Python 에서는 GIL(Global Interpreter Lock) 때문에 IO-bound 작업이 아닌 이상 Multithreading 멀티스레딩의 장점을 충분히 활용할 수가 없습니다. 그래서 앞선 글 에서 언급했듯이 파이썬에서는 CPU 리소스를 효과적으로 사용하기 위해 Multiprocessing 멀티 프로세싱을 적극적으로 활용하도록 권장하고 있습니다.
우리가 하고자 하는 작업 f 를 새로운 프로세스에서 실행하기 위해 아래와 같이 코드를 짤 수 있습니다. (공식 문서 제공)
from multiprocessing import Process
def f(name):
print('hello', name)
if __name__ == '__main__':
p = Process(target=f, args=('bob',))
p.start()
p.join()Python 에서 Process 클래스를 활용하여 새로운 프로세스를 생성하면 기본적으로
spawn을 활용합니다. 기본적으로 유닉스에서 사용하는 프로세스 생성 시스템 콜인fork는 부모 프로세스의 현재 상태 및 모든 자원을 복제해 갑니다. 그만큼 메모리에 대한 오버헤드가 증가하는 것이구요. 뿐만 아니라 파일 디스크립터와 같이 공유하는 메모리도 있어 동기화 문제가 발생할 수 있습니다. 따라서, spawn 은 명시적으로 필요한 것 외에 그 어떤 것도 복제하지 않고 완전히 깨끗한 새로운 프로세스를 만듭니다. 단순 copy-write 방식은 아니니 조금 더 느리지만, 조금 더 안전하고 컴팩트한 방식이라 할 수 있습니다. Windows 에서 이 방식을 기본으로 사용합니다.
(참고자료: https://www.geeksforgeeks.org/understanding-fork-and-spawn-in-python-multiprocessing/
https://stackoverflow.com/questions/64095876/multiprocessing-fork-vs-spawn)
그렇다면 예를 들어 굉장히 많은 작업을 처리하기 위해서, 계속해서 프로세스를 생성하면 될까요?

직감적으로 바람직하지 않다는 걸 압니다!
하나의 프로세스는 하나의 코어에서 돌아갑니다. 그렇기에 가장 이상적이고 빠른 것은 CPU, 즉 코어 개수만큼의 프로세스가 돌아가는 것일 겁니다. 그런데, 프로세스가 무차별적으로 생기면...
먼저 프로세스 생성에 대한 오버헤드가 증가합니다.
프로세스를 생성하는 것으로도 이미 OS 에게 오버헤드를 주고 있는 것이죠.
스케줄러 큐(Queue) 에 대기 중인 프로세스가 증가합니다.
OS의 스케줄러는 현재 대기 중인, 정확히는 Ready 상태의 프로세스를 기본적으로 프로세스 큐에 쌓아놓습니다. 그런데, 프로세스가 게속 생성되면 덩달아 큐에도 계속해서 쌓이게 되는 것이죠.
Contexting Switch 오버헤드가 증가합니다.
주어진 프로세스가 코어보다 많은 상황에서, OS 스케줄러는 최대한 많은 프로세스를 기다리게 하지 않기 위해 최선을 다할 것입니다. 이 과정에서 프로세스를 올렸다가 내렸다가 교체하는 Context Switching 에 대한 비용이 크게 발생하게 됩니다.
그러면 이런 문제를 해결하기 위해 정해진 최적으로 프로세스만 만들고, 새로운 작업들을 이 프로세스들에서 계속해서 실행하게 하여 재사용을 유도하면 어떨까요? 오버헤드를 최소화하면서 최적의 병렬 프로세싱을 유도할 수 잇을 것입니다. 이 개념이 바로 Process Pool 입니다. 같은 용도로 자바에서는 스레드에 대한 Thread Pool 이 존재하죠.
Process Pool - map() vs imap()
이런 프로세스 풀에 작업을 등록하면 풀은 알아서 풀에 존재하는 프로세스로 해당 작업을 진행시킵니다. 프로세스 풀에서 프로세스의 개수는 직접 지정할 수도 있지만, 지정하지 않으면 직접 os.cpu_count() 로 나오는 CPU 개수만큼으로 생성된다고 합니다. 작업을 등록하는 방식에는 apply, apply_async, map, map_async, imap, imap_unoredered 가 있습니다. 아래 공식문서의 코드를 볼까요?
from multiprocessing import Pool
import time
def f(x):
return x*x
if __name__ == '__main__':
with Pool(processes=4) as pool: # start 4 worker processes
print(pool.apply(f, (10, ))) # prints "100"
result = pool.apply_async(f, (10,)) # evaluate "f(10)" asynchronously in a single process
print(result.get(timeout=1)) # prints "100" unless your computer is *very* slow
print(pool.map(f, range(10))) # prints "[0, 1, 4,..., 81]"
it = pool.imap(f, range(10))
print(next(it)) # prints "0"
print(next(it)) # prints "1"
print(it.next(timeout=1)) # prints "4" unless your computer is *very* slow먼저, 가장 기본적인 함수는 apply 입니다. 함수와 전달해야할 인자를 넘기면 실행한 뒤, 결과가 나오면 반환합니다. 결과가 나오기 전에 일단 반환부터 하도록 비동기를 유도하고 싶다면 apply_async 를 사용하면 됩니다. AsyncResult 가 곧바로 반환되고, get(), wait() 등을 활용하여 결과를 나중에 받을 수 있습니다.
저 같은 경우는 바로 이 map 이 가장 매력적이라고 생각합니다. 실제 파이썬에서 사용하는 map 을 프로세스 풀에 적용하는 겁니다. 인자로 주어진 iterable 각 요소를 인자로 하여 풀 내에 프로세스에서 함수를 실행하는 것입니다. 저와 같은 경우는 회사에서 데이터 전처리에 유용하게 사용하고 있는데요. 전처리를 해야 하는 데이터들을 iterator 로 주고 전처리 함수를 넣어주면 Pool 이 알아서 병렬적으로 이를 실행시켜 줍니다.
(파이썬은...편하다..)

그런데, 사실 저는 imap 은 몰랐습니다. map 과 imap 의 차이는 무엇일까요?
먼저 map 은 모든 iterable 의 결과를 하나의 리스트로 반환합니다. 모든 요소에 대한 결과가 끝나면 이것들에 대한 결과를 한 번에 리스트로 주게 됩니다. 내부 사정은 이와 같습니다. map 은 먼저 iterable 을 적당한 크기의 chunk 단위로 자릅니다. 그리고 풀의 각 프로세스에게 이 chunk 를 전달합니다. 그림으로 보면 아래와 같습니다.
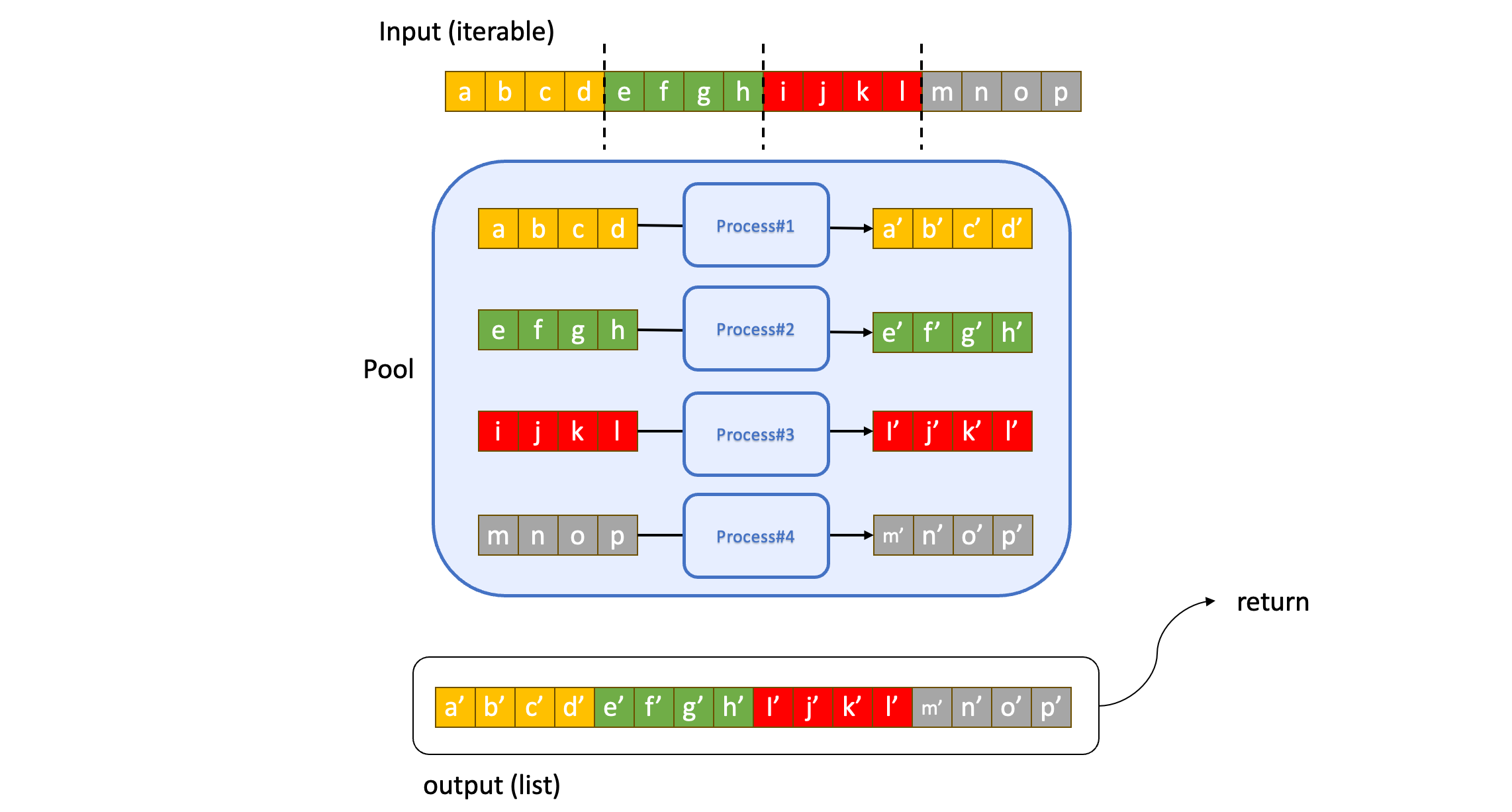
반면 imap 은 chunking 을 하지 않습니다. 각각의 요소를 하나씩 풀의 프로세스 각각에게 보내고, 이를 순서만 지켜서 iterator(정확히는 IMapIterator) 로 내보냅니다. 그림으로 표현하면 아래와 같습니다.
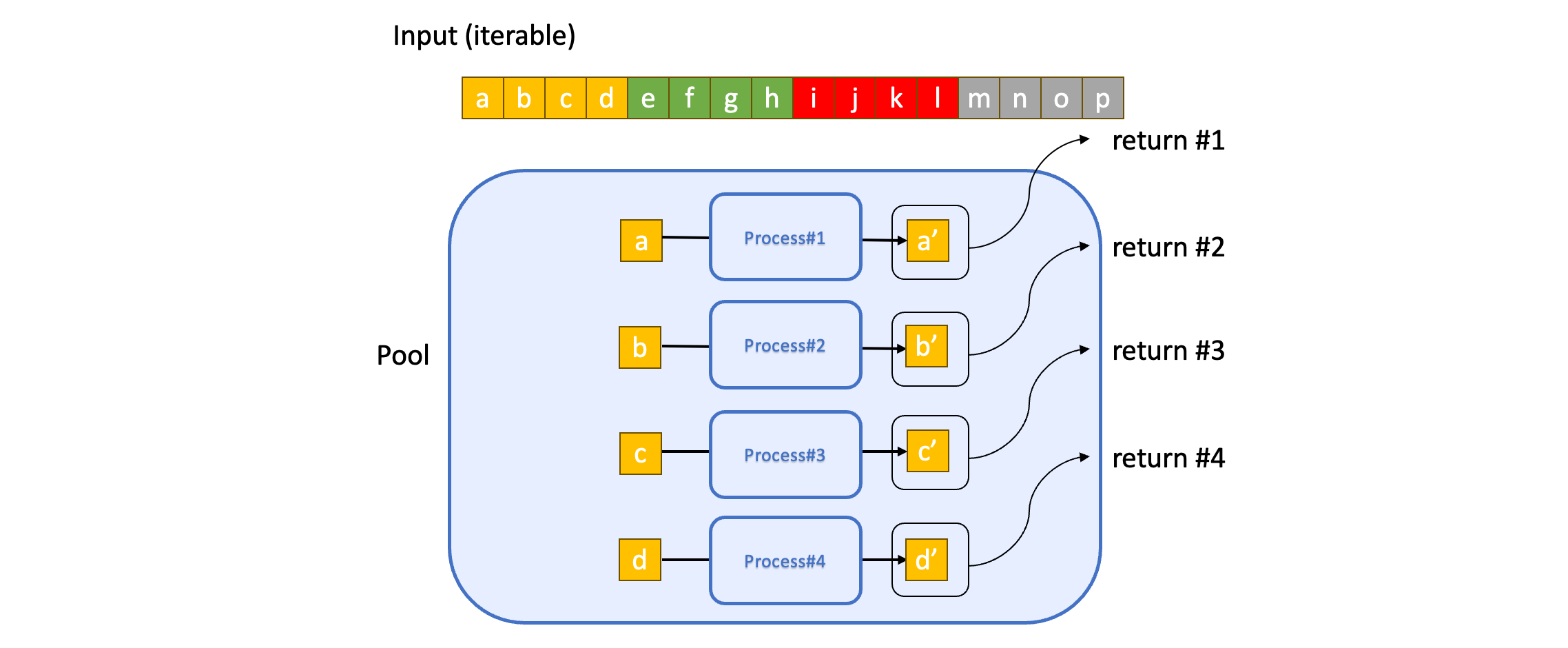
그럼 어떤 게 더 좋을까요?
- 메모리 효율 측면에서는
imap이 좋습니다.
map 에서 chunking 을 하기 위해서 입력으로 들어가는 전체 iterable 을 메모리에 올리게 됩니다. 만약 iterable 의 길이가 매우 크다면 메모리를 많이 차지 합니다.
- 속도 측면에서는
map이 좋습니다.
map 을 chunk 단위로 한 번에 여러 개 작업을 묶어 Pool 에 보내기 때문에 이에 대한 오버헤드가 적습니다. 반면, imap 을 쓰면 보다 자주 자주 보내야 합니다.
- 결과를 바로 바로 처리하고 싶을 때는
imap이 좋습니다.
map 은 전체 결과를 한 번에 리턴하는 데 반면 imap 은 순서대로 곧바로 return 합니다.
하지만, map 과 imap 모두 명시적으로 chunk size 를 넣을 수가 있습니다. 그렇게 되면 map 과 imap 의 차이는 반환 방식밖에 없어집니다. 결과적으로 가장 중요한 것은...
⭐️⭐️⭐️ 좋은 chunk size 를 설정하는 것!!! ⭐️⭐️⭐️
메모리를 과하게 차지하지 않으면서도 빠른 실행 속도를 위한 적당한 크기의 chunk size 를 설정하는 것이 매우 중요합니다. 무엇보다 iterable 길이가 길다면 더더욱!!! 아래 글에 따르면 map 에서 default chunk size 가 아닌 직접 chunk size 를 넣었을 때, 성능(속도) 의 차이가 iterable 이 길어질수록 기하급수적으로 차이가 난다고 합니다. 😲
ps.
파이썬의 기본적인 multiprocessing 은 각 프로세스에 할당할 데이터들을 pickle로 직렬/역직렬화 하기 때문에 굉장히 큰 오버헤드가 발생합니다. 뿐만 아니라, 각각마다 데이터가 복사되기 사용하기 때문에 메모리 또한 크게 사용합니다. 프로세스에 넘겨줄 때, 프로세스에서 받아올 때 둘 다 말이죠. 그래서 이 크기를 최대한 줄여 커뮤니케이션 비용을 최소화해야 합니다. 자식 프로세스에서 가능하다면 굳이 반환을 할 일이 없게 만들면 좋겠죠?
이게 걸린다면 파이썬 분산 프로그래밍을 위한 라이브러리인 RAY 를 고려해보세요. 프로세스 기반이지만 Apache Arrow와 Plasma를 Zero-copy 직렬화를 In-memory로 빠르게 공유하며, 사용이 간편하여 편리합니다.😄
