이전 포스팅에서 데이터를 삽입한 후 SELECT라는 명령문을 사용했는데 이는 바로 데이터를 조회하는 명령문입니다.
SELECT * FROM customers;위는 customers라는 테이블에 있는 모든 데이터를 조회할 수 있습니다.
SELECT column1, column2, ... FROM <테이블 이름>;SELECT 이 후, 칼럼명을 사용하여 특정 칼럼에 삽입된 데이터를 조회할 수 있습니다.
예를 들어, 이름 칼럼과 이메일 칼럼을 조회하려면 다음과 같은 명령문을 치면 됩니다.
SELECT name, email FROM customers;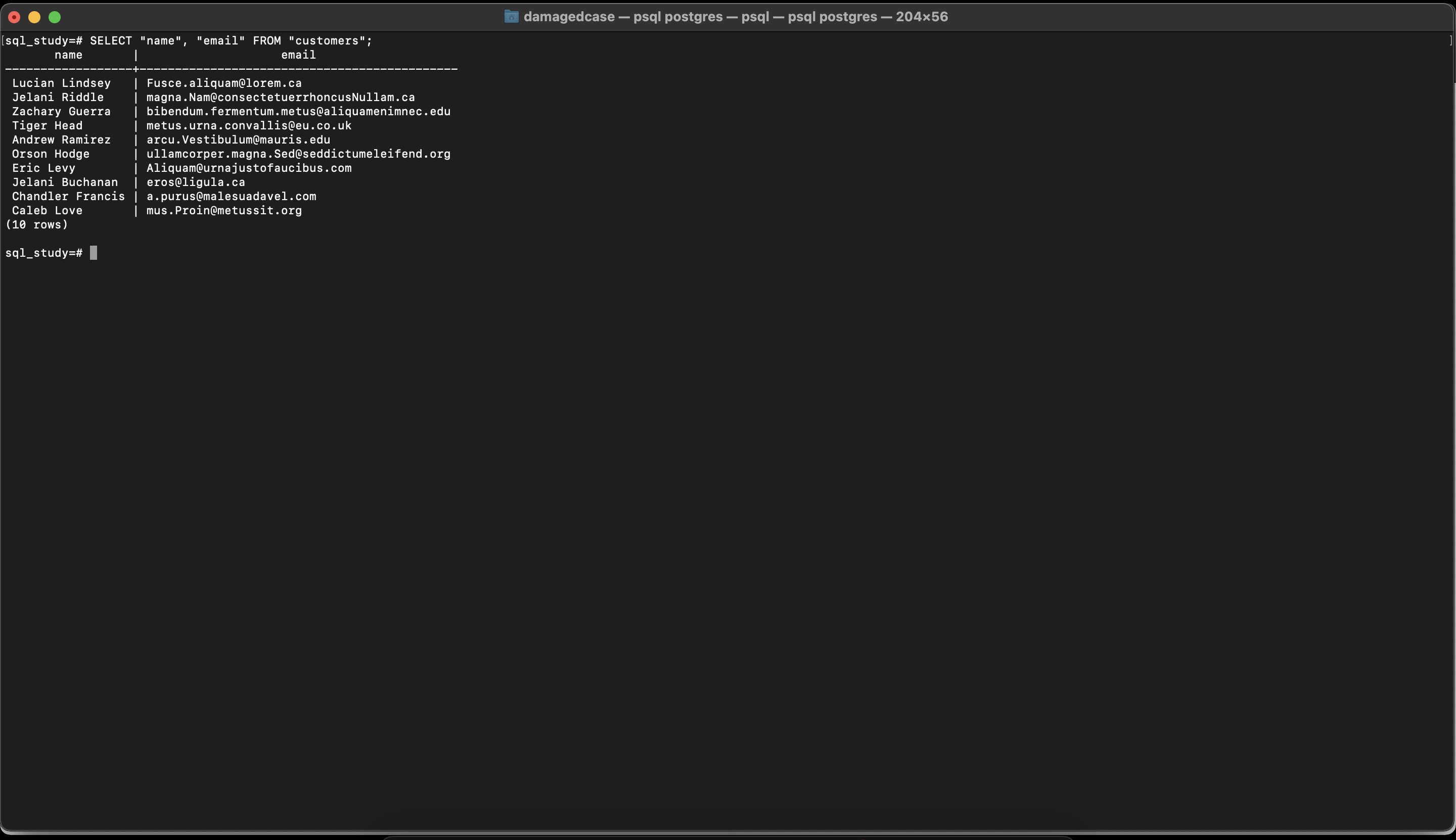
또한, SELECT DISTINCT란 명령문을 사용하여 칼럼에 있는 중복된 기록이 아닌 고유의 값들을 조회할 수 있습니다.
INSERT INTO "customers" ("name", "address", "mobileno", "email", "bod") VALUES ('Lucy Lindsey','157-2520 Mauris Avenue','(07745) 6435470','lucy.lindsey@lorem.ca','Jun 28, 2021');이를 확인해서 첫 번째 데이터와 동일한 address를 가지고 있는 데이터를 삽입하겠습니다.
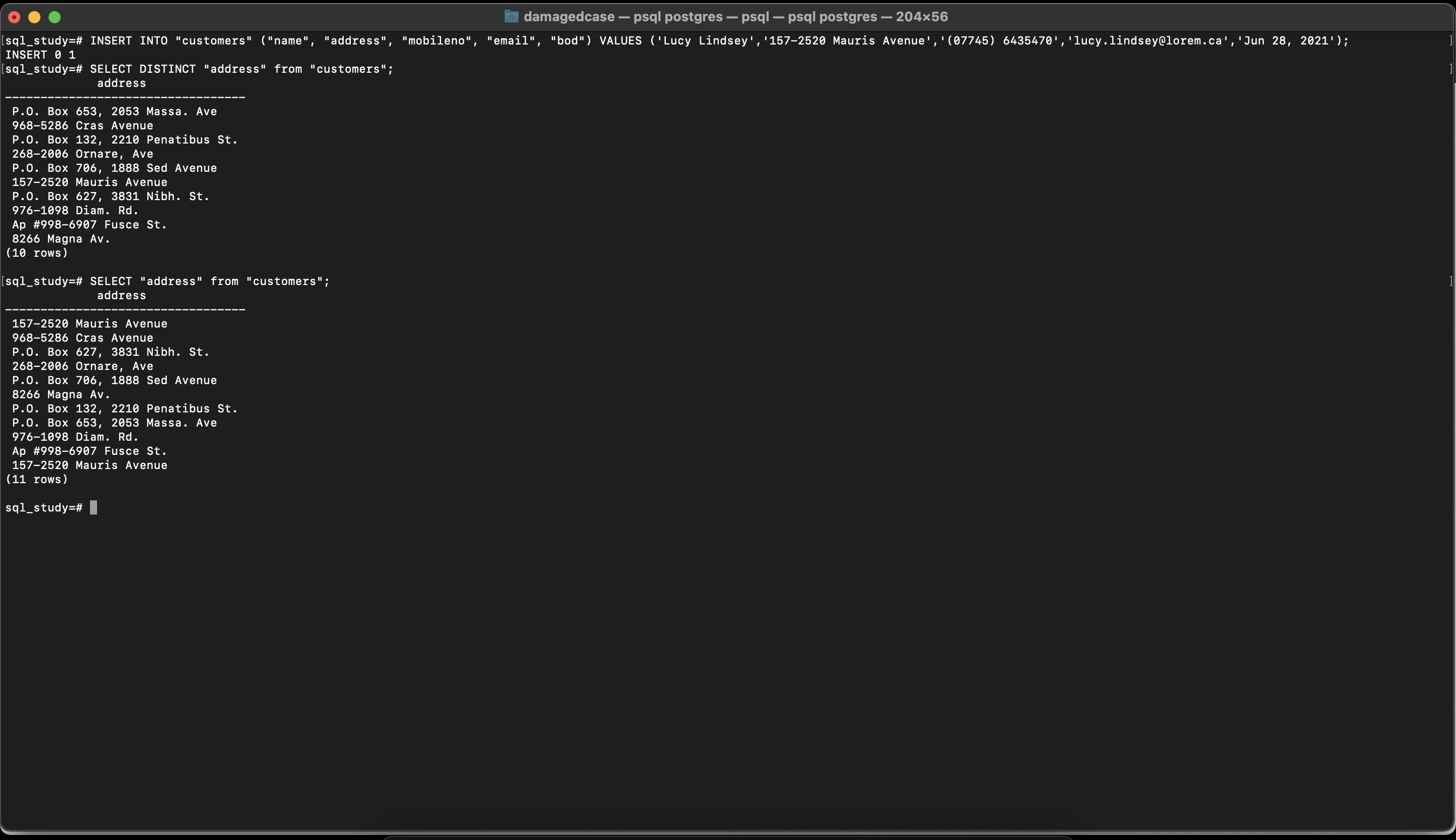
SELECT DISTINCT address from customers;위에 명령문을 썼을 때 총 11개의 데이터 중에 10개만 조회되는걸 볼 수 있는데 이는 address란 칼럼으로부터 고유한 값만 가지고 있는 데이터를 조회했기 때문입니다.
SELECT address from customers;DISTINCT를 명령문에서 뺀 경우에는 총 11개의 데이터가 조회되는 것을 확인할 수 있습니다.

성장을 추구하는 개발자