메모리의 비연속 할당 기법에 해당하는 페이징과 세그멘테이션에 대해 배워보자 ! 🕵🏼♀️ 💭
1. Paging
- 프로세스의 virtual memory를 동일한 사이즈의 page 단위로 나눔
- virtual memory의 내용이 page단위로 비연속적으로 저장됨 (보통 페이지 당 4KB로 구성됨)
- 일부는 backing storage에, 일부는 physical memory에 저장
- basic method
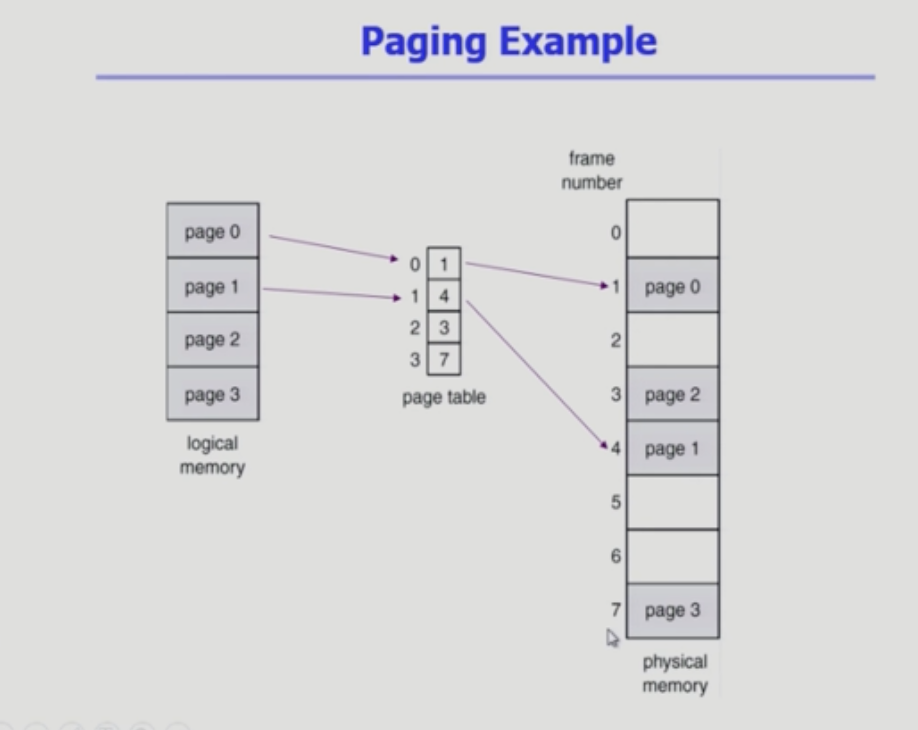
- physical memory 또한 동일한 크기의 frame으로 나눔
- 페이지를 담기 위한 공간이므로 page가 아닌 frame이라고 불림
- logical memory를 동일 크기의 page로 나눔 (frame과 같은 크기)
- 모든 가용 frame들을 관리
- page table 을 사용하여 logical address를 physical address로 변환
외부 조각발생 안함내부 조각발생 가능
- physical memory 또한 동일한 크기의 frame으로 나눔
Address Translation Architecture

- CPU는 논리적인 주소를 바라본다. P: 페이지 번호 d: 페이지 시작 위치로 부터 떨어진 offset
- 32비트 주소체계를 많이 씀 (최근엔 64비트로 구성됨)
그렇다면 프로그램의 최대 크기는?
- 메모리에 매겨지는 주소는 바이트 단위로 매겨짐
- 1비트면 서로 다른 2바이트 구분 가능. 2비트라면 서로 다른 4바이트 구분 가능
- 따라서 32비트면 서로 다른 2^32바이트를 구분할 수 있음
- 2^10 : KB / 2^20 : MB / 2^30 : GB
- 즉 프로그램은 최대 4GB
- 여기서 페이지 단위는 4KB이므로 페이지는 총 2^20(=
1MB)개가 나올 수 있음
Implementation of Page Table
- Page table은 main memory 에 상주
- Page-table base register (PTBR)가 page table을 가리킴
- Page-table length register (PTLR)가 테이블 크기를 보관
- 모든 메모리 접근 연산에는 2번 의 memory access 필요 (속도 저하)
- page table 접근 1번, 실제 data/instruction 접근 1번
- 속도 향상을 위해
- associative register 혹은 translation look-aside buffer (TLB)라 불리는 고속의 lookup hardware cache 사용
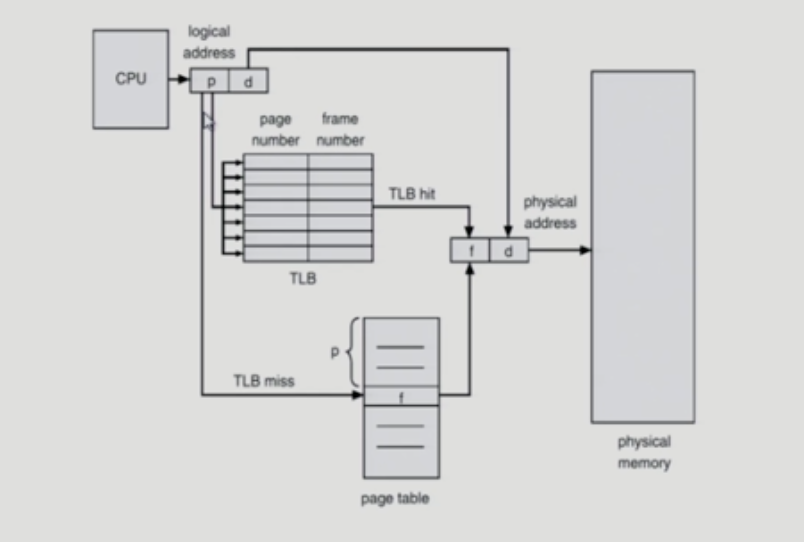
- TLB hit / TLB miss
- TLB는 page table의 일부를 담고 있고, logical memory와 physical memory를 쌍으로 갖고 있음 (page table의 경우 idx가 곧 logical memory를 나타냈기 때문에 인덱스에 대응하는 physical memory만 갖고 있었음)
- 따라서 TLB는 모든 테이블을 순차적으로 탐색하며 현재 logical memory에 대응하는 쌍이 있는지 찾아봐야하는데, 시간이 오래 걸리므로 병렬적으로 탐색할 수 있어야함 -> HW의 도움 필요 ->
associative register
- associative register 혹은 translation look-aside buffer (TLB)라 불리는 고속의 lookup hardware cache 사용
Associative Register
- parallel search가 가능
- page table 중 일부가 associative register에 보관되어 있음
- 만약 해당 page#이 associative register에 있는 경우 곧바로 frame을 얻음
- 그렇지 않은 경우 main memory에 있는 page table로 부터 frame을 얻음
- TLB는 context switch할 때 flush됨 (remove old entries)
- 프로세스 마다 page table를 갖고 있기 때문임
Effective Access Time
TLB 접근 시간= 엡실론메모리 접근 시간= 1Hit ratio= 알파 (associative resigster에서 찾아지는 비율)
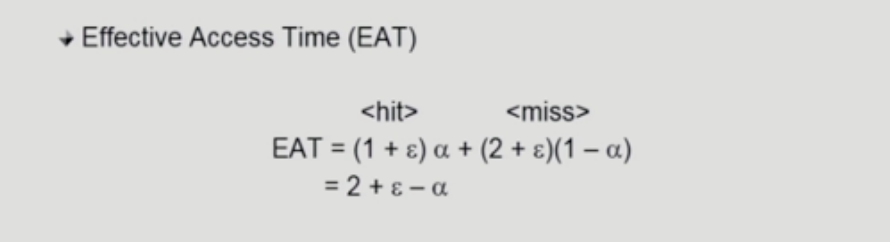
- hit는 메모리 1번, miss는 메모리를 2번 접근하는 것을 알 수 있음
Two-Level Page Table
- 32 비트 주소 체계 사용시 프로그램은 최대 4GB의 주소 공간을 갖게 됨
- page size가 4KB라면 1MB개의 page table entry가 필요함
- 각 page entry가 4B라면 프로세스당 4MB의 page table이 필요
- 그러나 대부분의 프로그램은 4G의 주소 공간 중 지극히 일부분만 사용하므로 page table 공간이 심하게 낭비 됨
- 해결책 (two-level page table)
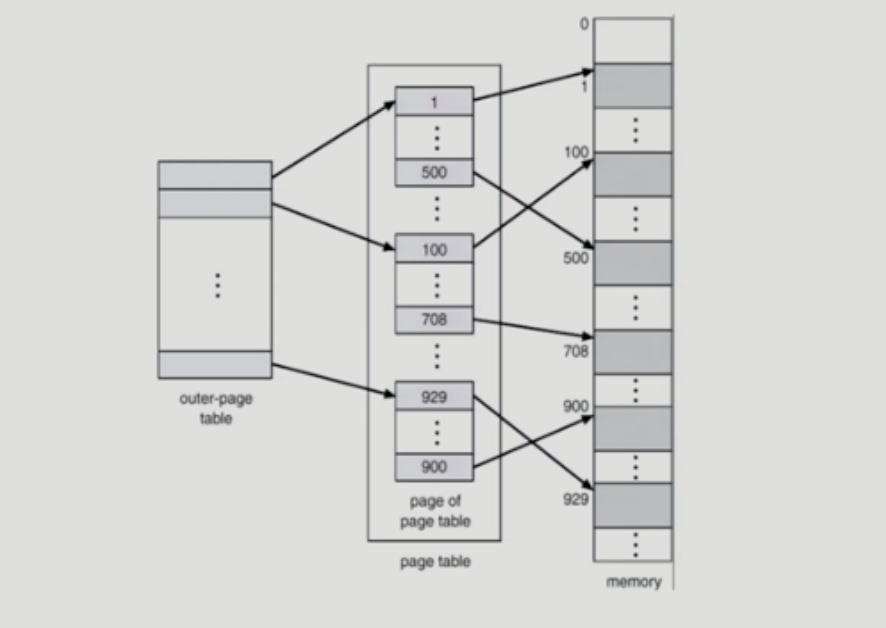
- page table 자체를 page로 구성
- 사용되지 않는 주소 공간에 대한 outer page table의 엔트리 값은 NULL (대응하는 innter page table이 없음)
Two-Level Paging Example
- logical address (32비트 주소 체계, 4K page 크기)의 구성
- 20bit의 page number
- 12bit의 page offset
- 4K를 각각 가리킬 수 있어야함. 2^2*2^10=2^12이므로 offset을 나타내기 위해선 12 bit가 필요함
- page table 자체가 page로 구성되기 때문에 page number는 다음과 같이 나뉜다

- 내부 페이지 테이블은 각각 4K이고, 각 엔트리는 4B이므로 1K개 존재. 이를 각각 가리킬 수 있어야하므오 10 bit가 필요
- 즉, P1은 outer page table의 idx이고, P2는 outer page table의 page에서의 변위이다.
Address-Translation Scheme
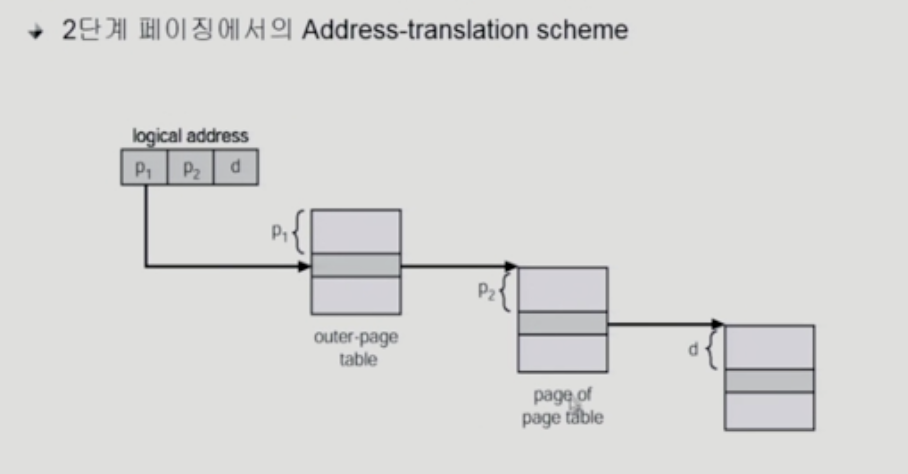
Multilevel Page and Performance
- address space가 더 커지면 다단계 페이지 테이블 필요
- 각 단계의 페이지 테이블이 메모리에 존재하므로 logical address의 phhysical address 변환에 더 많은 메모리 접근이 필요함
- TLB를 통해 메모리 접근 시간을 줄일 수 있음
- 4단계 페이지 테이블을 사용하는 경우

Valid / Invalid bit in a Page Table

- 해당 페이지가 실제 메모리에 올라가있는지 확인하기 위해 bit를 추가함
- 특정 페이지의 비트가 i라면 디스크에 swap out되었음을 의미함
Memory Protection
- Page table의 각 entry 마다 아래의 bit를 둔다
- Protection bit
- page에 대한 접근 권한 (write/read/read-only)
- ex. code로 이루어진 page는 read만 가능함
- page에 대한 접근 권한 (write/read/read-only)
- Valid/Invalid bit
- valid : 해당 주소의 frame에 그 프로세스를 구성하는 유효한 내용이 있음을 뜻함 (접근 허용)
- invalid : 해당 주소의 frame에 유효한 내용이 없으을 뜻함 (접근 불허)
Inverted Page Table
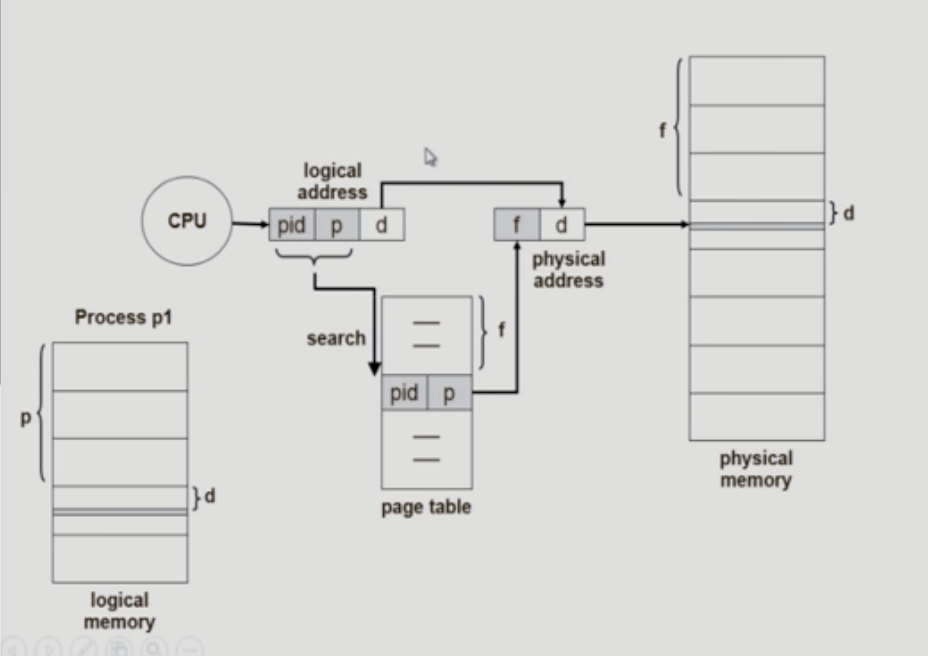
- 기존의 page table이 매우 큰 이유
- 모든 process 별로 그 logical address에 대응하는 모든 page에 대해 page table entry가 존재
- 대응하는 page가 메모리에 있는 아니든 간에 page table에는 entry로 존재
- 역방향(뒤집힌) page table
- page frame 하나 당 page table에 하나의 entry를 둔 것 (system-wide)
- 각 page table entry는 각각의 물리적 메모리의 page frame이 담고 있는 내용 표시 (pid,p)
- 단점
- 테이블 전체를 탐색해야 함
- 조치
- Associative register 사용 (expensive)
Shared Page
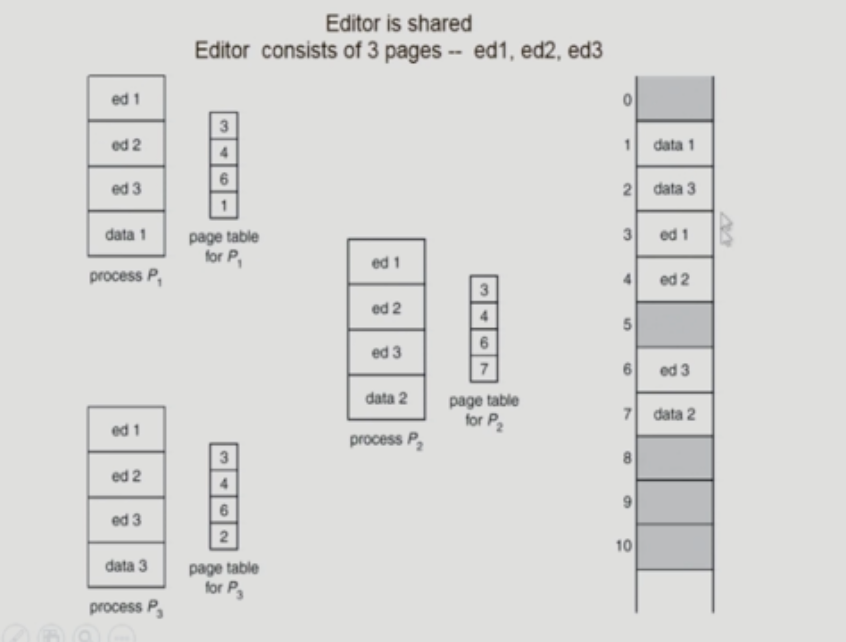
- 동일한 프로그램에 대한 프로세스가 위와 같이 3개 생성되었을 때 code영역의 page는 동일한 내용을 담고 있는 페이지이므로 중복되는 문제가 발생한다.
- shared code
- Re-entrant Code (=Pure code)
- 조건 1: read-only로 하여 프로세스 간에 하나의 code에만 메모리에 올림
- 조건 2: shared code는 모든 프로세스의 logical address space에서 동일한 위치에 있어야 함
- shared memory와는 전혀 다른 개념임 ❌
2. Segmentation
-
의미(code, data, stack) 단위인 여러 개의 segment로 구성
- 작게는 프로그램을 구성하는 함수 하나하나를 세그먼트로 정의
- 크게는 프로그램 전체를 하나의 세그먼트로 정의 가능
- 일반적으로는 code, data, stack 부분이 하나씩의 세그먼트로 정의됨
-
segment는 다음과 같은 logical unit 들임
main() function global variables stack symbol table, arrays
Segmentation Architecture
-
logical address는 다음의 두 가지로 구성됨
segment-numberoffset
-
segment table
- 각 테이블 entry
- base : starting physical address of the sement
- limit - length of the sement
- Segment-table base register (STBR)
- 물리적 메모리에서의 segment table의 위치
- Segment-table length register (STLR)
- 프로그램이 사용하는 segment의 수
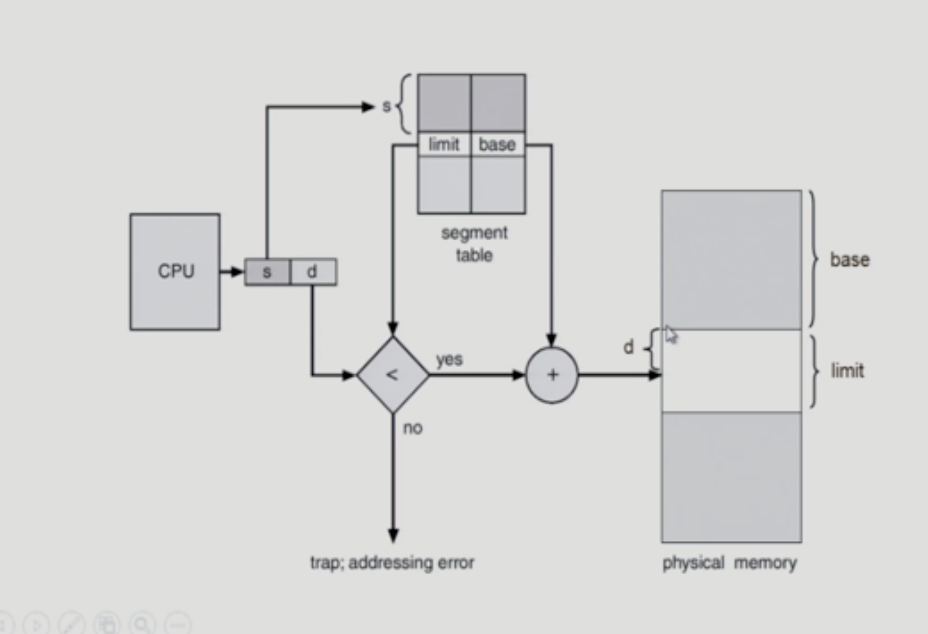
- 각 테이블 entry
-
위 그림과 같이 segment table은 limit 변수가 추가됨 (segment는 각각 크기가 다르기 때문에 그 길이를 알고 있어야 하기 때문)

-
protection
- 각 세그먼트 별로 proetection bit가 있음
- Each entry
- valid vit = 0, illegal segment
- Read/Write/Execution 권한 bit
-
Sharing
- shared segment
- same segment number
- Allocation
- first fit / best fit
- external fragmentation 발생
- segment의 길이가 동일하지 않으므로 가변분할 방식에서와 동일한 문제점들이 발생
segment는 의미 단위이기 때문에 공유(sharing)와 보안(protection)에 있어 paging보다 훨씬 효과적이다.
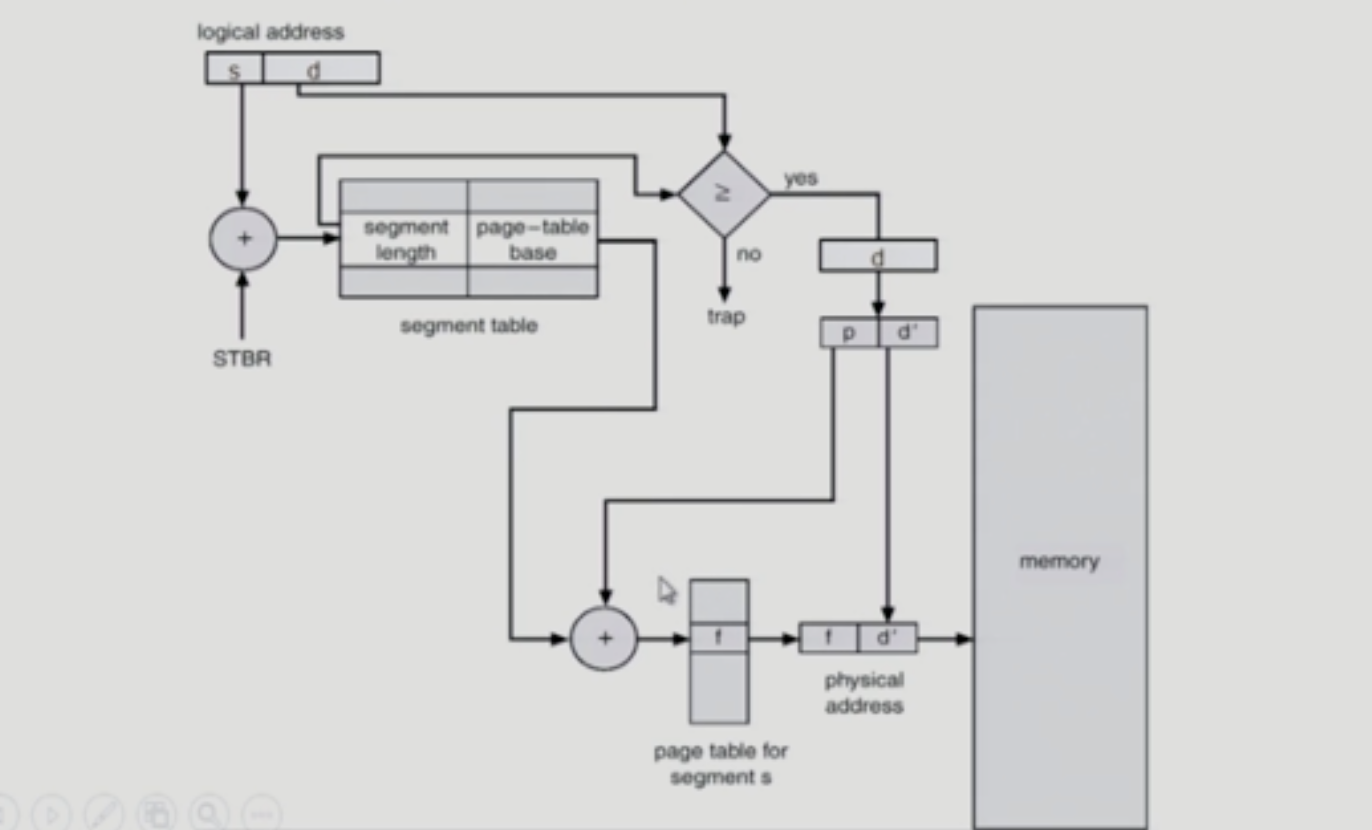
3. Paged Segmentation
- pure segmentation과의 차이점
- segment-table entry가 segment의 base address를 가지고 있는 것이 아니라 segment를 구성하는 Page table의 base address를 가지고 있음

둔한 붓이 총명함을 이긴다