[Transformers-Trainer] Evaluation 단계에서 계속 RuntimeError: CUDA out of memory 가 발생할 경우
DEEP LEARNING
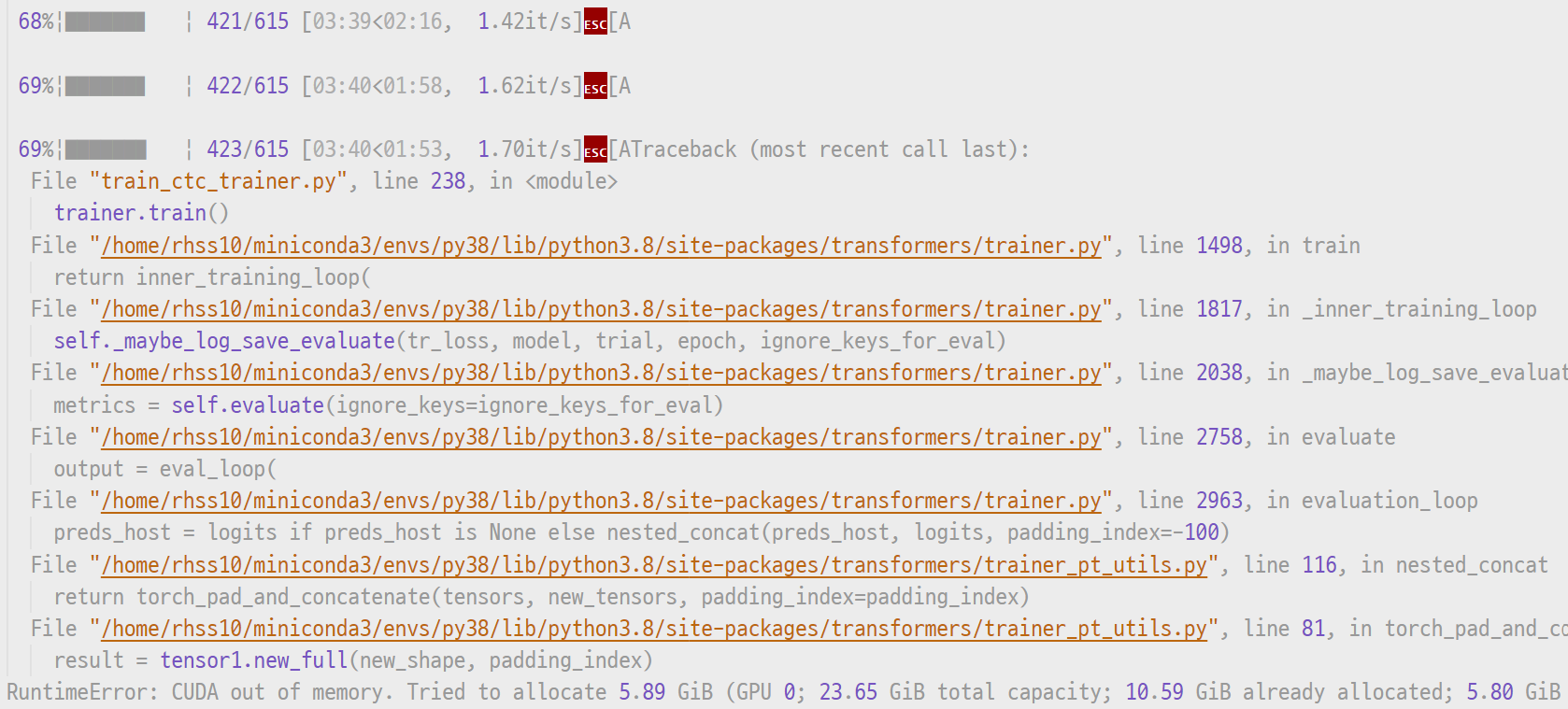
실험을 돌릴 때 배치의 데이터들이 계속 축적되기 때문에, 훈련 단계에선 잘 돌아가더라도 한 에폭의 마지막에 검증 데이터로 검증을 할 때 메모리 오류가 날 때가 생각보다 많다. 코드가 잘 돌아가는지 확인하냐 마냐의 문제도 아니고, 에폭 초기단계에서 발생하는 오류도 아니기 때문에 매우 허탈한 상황 중 하나.
만약 transformers.Trainer로 간단하게 실험하는 경우라면, 이때 유용하게 쓸 수 있는 인자가 있다. TrainingArguments의 eval_accumulation_steps로, 모든 검증 데이터를 GPU에 축적하여 한번에 계산하는 것이 아니라 N개씩 나누어 계산 후 CPU로 보내주는 인자다. 당연히 메모리 사용량이 줄어든다. 아래 사진과 같이 설정해주자.

TrainingArguments Class의 소스코드를 보면 eval_accumulation_steps에 대해 다음과 같이 설명돼 있다.
eval_accumulation_steps (int, optional): Number of predictions steps to accumulate the output tensors for, before moving the results to the CPU. If left unset, the whole predictions are accumulated on GPU/TPU before being moved to the CPU (faster but requires more memory).
링크: https://github.com/huggingface/transformers/blob/main/src/transformers/training_args.py#L122
이처럼 연산된 값들을 CPU로 옮기기 전에 몇 개나 쌓을지 직접 정할 수 있기 때문에 상황에 따라 1, 2, 10 등 다양하게 사용할 수 있을 것이다. 그러나 CPU <==> CPU 간에 소통하는 빈도가 잦으면 그만큼 병목현상이 생기기 때문에, 메모리가 부족하다고 뜨더라도 우선은 값을 높게 잡고 점점 1에 가깝게 줄이는 것이 좋겠다. 어김없이 나오는 space-time trade-off. 아무튼 다시 실험을 돌리면 검증단계가 매끄럽게 넘어가는 것을 확인할 수 있다.
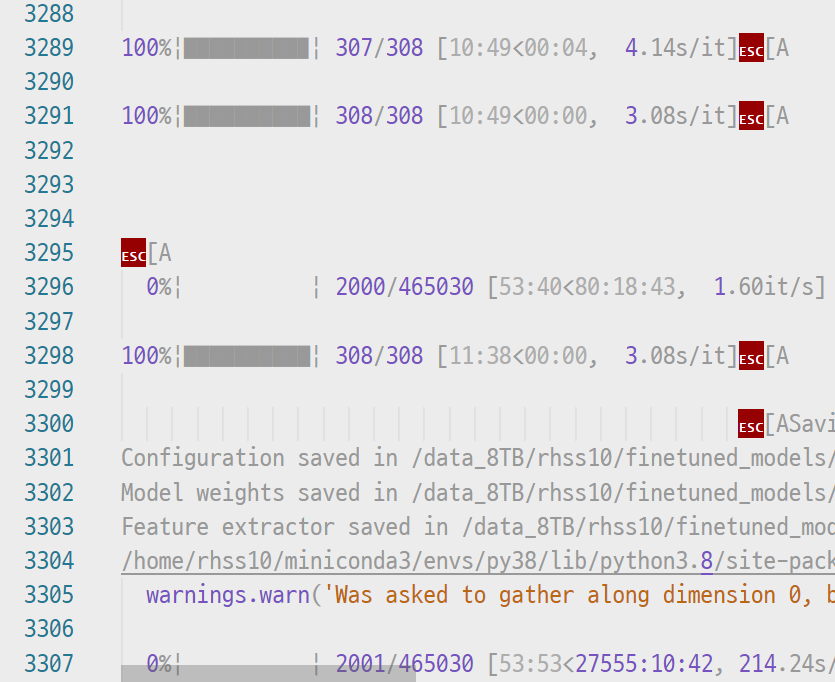
캡처된 실험의 경우, 검증 데이터에서만 아슬아슬하게 GPU가 부족한 것이어서 많이 사용되는 train batch size, gradient checkpointing, gradient accumulation 조절 등은 하지 않았다. 이 부분에 대해서 한꺼번에 정리한 게 있는데 완벽하게 정리한답시고 임시보관함에 지금 몇 달째 있다...
오늘은 Trainer에 대해서만 정리했지만, eval_accumulation_steps와 비슷한 설정값이 일반 torch 라이브러리에도 있을 것이라 생각한다. 나중에 한번 찾아보기.
