MLP와 BERT 모델
6개월 전 프로젝트를 처음 시작할때, 원래는 여러가지의 알고리즘을 개발하여 각각의 성능을 비교해볼까 하였었다. 안타깝게도 알고리즘 1개만이 코드 상 에러도 나지 않고 제대로 잘 구현이 되어 그 알고리즘의 성능을 높이는데에 집중을 하게 되었다.
오늘은 개발에 어려움을 겪었던 두가지 알고리즘, MLP와 Bert 모델에 대해 간단한 소개와 설명을 해보겠다.
1. MLP 모델
MLP(multi-layer perceptron)는 다층 퍼셉트론, 즉 퍼셉트론으로 이루어진 층 여러 개를 순차적으로 붙여놓은 형태를 말한다. 보통은 입력층, 하나 이상의 은닉층, 출력층으로 이루어진 전방향 신경망이고, 비선형 문제를 해결하기 위해 생긴 개념이다. 단순 퍼셉트론만으로는 해결할 수 없는 여러 복잡한 문제들을 퍼셉트론 여러개로 층을 쌓아 해결할 수 있는데, 가장 간단한 비선형인 XOR문제도 단층 퍼셉트론을 두개 연결시켜 구성하여 해결 할 수 있다.
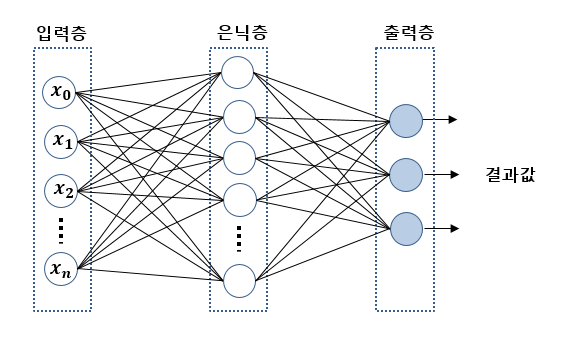
하지만 MLP도 좋기만은 하진 않는데, 바로 은닉층을 늘리는 과정에서 overfitting과 vanishing gradient 문제가 나타난다는 것이다. 이때 Overfitting이란 training set에 너무 과최적화되어 실제 데이터로 분류를 하려고 하면 정확도가 떨어지는 현상이고, Vanishing Gradient Problem은 layer가 deep해지면서 backpropagation으로 error를 뒤로 전파하게 되는 것에 문제가 생겨, 에러값이 뒤로 갈수록 현저히 작아지며 학습이 제대로 안되는 것을 말한다. 이와 같은 문제들을 해결하기 위하여 먼저 overfitting 문제에는 regularization, 즉 정칙화 기법을 사용한다. 정칙화 기법으로 weight가 너무 커버리지 않게 조절을 해주고, validation set을 활용하여 정확도를 조절해준다. 두번째 vanishing gradient 문제에 대해서는 sigmoid를 ReLU로 바꾸는 등 활성화 함수를 변경해본다.
이러한 문제들이 없고 MLP가 잘 작동한다면 높은 정확도로 텍스트를 labeling한 주제에 알맞게 분류할 수 있을 것이다.
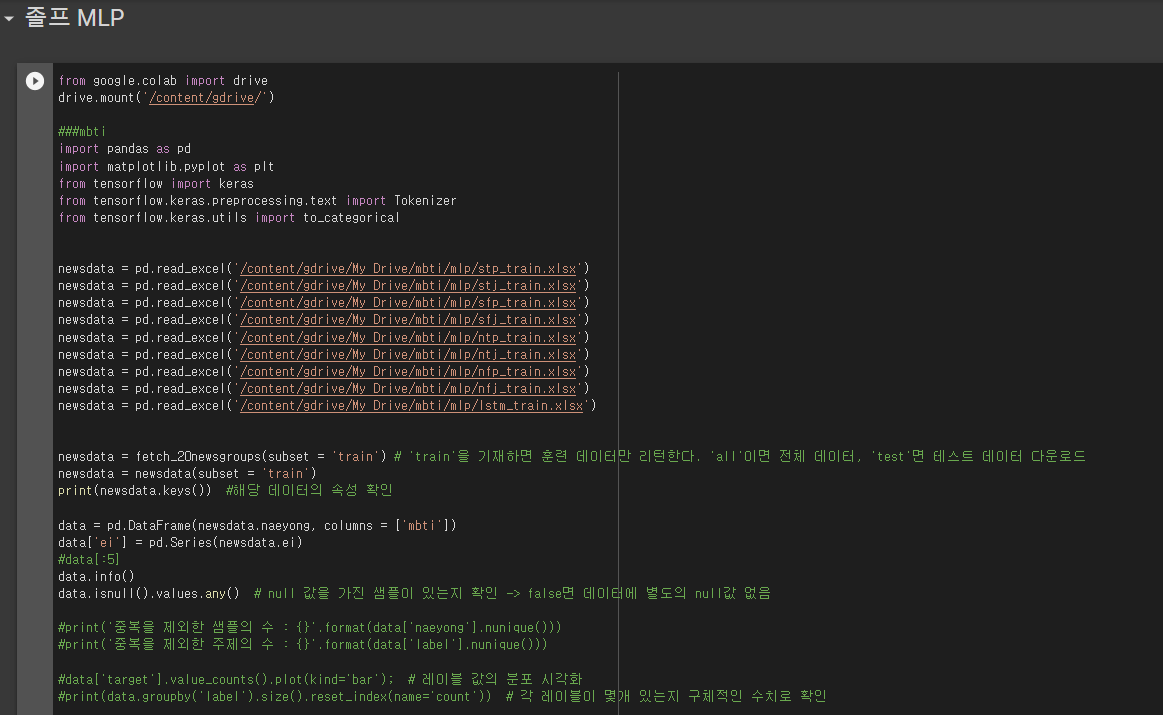
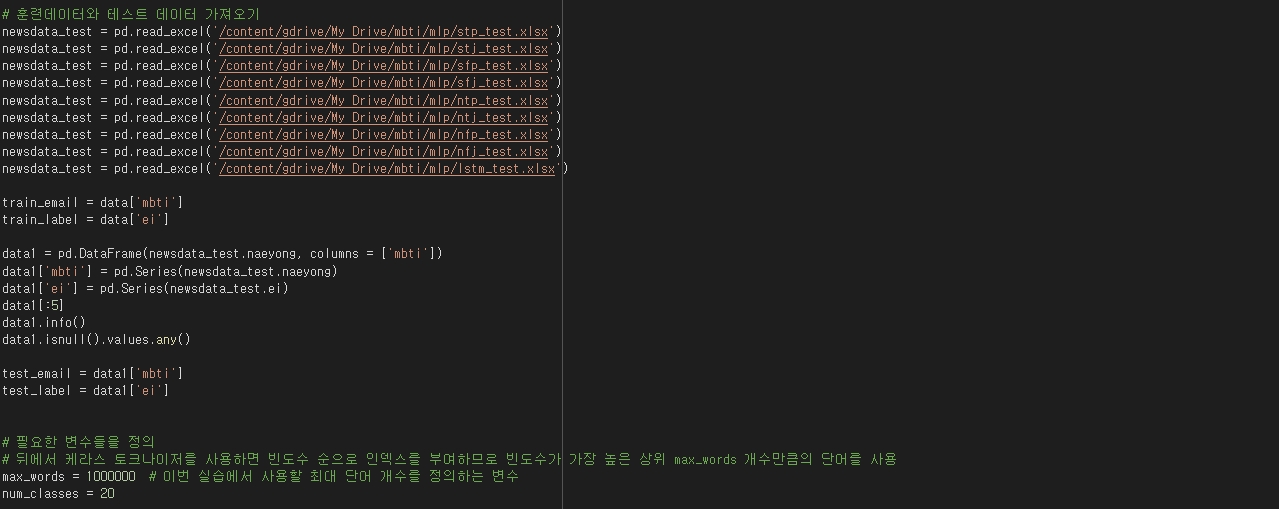
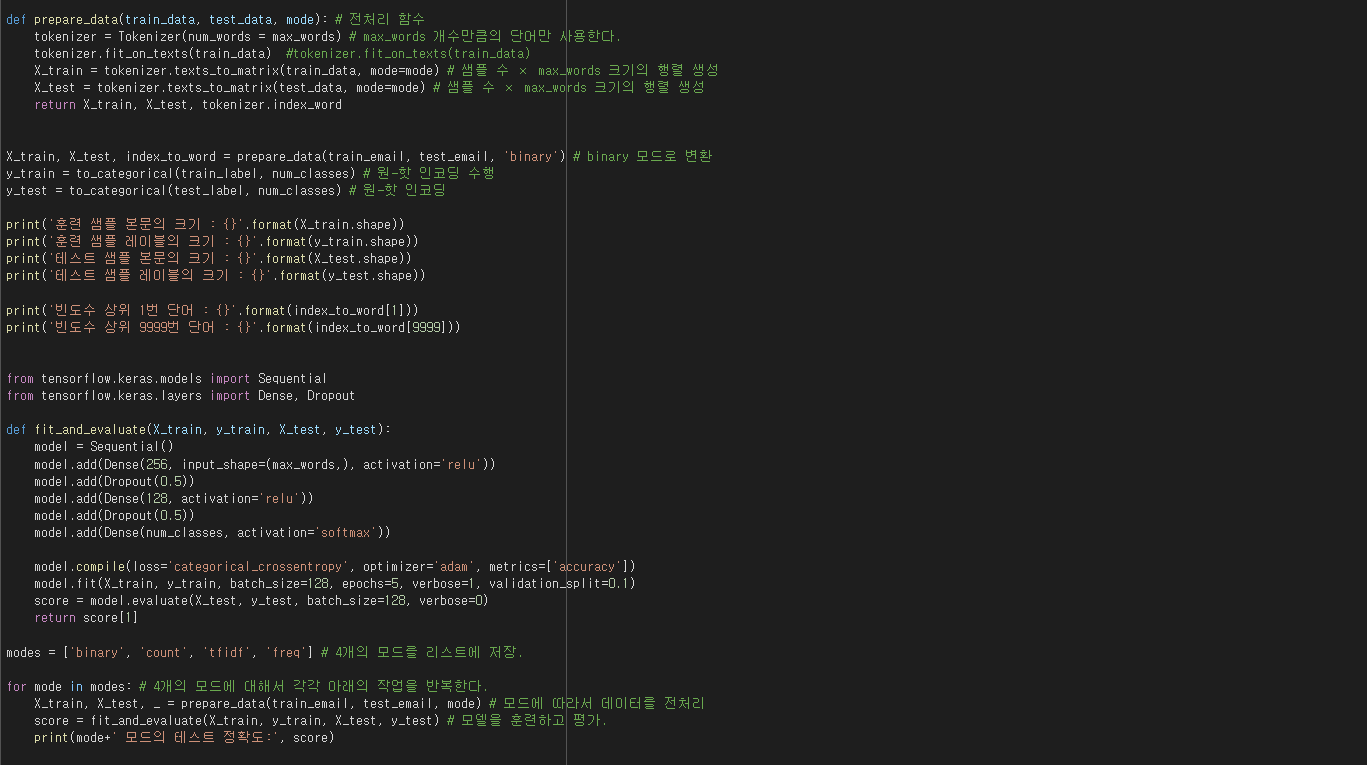
다음은 프로젝트를 위해 짰었던 MLP 알고리즘 코드의 일부분이다. 비록 이번 프로젝트 때 끝까지 완성하진 못하였지만 추후에 시간이 된다면 코드적 에러를 고쳐 뛰어난 성능을 지닌 알고리즘으로 만들어보고자 한다.
2. BERT 모델
BERT 모델은 구글에서 개발한 NLP(자연어처리) 사전 훈련 기술이며, 특정 분야에 국한된 기술이 아니라 모든 자연어 처리 분야에서 좋은 성능을 내는 사전 훈련 언어 모델이다. BERT를 사용하지 않은 일반 모델 과정은 분류를 원하는 데이터를 LSTM, CNN 등의 머신러닝 모델로 바로 분류를 한다. 하지만 BERT를 사용하여 모델링을 하면 관련 대량 코퍼스를 BERT 모델로 돌리고, 그 다음에 분류를 원하는 데이터를 LSTM, CNN 등의 머신러닝 모델을 통해 분류하게 된다. 즉 대량의 코퍼스를 Encoder가 임베딩하고 이를 전이하여 파인튜닝하고 Task를 수행하는 것이다. 추가적인 모델을 복잡한 CNN, LSTM, Attention을 쌓지 않고 간단한 DNN모델만 쌓아도 Task 성능이 잘 나온다고 알려져 있고, DNN을 이용하였을 때와 CNN등과 같은 복잡한 모델을 이용하였을 때의 성능 차이가 거의 없다고 알려져 있는 모델이다.
대용량의 데이터를 직접 학습시킬 때 상대적으로 적은 자원으로 충분한 자연어 처리를 수행할 때 BERT 모델을 사용한다.

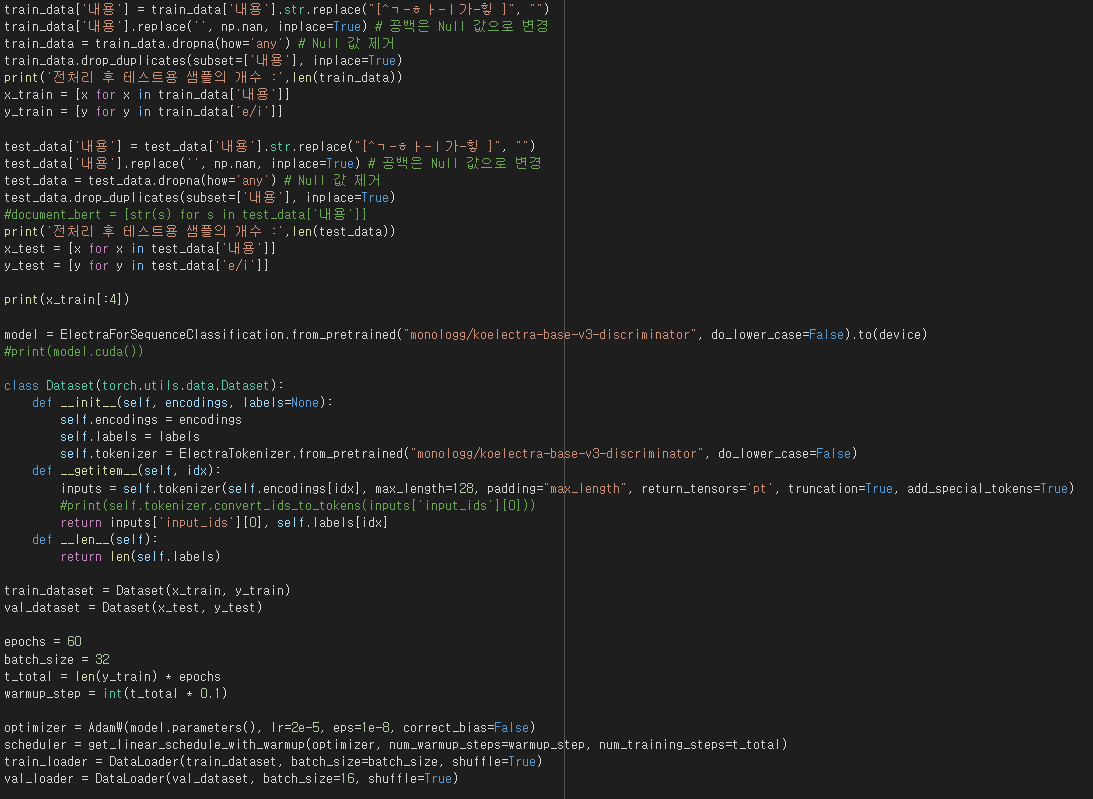
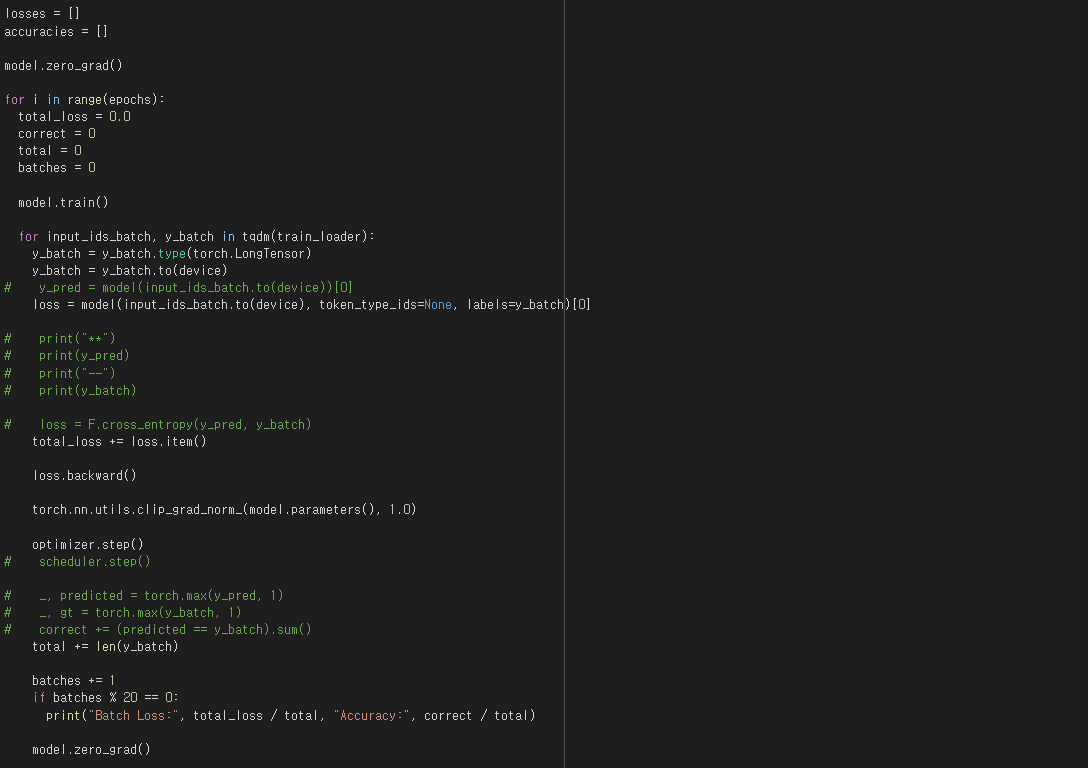
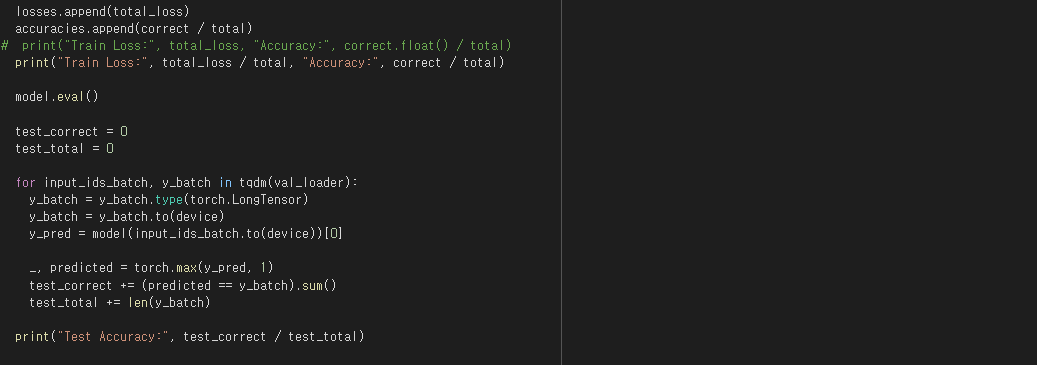
아쉽게도 BERT 모델 역시 완전한 모델로 구현하기에는 실패하였지만, 프로젝트를 위하여 다양한 알고리즘을 접해보고 구현하려고 시도한 것만으로도 많은 것을 배우는 등 충분한 의의가 있었다고 생각한다. 이 또한 프로젝트가 마무리되고 나중에 개발에 성공하여, 개인적으로라도 세가지 알고리즘(MLP, BERT, 그리고 실제 프로젝트에서 사용되는 LSTM)의 성능을 각각 비교해보고 싶다.
(지금 예상으로는 BERT-LSTM-MLP 순으로 높은 정확도를 보일 것 같은데, 실제로도 그럴지 알아보면 좋을 것 같다!!)
