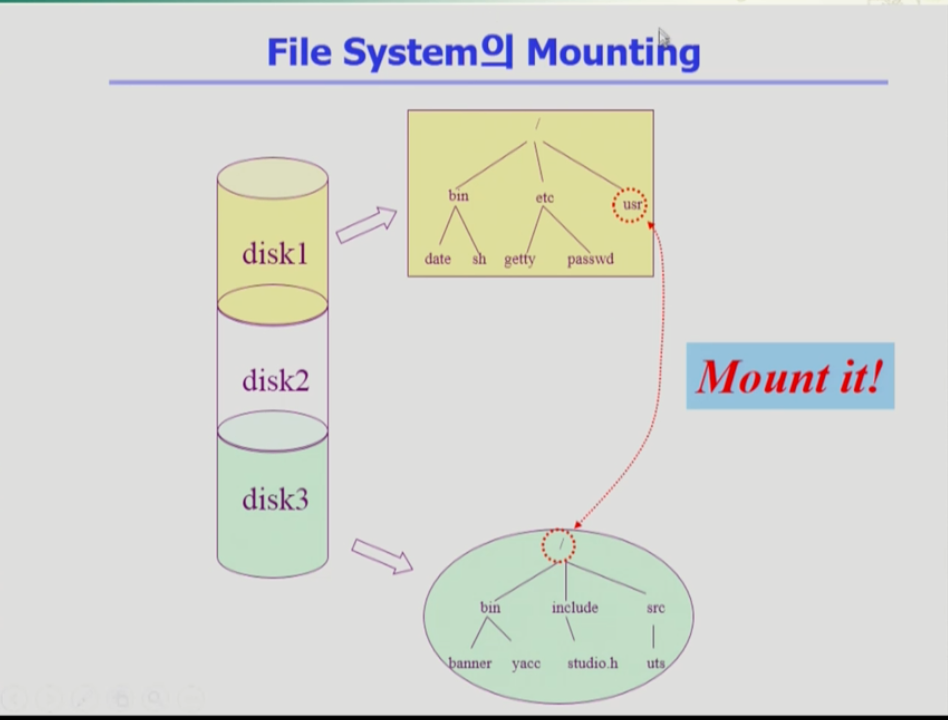
- 그 방법으로 마운팅이라는 연산이 있다. 이는 루트 파일 시스템의 특정 디렉토리 이름에(usr) 또 다른 파티션의 파일 시스템(연두색)을 마운트 해주면, 그 마운트된 디렉토리(usr)로 접근하면 결국 또다른 파티션의 파일 시스템(연두색)으로 접근하는 꼴이 되는 것이다.

- 파일을 접근하는 방법은 순차접근과 직접 접근(=임의 접근)방식이 있다.
- 이전의 카세트 테이프와 비디오 같은 것이 순차 접근 방식이다. 무조건 순차적으로 데이터에 접근할 수 있다. 영화의 10분을 보기 위해 10분까지 감기를 해야 하는 것과 같다.
- 직접 접근은 cd, 하드디스크같은 것으로 특정 위치에 바로 접근하는 법이 가능하다. 영화의 10분을 보기 위해 클릭 한 번으로 접근하는 것과 같다.

하마드