
현재 일을 하고 있는 것중에 외부업체로부터 데이터를 받아 프로젝트를 진행하고 있는 것이 있습니다. 그런데 언젠가부터 빈 파일의 데이터가 조금씩 들어오는 문제가 발생하였습니다. 원인을 파악하기 위해 외부업체로 외근을 나가게 되었습니다. 그렇게 스케줄링 코드를 한 땀 한 땀 나눠보면서 어디서 문제가 터진지를 파악 했습니다.
여기서는 네트워크 오버헤드를 줄이기 위해 데이터를 tar.gz 파일로 압축을 해야 했습니다. 그래서 기존 코드는 파이썬의 tarfile 라이브러리를 사용하여 아래와 같은 코드로 압축을 진행하고 있었습니다.
with tarfile.open("sample.tar.gz", "w:gz") as tar:
for name in ["file1", "file2", "file3"]:
tar.add(name)여기서 압축을 하면 특정 데이터에 한해, tar 아카이브에 들어있는 파일들이 완전히 빈 파일로 들어 있는 것입니다. 파일 이름은 잘 보존되어 있는데 말이죠. 사실 외근인데다 당일에 빠르게 처리를 해야하기 때문에 라이브러리에 대한 트러블슈팅을 할 수는 없었습니다. 그런데 리눅스 커맨드로 직접 아래와 같이 실행을 시켰는데 잘되는 겁니다ㅋㅋㅋㅋㅋ😂
tar -czvf sample.tar.gz file1 file2 file3그래서 이슈 fix 를 하기 위해서 그냥 Python 에서 리눅스 tar 커맨드를 실행시키는 것으로 수정하기로 했습니다. 그렇다면 Python 에는 크게 두 가지 방법이 있습니다. subprocess 라이브러리나 os 모듈을 사용하는 것입니다. 그래서 저는 subprocess.run(["tar", "-czvf", "sample.tar.gz"] + ["file1" + "file2" + "file3"]) 과 같이 해보았는데 결과가 똑같이 빈 아카이브가 나오는 겁니다! 😰
아니 이미 터미널에서 정상 동작을 확인했는데 왜 여기서는 안되는 걸까요??? 이해가 되진 않았지만, 어쩔 수 없습니다. 속행해야 합니다. 두 번째로 os.system("tar -czvf sample.tar.gz file1 file2 file3") 와 같이 실행을 시켜보았습니다. 그런데 잘 실행 되었습니다!
(왜...왜지??? 이 꺼림찍한 느낌...)
일단 덕분에 문제는 해결에는 성공을 하고 퇴근을 할 수 있었습니다. 그런데 왜 안 된건지 도저히 이해가 되지 않네요. 그래서 집으로 돌아와, 약간의 고찰(?)을 해보기로 했습니다.
왜 정상 동작하지 않았을까?
구글링을 해서는 명확한 해결책이 나오진 않았습니다. 그래서 저는 조금이라도 실제 tarfile 라이브러리에 대한 코드를 뜯어보는 편이 좋다고 생각했습니다.
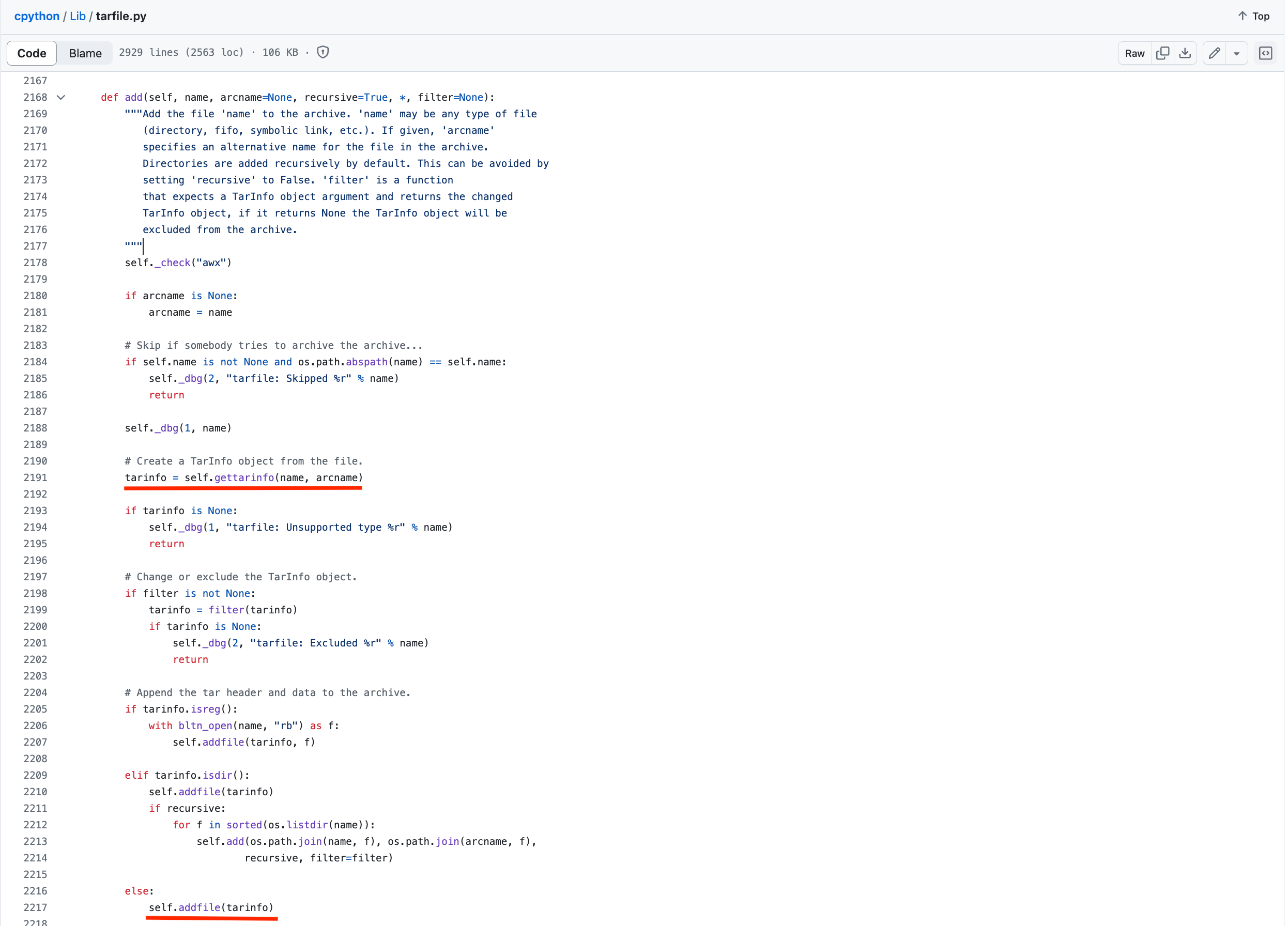
위와 같이 실제 add() 함수에서는 어떤 파일에 대한 정보를 가져와 이를 바탕으로 addfile() 함수를 호출하도록 되어 있습니다.

위가 실질적인 addfile() 코드입니다. 실제 아카이브(ex. tar.gz) 를 담고 있는 Tarfile 클래스에 파일을 복사시키고 해당하는 block 단위까지는 NUL 로 채운 뒤 offset 을 조정하는 것을 확인할 수 있습니다. 이 때 tarinfo.size 에 해당하는 만큼 파일을 쓰는 것을 코드를 보고 직감할 수 있습니다.
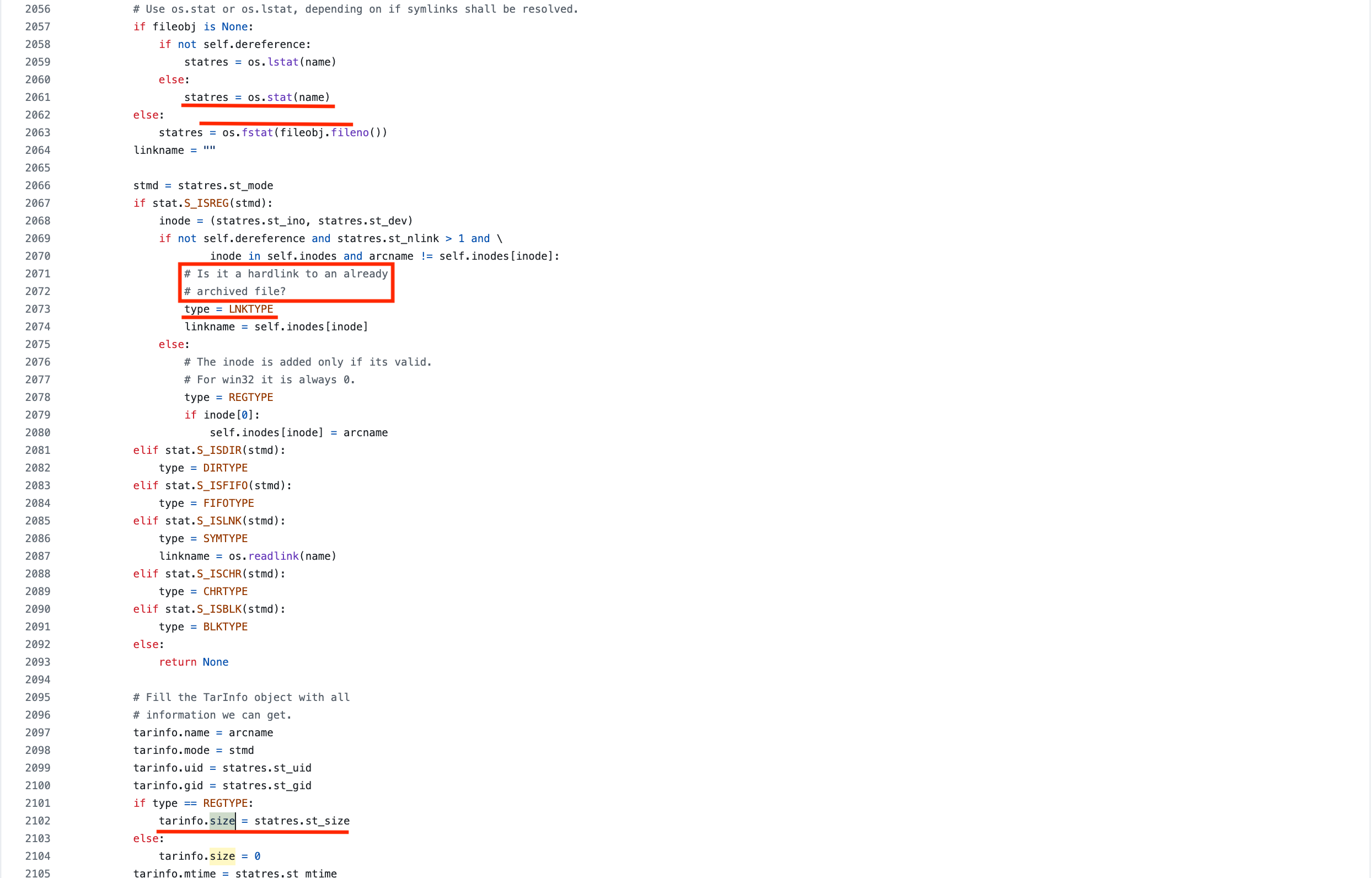
위와 같이 gettarinfo() 함수를 보면 기본적으로 os 의 stat 함수를 통해 파일 정보를 가져오는데요. 가져온 클래스의 st_size 를 통해 파일 크기를 확정 짓습니다. 여기서 파일 크기가 잘못 왔을 수도 있을 것 같습니다. 또 다른 한 가지의 가능성은 위를 보시면 만약 하드 링크 라면 타입이 REGTYPE 이 아니어서 파일 크기가 0으로 할당이 되는데요. 혹시나 추가하려는 파일이 하드 링크는 아닐지 생각해 보아야 할 것 같습니다.
그렇다면 왜 tar 커맨드는 subprocess 모듈에서는 잘 돌아가지 못했던 걸까요? shell=True 옵션을 추가해주어도 결과가 같았으며(아마??), 애초에 제가 쓴 커맨드가 쉘 기능이 포함되어 있지도 않은데요...
| 결론부터 말하면 모르겠습니다!!
애초에 프로그래밍이라는 게 '어? 이게 왜 되지?' 와 '엥? 이게 왜 안되지?' 의 연속이라서 그럴까요... 여건 상 다시 실험해볼 수도 없는 노릇이고 그냥 이 참에 왜였을까를 추측해 보면서 둘의 차이를 살펴보게 되었습니다.

먼저, os.sytem 은 하위 쉘에서 커맨드를 실행시키는 함수라고 써있습니다. C 언어에서의 system 함수를 호출하도록 구현되어 있다 하네요. 빨간 부분을 보면 공식 문서에서조차 subprocess 가 새로운 프로세스로 명령을 실행하고 결과를 가져오는 데 훨씬 강력하다고 권장한다고 합니다. 사실 shell 에서 돌리는 것이 OS-dependent 하니까 좋은 것도 아니고, shell injection 에 취약하게 됩니다. 커맨드를 리스트가 아닌 문자열 그 자체로 받기 때문에 명령어 자체를 바꾸는 공격(ex. rm)이 들어올 수 있으니까요.

물론, subprocess 모듈에서도 인자로 shell 옵션을 킬 수는 있습니다. 대신 위와 같이 인자에서 첫 번째만 실행되는 문제도 존재한다고 합니다. 글에서 저자는 이런 괴상한 인터페이스가 있다는 걸 믿을 수가 없다면서 화가 나셨네요 😅(출처: https://medium.com/python-pandemonium/a-trap-of-shell-true-in-the-subprocess-module-6db7fc66cdfd) 해당 부분에 대한 도큐는 subprocess 도큐에 아래와 같이 나와 있습니다.

추가적으로, 리턴 타입 등 사소한 차이점을 제외하면 눈에 띄는 차이점은 있지 않습니다. subshell 또한 새로운 자식 프로세스를 fork 하여 생성하는 것이고, subprocess 모듈의 run, call, check_out 등의 실행 함수들도 결국은 subprocess.Popen (C - stdio.h 에도 있는 근본 친구) 을 통해 구현되는 데 이 또한 새로운 자식 프로세를 만들고 이를 손쉽고 유연하게 제어 및 모니터링 하기 위한 클래스 및 함수이기 때문입니다. (코드 타고 타고 들어가보면 결국 Modules/_posixsubprocess.c 에서 fork 수행함.)
여기 에 제가 지녔던 질문에 대한 Quora 게시글이 있는데요. 많은 답들 중에 뭐...Popen 은 프로세스 풀에서 생성한다는 말도 있고...🤨 (제가 구현을 봤을 땐 c로 fork() 를 하던데 아직 덜 깊게 들어간 걸수도...???) 다른 글을 봤을 때 정확한 이유는 없지만 subprocess 로 문제가 있어 os.system 을 사용했다는 동지도 있고...(출처 <- 첫 번째 answer 에 comment)
그래서인지 대부분의 사람들이 그냥 subprocess.call(cmd, shell=True) = os.system 이라 하더라구요..ㅋㅋㅋㅋ 더 깊이 들어갈 엄두는 안 나네요.
혹시나 아시는 부분 있으면 댓글 남겨주시길! 부탁드립니다~🥹
