What is Knowledge Graph?
Knowledge Graph (KG)
- 구글에 의해 정의된 용어 (구글이 만든 건 X, 원래부터 있었음)
- schema로 정의된 interconnected entity들의 지식 베이스(KB)
Three levels of knowledge
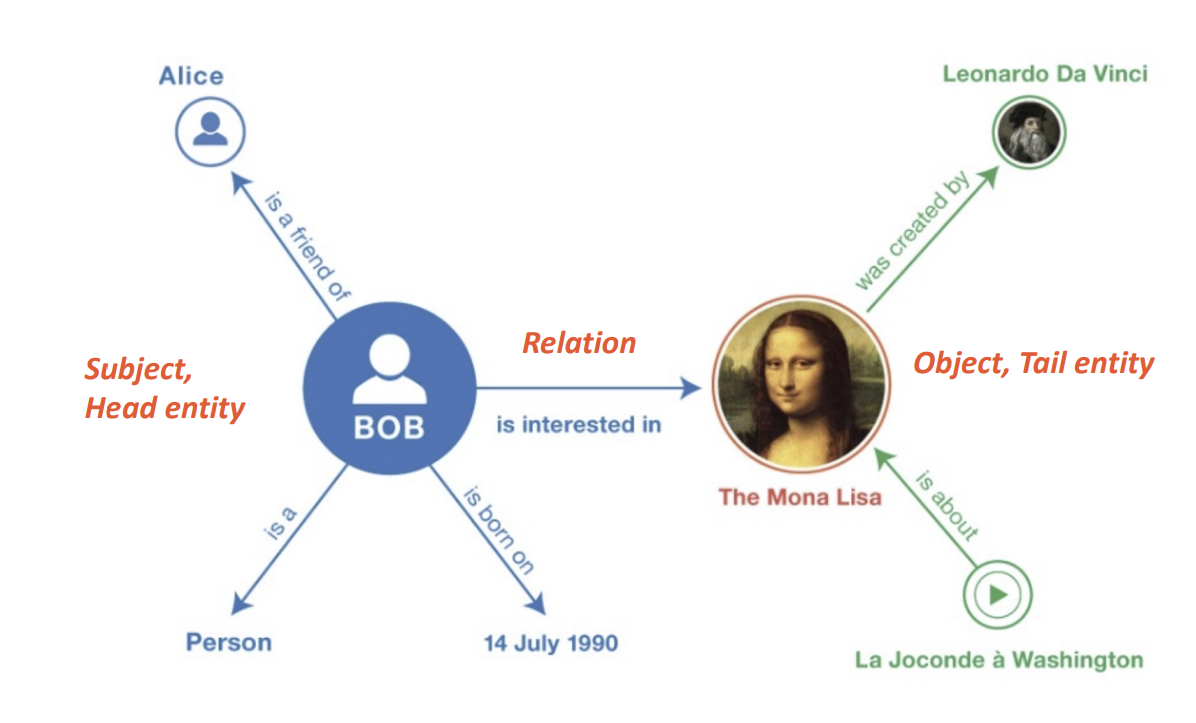
- Entity
- BOB, The Mona Lisa
- 아직은 의미있는 정보를 가지지 못함
- Tripe (unit of a multi-relational graph)
- BOB, is interested in, The Mona Lisa
- 사람마다 다르게 생성 → 공통된 약속이 필요
- too simple → 이용하기 어려움
- Schema (defining the vocabulary)
- 공통의 약속-
기계가 읽고 사용할 수 있는 형태
-
여러 곳에서 사용 가능, 오픈소스화
-
Motivation
- web의 world knowledge를 표현
- 현재의 웹을 web of data로 convert하는 데 도움
- 기계가 이해할 수 있는(machine-understandable) web을 구현하기 위해 고안
- 여러 application에서 data를 combining하여 new information을 도출
Application
- 구글 검색, 유튜브 추천, Fraud Detection …
그래서 KG란??
- set of standards
- node, triple, schema 등을 어떻게 표현할지 표준을 정함
- defines best practices for sharing data over the wed for use by application
- 정보를 공유하기에 최고로 실용적
- allows defining the semantics of data
- 데이터의 시멘틱을 정의 가능. 웹에 있는 데이터(테이블, 일반적인 DB 등)는 시멘틱을 갖지 않음. 사람이 상식으로 해석할 뿐. 따라서 모두가 읽고 사용하려면 규칙 필요.
- ex) spouse is a symmetric relations
zip codes are a subset of postal codes
“sell” is the opposite of “buy”
- Semantic descriptions of entities and their relationships
- 주석이 달려 있으며 알아보기 쉽게 명명함
- Uses a knowledge representation formalism
(RDF, RDF-Schema, OWL)
- Entities : real world objects and abstract concepts
- 모든 노드가 엔티티는 아님. 모든 노드의 부분집합이 엔티티. 엔티티가 아닌 노드도 존재함. 중요한 것들, 가치있다고 생각되는 것들이 엔티티가 됨(정의하기 나름)
- 엔티티가 아닌 노드는 literal value (string)
- Relationships : graph-based data model where relationships are first-class
- Semantic descriptions : types and properties with a well-defined meaning (e.g. through an ontology)
- relation에 붙여 있는 label. 그래프에서 semantic을 설명해줌
- Possibly axiomatic knowledge (e.g. rules) to support automated reasoning
- 더 이상 쪼개기 힘든 작은 knowledge. 다양하게 활용하기 위해 정보를 최대한 쪼개 놓음
Example of Knowledge Graph
Google Knowledge Graph
- entity search and summarizations - entity 차원 검색
- discovering related entities - relation 차원 검색
- factual answers - schema 차원 검색
Key benefits
- 옳은 정보를 찾을 수 있음
- 새로운 정보를 추가하고 확장하기 용이
- 언어 모델보다 정확한 정보 제공
- 최고의 summary 제공
- 구조화 되어있기 때문에 더 깊고 넓게 정보 탐색 가능
Amazon
- Alexa 인공지능 스피커
- billions of entities
- combining heterogeneous knowledge sources
- provide answers to customer queries
- Product Graph
- AutoKnow
- 새로운 정보를 넣어주면 자동으로 지식그래프 생성. 사람이 일일히 연결해 줄 필요 없음
Microsoft
Key benefit
- Enterprise KG provides connected data supporting people at work
- Personalized search
Many Semantic Web components (e.g. RDF and SPARQL) are used in various domains:
• Semantic Search (Google, Microsoft, Amazon)
• Smart Governments (data.gov.us, data.gov.uk)
• Pharmaceutical Companies(AstraZeneca) 제약회사
• Automation (Siemens)
• Mass Media (Thomson Reuters)
Knowled Graph API (Open-sourced KGs) ↔ Private KGs
Data Model in Knowledge Graph
왜 Graph인가?
- 지식을 structured하고 formal하게 보여줘야 함
- relation으로 연결된 entity들에 둘러싸여 있음
- Graph는 entity와 relationship을 보여주는 자연스러운 방법
- Graph는 효과적으로 관리될 수 있음
Semantic Networks
KG의 원시 형태
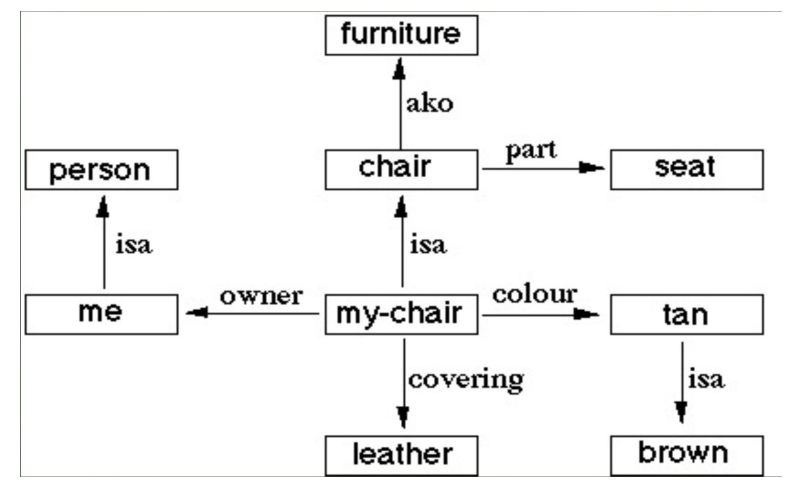
- 문장에 있는 단어의 의미를 분석하기 위해 제시됨 (1950s-60s)
- Memory like structure to store and access knowledge by machines
- Basic notations
- Node : object, concept, situation
- Edge : relationship
- 장점
- 계층 추적이 쉬움
- 연관성 추적이 쉬움
- flexible
- 단점
- No well defined syntax
- No formal semantic
- label의 의미를 define하기에 충분히 expressive하지 않음
- 비효율적
→ Description Logic으로 발전 (underpinning of the W3C OWL standard)
Knowledge Graph: Going beyond Semantic Network
- Key KG Standards
- standard : RDF
주어, 술어, 목적어의 triple - schema standard : OWL, based on Description Logics (DL)
- query language standard : SPARQL
- standard : RDF
- Example KG in DL
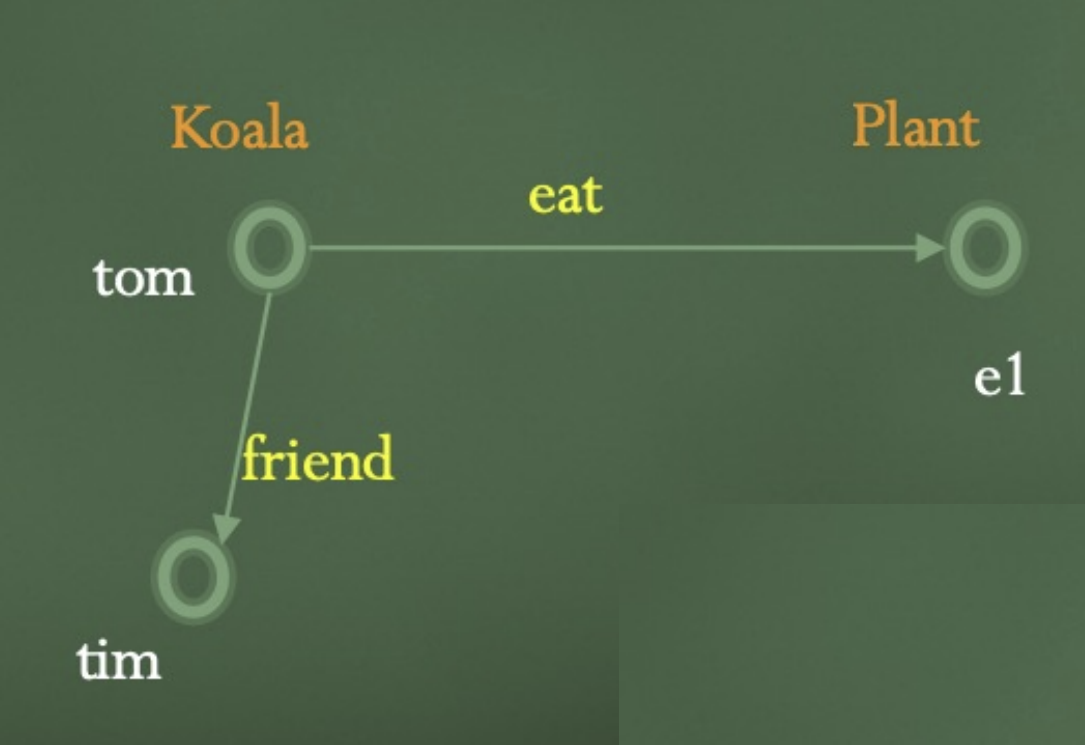
- Abox (data):
tom:Koala,e1:Plant,(tom,tim):friend,(tom,e1):eat - Tbox (schema/ontology):
Koala ⊑ ∀eat.Plant
상식, 개념
- Abox (data):
- RDF (W3C standard for Knowledge Graph)
- formal syntax. such as meta-properties (
rdf:type,
rdfs:subClassOf) - formal semantics
- NOT able to define classes → OWL 필요
- formal syntax. such as meta-properties (
- Data sub-graph
- [dbr:Barack_Obama rdf:type dbo:President .][dbr:Barack_Obama dbo:birthplace dbr:Hawaii .]
[dbr:Barack_Obama dbo:spouse dbr:Michelle_Obama .]
- [dbr:Barack_Obama rdf:type dbo:President .][dbr:Barack_Obama dbo:birthplace dbr:Hawaii .]
- Schema sub-graph
- dbo:President ⊑ dbo:Politician
RDF Resource Description Framework
resource → URI(통합 자원 식별자)
- standard for representing knowledge
- triple이라는 list of statements로 표현
- Triple : SUBJECT, PREDICATE, OBJECT
- ex. (”Muhammad Ali”, “isA”, “Boxer”)
- Graph in RDF
- directed
- edge-labelled (단순 숫자가 아닌 semantic을 가짐)
- multi-graph의 엄격한 형태 (multiple edge가 같은 vertices 사이에 존재 가능, only if they have different labels)
RDF Model
-
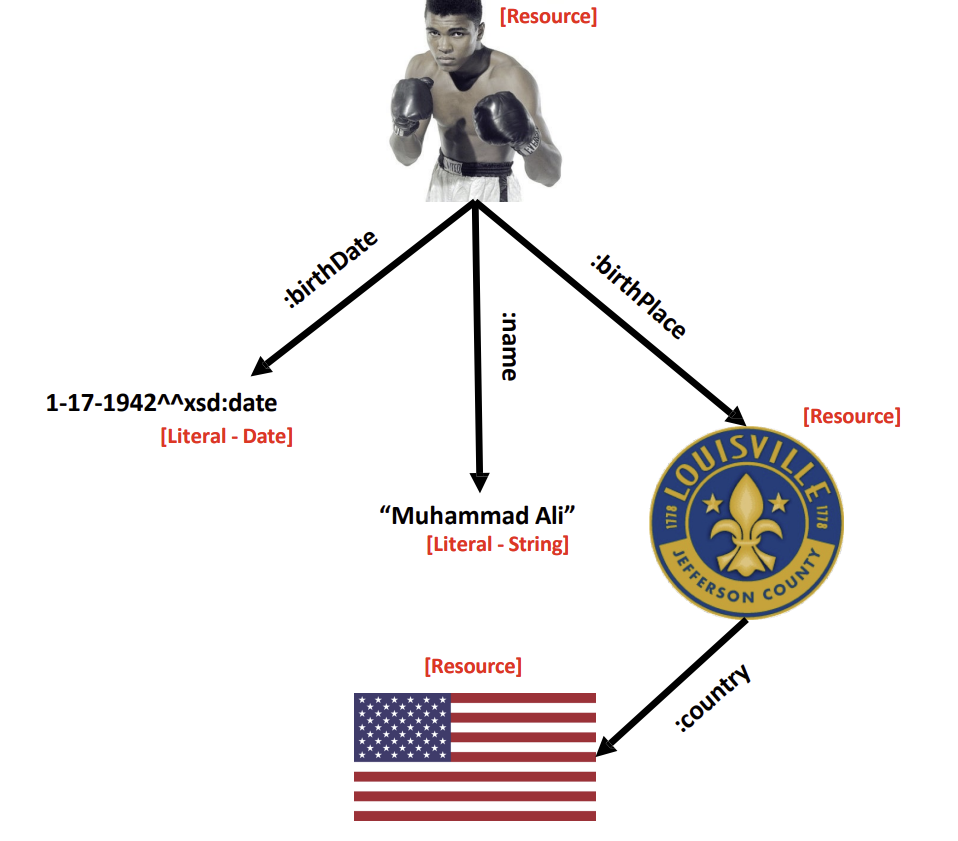
Triple(or triplet) Structure
- subject, predicate, object가 resource나 literal으로 표현
-
resource: URI (named thing으로 denote)
<http://dbpedia.org/resource/Muhammad_Ali>또는:Muhammad_Ali
-
literal: string, number
-
- Literals representing values other than strings may have an attached datatype
- subject, predicate, object가 resource나 literal으로 표현
-
Vocabularies
- vocabulary can be created or reused
- existing vocabularied (e.g. Friend of a Friend - FOAF) are stored using, e.g., RDF schema (RDFS)
- The RDF Vocabulary Description Language (RDF Schema) allows describing vocabularies
- RDF Schema allows defining properties or new classes of resources
-
Mapping on Data to Ontologies
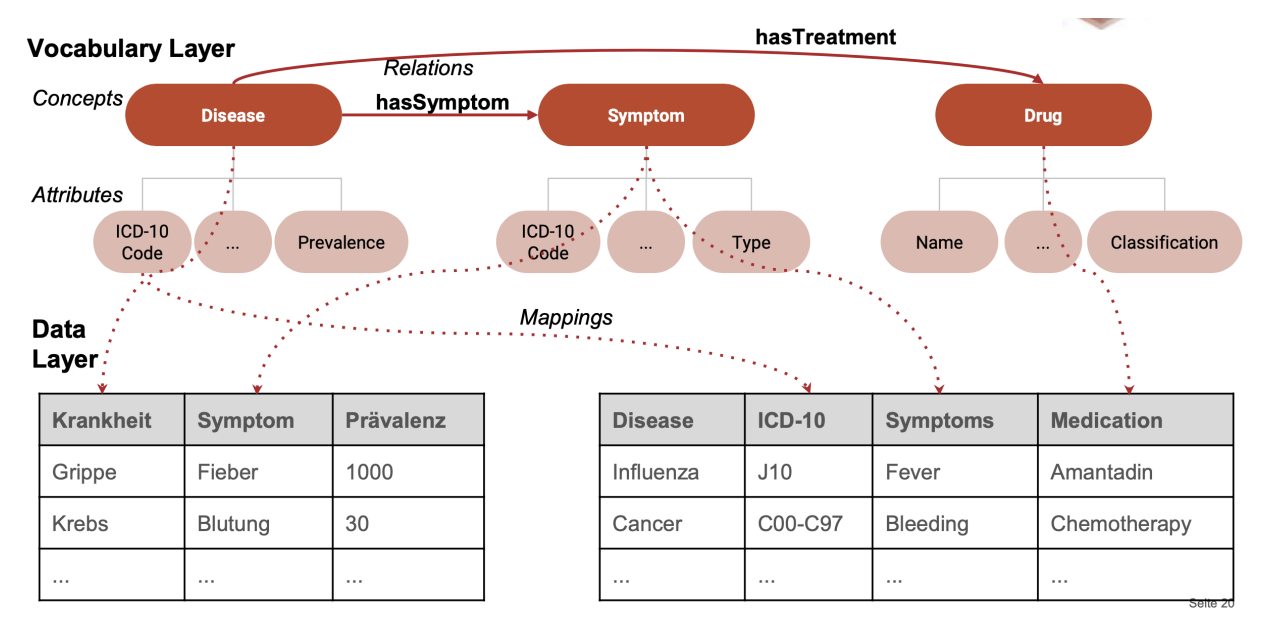
OWL Web Ontology Language
- key technology for defining semantics for RDF data
- OWL extends RDFs to define ontologies
- ontology
- formal definition of set of vocabulary that define relationships between vocabulary term and class members
- describe domain knowledge → users are able to more formally share and understand data
- ontology of OWL is a collection of triples
Knowledge Graph Construction
- 사람이 한땀한땀 만들기 → 한계…
- 데이터에서 온톨로지에 맞게 자동으로 생성
text to Knowledge Pipleline System (Kakao)
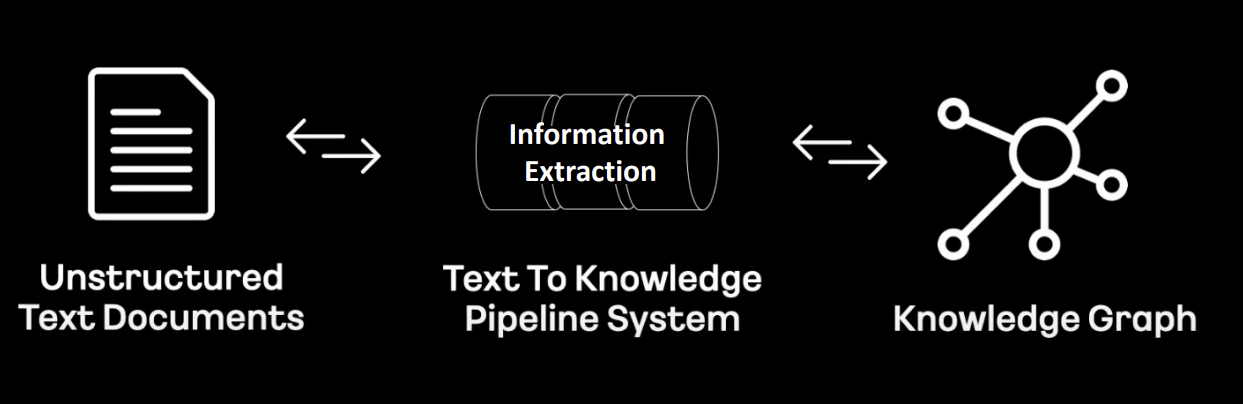
unstructured text doc → pipeline → KG
- pipleline: 여러 가지 모듈이 순차적으로 결합된 것
Information Extraction
- Named Entity Recognition 웹에 있는 비구조화된 문서를 KG로 만들고 싶음. 일단 그 문서에서 무엇이 entity인지 알아야 함. 줄글에서 Steve Jobs, Steve Wozniak, Apple을 추출하고 타입(PERSON, ORG) 역시 찾아줌
- Relation Extraction entity를 찾았으면 이제 관계를 찾아야 함. 예전에는 pattern matching으로 찾음. 지금은 질의응답 방식으로 찾음. 챗지피티한테 물어본다든지…
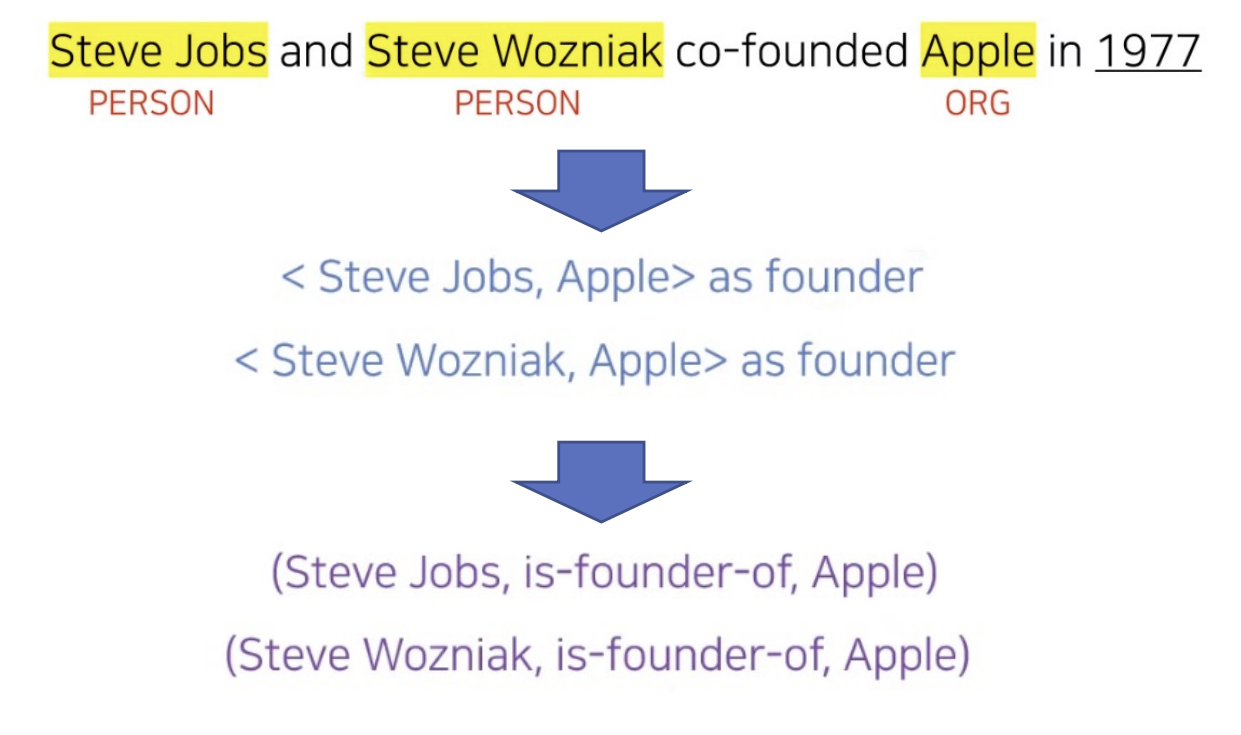
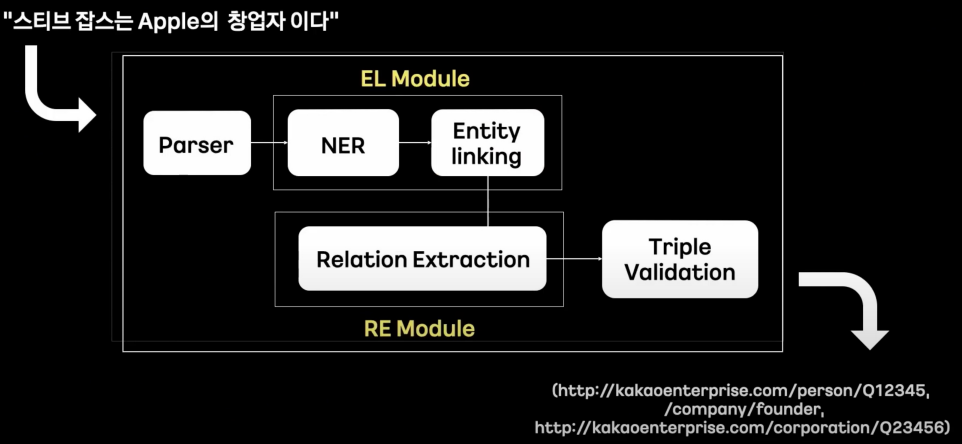
Parser : 글자를 의미 있는 토큰(기계가 읽는 최소 단위)으로 쪼갬.(Tokenization) → 토큰과 토큰의 관계를 그래프로 연결
→ NER (Named Entity Recognition) : entity 찾음 (아직 의미는 알지 못함)
→ Entity Linking : 리소스화 하기 위해 URI 연결
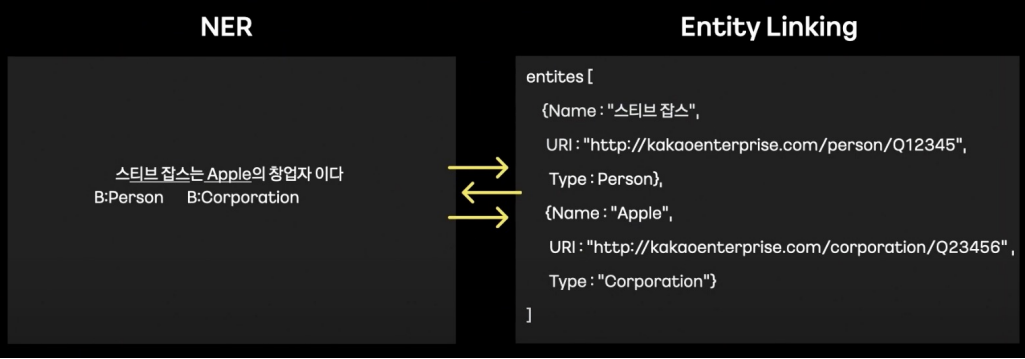
Entity Linking Module
→ Relation Extraction : 관계를 보여줌

Relation Extraction Module
→ Triple Validation : 만들기 나름. 이미 있는 KG에 비슷한 게 있는지 검색해본다던지… 모순적인 내용이 있는지 보든지… 지지해주는 web 문서가 얼마나 많은가…
Wikidata (Wikipedia)
- Collecting structured data
- Collaborative
- Free
- Large
DBpedia
KG Construction from (Web) Tables
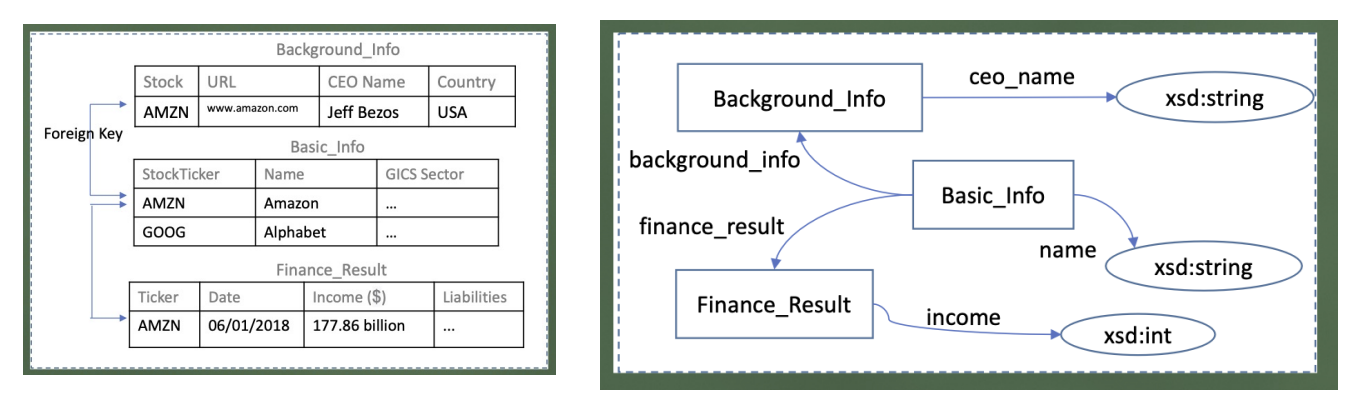
- (Web) Table understanding
- Extraction of Web tables: HTML tables, attribute-value pairs (such as info box), entity lists
- Alignment with KG schema
- Column type prediction
- Table enhancement
NELL: Never Ending Language Learner
자동으로 평생 학습이 되도록 만들고 싶음.
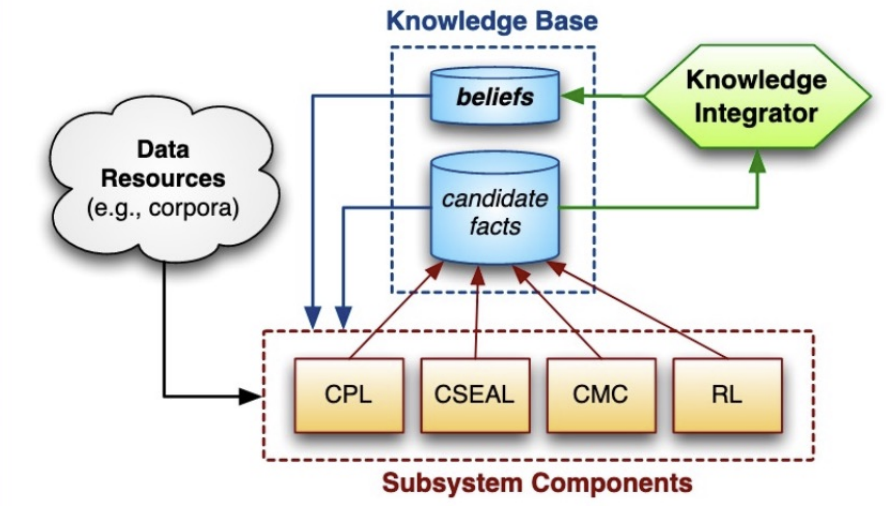
- Goals
- Extract information from Web texts to construct KB
- Learn to read better than before
- Inputs
- Schema with 800 types and relation
- 10 – 20 seed examples for each
- Output
- continuously growing KB
- Key methods
- Coupled Pattern Learner (CPL)
- Coupled SEAL (CSEAL)
- Coupled Morphological Classifier (CMC)
- Rule Learner (RL)
Applications of Knowledge Graph
Knowledge Graphs Enabling Intelligent Applications
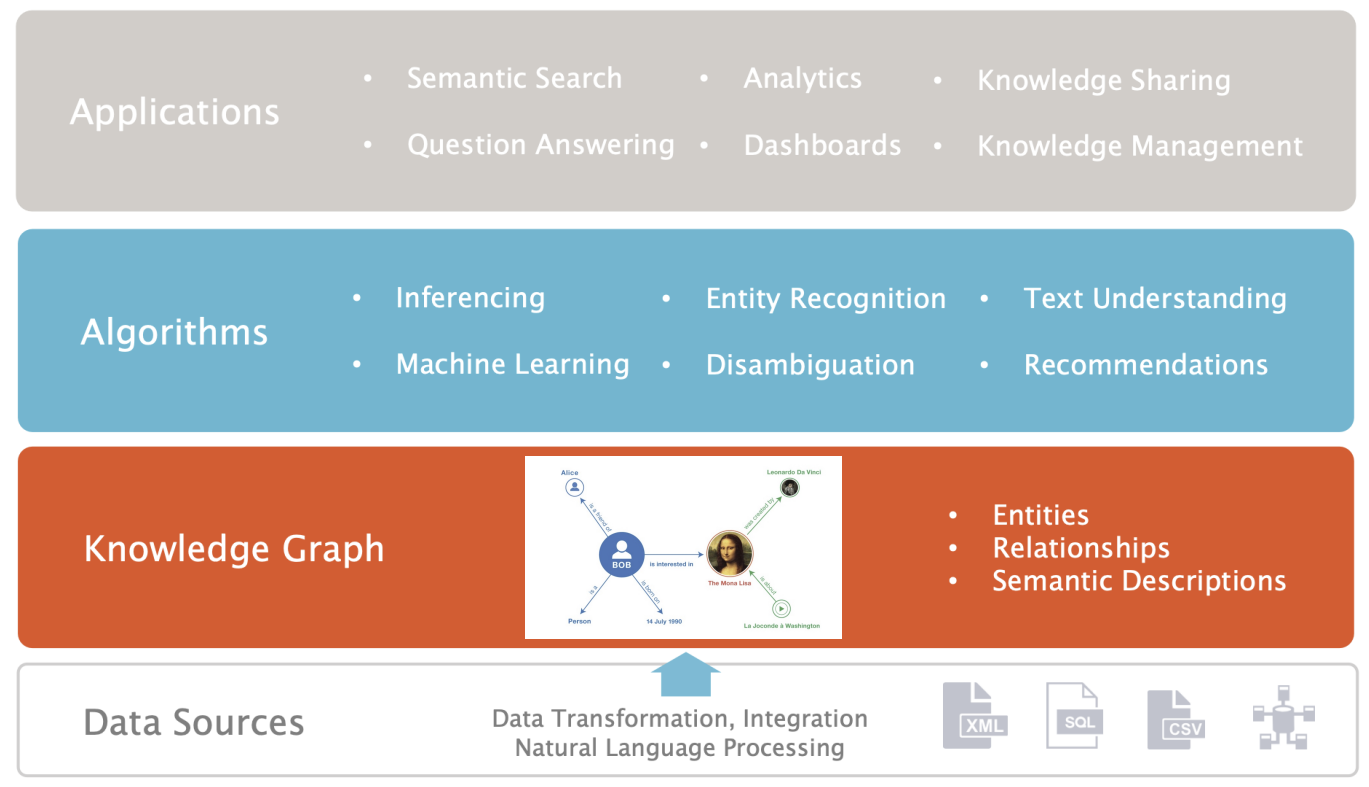
text understanding 자연어 처리, 이해
disambiguation 이 apple이 과일인지 회사인지… entity linking할때
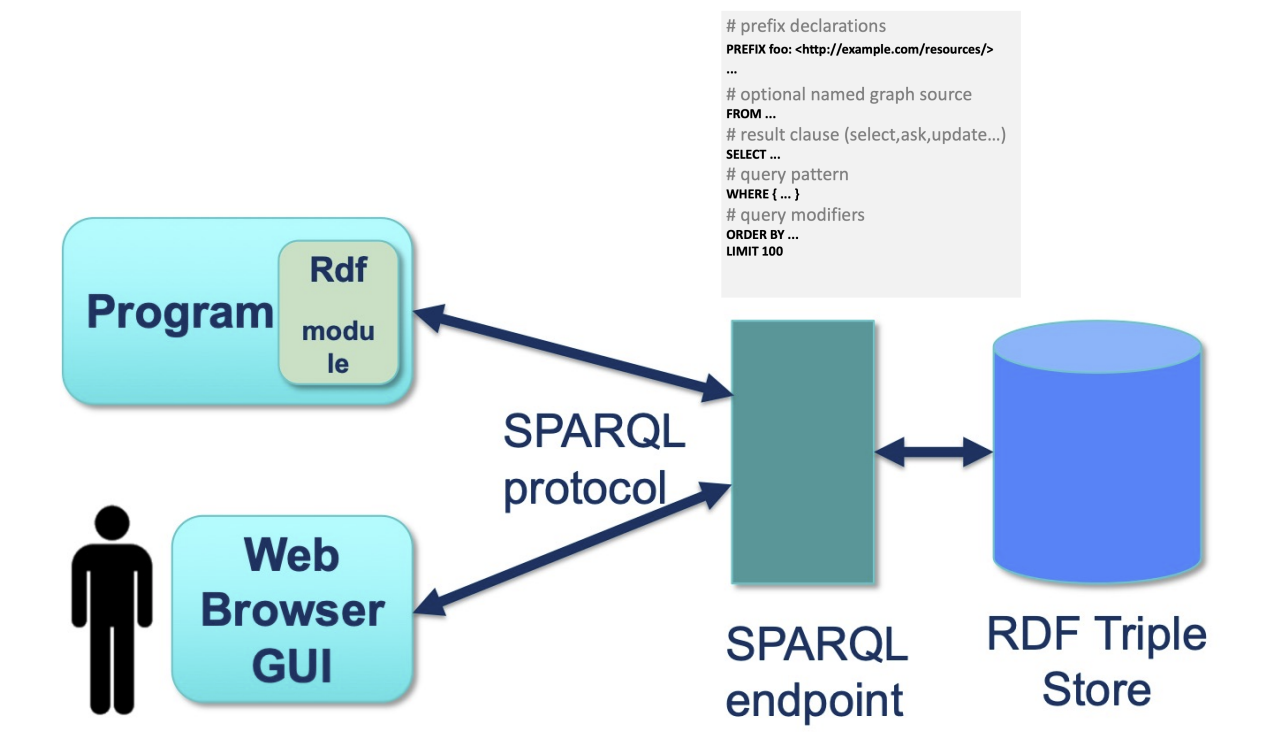
KG Querying with SPARQL
- SPARQL : standard query language of and standard protocol for querying KGs
DB언어. 정보를 찾아오는 데 사용
Reasoning with KG
- Infer implicit knowledge from explicit knowledge
삼단논법같은거… 정보를 타고타서 얻을 수 있는 정보
Review
Explain the concept of a "Triple" in a Knowledge Graph and why a common agreement or standard is needed for creating them.
Triple은 지식 그래프에서 중요한 요소 중 하나로 엔티티와 그들 간의 관계를 나타내는 데 사용된다. 주로 Subject(주어), Predicate(동사), Object(목적어)로 표현된다. 여러 사람이 만든 데이터를 통합하고, 기계가 이해할 수 있게 하고, 다양한 곳에서 활용하려면 Triple의 공통된 약속(standard)가 필요하다.
Discuss the motivation behind the development of Knowledge Graphs and how they contribute to converting the web into a "web of data."
지식그래프를 사용하면 방대한 웹의 지식들을 기계가 이해할 수 있는 형태로 표현할 수 있고, 다양한 웹 데이터 소스에서 나오는 정보들을 일관되게 통합할 수 있고, 다양한 응용 프로그램에서 유용하게 활용할 수 있다.
Describe the role of "Semantic descriptions" in a Knowledge Graph and how they contribute to the understanding of entities and relationships.
Semantic descriptions은 지식 그래프 내의 엔티티와 관계의 의미와 성격을 명확하게 정의하고 설명하는 역할을 하며, 이를 통해 데이터의 이해와 활용을 개선한다.
Knowledge Graph에서 "axiomatic knowledge"이란 무엇이며, 왜 이것이 자동 추론을 지원하는 데 중요한가?
axiomatic knowledge는 지식 그래프에서 자동 추론을 지원하는 데 사용되며, 더 이상 분해되지 않는 작은 지식 조각을 나타낸다. 이러한 작은 조각은 자동화된 추론을 지원하고, 다양한 정보를 연결하거나 확장하여 새로운 지식을 도출할 수 있도록 해 준다. 예를 들어, “X는 Y의 부모”라는 axiomatic knowledge가 있다면, 지식 그래프에서 X와 Y의 관계를 자동으로 유도하여 “Y는 X의 자녀”라는 관계를 찾아낼 수 있다. 이를 통해 지식 그래프의 의미를 확장하고 새로운 정보를 발견할 수 있다.
"NELL: Never Ending Language Learner"의 주요 목표는 무엇인가?
웹 텍스트에서 정보를 추출하여 지식 베이스(Knowledge Base)를 지속적으로 확장하고, 읽기 능력을 향상시키는 것
Knowledge Graph 구축에서 "Table understanding" 단계에서 무엇을 수행하는가?
웹 테이블을 추출하고, Knowledge Graph 스키마와 일치시키고, 열 유형을 예측하며, 테이블을 향상시키는 작업을 수행한다.
Knowledge Graph의 주요 구성 요소 중 하나인 "Schema"은 어떤 정보를 포함하는가?
Knowledge Graph의 엔티티 및 관계 유형, 속성 및 메타정보를 포함한다.
Information Extraction 모듈과 Table understanding 모듈은 Knowledge Graph 구축에서 어떤 역할을 하는지 설명하시오.
Information Extraction 모듈: 비구조화된 텍스트 문서에서 엔티티와 관계를 추출하여 Knowledge Graph를 구축한다. 문서에서 중요한 정보를 식별하고 그 정보를 구조화된 형태로 변환합니다.
Table understanding 모듈: 웹 테이블을 이해하고 Knowledge Graph와 일치시킨다. 웹 테이블로부터 데이터를 추출하고 그 데이터를 Knowledge Graph에 통합하여 지식을 확장한다.
지식 그래프에서 "노드"는 무엇을 나타내는가?
노드는 지식 그래프에서 엔티티, 개념, 사건 또는 항목을 나타낸다.
