1. Deadlock
Deadlock이 무엇인지, 왜 문제가 되고 OS가 어떻게 해결하는지에 대한 파트다.
Introduction
- Blocked/asleep state
- 프로세스가 특정 이벤트(요청한 I/O가 끝났다는 signal)을 기다리는 상태
- 프로세스가 자원의 할당을 기다리고 있는 상태
- semaphore의 lock이 풀리길 기다리는 등등
- Deadlock state
- 앞으로 절대 발생할 일이 없는 이벤트를 기다리는 상태
- 하나 이상의 프로세스가 deadlocked state면 그 시스템 전체가 deadlocked state인 것이다.
 깨어날 가능성이 없는 deadlock과 starvation을 잘 구분하자
깨어날 가능성이 없는 deadlock과 starvation을 잘 구분하자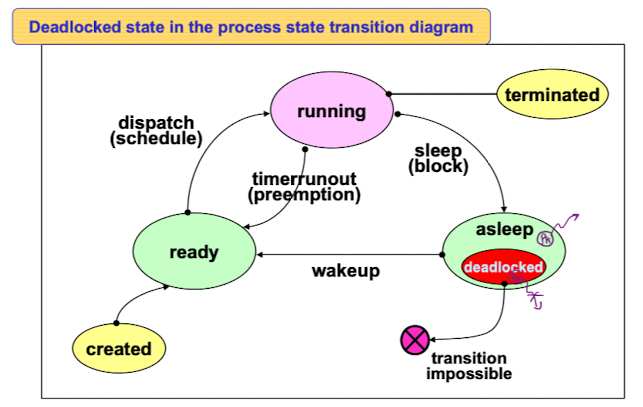 deadlocked 상태는 asleep 상태에 포함되는 것으로 이해해도 좋다.
deadlocked 상태는 asleep 상태에 포함되는 것으로 이해해도 좋다.
Classification of Resource Types
교착상태를 잘 이해하기 위해선 자원의 분류를 정확히 알아야 한다.
- Preemptible of non-preemptible
- Preemptible resources
- 다른 프로세스가 사용하고 있는 자원을 잠시 뺏어와서 써도 문제가 없는 자원
- Processor, memory, etc...
- Non-Preemptible resources
- 자원을 뺏긴 프로세스가 죽거나 다시 실행해야하는 자원
- Magnetic tape drive, etc...
- Preemptible resources
- Total or partitioned allocation
- Total allocation resources
- 자원을 할당할 때 통째로 할당해줘야하는 자원
- CPU, magnetic tape drive, etc...
- Partitioned allocation resources
- 자원을 분할해서 조금씩 할당해주는 자원
- Memory, etc...
- Total allocation resources
- Exclusive or shared allocation
- Exclusive allocation resources
- 한 번 할당된 자원의 공간을 다른 프로세스와 동시에 쓸 수 없는 자원
- CPU, memory(분할된 공간은 혼자만), magnetic tape drive, buffer, etc...
- Shared allocation resources
- 여러개의 프로세스가 동시에 사용할 수 있는 자원
- 대부분 software resources
- Programs (software), shared data, etc...
- Exclusive allocation resources
- SR or CR
- SR (Serially reusable)
- 시스템에 영구적으로 존재한다.
- 프로세스는 사용하고 나면 그 자원을 반납한다.
- CPU, memory, buffer, magnetic tape, etc...
- CR (Consumable)
- 프로세스가 사용 후 사라지는 자원
- 자원을 반납하지 않는다.
- Signal, message, etc...
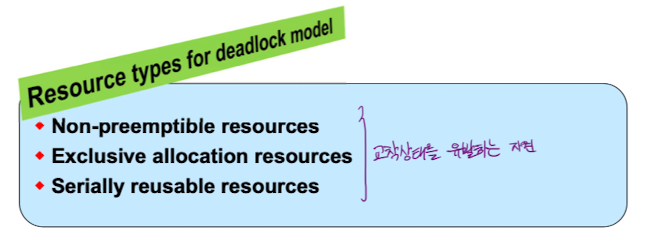
- SR (Serially reusable)
Example Deadlock
 P1은 R1을 할당받고 R2 요청 후 sleep 상태이고, P2는 R2를 할당 받고 R1을 요청 후 sleep상태로 교착상태다.
P1은 R1을 할당받고 R2 요청 후 sleep 상태이고, P2는 R2를 할당 받고 R1을 요청 후 sleep상태로 교착상태다.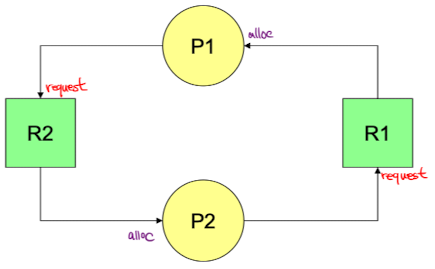 그림과 같이 영원히 해결되지 않는다.
그림과 같이 영원히 해결되지 않는다.
2.Deadlock Model
Deadlock Model
- Graph model
- Node : Process node(Pi), resource node(Rj)
- Edge
- Rj -> Pi : assignment(allocation) edge (Rj가 Pi에게 할당됐다)
- Pi -> Rj : request edge (프로세스 Pi가 Rj를 요청, 기다린다)
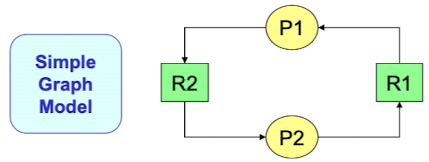
- Example
2개의 프로세스와 2개의 자원을 가진 시스템이고, 프로세스는 한 번에 하나의 자원만을 요청/반납할 수 있다고 가정하자. 상태는 다음과 같이 구분될 수 있다.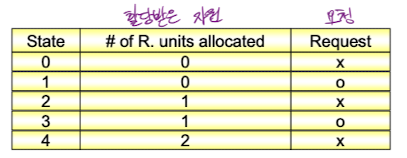 이 정보를 바탕으로 Graph model을 그려보면 다음과 같다.
이 정보를 바탕으로 Graph model을 그려보면 다음과 같다.
Necessary Conditions for Deadlock
deadlock이 발생하는 원인이 크게 4가지 있다. 4가지 모두 만족하는 상태이면 deadlock 상태가 된다.
- Exclusive use of resources (공유가 불가능한 자원을 배타적으로 사용)
- Non-preemptible resources
- Hold and wait (partial allocation) : 이미 특정 자원을 할당받은 상태에서 다른 자원을 기다리는 상태
- Circular wait : edge의 cycle이 발생
이 deadlock을 해결하는 방법에는,
- Deadlock prevention methods
- Deadlock avoidance methods
- Deadlock detection and deadlock recovery methods
이렇게 4종류가 있는데, detection/recovery methods는 같이 사용되기 때문에 하나로 묶어서 얘기한다. 하나씩 살펴보자.
3. Deadlock resolution method
Deadlock Prevention
Deadlock이 발생하는 4가지의 원인 중 하나 이상의 원인을 배제시키려는 방법이다.
하지만 prevention하기 위해서는 많은 자원을 낭비하게 돼서, 실질적인 방법은 아니다. 그래도 한번보자
Denying necessary conditions를 어떻게 해결해야할까?
-
Exclusive use of resources : 모든 자원이 sharable하게 만들자 <- 불가능
-
Non-preemptible resources : 모든 자원을 preemptible가능하게 하자
-
CPU/Memory 같은 자원 이외의 자원도 preemptible하게 사용하는 방법
- Method -1 : 다른 프로세스가 선점 중인 자원을 요청한 프로세스는 wait 하지말고, 현재 가지고 있는 자원을 모두 반납하고 restart or rollback to a checkpoint한다. 자기희생적인 방법이다.
- Method -2 : 다른 프로세스(P1)가 선점 중인 자원을 요청한 프로세스(P2)는 P1의 자원을 그냥 뺏어서 쓴다.
이렇게 하면 deadlock이 발생하진 않지만, 자원을 뺏긴 프로세스는 죽어야하기 때문에 불가능하진 않지만 실용적이지 않다.
-
-
Hold and wait (partial allocation of resources)
- Method -1 (Total allocation) : 프로세스가 시작할 때, 필요할 가능성이 있는 자원을 모두 한 번에 다 할당받는다. 이 방법은 프로세스가 할당받은 자원을 사용하지 않는동안 자원이 계속 낭비되게 된다.
- Method -2 : 아무 자원도 할당 받지 않은 프로세스에게만 자원을 할당해준다. 만약 R1,R2,R3가 필요하다면 R1을 할당받을 때 R2,R3 모두 한 번에 할당받는 방법이다. 1번 방법과 같은 맥락으로 자원의 낭비를 초래하게 된다.
자원을 낭비할 뿐만 아니라 Indefinite postponement가 발생할 수 있다.
-
Circular wait condition
- Deny circular wait
- 아래 그림과 같이 resources를 grouping / ordering 하자.
- 프로세스는 현재 할당받은 자원의 우선순위보다 높은 우선순위 그룹의 자원만 할당받을 수 있다.
- Hold and wait를 해결하는 total allocation 방법의 일반화된 방법이다.
- Resource waste
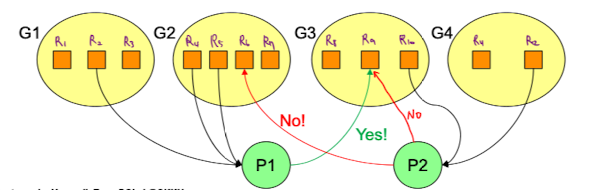
- Witness in freeBSD Unix
witness는 위 그림의 NO에 해당되는 자원 요청의 경우 warning을 주는 방법이다. thread-1은 first_mutex -> second_mutex 순으로 lock을 걸고, thread-2는 second_mutex -> first_mutex 순서로 lock을 걸고있다.
thread-1은 first_mutex -> second_mutex 순으로 lock을 걸고, thread-2는 second_mutex -> first_mutex 순서로 lock을 걸고있다.
서로 반대방향으로 자원의 요청/할당이 이루어질것이기 때문에 교착상태가 발생할 가능성이 높다. 이럴때 witness가 미리미리 warning을 준다.
- Deny circular wait
정리하자면, deadlock prevention은 교착상태를 발생시키는 4가지의 원인을 막는 방법이다.
첫 번째 방법은 아예 불가능했고, 나머지 3개 조건을 deny하는 방법은 가능했지만 심각한 자원낭비를 초래하기 때문에 실용적이지 않다.
Deadlock Avoidance
교착상태의 원인인 4가지 방법은 하드웨어의 속성에서 오는 문제기 때문에 막으려하면 자원의 낭비가 심하다는 것을 앞서 살펴봤다. Avoidance는 교착상태원인 4가지를 그대로 둔다.
대신 이 기법은 시스템의 상태를 지속적으로 모니터링한다. 자원들이 어떻게 할당돼있는지를 보는것인데, 시스템이 항상 safe states를 유지하도록 한다.
여기서 safe state는 교착상태가 발생하지 않고 모든 프로세스를 정상적으로 작동시킬 수 있는 적어도 하나의 root를 유지하는 상태를 말한다.
-
Safe state vs. unsafe state

- safe state : 시스템이 교착상태가 되지 않는것을 보장하는 상태
- unsafe state : 교착상태가 발생할 수도 있는 상태
-
Deadlock avoidance method의 가정
- 프로세스 개수가 고정돼있다.
- resouce types (자원형)과 resource units (단위 자원)의 개수가 고정돼있다.
(CPU가 8개 있는 환경이면, CPU는 resource type이고 단위 자원(resource units)는 8개다.)
signal 같이 동적으로 생성되고 없어지는 자원의 경우 resouce type, resouce unit의 개수가 고정돼있지 않기 때문에 이런 환경에서는 avoidance를 사용할 수 없다. - 각 프로세스가 요구할 최대 자원의 수를 미리 알고있어야한다.
- 할당받은 자원은 반드시 반납한다.
-> 역시 실용적이지는 않다.
Dijkstra's algorithm
이론적인 알고리즘으로, system을 항상 safe state로 유지시키는 방법이다.
Resouce type은 하나만 가지고 있어야하고 , Resource units은 여러개여도 상관없다.
먼저 safe state, unsafe state가 어떻게 판별되는지 알아야 한다.
-
Safe state example
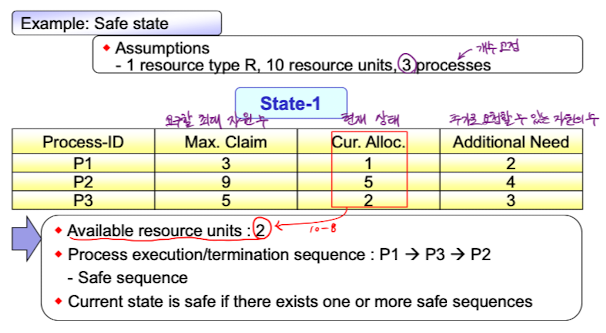 현재 상태를 보고 safe state인지 판단하게 된다. 현재 남은 자원의 개수가 2개이고, P1->P3->P2 순서대로 자원을 할당해주면 Additional Need에 알맞게 할당하고 프로세스가 종료될 수 있다. Safe state는 적어도 하나의 safe sequence만 존재하면 되기때문에 현재 상태는 safe하다고 판단할 수 있다.
현재 상태를 보고 safe state인지 판단하게 된다. 현재 남은 자원의 개수가 2개이고, P1->P3->P2 순서대로 자원을 할당해주면 Additional Need에 알맞게 할당하고 프로세스가 종료될 수 있다. Safe state는 적어도 하나의 safe sequence만 존재하면 되기때문에 현재 상태는 safe하다고 판단할 수 있다. -
Unsafe state example
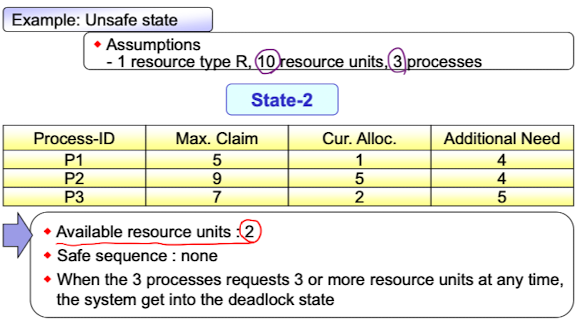 이 상태는 현재 남아있는 자원을 프로세스들에게 할당해도 정상 종료되는 프로세스가 없기 때문에 safe sequence가 없으므로 unsafe state이다. Dijkstra 알고리즘은 이런 종류의 unsafe state로 끌고가지 않는 알고리즘이다.
이 상태는 현재 남아있는 자원을 프로세스들에게 할당해도 정상 종료되는 프로세스가 없기 때문에 safe sequence가 없으므로 unsafe state이다. Dijkstra 알고리즘은 이런 종류의 unsafe state로 끌고가지 않는 알고리즘이다. -
그럼 다익스트라 알고리즘이 작동하는 원리를 살펴보자.
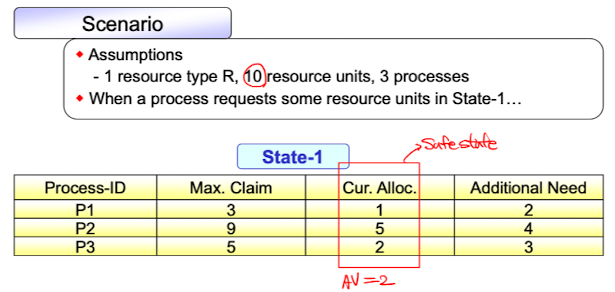 초기상태는 이렇고, 현재 AV(Available resouce unit)는 2개로 safe sequence가 존재해 Safe state이다.
초기상태는 이렇고, 현재 AV(Available resouce unit)는 2개로 safe sequence가 존재해 Safe state이다.
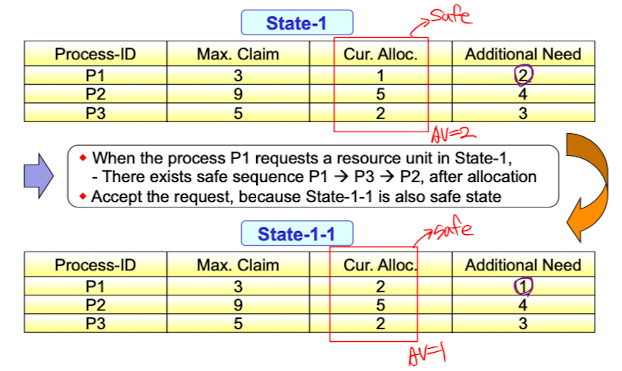 만약 State-1에서 P1이 자원 1개를 요청한다면 여전히 Safe state이기 때문에 자원을 할당해주고 State-1-1로 넘어간다.
만약 State-1에서 P1이 자원 1개를 요청한다면 여전히 Safe state이기 때문에 자원을 할당해주고 State-1-1로 넘어간다.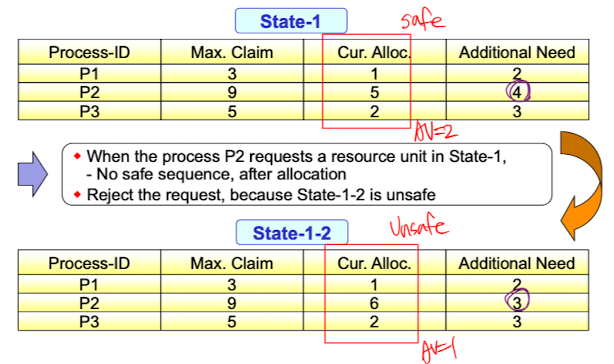 하지만 State-1에서 P2가 자원을 1개 요청한다면 Unsafe state가 되기 때문에 요청을 거절하고 P2를 sleep시킨다. 이런식으로 Unsafe state로는 절대 가지 않는다.
하지만 State-1에서 P2가 자원을 1개 요청한다면 Unsafe state가 되기 때문에 요청을 거절하고 P2를 sleep시킨다. 이런식으로 Unsafe state로는 절대 가지 않는다.
Habermann's algorithm
다익스트라 알고리즘의 확장판으로, 다익스트라와는 달리 resource type이 여러개라고 가정한다. 바로 예시를 보자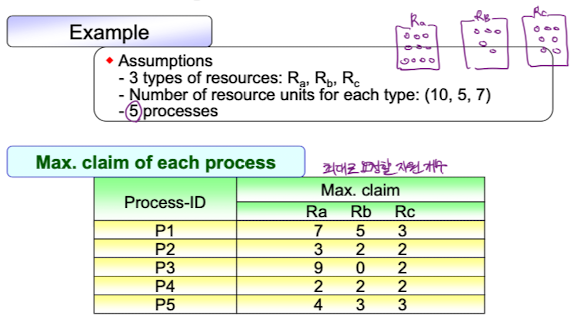 초기 조건과 상태로 여러개의 resource type이 있는 것을 볼 수 있고, 최대 요청 가능 자원도 알려져있다.
초기 조건과 상태로 여러개의 resource type이 있는 것을 볼 수 있고, 최대 요청 가능 자원도 알려져있다.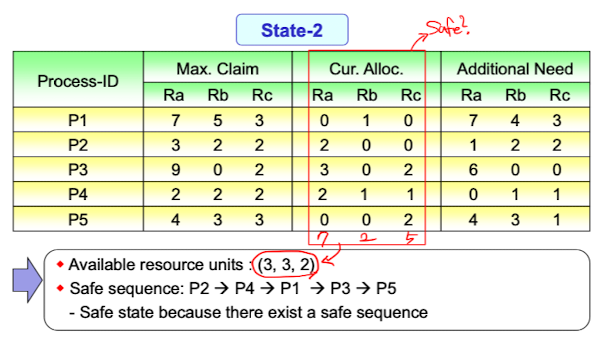 예시로 가정한 자원 할당 상태이다. 다익스트라와 마찬가지로 현재 자원할당 상태를 바탕으로 safe sequence가 있는지 확인해보면 되는데, 제일 쉬운 방법은 현재 AV를 기준으로 Additional need를 만족하는 프로세스가 있는지부터 보는것이다. (3,3,2)로 제일 먼저 P2와 P4를 만족할 수 있다.
예시로 가정한 자원 할당 상태이다. 다익스트라와 마찬가지로 현재 자원할당 상태를 바탕으로 safe sequence가 있는지 확인해보면 되는데, 제일 쉬운 방법은 현재 AV를 기준으로 Additional need를 만족하는 프로세스가 있는지부터 보는것이다. (3,3,2)로 제일 먼저 P2와 P4를 만족할 수 있다.
P2 -> P4 -> P1 -> P3 -> P5의 Safe sequence가 있기 때문에 safe state이다.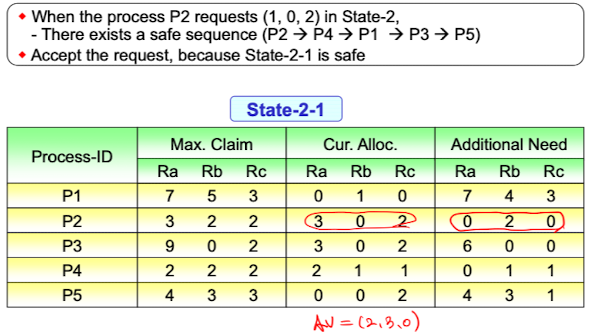
State-2에서 만약 P2가 (1,0,2)의 자원을 요청하면, AV = (2,3,0)이 되고 이를 바탕으로 한 safe sequence가 존재하기 때문에 요청을 받아준다. State-2에서 만약 P1이 (0,3,0)의 자원을 요청하면, AV = (3,0,2)이고 이 경우 safe sequence가 없기 때문에 지금 자원을 준다면 unsafe state가 되므로 P1을 sleep시키고 요청을 거절한다.
State-2에서 만약 P1이 (0,3,0)의 자원을 요청하면, AV = (3,0,2)이고 이 경우 safe sequence가 없기 때문에 지금 자원을 준다면 unsafe state가 되므로 P1을 sleep시키고 요청을 거절한다.
이렇게 Djikstra's algorithm, Habermann's algorithm을 살펴봤다. 예시를 보면 알 수 있듯이 Deadlock avoidance 기법은 worst case를 생각하는 기법이라고 할 수 있다.
Deadlock Detection
앞서 살펴본 prevention, avoidance는 교착상태를 애초에 발생하지 않게했다.
prevention은 교착상태가 발생할 수 있는 4가지 원인을 막자는 방법이고, avoidance는 unsafe state로 진입하지 않게 사전에 자원 할당을 막는 방법이였다.
Deadlock Detection은 위와같은 사전처리가 없기 때문에 교착상태에 처하게 된다. 그래서 deadlock 상태인지 계속 check/detect해주는데, 이를 확인하는데 특별한 graph를 사용한다.
Resource allocation graph
- Deadlock detection에 사용된다.
- Directed bipartite graph이다.
(두 영역으로 partition 할 수 있는 그래프. 아래 그림과 같이 모든 edge들이 두 그룹간에만 존재한다.)
- Directed graph G = (N,E)
 보통 프로세스노드는 O, 자원노드는 ㅁ로 표시한다. process끼리는 edge가 없고, resorce 끼리도 edge가 없기때문에 directed bipartite graph인 것이다.
보통 프로세스노드는 O, 자원노드는 ㅁ로 표시한다. process끼리는 edge가 없고, resorce 끼리도 edge가 없기때문에 directed bipartite graph인 것이다. P->R 또는 R->P 방향으로만 edge가 있다.
P->R 또는 R->P 방향으로만 edge가 있다. tk는 Rk의 자원개수이다. 만약 CPU 코어가 8개 있다면 Rk는 CPU, tk는 8이다.
tk는 Rk의 자원개수이다. 만약 CPU 코어가 8개 있다면 Rk는 CPU, tk는 8이다.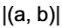 노드 a에서 노드 b로 가는 edge의 개수를 의미한다.
노드 a에서 노드 b로 가는 edge의 개수를 의미한다. - Example
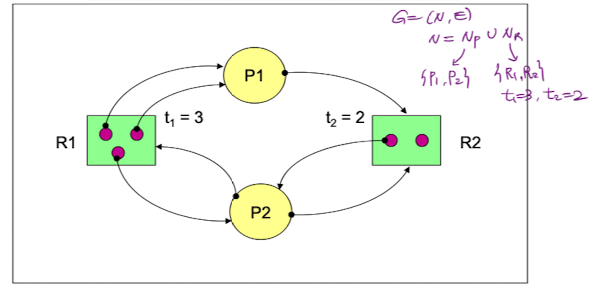 P->R edge는 resource type까지만 닿아있는 것을 볼 수 있다.
P->R edge는 resource type까지만 닿아있는 것을 볼 수 있다.
P1은 R1의 단위자원을 2개 할당받고 있고, R2의 단위자원 하나를 요청하고있다.
P2는 R1,R2로 단위자원을 1개씩 할당받고 있고 R1,R2로 단위자원을 하나씩 요청하고있다.
지금 이 상태는 deadlock이 아니지만, P2가 R2를 할당 받으면 사이클이 생겨 deadlock 상태가 된다.
Deadlock detetion method
-
Graph reduction
- 주어진 edge를 하나씩 제거해나간다.
- 다 제거가 되면 -> 원래 시스템에 deadlock이 없었던 것
- 다 제거할 수 없다면 -> 하나이상의 deadlock이 있었던 것
-
Finding unblocked processes (process state의 unblock과는 다른 개념)
- 프로세스가 요청한 자원들이 전부 할당가능한 상태면 unblocked process라고 한다.
바로 위 예제에서 P1은 요청한 자원이 전부 할당가능하니 unblocked process지만 P2는 R1 쪽에서 할당받지 못하기 때문에 blocked process다. 좌항 <= 우항이면 할당 가능한 단위자원이 있다는 뜻이니 위 식이 unblocked process가 되기 위한 조건이다.
좌항 <= 우항이면 할당 가능한 단위자원이 있다는 뜻이니 위 식이 unblocked process가 되기 위한 조건이다.
- 프로세스가 요청한 자원들이 전부 할당가능한 상태면 unblocked process라고 한다.
-
Graph reduction procedure
- Unblocked process node와 인접한 edge를 제거한다.
- 반복한다.
- 마지막에, 모든 edge가 다 지워졌으면 No deadlock, 모두 지워지지 않으면 deadlock.
-
Example(1)
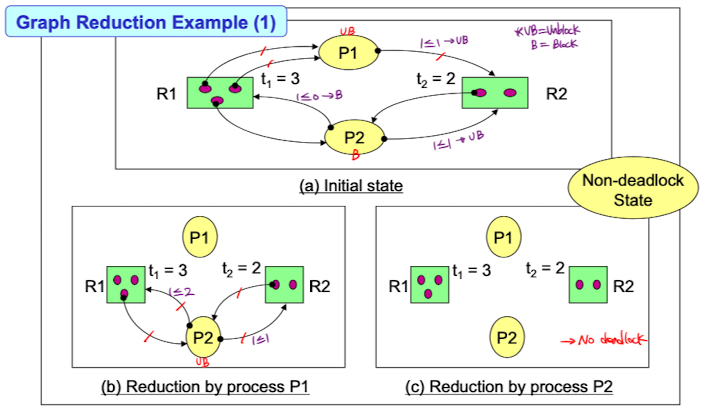 (a) -> (b) -> (c) 순서로 진행됐다.
(a) -> (b) -> (c) 순서로 진행됐다.(1) Unblocked인지 blocked인지 판별하고
요청중인 단위자원 개수 <= 남아있는 단위자원 개수 면 UB이다.
(2) UB이면 인접한 edge를 모두 삭제한다.이 과정을 반복해서 (c)를 보면 모든 edge가 삭제됐으므로 No deadlock이였다라는 것을 알 수 있다.
-
Example(2)
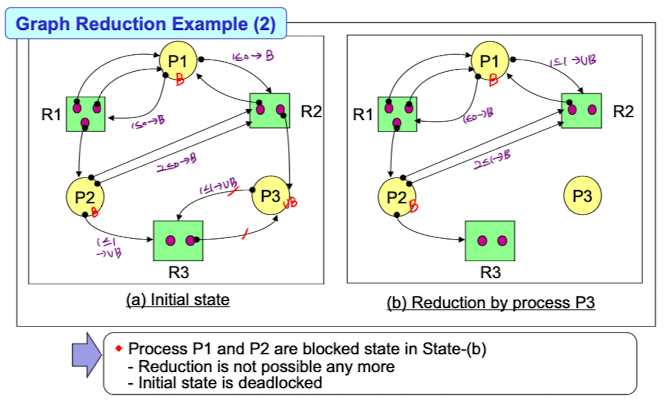 (b)에서 더 이상 edge를 제거할 수 없으므로 deadlock이다.
(b)에서 더 이상 edge를 제거할 수 없으므로 deadlock이다.
이 때, edge가 남아있는 Process들이 교착상태에 걸려있는 것이다. -
Deadlock detection methods는 graph reduction 과정에서 overhead가 큰 기법이다.
그럼 더 빠른 방법은 없을까?
더 좋은 기법은 없지만 특별한 가정을 하면 overhead가 작아지고 빨라진다.- Case-1) 모든 Resource type에 unit이 전부 하나만 있는 case
- 이때는 graph reduction할 필요가 없고 cycle 만 탐지하면 된다.
- Case-2) Single-unit requests in expedient state
- Single-unit request란 한 프로세스는 하나의 unit만 request
expedient state란 프로세스가 자원을 요청했는데 available하면 즉시 할당 - 이런 case에서는 Knot detection을 한다. >> 기회가 되면 따로 정리
- Single-unit request란 한 프로세스는 하나의 unit만 request
- Case-1) 모든 Resource type에 unit이 전부 하나만 있는 case
정리)
avoidance는 worst case를 보고, detection은 most favorable case를 본다. 두 방법 모두 P->R 요청하는 자원, R->P로 할당받고있는 자원 두 가지 매트릭스만 있으면 알고리즘을 사용할 수 있어서 비슷하지만 사실 근본적으로 다른 것이다.
Deadlock Recovery
Deadlock Recovery는 Deadlock detection 이후에 교착상태가 시스템에 있다고 검출되면 그리고 어떤 프로세스들이 교착상태에 걸려있는지 확인이 되면 그 다음에 실행되는 기법으로 교착상태를 제거해주는 기법이다.
Deadlock recovery methods
-
Process termination
-
교착상태에 걸려있는 프로세스의 일부를 abnormally terminate 시켜서 restart or roll back해야한다.
그럼 어떤 프로세스를 terminate하는 것이 효율적일까? termination cost model을 보자 -
Termination cost model
- Termination cost
- Process priority
- Process type (interactive, batch, real-time, etc..)
- Accumulated execution time and remaining time
- Type of resources used
- Accounting cost
- Etc
- 이 cost를 바탕으로 deadlocked process들을 terminate 시킨다.
- Termination cost
-
Lowest-termination-cost process first
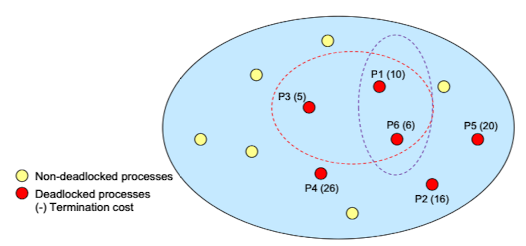 cost가 가장 작은 P3를 먼저 종료시켜본다. 그래도 해결되지 않으면 그 다음으로 작은 P6, 그래도 안되면 다음으로 작은 프로세스를 종료시키는 과정을 밟는다. 여기선 P3, P6, P1을 종료시켜 deadlock을 해결했다.
cost가 가장 작은 P3를 먼저 종료시켜본다. 그래도 해결되지 않으면 그 다음으로 작은 P6, 그래도 안되면 다음으로 작은 프로세스를 종료시키는 과정을 밟는다. 여기선 P3, P6, P1을 종료시켜 deadlock을 해결했다.- Simple and low overhead
- May terminate unnecessary processes : 사실 P1, P6만 종료해도 교착상태는 풀리는데 P3는 cost가 작다는 이유로 억울하게 종료됐다.
-
Minimum-cost recovery
위 그림에서 교착상태에 있는 프로세스는 6개이다. minimum-cost recovery를 위해서 6개의 모든 subset (2의 6승으로 64개) 을 보고 교착상태가 풀리는 조합중 가장 cost가 작은 조합을 terminate시킨다.- time complexity가 너무 크다.
- High overhead
-
-
Resource preemption
교착상태에 있다는 말은 자원의 할당을 기다리고 있다는 것이기 때문에 그 프로세스에게 자원을 preepmtion해서 주는 방법이다.
교착상태 해결을 위해 preemption할 resource를 선택하고 다른 프로세스에게 주는 방법이다. Resource를 뺏긴 프로세스들은 terminate 될 수 밖에 없다.- Selecting a victim : 앞서 살펴본 process termination과 마찬가지로 cost model로 victim resource를 정해야한다.
- Rollback
Process가 뺏기면서 terminate되는데 rollback 할 때 두가지 방법이 있다.- Partial rollback : 약간만 뒤로 돌아가는 방법. Context saving (앞 장에서 나온 register를 저장하는 context saving이 아닌, 프로세스의 모든 정보를 saving해야한다.)
 최소 거리의 checkpoint로 돌아간다. checkpoint 를 저장해야하기 때문에 overhead가 있다.
최소 거리의 checkpoint로 돌아간다. checkpoint 를 저장해야하기 때문에 overhead가 있다. - Total rollback : abort and restart
- Partial rollback : 약간만 뒤로 돌아가는 방법. Context saving (앞 장에서 나온 register를 저장하는 context saving이 아닌, 프로세스의 모든 정보를 saving해야한다.)
- starvation
마무리하면서, 7장에서 살펴본 정형화된 교착상태 해결 방법들은 실제 OS에서 잘 사용되지 않는다고 한다. prevention 기법같이 현실성 없는 가정을 둔 기법들도 있고, 대부분의 방법들은 자원 낭비가 심하게 발생하기 때문이다. 실제로 교착상태가 발생한다고 하더라도, 시스템전체를 한번 리셋하는 것을 감수하는 것이 낫겠다는 판단을 있다. 교착상태가 자주 발생하는 현상이 아닌데, 이 현상을 주기적으로 검사하고 그럴 필요가 없다는 판단이다.
real-time system 같은 경우는 교착상태를 관리하는 것이 중요하기 때문에 이를 막기 위해 더 강한 방법을 써야한다는 이슈가 있어서 교착상태를 아예 무시할 수 있는 상황은 아니다.
그렇다고 지금 사용되는 OS가 교착상태를 아예 관리하지 않는 것은 아닌데, 7장의 정형화된 해결방법이 아닌 ad hoc적인 기법을 사용한다. 프로세스들 간의 lock을 거는 sequence를 잘 조절하는 방식을 사용하고 있다.
