CTCTokenizer
여러 사람 구하는 Transformers 라이브러리. 그중 CTCTokenizer을 한번 따로 뽑아보자.
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer(path, unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")
print(tokenizer)
'''
#결과
PreTrainedTokenizer(name_or_path='', vocab_size=127, model_max_len=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={'bos_token': '<s>', 'eos_token': '</s>', 'unk_token': '[UNK]', 'pad_token': '[PAD]'})
'''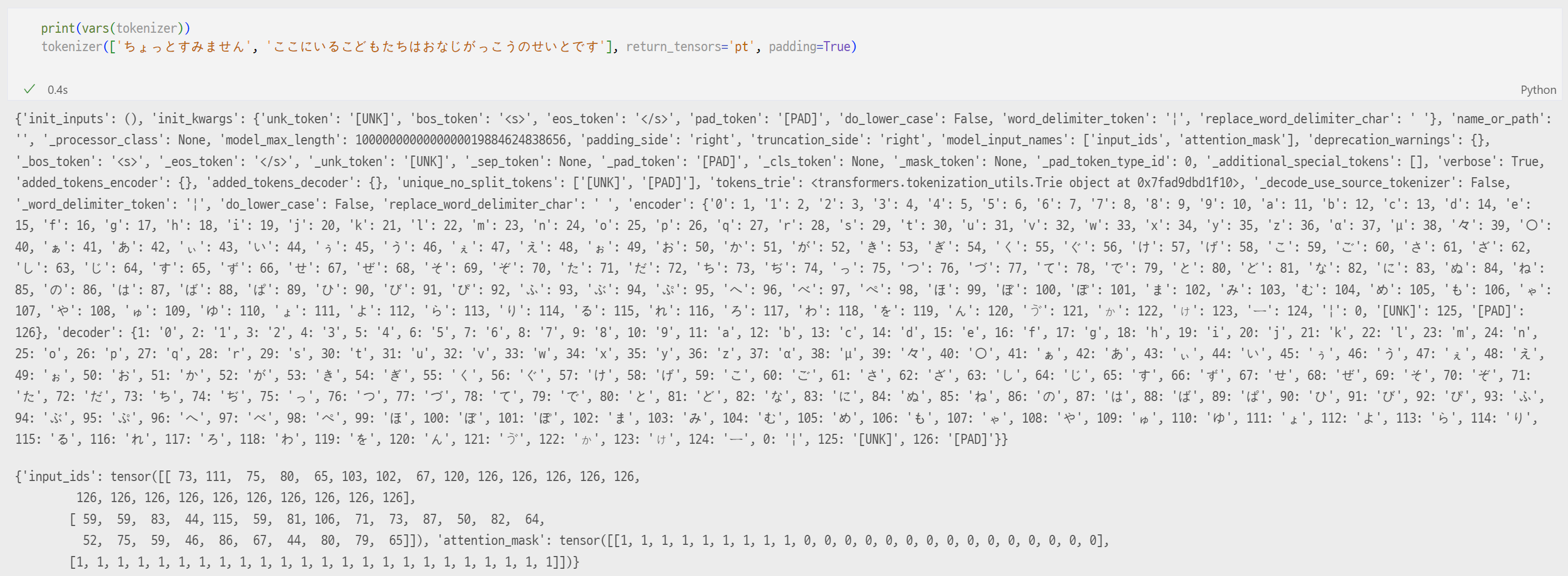
공간이 부족해서 vars만 뽑아봤지만 dir을 보면 많은 함수가 내장되어 있다. 함수들 이름도 직관적이고 잘 정리되어 쓰기 편하다. 지금 하고 있는 연구과제 언어가 일본어여서 보면 vocab이 일본어 히라가나다.
- word_delmiter_token = | 로 했는데, space token이 무의미한 정보가 아님을 직관적으로 보여주기 위해서 | 를 많이 사용한다.
- tokenizer output으로 나오는 attention_mask는 1 또는 0으로 되어있어 [PAD] 토큰을 attend하지 않게끔 처리해준다.
아직 궁금한 부분
- decode(), batch_decode()에서 -100 같이 안 할당된 숫자값이 들어오면 [UNK]로는 처리되지만 remove_special_tokens=True 설정에서는 또 special_tokens로는 처리되지 않는 문제. 내가 헷갈리는 걸까? 나중에 github issue 에 물어보고 싶다.

Speech Processing/AI/Linguistics/CS/etc.