실제로 시스템의 파일시스템이 HDD나 SDD같은 스토리지 영역에 어떤 레이아웃으로 구성되는지, 레이아웃에 파일이 생성됐을때 어떤 식으로 접근되는지에 대한 파트이다.
File System structure
Layered file system
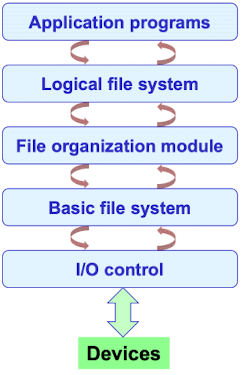 가운데 세가지 레이어가 파일시스템을 구분하는 layer다.
가운데 세가지 레이어가 파일시스템을 구분하는 layer다.
실제로 각 경계가 명확하게 구분되지는 않지만 파일 시스템이 워낙 큰 소프트웨어 모듈이기 때문에 이해를 위해 이렇게 구분한다.
- Logical file system : application에 가까운 기능들
- File system metadata (file의 데이터가 아닌 file system의 metadata) 관리
- 디렉토리 structure 관리
- FCB(File Control Block) 관리
- Protection and security
- File organization module
- logical block address <-> physical block address 사이의 매핑
- 스토리지 상의 빈 공간 관리
- Basic file system : hardware와 가까운 기능들
- device driver와의 interation, physical block을 읽고쓰는 opration 관리
대표적인 Unix의 파일시스템으론 UFS, FFS가 있고, Linux는 40개 이상의 파일시스템을 지원하지만 EXT2,EXT3,EXT4 라는 고유의 파일시스템이있다.
File System Layout
-
Disk Layout

HDD,SDD 같은 스토리지의 physical device쪽에선 이렇게 block들의 seqeunce로 구성돼있다.- Boot control block (Boot block)
Bo 초록색 부분으로 부팅을 위한 Bootstrap code가 저장된다. 즉 kernel image를 읽어서 메모리에 올려주기위한 부분이다. - Volume control block (Superblock)
B1 빨간색 부분으로 Volume(block전체)에 대한 정보를 저장한다.- number of blocks in the partition(Volume, Filesystem)
- size of the blocks
- free block 개수, free block 포인터
- free FCB 개수, free FCB 포인터
- Directory structure
별도의 영역을 두진 않고 Data block에 섞여있다. 즉 디렉토리 structure도 일반 파일처럼 저장된다.
Unix의 UFS에선 다음과같이 저장된다. file name과 inode번호의 쌍이 연속적으로 저장된다.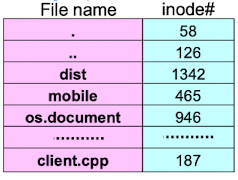
- FCB (Inode)
file에 대한 정보가 저장돼있다. 이 영역에 몇 개의 block을 할당해주는지에 따라 저장할수있는 최대 Inode개수가 달라지기 때문에, 최대 파일생성가능 개수를 결정한다.- Ownership
- Permissions
- Size
- Location of the data blocks
- Data blocks : 실제 file content를 포함하고, 흩어져서 저장돼있다.
- Boot control block (Boot block)
Unix의 파일시스템 UFS의 구조는 이렇게 생겼다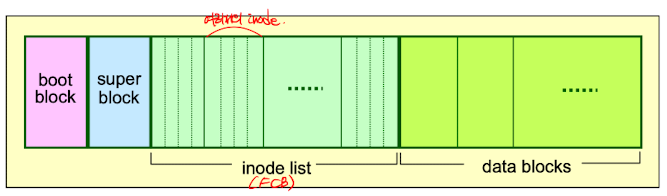
Kernel Data Structure
파일시스템과 관련된 커널 자료구조는 어떻게 생겼을까
-
open-file table (in Unix)
per-process open-file table인User file descriptor table, system-wide open-file table인file table,Inode table이 오픈된 파일에 대한 정보를 확인하기 위해 커널영역에 존재한다.
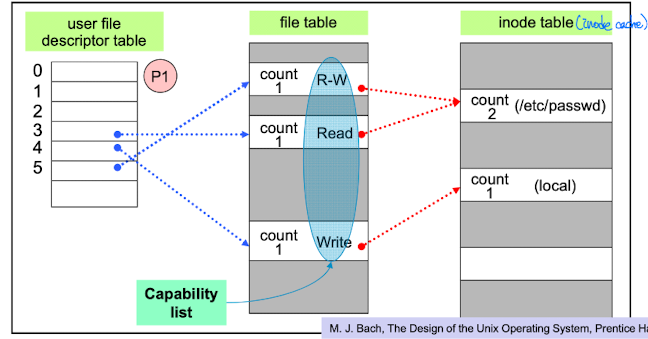
-
Mount table (in Unix)
어떤 파일 시스템이 마운트 될떄마다mount table에 저장된다.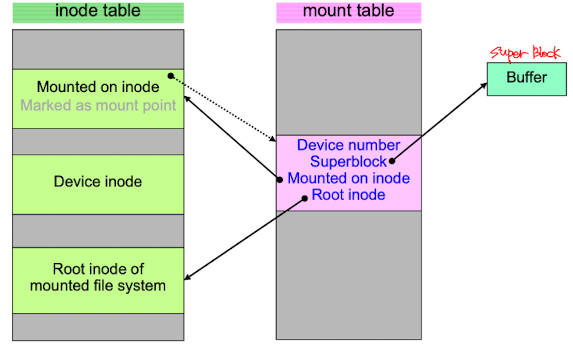 Device number, 마운트 된 파일시스템의 Superblock으로의 pointer, root directory inode로의 pointer, mount point directory의 inode로의 포인터가 mount table에 저장된다.
Device number, 마운트 된 파일시스템의 Superblock으로의 pointer, root directory inode로의 pointer, mount point directory의 inode로의 포인터가 mount table에 저장된다. -
Directory structure cache : 최근 접근된 directory에 대한 정보가 저장돼있다.
-
VFS (in Linux)
VFS를 통해서 리눅스는 많은 종류의 파일종류를 지원가능하다. VFS로 끊김없이 다른 종류의 file systme type을 navigate할 수 있게 해주고, user가 여러종류의 파일 시스템에 저장돼있는 파일을 접근하게 해준다.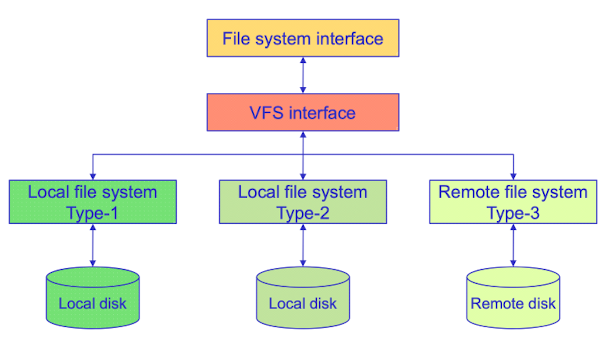 이렇게 VFS interface를 둬서 한 종류의 system call로 app을 실행할수있게하고, 각각 file systme type에 맞는 system call로 변환해준다.
이렇게 VFS interface를 둬서 한 종류의 system call로 app을 실행할수있게하고, 각각 file systme type에 맞는 system call로 변환해준다.file metadata도 다르게 저장이 되는데(ext4->inode , UFS->inode, MS -> dir entry 등등) 이걸 통일해주는 것이
vnode이다. app들은vnode구조를 보고 파일에 접근할수있게 하거나 저장할 수 있도록 하고, 마찬가지로 VFS interface가 변환해준다.
Directory Implementation
-
Linear lists
위에서 잠깐 본거처럼 file name과 metadata의 쌍으로 이어져있는데, unix/linux의 경우 metadata를 inode 저장하므로 해당 inode의 번호를 저장해둔다.
-
Hash table
linear list로 저장해두면 한 디렉토리에 속해있는 entry(file)들이 너무 많을 땐 특정 파일을 찾을 때 너무 오랜시간이 걸린다는 단점이 있다. 이를 보완한 방법이hash table로 저장한 방법이다.
하지만 hash의 특징인 collision이 발생할수도 있어서 잘 사용하지는 않는다.
Issues(consideration)
- Directory search overhead , file creation/removal overhead
- Directory caching mechanism
Allocation Methods
스토리지 상에서 파일contents를 저장할 공간을 allocation하는 기법이 여러가지 있다.
-> 스토리지 공간을 효율적으로 사용할 수 있어야하고, 빠르게 접근하게할 수 있어야한다.
-
Contiguous allocation : physical block을 연속되게 배치
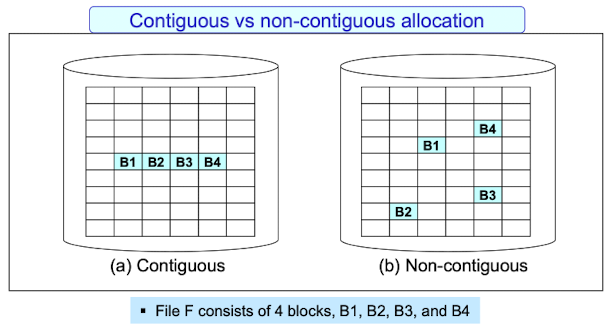 빠르게 접근할 수 있다는 장점이 있지만, 다음과 같은 단점이 있다.
빠르게 접근할 수 있다는 장점이 있지만, 다음과 같은 단점이 있다.-
Finding space for a new file : B5 블록을 추가해야할때 B4옆에 다른 블록이 있다면 통째로 전체를 저장할 다른 space를 찾아야한다.
-
External fragmentation : 4블록을 넣어야하는데 남은 빈 공간이 3블록밖에 없을경우
-
파일이 생성될때 몇 블록이 필요할지 예상하는것도 쉽지 않다.
이런 단점을 해결하기 위해 Linux의 EXT4는 파일을 일정한 크기의 블록들로 쪼갠 단위인
extents를 사용하기도 한다.
-
-
Lilnked allocation <- discontiguous allocation
각 block을 흩어져서 저장하고 linked list로 연결시키고, directory는 첫번째/마지막 블록의 포인터를 포함한다. external fragmentation은 발생하지 않는다.-
단점
- direct-access가 힘들다
- pointer를 저장하기 위한(아래의 FAT영역) 공간이 필요하다.
- 링크가 하나 끊어지면 이후 블록은 접근할 수 없다.
linked allocation을 사용한 MS windows의 FAT을 보자
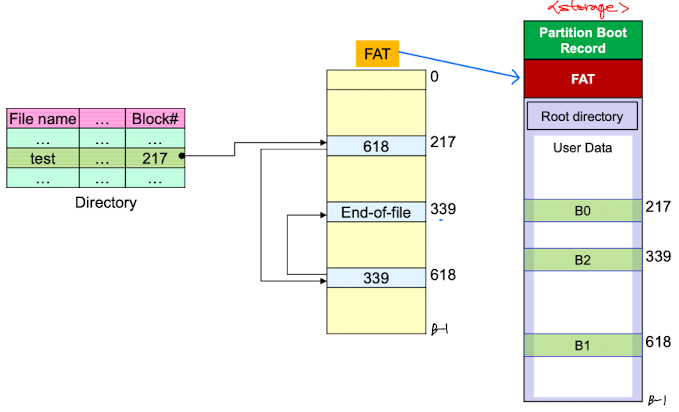 디렉토리를 보면 파일이름과 metadata, 첫번째 블록의 주소가 있다. 첫번째 블록을 찾아가보면 FAT영역에 다음 블록의 주소가 있고, 실제 스토리지에 해당 주소에 파일 데이터를 저장해둔다. 이렇게 FAT영역과, Data 영역을 따로 구분해 storage에 저장하는 방식을 사용한다.
디렉토리를 보면 파일이름과 metadata, 첫번째 블록의 주소가 있다. 첫번째 블록을 찾아가보면 FAT영역에 다음 블록의 주소가 있고, 실제 스토리지에 해당 주소에 파일 데이터를 저장해둔다. 이렇게 FAT영역과, Data 영역을 따로 구분해 storage에 저장하는 방식을 사용한다.
-
-
Indexed allocation
각 블록의
index block정보를 한 곳에 모아둔다. <- Inode에 저장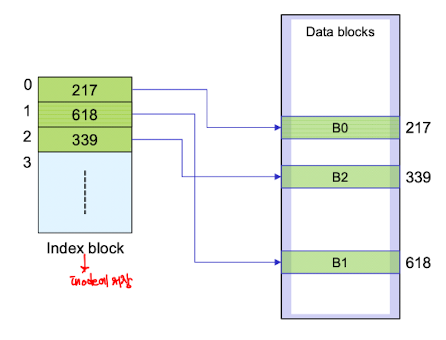
하지만 Inode의 공간이 한정적이기 때문에 용량을 초과하게되는 파일을 저장할 수 없다는 문제가 있다.- Linked scheme : linking of index blocks
- Multi-level index
- Combined scheme : combines direct blocks and indirect blocks <-UFS에서 사용
이 방법들로 해결할 수 있다. 다음 포스트에서 자세하게 다룰 예정이다.
Free Space Management
-
Bit vector
block개수만큼의bit map을 만들어서 block과 1:1 매칭하는 방법으로, 비어있다면 0, 사용중이라면 1로 1개의 bit로 표시해준다.- n개의 연속적인 free block을 찾거나, first free block을 찾는데 효과적이다.
- Linux의 Ext2/Ext3/Ext4가 이 기법을 사용중이다.
-
Linked list
모든 free block을 연결해서 관리한다. 따로 link pointer를 저장할 필요없이 free block은 비어있으므로 그 공간에 다음 빈 block의 정보를 담아둔다.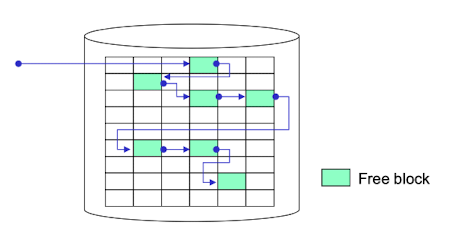 계속 링크를 따라가야 여러개의 빈 block을 찾아야하고, 중간에 free block이 끊기면 다음 block을 접근할 수 없기때문에 효과적이진 않다.
계속 링크를 따라가야 여러개의 빈 block을 찾아야하고, 중간에 free block이 끊기면 다음 block을 접근할 수 없기때문에 효과적이진 않다. -
Grouping
linked list를 보완한 기법으로 빈 block에 다음 block번호만 하나 넣어두는건 공간 낭비가 심하기때문에 여러개의 free block번호를 저장해주는 기법이다.
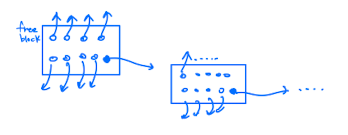 여러개의 빈 블록 번호중 마지막 번호에는 다음 연결할 빈 블록의 주소를 저장한다.
여러개의 빈 블록 번호중 마지막 번호에는 다음 연결할 빈 블록의 주소를 저장한다.
Unix의 UFS에서 사용중이다.
- Counting
first free block의 주소와 연속된 free block의 개수를 같이 저장하는 기법으로 contiguous allocation에서 효과적으로 사용될수있다.