11.1 해싱이란?
해싱: 키 값에 직접 산술적인 연산을 적용하여 항목이 저장되어 있는 테이블의 주소를 계산하여 항목에 접근 -> 해시 테이블을 이용한 탐색
해시 테이블(hash table): 키 값의 연산에 의해 직접 접근이 가능항 구조
11.2 추상 자료형 사전 구조
사전 구조의 개념
사전 구조(dictionary): 맵(map)이나 테이블(table)로 불리기도 함
1. 영어 단어나 사람의 이름 같은 탐색 키(search key)
2. 단어의 정의나 주소 또는 전화 번호 같은 탐색 키와 관련된 값(value)
- 사전 구조에서 항목들은 탐색 키에 의해서 식별하고 관리
- 사전 구조에서 항목들은 모두 탐색 키를 가지고 있다는 점에서 리스트와 같은 다른 자료 구조들과 구분됨 -> 리스트에도 탐색 키를 같이 넣어서 저장할 수 있지만 근본적으로 위치에 의해 관리되는 자료구조임, 반면 사전 구조는 오직 탐색 키에 의해 관리
사전 구조의 연산
<ADT 11.2.1> 추상 자료형 dictionary
객체: 일련의 (key,value) 쌍의 집합
연산:
add(key,value) ::= (key,value)를 사전에 추가함
delete(key) ::= key에 해당되는 (key,value)를 찾아서 삭제, 탐색 성공 시 value, 실패 시 NULL을 반환
search(key) ::= key에 해당하는 value를 찾아서 반환, 탐색 실패 시 NULL 반환- 이진 탐색 트리를 사용한아면 최악의 경우 시간복잡도 O(n)이 될 것임
- 사전 구조를 가장 효율적으로 구현할 수 이쓴 방법은 해싱
- 해싱은 탐색 키의 비교가 아닌 탐색 키에 수식을 적용시켜 바로 탐색 키가 저장된 위치를 얻음
11.3 해싱의 구조
- 탐색 키들은 문자열이나 큰 숫자이기 때문에, 탐색 키를 직접 배열의 인덱스로 사용하기에는 무리가 있으므로, 이를 작은 정수로 사상(mapping)하는 함수가 필요함
- 해싱: 어떤 항목의 탐색 키만을 가지고 바로 항목이 저장되어 있는 배열의 인덱스를 결정하는 기법임
- 해시 함수(hash function): 탐색 키를 입력으로 받아 해시 주소(hash address)를 생성하고, 이 해시 주소가 배열로 구현된 해시 테이블(hash table)의 인덱스가 됨
-> 이 배열의 인덱스 위치에 자료를 저장할 수 있고 저장된 자료를 꺼낼 수 있음
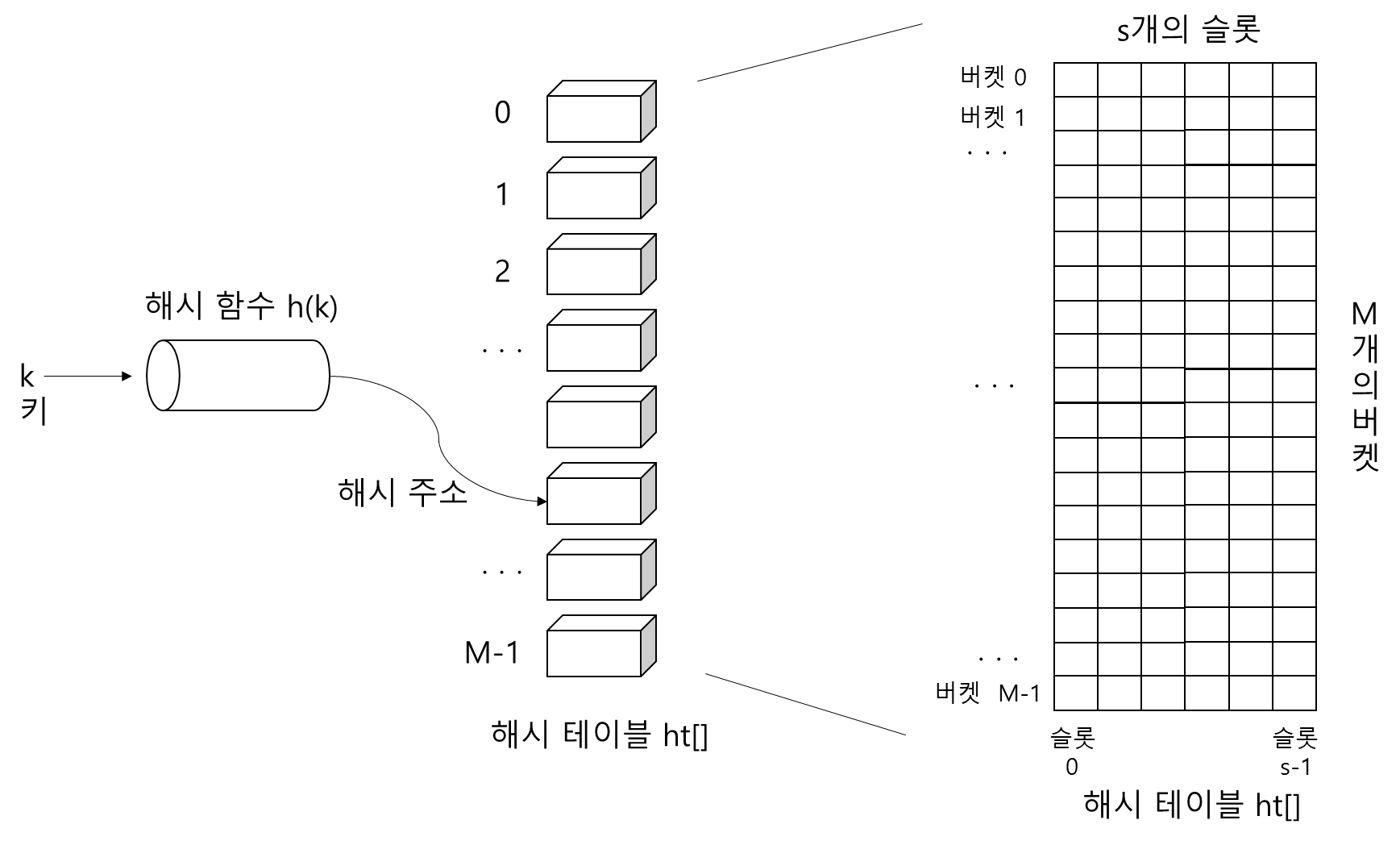
- 키 값 k를 입력 받아 해시 함수 h()로 연산한 결과인 해시 주소 h(k)를 인덱스를 사용하여 해시 테이블에 있는 항목에 접근
- 해시 테이블 ht는 M개의 버켓(bucket)으로 이루어지는 테이블로서 ht[0], ht[1], ..., ht[M-1]의 원소를 가짐
- 하나의 버켓은 s개의 슬롯(slot)을 가질 수 있으며, 하나의 슬롯에는 하나의 항목이 저장됨
-> 하나의 버켓에 여러개의 슬롯을 두는 이유: 서로 다른 두 개의 키가 해시 함수에 의해 동일한 해시 주소로 변환될 수 있으므로 여러 개의 항목을 동일한 버켓에 저장하기 위함, 하지만 대부분의 경우 하나의 버켓에 하나의 슬롯을 가짐
- 해시 테이블의 버켓 수는 키가 가질 수 있는 모든 경우의 수보다 매우 작기때문에 여러 개의 서로 다른 탐색 키가 해시 함수에 의해 같은 해수 주소로 사상(mapping)될 수 있음
- 서로 다른 두 개의 탐색 키가 같은 경우를 충돌(collision)이라고 하며, 이러한 키들을 동의어(synonym)라고 함
- 충돌이 발생하면 같은 버켓에 있는 다른 슬롯에 항목을 저장하게 됨
- 충돌이 버켓에 할당된 슬롯 수보다 많이 발생하게 되면 버멧에 더 이상 항목을 저장할 수 없게 되는 오버플로(overflow)가 발생함 -> 이에 대한 해결 방법이 반드시 필요
이상적인 해싱
- 이상적인 해싱은 매우 빠르게 자료를 저장하고 탐색할 수 있음
- 자료를 꺼내기 위해 전체 배열을 탐색하지 않았음에 유의
<알고리즘 11.3.1> 이상적인 해싱 알고리즘
add(key, value)
index <- hash_function(key)
ht[index] <- value
search(key)
index <- hash_function(key)
return ht[index]- 해시 테이블이 충분한 공간만 가지고 있으면 잘 동작
실제의 해싱
- 실제로는 해시 테이블의 크기가 제한되어 있으므로 하나의 탐색 키당 해시 테이블에서 하나의 공간을 할당 받을 수 없음
- 더 작은 해시 테이블을 사용하는 해시 함수를 고안해야 함
-> 탐색 키를 해시 테이블의 크기로 나누어 그 나머지를 해시 테이블 주소로 하는 방법 (제산 함수) - 이 경우 충돌과 오버플로가 발생하는데 이를 해결하는 방법이 필요함
11.4 해시 함수
좋은 해시 함수의 조건
1. 충돌이 적어야 함
2. 해시 함수 값이 해시 테이블의 주소 영역 내에서 고르게 분포되어야 함
3. 계산이 빨라야 함
제산 함수
제산 함수: 나머지 연산자(mod)를 사용하여 탐색 키를 해시 테이블의 크기로 나눈 나머지를 해시 주소로 사용하는 방법
h(k) = k mod M // 0 ~ M-1까지의 숫자가 해시 테이블을 위한 유효한 인덱스가 됨 - 해시 테이블의 크기 M은 주로 소수(prime number)로 나누어지지 않는 수로 선택해야하고, 항상 홀수여야 함.
- 나머지 연산을 수행했을 때 음수가 나올 가능성에도 대비 해야함 -> M을 더해 항상 0 ~ M-1의 값이 되도록 함
int hash_function(int key){
int hash_index = key % M;
if(hash_index < 0){
hash_index += M;
}
return hash_index;
}홀딩 함수
홀딩 함수: 팀색 키를 여러 부분으로 나누어 모두 더한 값을 해시 주소로 사용
탐색 키를 나누고 더하는 방법에는 이동 폴딩(shift folding)과 경계 폴딩(boundary folding)이 대표적
이동 폴딩: 탐색 키를 여러 부분으로 나눈 값들을 더하여 해시 주소로 사용
경계 폴딩: 탐색 키의 이웃한 부분을 거꾸로 더하여 해시 주소로 사용

폴딩(folding): 탐색 키를 몇 개의 부분으로 나누어 이를 더하거나 비트별로 XOR 같은 부울 연산을 하는 것
ex) 32비트 키를 2개의 16비트로 나누어 비트별로 XOR 연산하는 코드
hash_index = (short)(key ^ (key>>16))중간 제곱 함수
중간 제곱 합수: 탐색 키를 제곱한 다음, 중간의 몇 비트를 취해서 해시 주소를 생성
- 제곱한 값의 중간 비트들은 대개 탐색 키의 모든 문자들과 관련있기 때문에 서로 다른 탐색 키의 문자가 같을지라도 서로 다른 해싱 주소를 갖게 됨.
- 탐색 키 값을 제곱한 값의 중간 비트들의 값은 비교적 고르게 분산되어 있음
비트 추출 방법
비트 추출 방법: 해시 테이블의 크기가 M=일 떄 탐색 키를 이진수로 간주하여 임의의 위치의 k개의 비트를 해시 주소롤 사용하는 것
- 아주 간단하다는 장점이 있지만, 탐색 키의 일부 정보만을 사용하므로 해시 주소의 집중 현상이 일어날 가능성이 높다는 단점이 있음
숫자 분석 방법
숫자 분석 방법: 숫자로 구성된 키에서 각각의 위치에 있는 수의 특징을 미리 알고 있을 때 유용, 키의 각각의 위치에 있는 숫자 중에서 편중되지 않은 수들을 해시 테이블의 크기에 적합한 만큼 조합하여 해시 주소로 사용하는 방법
- ex) 학생의 학번이 200812345 일 때, 입학년도를 의미하는 앞의 4 자릿수는 편중되어 있으므로 가급적 사용하지 않고 나머지 수를 조합하여 해시 주소로 사용
탐색 키가 문자열일 경우 주의할 점
- 문자열 안의 문자에 정수를 할당하는 것 ex)'a' 부터 'z'에 1부터 26을 할당하는 것
- 문자의 아스키 코드 값이나 유니 코드 값을 사용하는 것
-> 아스키 코드 값에 위치에 기초한 값을 곱하는 것, 즉 문자열 s가 n개의 문자를 가지고 있다고 가정하고 s 안의 i번째 문자가 라고 하면 해시 주소는 이 됨 (g는 양의 정수)
- 계산량을 줄이기 위해 호너의 방법(Horner's method)을 사용할 수 있음
->
int hash_function(char* key){
int hash_index = 0;
while(*key){
hash_index = g*hash_index + *key++; // 보통 g는 31을 사용
}
return hash_index;
}- 탐색 키가 긴 문자열로 되어 있을 경우, 오버플로를 일으킬 수 있음, 그러나 C언어에서는 오버플로를 무시하므로 여전히 유효한 해시 주소를 얻을 수 있음
- 오버 플로가 발생하면 해시 코드 값이 음수가 될 수 있으므로 이런 경울르 검사해야 함
11.5 충돌 해결책
충돌(collision): 서로 다른 탐색 키를 갖는 항목들이 같은 해시 주소를 가지는 현상
- 충돌이 일어난 항목을 해시 테이블의 다른 위치에 저장
-> 해시 테이블 안에서 현재 사용되지 않는 공간을 찾는 방법으로 선형 조사법(linear probing)이라고 함 - 해시 테이블의 하나의 위치가 여러 개의 항목을 저장할 수 있도록 해시 테이블의 구조를 변경
-> 해시 테이블의 구조를 바꾸는 방법으로 체이닝(chaining)이라고 함
11.5.1 선형 조사법
선형 조사법: 특정 버켓에서 충돌이 발생하면 해시 테이블이 비어 있는 버켓을 찾는 방법
- 조사(probing): 해시 테이블에서 비어 있는 공간을 찾는 것
- ht[k]에서 충돌이 발생했으면 ht[k+1]이 비어 있는지 확인 후 비어 있지 않다면 ht[k+2]를 살펴봄, 비어 있는 공간이 나올때까지 조사하는 방법
// 조사되는 위치
h(k),h(k)+1,h(k)+2,h(k)+3,...
ex) 크기가 7인 해시 테이블과 h(k) = k mode 7인 해시 함수로 사용한다고 가정할 때, 8, 1, 9, 6, 13의 순으로 탐색 키를 저장하면
1단계 (8): h(8) = 8 mod 7 = 1(저장)
2단계 (1): h(1) = 1 mod 7 = 1(충돌 발생)
(h(1)+1) mod 7 = 2(저장)
3단계 (9): h(9) = 9 mod 7 = 2(충돌 발생)
(h(9)+1) mod 7 = 3(저장)
4단계 (6): h(6) = 6 mod 7 = 6(저장)
5단계(13): h(13) = 13 mod 7 = 6(충돌 발생)
(h(13)+1) mod 7 = 0(저장)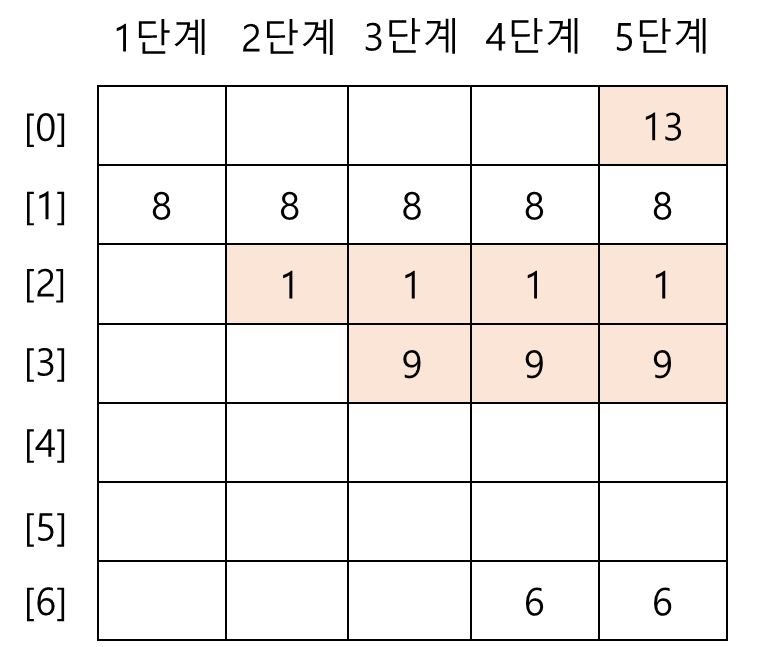
- 총돌이 나서 다른 곳에 저장된 탐색 키들은 주황색으로 표시
<프로그램 11.5.1.1> 선형 조사법의 구현 part 1
- 해시 테이블 1차원 -> 키 필드, 자료 필도
- 탐색 키는 문자열
- 버켓당 하나의 슬롯
#define KEY_SIZE 10 // 탐색 키의 최대 길이
#define TABLE_SIZE 13 // 해시 테이블의 크기(소수)
typedef struct{
char key[KEY_SIZE];
// 다른 필요한 필드를 여기에 넣음
}element;
element hash_table[TABLE_SIZE]; // 해시 테이블<프로그램 11.5.1.2> 선형 조사법의 구현 part 2
초기화 함수: 각 버켓을 공백 상태를 만드는 것
- 문자열이 탐색 키이므로 탐색 키의 첫 번째 문자가 NULL값이면 버켓이 비어 있는 것으로 생각
// 해시 테이블의 각 요소를 초기화하는 함수
void init_table(element ht[]){
for(int i=0;i<TABLE_SIZE;i++){
ht[i].key[0] = NULL; // 문자열이 탐색 키이므로 탐색 키의 첫 번째 문자가 NULL 값이면 버켓이 비어 있는 것으로 생각할 수 있음
}
}<프로그램 11.5.1.3> 선형 조사법의 구현 part 3
해시 함수
- 문자열을 먼저 정수로 바꾸고 다시 여기에 제산 함수를 적용시킴
- 문자열을 정수를 변환하는 함수는 문자열의 각 문자 아스키 코드를 전부 합하는 방법을 사용
// 해시 테이블에 탐색 키를 삽입하기 전 탐색 키를 정수로 바꿔주는 해시 함수 필요
// 문자로 된 탐색 키를 숫자로 변환
int transform(char *key){
int number =0;
while(*key){ // 간단한 덧셈 방식 사용 자연수 생성
number += *key++;
}
return number;
}
int hash_function(char *key){
return transform(key) % TABLE_SIZE;
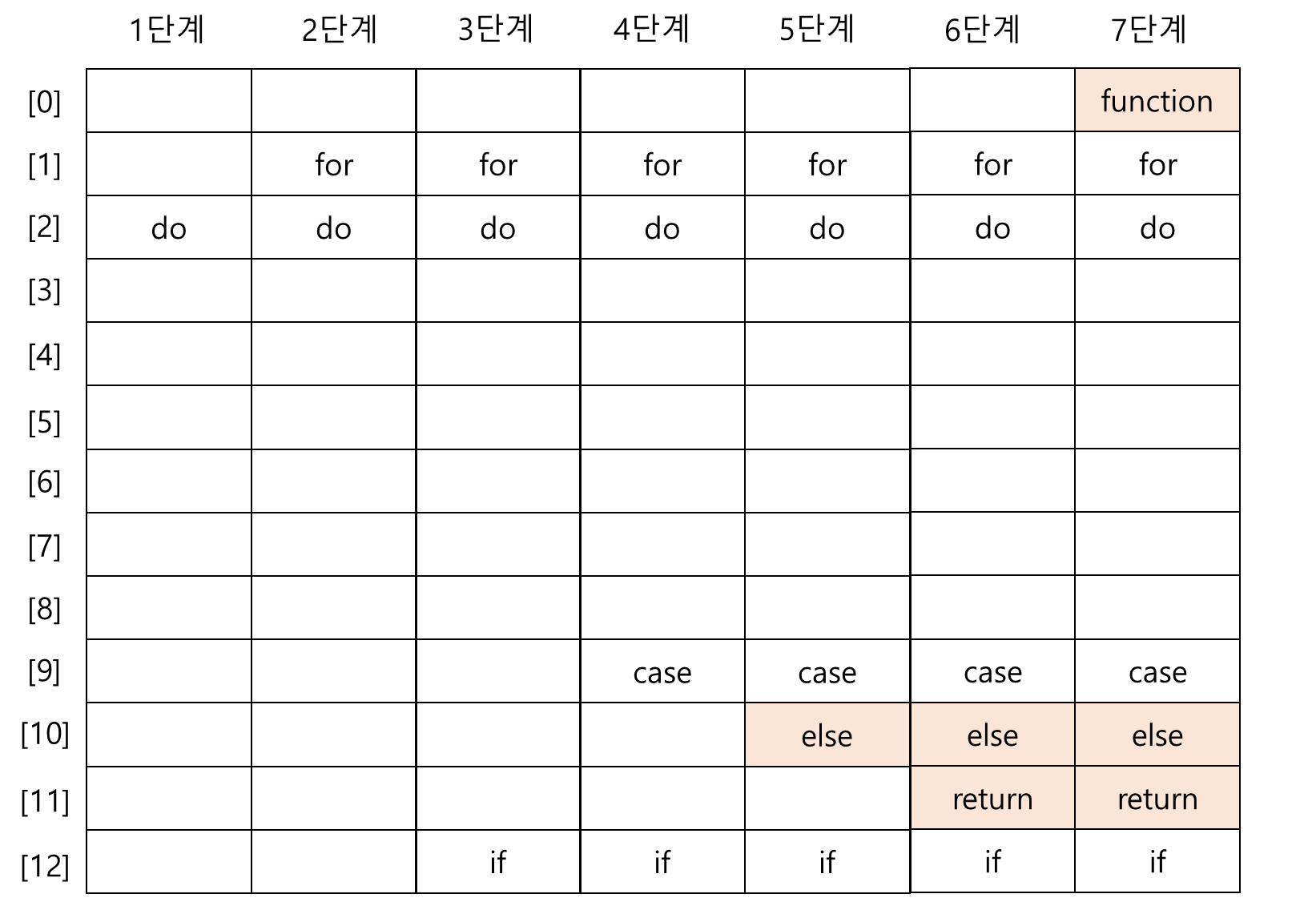
}ex) 탐색 키가 "do", "for", "if", "case", "else", "return", "function" 일 때, 문자열에서 정수로의 변환 과정을 거쳐 해시 주소를 구해보면
| 탐색 키 | 덧셈식 변환 과정 | 덧셈 합계 | 해시 주소 |
|---|---|---|---|
| do | 100+111 | 211 | 3 |
| for | 102+111+114 | 327 | 2 |
| if | 105+102 | 207 | 12 |
| case | 99+97+115+101 | 412 | 9 |
| else | 101+108+115+101 | 425 | 9 |
| return | 114+101+116+117+114+110 | 672 | 9 |
| function | 102+117+110+99+116+105+111+110 | 870 | 12 |
- "case", "else", "return"은 모두 같은 해시 주소로 계산됨("if","function"도 마찬가지) -> 선형 조사법으로 해결
- 버켓 조사는 원형으로 회전함 즉, 해시 테이블의 마지막에 도달하면 다시 처음으로 돌아감
- 한 번 충돌이 시작되면 그 위치에 항목들이 집중되는 군집화(clustering) 현상을 관찰할 수 있음
<프로그램 11.5.1.4> 선형 조사법의 구현 part 4
삽입 함수
1. 탐색 키에 대해 해시 주소를 계산
2. 그 주소가 비어 있는지를 검사해서 비어 있지 않으면 먼저 그 주소에 저장된 탐색 키와 현재 삽입하려고 하는 탐색 키가 동일한지를 체크
3. 동일하면 탐색 키 중복되었다는 것을 화면에 출력하고 복귀
4. 동일하지 않으면 현재 주소를 나타내는 변수 i를 증가하여 다음 버켓을 가리키도록 함
5. 증가된 주소가 시작 주소로 되돌아온 경우에는 다른 모든 버켓을 조사했는데도 빈 버켓이 없는 경우이므로 더 이상 삽입이 불가능한 오류 상태임을 알리고 복귀
#define empty(e) (strlen(e.key) == 0) // 현재 버켓이 비어 있는지를 검사하는 함수
#define equal(e1, e2) (!strcmp(e1.key,e2.key)) // 두 개의 항목이 동일한지를 검사하는 함수
// 선형 조사법을 이용하여 테이블에 키를 삽입하고,
// 테이블이 가득 찬 경우 종료
void hash_lp_add(element item, element ht[]){
int i;
int hash_value = i = hash_function(item.key); // 탐색 키에 대하여 해시 주소를 계산
while(!empty(ht[i])){ // 그 주소가 비어 있는지 검사
if(equal(item,ht[i])){ // 그 주소에 저장된 탐색 키와 현재 삽입하려는 탐색 키가 동일한지 검사
fprintf(stderr,"Duplicate key.\n");
return;
}
i = (i+1) % TABLE_SIZE; // 저장된 탐색 키가 종복되지 않았을 경우 현재 주소를 나타내는 변수 i를 증가시켜 다음 버켓을 가리키도록 함
if( i == hash_value){
fprintf(stderr,"Table is full\n");
return;
}
}
ht[i] = item;
}<프로그램 11.5.1.5> 선형 조사법의 구현 part 5
탐색 함수
1. 탐색 키에 해시 함수를 적용시켜 계산된 주소에서 항목을 찾지 못하면 해당 항목을 찾을 때까지 연속 버켓을 탐색
2. 탐색하다가 시작 주소로 되돌아오면 해당 항목이 테이블에 없다고 결론 내릴 수 있음
// 선형 조사법을 이용하여 테이블에 저장된 키를 탐색
void hash_lp_search(element item, element ht[]){
int i;
int hash_value = i = hash_function(item.key);
while(!empty(ht[i])){
if(equal(item,ht[i])){
fprintf(stderr,"Search Success: Location = %d\n",i);
return;
}
i = (i+1) %TABLE_SIZE;
if(i == hash_value){
fprintf(stderr,"Search fail\n");
return;
}
}
fprintf(stderr,"Search fail\n");
}<프로그램 11.5.1.6> 선형 조사법의 구현 part 6
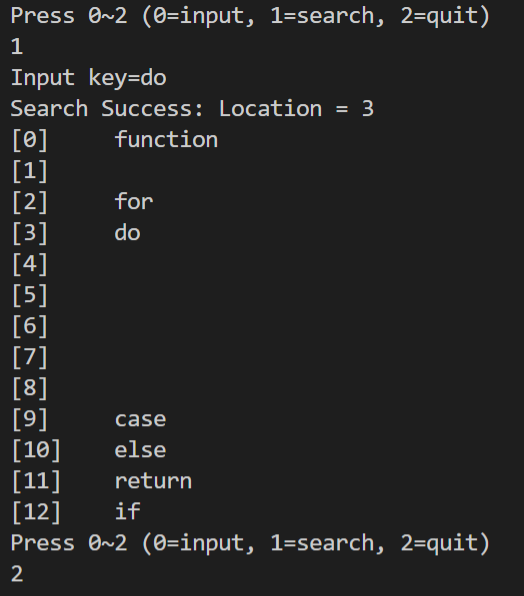
// 해싱 테이블의 내용을 출력
void hash_lp_print(element ht[]){
for(int i=0;i<TABLE_SIZE;i++){
printf("[%d] %s\n",i,ht[i].key);
}
}
// 해싱 테이블을 사용한 예제
int main(){
element tmp;
int op;
while(1){
printf("Press 0~2 (0=input, 1=search, 2=quit)\n");
scanf("%d",&op);
if(op == 2) break;
printf("Input key=");
scanf("%s",tmp.key);
if(op == 0){
hash_lp_add(tmp, hash_table);
}else if (op == 1){
hash_lp_search(tmp, hash_table);
}
hash_lp_print(hash_table);
}
}
- 비교적 간단한 이 방법은 탐색 키들이 집중되어 저장되는 군집화 현상이 발생하게 되고, 최악의 경우 집중된 항목들이 결합(coaliasing)하는 현상이 발생하므로 탐색 시간이 길어지는 단점이 있음
삭제 함수
- 삭제를 가능하게 하려면 버켓을 몇 가지로 분류해야함 -> 한 번도 사용이 안된 버켓, 사용되었으나 현재는 비어 있는 버켓, 현재 사용 중인 버켓으로 분류
- 탐색 함수에서는 한 번도 사용이 안된 버켓을 만나야 탐색이 중단되도록 함
이차 조사법
이차 조사법(quadratic probing): 선형 조사법과 유사하지만, 다음 조사할 위치를 아래의 식에 의해 결정
- 이 방법은 선형 조사법의 문제점인 집중과 결합을 크게 완화할 수 있음
- 하지만 이 방법도 2차 집중 문제를 일으킬 수 있지만, 1차 집중처럼 심각한 것은 아님
- 2차 집중의 이유: 동일한 위치로 사상되는 여러 탐색 키들이 같은 순서에 의해 빈 버켓을 조사하기 때문 -> 이 문제는 이중 해시법으로 해결할 수 있음
- 이차 조사법을 구현하려면 다음 조사 위치를 찾는 부분만 변경시키면 됨
<프로그램 11.5.1.7> 이차 조사법 구현
void hash_qp_add(element item, element ht[]){
int i, inc = 0;
int hash_value = i = hash_function(item.key);
// printf("hash_address=%d\n",i);
while(!empty(ht[i])){
if(equal(item,ht[i])){
fprintf(stderr,"Duplicate key.\n");
return;
}
// 다음 조사 위치를 찾는 부분 변경
i = (hash_value + inc*inc) % TABLE_SIZE;
inc = inc +1;
if( i == hash_value){
fprintf(stderr,"Table is full\n");
return;
}
}
ht[i] = item;
}이중 해싱법
이중 해싱법(double hashing) 또는 재해싱(rehashing): 오버플로가 발생함에따라 항목을 저장할 다음 위치를 결정할 때, 원래 해시 함수와 다른 별개의 해시 함수를 이용하는 방법
- 이 방법은 항목들을 해시 테이블에 더욱 균일하게 분포시킬 수 있으므로 효과적
- 선형 조사법과 이차 조사법은 충돌이 발생했을 때 해시 함숫값에 어떤 값(각각 1과 )을 더하여 다음 위치를 얻음
-> 따라서, 해시 함숫값이 같으면 차후에 조사되는 위치도 같게 됨
ex) 크기가 10인 해시 테이블에서 제산 함수를 이용하는 해싱 함수를 사용할 때, 15, 25는 이차 조사법에서 5,6,9,14,... 와 같은 동일한 조사 순서를 생성함 - 이중 해싱법에서는 탐색 키를 참조하여 더해지는 값이 결정 됨
-> 따라서, 해시 함숫값이 같더라도 탐색 키가 다르면 서로 다른 조사 순서를 갖음, 2차 집중을 피핼 수 있음 - 두 번째 해시 함수는 조사 간격을 결정
step = C - (k mod C) // 이런 형태의 함수는 [1...C] 사이의 값을 생성, C는 보통 테이블 크기인 M보다 약간 작은 소수 - 충돌이 발생했을 때, 조사되는 위치
- 이중 해싱에서는 같은 해시 함수값과 같은 탐색 순서를 가지는 요소들이 거의 없기 때문에 집중 현상이 매우 드묾
ex) 탐색 키가 8, 1, 9, 6, 13이고, 첫 번째 해시 함수가 h(k) = k mod 7이고, 오버플로 발생 시 해시 함수가 h'(k) = 5 - (k mod 5) 일 때, 삽입 예
1단계 (8): h(8) = 8 mod 7 = 1(저장)
2단계 (1): h(1) = 1 mod 7 = 1(충돌 발생)
(h(1) + h'(1)) mod 7 = (1 + 5 - (1 mod 5)) mod 7 = 5(저장)
3단계 (9): h(9) = 9 mod 7 = 2(저장)
4단계 (6): h(6) = 6 mod 7 = 6(저장)
5단계 (13): h(13) = 13 mod 7 = 6(충돌 발생)
(h(13) + h'(13)) mod 7 = (6 + 5 - (13 mod 5)) mod 7 = 1(충돌 발생)
(h(13)+2*h'(13)) mod 7 = (6+2*2) mod 7 = 3(저장)
<프로그램 11.5.1.8> 이중 해싱법의 구현
void hash_qp_add(element item, element ht[]){
int i;
int hash_value = i = hash_function1item.key);
int inc = hash_function2(item.key);
while(!empty(ht[i])){
if(equal(item,ht[i])){
fprintf(stderr,"Duplicate key.\n");
return;
}
// 다음 조사 위치를 찾는 부분 변경
i = (i + inc) % TABLE_SIZE;
if( i == hash_value){
fprintf(stderr,"Table is full\n");
return;
}
}
ht[i] = item;
}- 선형 조사법의 문제점은 한 번도 사용되지 않은 위치가 있어야만 탐색이 빨리 끝나게 된다는 것
- 만약 거의 모든 위치가 사용되고 있거나 사용된 적이 있는 위치라면 실패하는 탐색인 경우, 테이블의 거의 모든 위치를 조사하게 됨
-> 체이닝 방법은 이러한 문제가 없음
11.5.2 체이닝
- 체이닝: 해시 테이블의 구조를 변경하여 각 버켓이 하나 이상의 값을 저장할 수 있도록 하는 방법
- 체이닝은 오버플로 문제를 연결 리스트로 해결함, 고정된 슬롯을 할당하는 것이 아니라, 각 버켓에 삽입과 삭제가 용이한 연결 리스트를 할당
ex) 탐색 키가 8, 1, 9, 6, 13이고, 해시 함수가 h(k) = k mod 7 일 때 삽입 예
1단계 (8): h(8) = 8 mod 7 = 1(저장)
2단계 (1): h(1) = 1 mod 7 = 1(충돌 발생 -> 새로운 노드 생성 저장)
3단계 (9): h(9) = 9 mod 7 = 2(저장)
4단계 (6): h(6) = 6 mod 7 = 6(저장)
5단계 (13): h(13) = 13 mod 7 = 6(충돌 발생 -> 새로운 노드 생성 저장)-
연결 리스트의 어디에 새로운 항목을 삽입해야할지 결정해야 함
-> 중복이 허용된다면, 연결리스트의 처음에 삽입하는 것이 능률적
-> 중복이 허용되지 않는다면, 연결리스트의 마지막에 삽입하는 것이 자연스러움 -
문자열 키에 대한 체이닝 해싱 구현을 위한 구조체
#define KEY_SIZE 10 // 탐색 키의 최대 길이
#define TABLE_SIZE 13 // 해싱 테이블의 크기(소수)
typedef struct{
char key[KEY_SIZE];
// 다른 필요한 필드
}element;
typedef struct ListNode{
element item;
struct ListNode *link;
}ListNode;
ListNode *hash_table[TABLE_SIZE];<프로그램 11.5.2.1> 체이닝의 구현
삽입 함수
1. 탐색 키가 버켓으로 들어오면 먼저 동적 메모리 할당을 이용하여 연결 리스트의 노드를 생성
2. 이 새로운 노드에 탐색 키를 복사
3. 버켓에 연결되어 있는 기존의 연결 리스트에서 동일한 탐색 키가 존재하는지 검사
4. 동일한 키가 있을 경우 오류 메시지 출력하고 복귀
4. 동일한 키가 없을 경우 연결 리스트의 맨 끝에 새로운 탐색 키를 포함하는 새로운 노드를 연결
5. 만약 기존의 연결 리스트가 없을 경우 해시 테이블의 포인터에 새로운 노드를 연결
#define equal(e1,e2) (!strcmp(e1.key, e2.key)
// 체이닝을 이용하여 테이블에 키 삽입
void hash_chain_add(element item, ListNode *ht[]){
int hash_value = hash_function(item.key);
ListNode *ptr; // 새로운 노드
ListNode *node_before = NULL; // 이전 노드
ListNode *node = ht[hash_value]; // 현재 노드
for(;node;node_before = node, node = node->link){
if(equal(node->item,item){
fprintf(stderr,"Already key\n");
return;
}
}
ptr = (ListNode*)malloc(sizeof(ListNode));
ptr->item = item;
ptr->link = NULL;
if(node_befor){ // 기존의 연결 리스트가 있다면
node_before->link = node;
}else{ // 기존의 연결 리스트가 없으면
ht[hash_value] = ptr;
}
}
// 체이닝을 이용하여 테이블에 저장된 키를 탐색
void hash_chain_find(element item, ListNode *ht[]){
ListNode *node;
int hash_value = hash_function(item.key);
for(node= ht[hash_value];node;node = node->link){
if(equal(node->item, item){
printf("Find key\n");
return;
}
}
printf("Not Found key\n");
}node_before 포인터가 필요한 이유
- node 포인터가 NULL이 되면 for 루프가 끝나게 됨
- 하지만, 우리가 필요한 포인터는 NULL 바로 앞에 있는 포인터
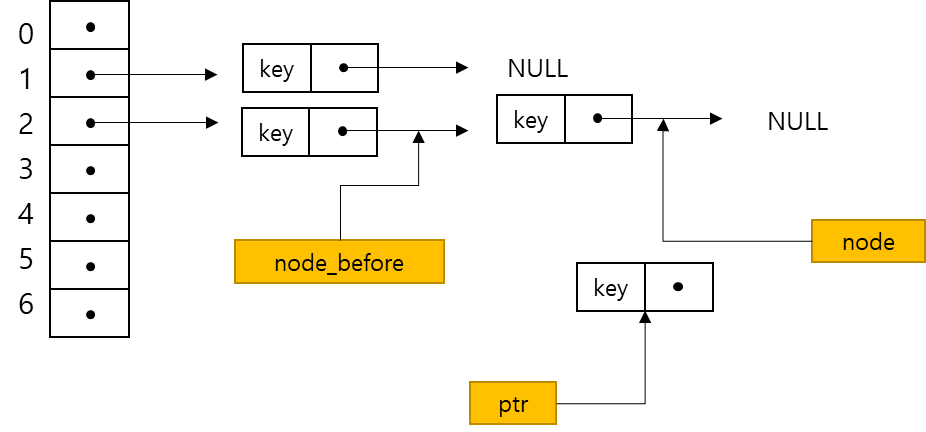
- 체이닝에서 항목을 탐색하거나 삽입하고자 하면 키 값의 버켓에 해당하는 연결 리스트에서 독립적으로 탐색이나 삽입이 이루어짐
- 체이닝은 해시 테이블을 연결 리스트로 구성하므로 필요한 만큼의 메모리만 사용하게 되어 공간적 사용 효율이 매우 우수함
- 오버플로가 발생할 경우에도 해당 버켓에 할당도니 연결 리스트만 처리하게 되므로 수행 시간 면에서도 매우 효율적임
11.6 해싱의 성능 분석
-
해싱에서 중요한 연산은 탐색 연산
-> 해시 테이블에 자료를 추가하거나 자료를 꺼내거나 자료를 삭제하는 연산들은 모두 탐색 연산을 사용하게 됨 -
이상적인 해싱
-> 충돌이 전혀 일어나지 않는다믄 가정하에 가능
-> 시간복잡도 -
해싱 성능 분석
-> 해시 테이블이 얼마나 채워져 있는지를 나타내는 척도를 정의
-> 해시 테이블의 적재 밀도(loading density) 또는 적재 비율(loading factor)은 현재 저장된 항목의 개수 n과 해시 테이블의 크기 M의 비율
-> 가 0이면 해시 테이블이 비어 있음을 의미함
-> 의 최댓값은 충돌 해결 방법에 따라 달라지는데 선형 조사법에서는 해시 테이블이 가득 찬다면 각 버켓당 하나의 항목이 저장될 것이기 때문에 1이 되고, 체이닝에서는 저장할 수 있는 항목의 수가 해시 테이블의 크기를 넘어 설 수 있기 때문에 최대값을 가지지 않음 -
선형 조사법
-> 실패한 탐색:
-> 성공항 탐색: -
체이닝
-> 실패한 탐색:
-> 성공한 탐색:=> 체이닝의 경우 가 증가하더라도 성능이 급격하게 떨어지지 않음. 하지만, 효율성을 위해 낮게 유지할 필요가 있음
탐색 방법 탐색 삽입 삭제 순차 탐색 O(n) O(1) O(n) 이진 탐색 O(logn) O(logn + n) O(logn + n) 이진 탐색 트리 균형 트리 O(logn) O(logn) O(logn) 경사 트리 O(n) O(n) O(n) 해싱 최선의 경우 O(1) O(1) O(1) 최악의 경우 O(n) O(n) O(n)
<참고자료>
천인국 · 공용해 · 하상호 지음,『C언어로 쉽게 풀어쓴 자료구조』, 생능출판(2016)
