[GPU] fp16에 대한 간단한 이론적 배경
흔히 메모리가 부족하거나 학습을 더 빠르게 하고 싶을 때 mixed precision training을 하게 되는데, 이에 대해 이론적으로 자세히 공부한 적은 없어 이 참에 정리해보았다.
- fp16을 이용할 때 속도가 향상되는 이유
아이디어 자체는 모든 변수들이 32bit로 저장될 필요가 없다는 데에서 시작된다. 비트 수가 줄어들었으므로 연산량이 줄어들어 당연히 속도는 향상된다.
- fp16을 이용할 때 (가끔) 메모리 사용량이 줄어드는 이유
아이디어는 좋지만 실제로는 모든 변수들이 half-precision으로 저장되는 것이 아니기 때문에 메모리 사용량이 배치 사이즈에 따라 거의 안 줄어들 수도 있다. 아래는 Huggingface에서 소개한, fp16가 동작하는 방식이다:
- 모델은 메모리에 2개의 복사본을 갖고 있는데, 1개는 순전파/역전파용의 fp16 텐서들이고, 나머지 1개는 fp32다. ==> 메모리 사용량은 그대로
- 미분값 계산을 위해 순전파로 활성화된 값들은 fp16로 저장 ==> 여기서 메모리 사용량이 줄어듦
- 미분값은 fp16로 계산되지만 업데이트를 위해 다시 fp32로 변환됨 ==> 메모리 사용량은 그대로
- 옵티마이저 업데이트는 모두 fp32로 실행됨 ==> 메모리 사용량은 그대로
즉, 1. 단계에서 메모리의 가중치들이 fp16, fp32로 둘 다 저장되기 때문에 오히려 오버헤드가 조금 발생하며, 2. 단계의 순전파에서만 메모리 절약이 이루어진다. 순전파에서만 절약되므로, 배치 사이즈가 커질 수록 절약되는 메모리도 덩달아 커질 것이다.
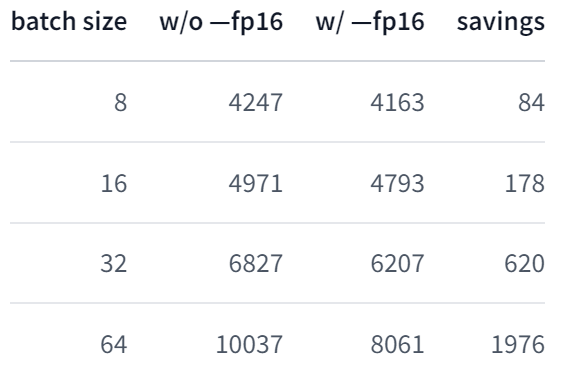
실제로 Huggingface에서 nvidia-smi로 비교한 결과에 의하면, 8 배치 이하의 경우엔 (1. 단계 오버헤드로 인해) 메모리가 오히려 더 사용되며, 위 사진처럼 배치 사이즈가 커질 수록 실제로 더 메모리가 많이 절약되었다고 한다. (출처는 하단 참고사이트의 2.) 한편 이처럼 fp32, fp16이 섞여서 학습되기 때문에 mixed precision training이라 부르는 것이기도 하다.
- 구현 코드:
import torch
# 스캐일러 초기화
scaler = torch.cuda.amp.GradScaler()
for data, label in data_iter:
optimizer.zero_grad()
# 앞의 설명대로 순전파 값들이 Automatic Mixed Precision (AMP) feature 을 통해 fp16으로 저장된다
with torch.cuda.amp.autocast():
loss = model(data)
# fp16으로 미분값이 계산된다
scaler.scale(loss).backward()
# fp32으로 변환되고, 옵티마이저 콜 or 스킵
scaler.step(optimizer)
# 스케일러 업데이트
scaler.update()한편 이렇게 코드를 짤 경우, 앞의 글(https://velog.io/@rhss10/Pytorch-Scaler-%EC%82%AC%EC%9A%A9-%EC%8B%9C-Detected-call)에서도 작성했지만 lr_scheduler를 사용할 때 오류가 뜰 수도 있다. 정리하자면, fp16는 속도 향상이 가장 큰 장점이고, 배치사이즈가 클 수록 메모리가 줄어드는 기능이라고 할 수 있겠다.
- 참고 사이트:
