사용한 데이터셋: Red Wine Quality
https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009/data
실습한 코드:
https://github.com/2022148072/study/blob/main/ai_ass2/red-wine-quality-prediction.ipynb
1 데이터 확인
가) 변수 확인
입력 변수는 11개로, fixed acidity, volatile acidity, citric acid, residual sugar, chlorides, free sulfur dioxide, total sulfur dioxide, density, pH, sulphates, alcohol이 있다. 출력 변수는 quality이다.
와인의 품질(quality)은 3~8의 6개 정수 중 하나이며, 5와 6에 데이터가 몰려 있었다.
나) 상관분석
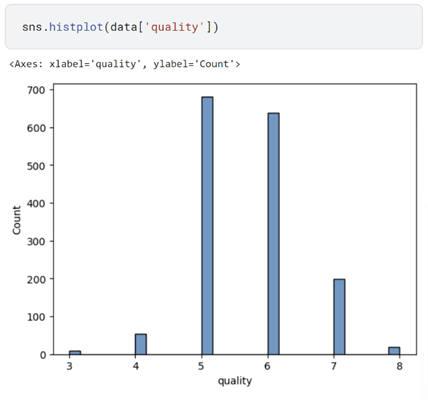
변수 간 상관관계를 확인하여 품질을 예측하기 좋은 입력 변수를 골라보려 한다. Pearson Correlation Coefficient는 두 변수 간 선형 상관관계를 수치화한 값이다. -1에서 +1까지로 나타나며 -1에 가까울수록 강한 음의 선형 상관관계를, +1에 가까울수록 강한 양의 상관관계를 나타낸다. 0일 경우 두 변수는 선형 상관관계가 없다.
각 변수끼리의 상관계수를 계산해 본 결과 alcohol 변수가 quality와 가장 큰 절댓값을 가지는 것으로 나타났다.
2 클러스터링 Clustering
클러스터링은 비지도학습의 한 종류로, 비슷한 특성을 지니는 데이터 포인트들을 그룹으로 묶는 기법이다. 주어진 데이터 집합 내에서 데이터 간의 유사성이 높은 그룹을 형성하고, 이를 클러스터(cluster)라고 부른다. 클러스터링을 이용하면 데이터의 구조와 패턴을 파악하거나 데이터를 간소화하여 분석, 시각화, 레이블링, 분류 등 작업에 활용할 수 있다. 클러스터링의 메서드로는 대표적으로 계층적 클러스터링과 K-mean 클러스터링이 있다.
와인 품질 예측을 위해 클러스터의 수를 미리 정해두고 클러스터링을 진행하는 K-means 방법을 이용하였다.
가) 데이터 전처리
‘quality’ 열을 타겟 변수로 설정하고 나머지 열을 입력 변수로 설정한다. 그 다음 데이터를 표준화하기 위해 ‘StandardScaler’을 사용하였다. 이 메서드는 데이터의 평균과 표준 편차를 계산하고 각 특성을 표준화된 값으로 변환한다. 이를 통해 각 특성이 동일한 스케일을 가지고 중요도가 동등하게 고려되도록 하였다.
y = data['quality']
X = data.drop('quality', axis=1)columns = X.columns
scaler = StandardScaler()
X = scaler.fit_transform(X)
나) K값 설정 및 모델 생성
1-가)에서 예측하고 싶은 와인의 품질(quality)이 6가지 존재했기 때문에 클러스터의 수(k)를 6으로 지정하고 클러스터링 객체를 생성하였다. 이후 K-mean 클러스터링을 수행하여 데이터를 클러스터로 그룹화하고, 각 데이터 포인트가 어느 클러스터에 속하는지 예측하였다.
kmean = KMeans(n_clusters = 6, n_init = 10)
kmean.fit(X)reduced_X['cluster'] = clusters데이터가 고차원이기 때문에 2차원으로 차원을 축소하여 결과를 시각화하여 다음과 같은 결과를 얻었다. 위는 PCA를, 아래는 TSNE를 이용하여 차원 축소와 시각화를 수행하였다.
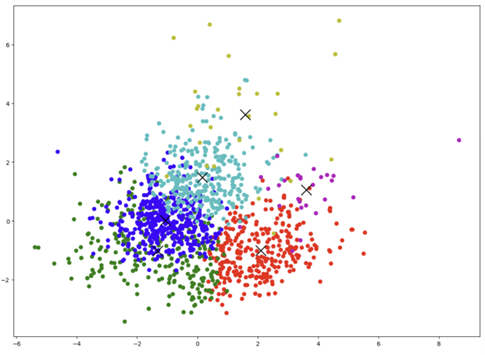
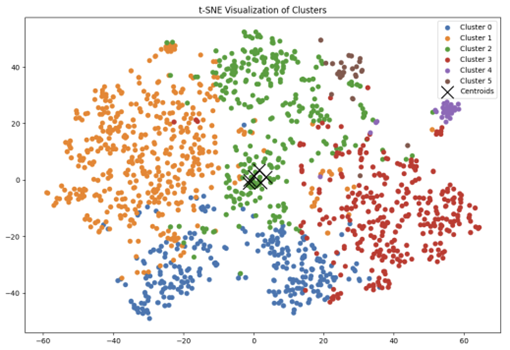
다) 성능 평가
다층 퍼셉트론(MLP, Multi-Layer Perceptron) 분류기를 사용하여 데이터를 학습하고 테스트 데이터에 대한 정확도를 계산한다. 전체 데이터의 80%를 학습용으로, 나머지 20%를 테스트용으로 사용하였다.
X_train, X_test, y_train, y_test = train_test_split(X,y,train_size = 0.8 ) nn_model = MLPClassifier(hidden_layer_sizes = (256,256), max_iter=500)
nn_model.fit(X_train, y_train)테스트 결과 모델은 0.646875의 정확도를 가졌다.
3 선형 회귀 Linear Regression
선형 회귀는 입력 변수와 출력 변수 간의 관계를 모델링하는 지도학습의 한 종류로, 주어진 데이터를 학습하여 회귀 계수를 결정하고 새로운 입력 데이터에 대한 출력 값을 예측한다. 이 모델은 주로 연속적인 출력 변수를 예측하는 데 사용되기 때문에 결과가 불연속적인 와인 품질 예측에 적합하진 않지만, 연습을 위해 선형회귀분석을 진행해 보았다. 1-나)에서 quality와 상관계수가 가장 높았던 alcohol을 입력 변수로 선택하였다.
가) 데이터 시각화
산점도와 선형 회귀 선을 나타내어 alcohol과 quality 간의 선형 관계를 시각적으로 확인하였다.
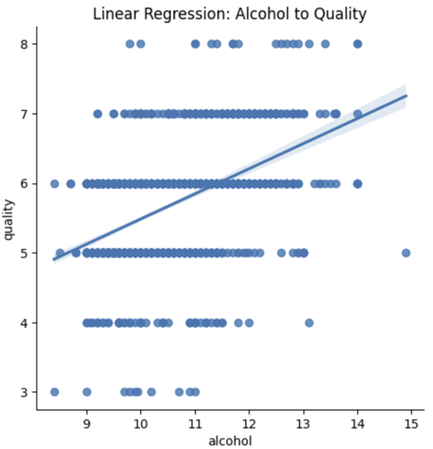
나) 선형 회귀 모델 생성
최소제곱법(OLS)을 사용하여 선형 회귀 모델을 생성하고 다음과 같은 요약 통계를 얻었다.
# 선형 회귀 모델 생성
X = sm.add_constant(data['alcohol']) # 상수 항을 추가
lr = sm.OLS(data['quality'], X).fit()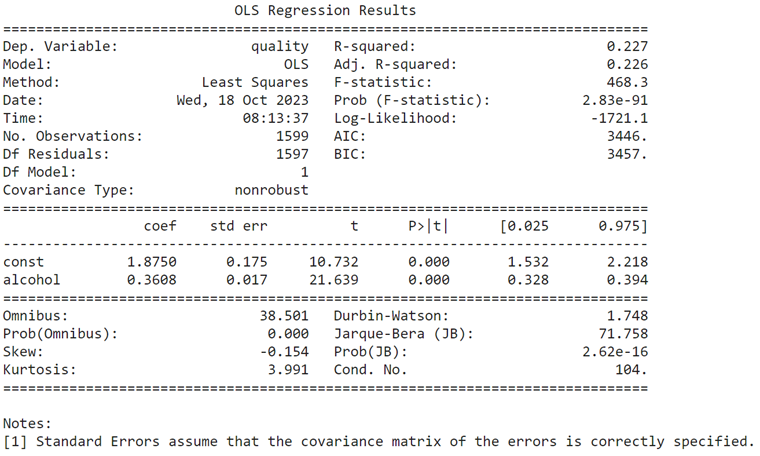
R-squared 값은 모델의 설명력을 나타낸다. 이 모델은 데이터의 분산 중 약 22.7%를 설명하고 나머지 77.3%는 설명하지 못하기 때문에 좋은 예측을 제공하지 않는다.
다) 성능 평가
평균 제곱 오차(MSE)를 계산하여 모델의 성능을 평가하였다. 예측값과 실제값 사이의 차이를 제곱하고, 그 제곱 오차들의 평균값을 계산하여 MSE를 구한다. 이 모델의 MSE는 약 0.504로 나타났고, 이는 모델의 예측이 실제 값과 얼마나 떨어져 있는지를 나타낸다.
# 예측값과 실제값 가져오기
predicted_values = lr.predict(X)
actual_values = data['quality']
# MSE (Mean Squared Error)
mse = ((predicted_values - actual_values) ** 2).mean()
print("Mean Squared Error (MSE):", mse)
4 로지스틱 회귀 Logistic Regression
로지스틱 회귀는 분류 문제를 다루는 지도학습의 한 종류로, 입력 변수와 출력 변수 간의 관계를 모델링하고 출력 변수를 두 가지 클래스 중 하나로 분류한다.
Sigmoid를 이용하여 와인의 품질을 좋음(1), 나쁨(0)의 그룹으로 이진 분류하려고 한다. quality가 7 이상일 경우에는 좋음, 6이하인 경우에는 나쁨으로 분류할 것이다.
가) 데이터 전처리
‘quality’의 값을 7이상이면 1, 6 이하면 0으로 바꿈에 따라 0 또는 1의 값을 갖는 이진 분류 문제로 변환한다.
‘quality’를 이진 분류의 목표값(레이블)로 저장하고, 안정적인 모델 학습을 위해 데이터를 0~1 사이의 값으로 정규화한다.
나) 로지스틱 회귀 모델 생성
학습 데이터와 테스트 데이터를 분할한다. 데이터의 80%는 학습에 사용하고 나머지 20%는 성능 평가를 위해 남겨두었다. scikit-learn 라이브러리에서 제공하는 로지스틱 회귀 모델을 생성하고 데이터를 학습시킨다.

다) 성능 평가
테스트 데이터를 이용하여 클래스별 확률을 예측하고 이진 분류의 예측된 클래스 레이블을 반환한다. 실제 이진 레이블과 비교하여 로그 손실을 계산하는 BCE (Binary Cross-Entropy)로 Loss를 계산하였다. BCE Loss는 약 0.414, 모델의 정확도는 지금까지의 세 모델 중 가장 높은 85.31%로 확인되었다.

5 결론
본 실습에서는 red wine의 데이터를 학습시켜 품질을 예측하는 모델을 클러스터링, 선형 회귀, 로지스틱 회귀의 세 방법을 이용하여 생성하였다.
클러스터링 모델에서는 클러스터의 값을 미리 지정하는 K-Means 방식을 이용하여 와인의 품질을 6개의 클러스터로 분류하였다. 이 모델은 64.69%의 정확도를 가졌다.
선형 회귀 모델에서는 와인의 알코올에 따른 품질을 예측하였다. 이 모델은 0.227의 R-squared값과 0.504의 MSE를 가졌다.
로지스틱 회귀 모델에서는 와인의 품질을 좋음과 나쁨, 두 그룹으로 이진 분류하였다. 이 모델은 0.414의 BCE와 85.31%의 정확도를 가졌다.
참고자료
- chatGPT – TSNE 시각화 코드, BCE 손실 계산 코드
- Red Wine Quality Prediction For Beginners (https://www.kaggle.com/code/ademox02/red-wine-quality-prediction-for-beginners)
- Red Wine Quality Linear Regression (https://www.kaggle.com/code/tanyildizderya/red-wine-quality-linear-regression)
- Wine Quality - Linear Regression (https://www.kaggle.com/code/daalex/wine-quality-linear-regression)
- Machine Learning 3 Logistic and Softmax Regression (https://www.kaggle.com/code/fengdanye/machine-learning-3-logistic-and-softmax-regression)
- 데이터 상관관계 분석 방법들의 원리와 장단점 (https://tech.onepredict.ai/7b5cb659-687d-48a4-ac80-827d30e49fb3)
- How to Use t-SNE Effectively (https://distill.pub/2016/misread-tsne/)
