
쓸모있는 개발자가 되기 위해 가장 필요한 상식 중에 하나는 동기/비동기 개념일 것입니다. 저또한 몇 번의 비동기 코딩을 해보았으며, 이 개념에 대해서 어느 정도 알고 있다고 생각했지만...
택도 없었습니다! 두루 뭉술하게 알아서는 제가 설명할 수가 없더라고요. 그래서 이번 기회에 이 개념에 대해서 확실히 짚고 넘어가기 위해 이 글을 쓰게 되었습니다. 더해서, 개인적으로 제가 웹 개발에 Django를 사용하고 있기 때문에 파이썬에서의 동기/비동기 처리를 부록으로 정리해 보았습니다.
인터넷과 서적에 정말 많은 글들이 있지만, 저마다 설명하는 방식이 달라 약간은 헤메기 쉬운 개념이었던 것 같습니다. 물론 어떤 목적이냐, 어떤 프레임워크를 사용하느냐에 따라 그 쓰임새가 달라져야 하기 때문에 그럴 수 있습니다. 여기서는 제가 이해한 대로 설명해보도록 하겠습니다.
Blocking & Non-blocking 이란 무엇일까?
동기/비동기에 들어가기 전 먼저 필수적으로 짚고 넘어가야 할 개념이 바로 Blocking 과 Non-blocking 개념입니다. 이 부분은 관점을 제어로 바라보는 부분입니다. CPU에 대한 제어권을 넘겨주지 않는다면 Blocking 이며, 넘겨준다면 Non-blocking 입니다. 예를 들어, A란 작업과 B라는 작업이 있다고 합시다. A에서 B라는 작업을 요청한 상황을 상상해보죠.
만약 Blocking 상태라면 B 작업이 CPU에서 실행되기 시작할 때 제어를 A에게 넘겨주지 않는 것입니다. 그래서 A라는 작업은 B라는 작업이 끝나기 전엔 CPU에 올라가 실행되지 못하는 것입니다. 아무 일을 할 수 없이 기다려야 하는 것이죠. 그래서 A작업을 막는다(block)하는 겁니다. 반대로 Non-blocking 상태라면 B 작업은 실행가 동시에 A에게도 제어권을 넘겨주게 됩니다. A는 B가 작업하는 동안 자신도 CPU에 올라가 작업을 수행할 수 있는 상태입니다.
보통 이 Non-blocking을 수행할 때는 I/O를 빼먹을 수 없는데요. 이것이 대표적인 Non-blocking의 사례이기 때문입니다. I/O 처리는 굉장히 무겁고 시간이 걸리는 작업이기 때문에, 이를 요청했던 작업이 이 I/O처리가 다 될때까지 기다리는 것이 굉장히 비효율적이게 됩니다. 그래서 Non-blocking으로 I/O 처리를 해주어 작업을 계속하다가 커널 영역에서 I/O 처리가 끝나면 Interrupt를 하는 식으로 진행하는 것이죠.
Sync(동기)/Async(비동기)란 무엇일까?
이 부분은 관점을 순서로 바라보는 부분입니다. 먼저 동기와 비동기의 단어적 의미부터 살펴볼까요? 간단한 정의로 동기는 같음 을 뜻하고, 비동기는 같지 않음을 뜻합니다. 이를 그대로 가저오면 동기, 즉 Synchronous는 작업을 요청한 순서와 응답(작업이 끝나는) 순서가 같다는 뜻입니다. 반대로 비동기는 서로 다른 작업들이 각각 독립적으로 실행되어 요청한 순서와 응답 순서가 다를 수 있습니다.
아직 와닿지가 않으시죠? 다음 파트를 통해 체감해봅시다.
4가지 조합
정리하자면 Blocking/Non-blocking 은 제어에 관점을 두는 것이고 Sync/Async 는 순서에 관점을 두는 것입니다. 이를 통해서 총 4가지의 조합이 나올 수 있는데요. 하나씩 알아보도록 합시다. 먼저 Sync 를 기준으로 알아보도록 하겠습니다.
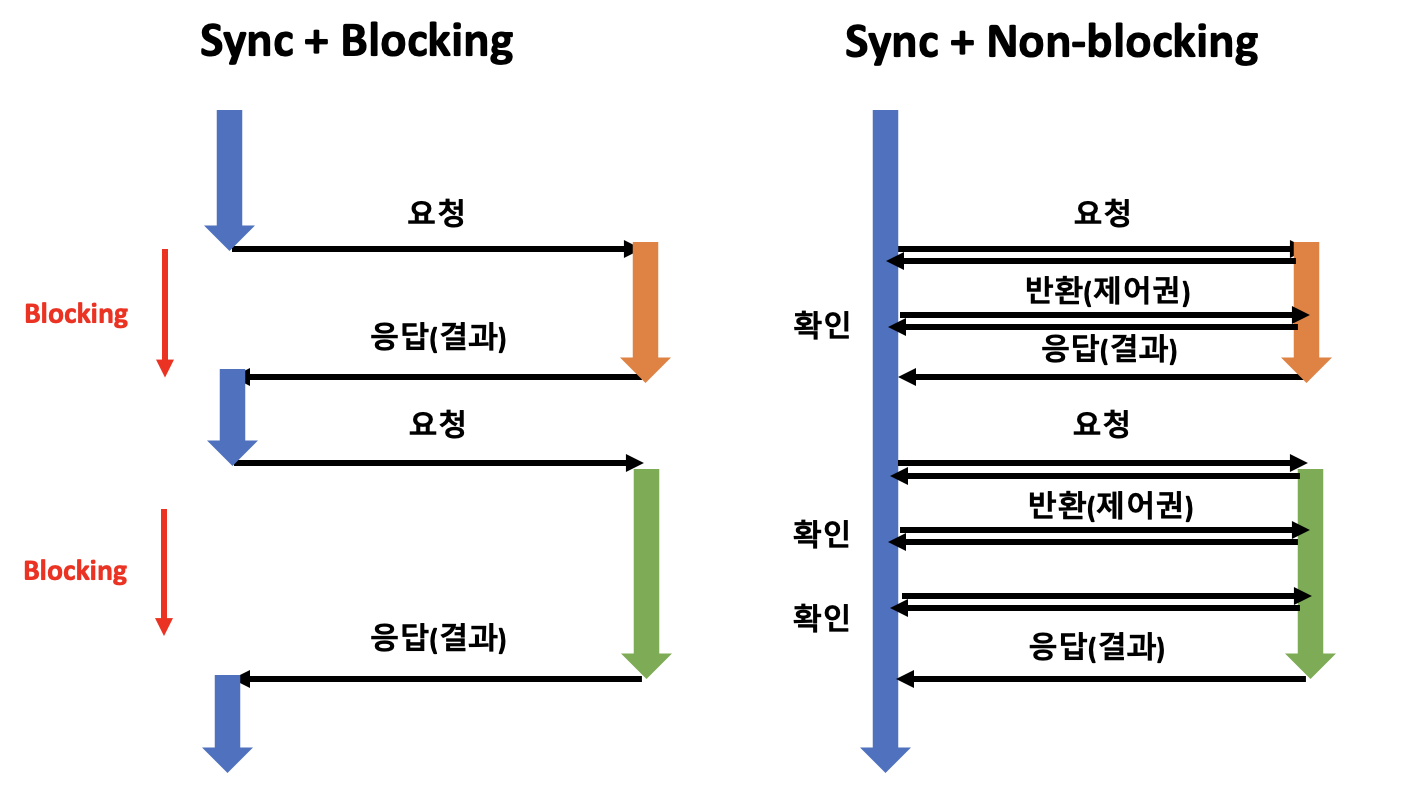
Sync + Blocking
A가 B 작업을 요청하면 B 작업은 A를 blocking 합니다. 이로 인해 A는 B가 작업을 마칠 때까지 아무것도 하지 못하게 됩니다. 그리고 그 B작업이 마쳐지면 그 때 응답으로 작업의 결과와 함께 다시 제어권이 주어지게 되는 것입니다. 우리가 일반적으로 코딩을 할 때 보통 이런 식으로 실행이 되죠??
Sync + Non-blocking
이 때는 이전과 다르게 B 작업은 시작과 동시에 A에게 반환을 해주면서 제어권을 넘겨주게 됩니다. 그 덕분에 A는 기존에 본인이 해야하는 작업을 할 수 있게 됩니다. 그러나, A는 B가 언제 끝날지 알 수 없기 때문에 지속적으로 결과를 확인하는 작업을 하게 됩니다. 이것을 Polling 이라고 하죠. 그리고 또한 Sync를 지켜야 하기 때문에 B가 끝나기 전에 함부로 C와 같은 다른 작업을 요청할 수 없습니다.
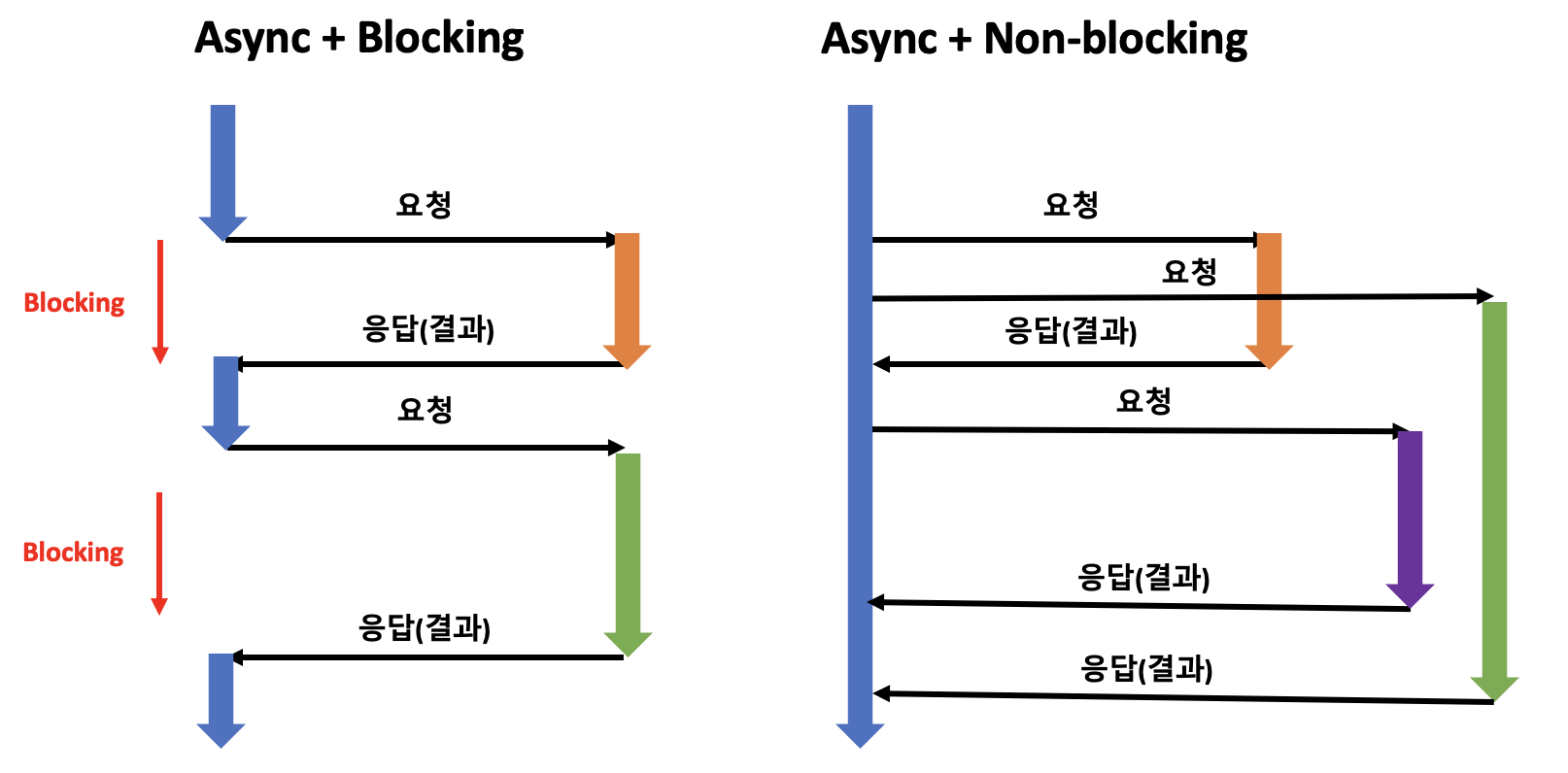
Async + Blocking
Async로 순서는 상관없지만...그럼 뭐하나요. B 작업을 요청한 A 함수는 Blocking이 되어버려 다른 작업을 요청할 수도 없습니다. Sync + Blocking과 다른 점이 없어버리죠. 그래서 이와 같은 방식은 무의미해서 사용되지도 않습니다. 보통 다음에 설명할 Async + Non-blocking을 유도하려다 실수로 이와 같은 상황이 벌어진다고 하네요.😅
Async + Non-blocking
가장 자원과 시간이 모두 효율적인 구조입니다. A는 기본적으로 자신의 일을 하면서 여러 작업을 요청할 수 있습니다. 각각의 요청은 완전히 독립적이며 그렇기 때문에 무엇이 얼마나 걸려서 언제 끝나는지, 즉 완료 순서가 예측할 수 없이 뒤죽박죽이죠. 그래서 기본적으로 결과를 받아서 처리해야 하는 부분을 Callback 함수를 통해 전달합니다. 그러면 B에서 알아서 해당 작업이 끝나면 요청 시 전달받았던 콜백 로직을 실행하죠. 하지만, 이러한 콜백은 콜백 지옥 이라는 어마무시한 단점을 가지고 있기 때문에 이를 피하기 위해 Promise 를 사용하기도 합니다. Promise 객체를 통해 결과를 받으면 A에서 해당 결과에 대한 로직을 실행시키죠. 한 번 더 나아가면 이 Promise 또한 Promise 객체 후, then() 에서 새로운 비동기 작업을 통해 Promise 객체를 동작시키면... 체이닝으로 인해 콜백 지옥과 다를 것이 크게 없어지게 됩니다. 그래서 최종적으로 이 Promise를 마치 동기적으로 코딩할 수 있게끔 하는 async/await 을 사용하게 되는 겁니다. (Javascript 기준)
그럼 무조건 Non-blocking + Async?
비동기 + Non-blocking 이 자원을 효율적으로 사용하며 실제 수행시간을 단축시키는 것은 자명하지만, 그렇다고 무조건 비동기만 쓸 수는 없습니다. 어떤 상황이냐에 따라 신중하게 고려해야 할 문제이죠. 어떤 작업에 대한 결과(응답)를 가지고 다음 작업을 수행해야 할 상황은 분명 존재하기 마련입니다. 이 때는 필수적으로 동기 작업이 필요한 상황이죠.
예를 들어, 우리가 결제를 한다고 생각해봅시다. 내가 가진 돈이 10000원인데 8000원 짜리 국밥과 5000원 짜리 담배 결제를 비동기식으로 처리할 수 있을까요? 국밥을 결제하고 남은 2000원으로 담배를 사려고 할 때, 남은 돈이 부족하기 떄문에 해당 결제 처리를 해서는 안될 것입니다. 비동기식으로 동시에 해버리면 국밥도 결제가 가능하고 담배도 결제가 가능하기 될 겁니다. 국밥 결제에서 남은 돈 2000을 응답으로, 담배 결제에서는 5000원을 응답으로??? 이래서는 안되겠죠.
물론 해당 예시는 현실에서는 결제 시스템의 데이터 베이스에서 Transaction 에서 처리를 하게됩니다. 조금 더 나아가보면 여기서 현재 내 잔액은 서로 다른 스레드(프로세스)가 동시에 접근을 해서는 안되는 Crtiical Section 입니다. Lock 과 같은 동기 처리가 필요하죠. 이것에 대한 글은 OS 에 Concurrency Problem 파트에 보다 자세히 정리를 해놓았습니다.☺️
부록: Python
그러면 이 비동기 처리에 대해서 파이썬에서는 어떻게 하는 지 알아보도록 해봅시다. 새로운 실행 흐름을 만들기 위해서는 새로운 Thread(스레드) 와 Process(프로세스) 를 파야 합니다. (각각에 대한 설명은 제 OS 파트에...). 보다 가벼운 스레드를 사용하고 이를 위한 threading 모듈이 존재하지만...
파이썬(Cpython)은 한 번에 하나의 스레드밖에 처리하지 못한다고 합니다!!!😱 이는 전역 인터프리터 록(GIL)이라는 표준 파이썬 시스템의 구현 사항 때문이라고 하는데요. 그래서 여러 스레드를 만들게 되면 여러 개의 CPU 코어들을 사용하는 것이 아니라 CPU 하나에서 Context-Switching을 반복하며 돌아가는 것입니다. 그래서 코어 활용률은 올라가겠지만 실질적으로 동시적이고 빠른 수행을 기대할 순 없는 것이지요. 그래서 CPU 리소스를 효율적으로 쓰기 위해서는 multiprecessing 모듈로 프로세스를 활용한 병렬 프로그래밍을 하라고 합니다.(파이썬 공식문서에서)
하지만 CPU-bound 작업이 아닌 I/O-bound 작업인 경우, 여전히 스레드 기반의 병렬 처리 모델이 효과적일 수 있습니다. I/O-bound 작업은 CPU가 아닌, 파일의 경우 저장장치 디바이스에서, 네트워크의 경우 네트워크 인터페이스 카드(NIC)에서, 쿼리의 경우 데이터베이스에서 수행하기 떄문이죠. 스레딩을 통해 Non-blocking을 유도하여 충분히 동시적으로 수행할 수 있는 겁니다.
그런데 Python 에서 개발자가 직접이 스레드를 관리하는 것은 여간 복잡하고 어려운 작업이 아닐 수 없습니다. 그래서 3.4 버전부터 Python에서는 I/O 작업에 대한 비동기 프로그래밍을 효율적으로 지원하기 위한 asyncio 라이브러리를 비동기 표준 라이브러리로써 지원하고 있습니다. 이 친구를 중심으로 알아보도록 합시다!
asyncio
asyncio는 Coroutine과 Task를 동작시키기 위한 high-level의 API들을 의미합니다. 먼저, Coroutine에 대해 알아봅시다.
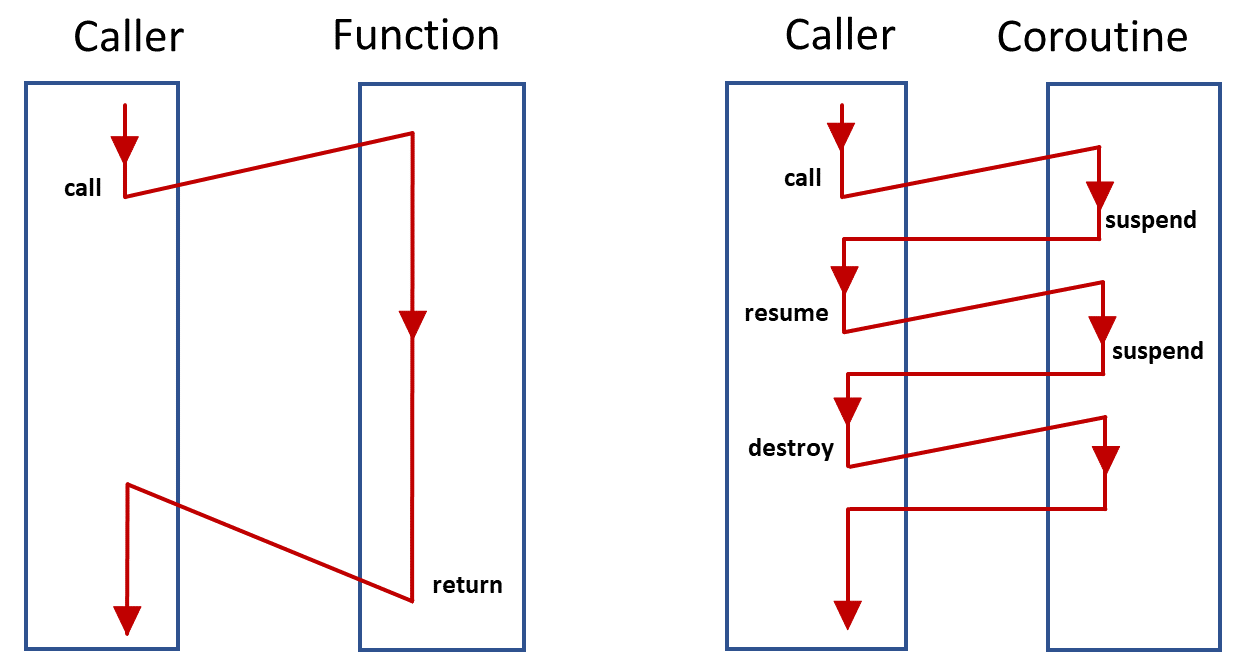
출처: https://www.modernescpp.com/index.php/implementing-futures-with-coroutines
Coroutine(코루틴)이란 쉽게 말해 우리와 친근한 함수(Subroutine(서브 루틴))의 일종입니다. 공식 문서에서는 더 일반화된 형식이라고 표현합니다. 이 코루틴이 일반적인 서브 루틴과 같는 가장 큰 차이는 시작과 종료만 존재하는 서브 루틴과 달리 코루틴은 중간에 다양한 시점에서 멈추고 재개하는 것이 가능합니다. 동작과 정지가 매우 자유로운 것이죠. 코루틴들끼리 더 오래 걸리면 잠시 하던 일을 멈추고 다른 코루틴을 기다려주고...하는 것들이 가능합니다. 이렇듯 완전한 Non-blocking을 유도함으로써, 동시 처리에 사용할 수 있는 것이죠.
코루틴은 프로세스보다 가벼운 스레드보다도 훨씬 가볍습니다. 스레드는 그래도 운영체제의 관리 내에서 돌아가는 하나의 실행 흐름이지만 코루틴은 그저 언어 단위에서의 실행 흐름이기 때문이죠. 이 말인 즉슨 단순 메모리 차원뿐만 아니라 생성하고 실행하고 제거하는 것이 스레드보다도 훨씬 빠르다는 것입니다. 결과적으로 하나의 스레드 내에서는 여러 코루틴이 실행되게 됩니다.
코루틴은 마치 Promise처럼 하나의 객체로 구현됩니다. 이 Coroutine을 만들기 위해서는 일반적인 함수에 async def 라는 키워드를 붙여 생성할 수 있습니다. 아래는 공식 문서에서 제공하는 코드입니다.
import asyncio
async def main():
print('hello')
await asyncio.sleep(1)
print('world')
asyncio.run(main())여기서 await 은 하나의 코루틴이 다른 코루틴을 실행시키고 그것의 완료를 기다리도록 하는 것입니다. 1초 동안 가만히 있는 코루틴을 기다리는 것이지요. 마지막 asyncio.run() 함수는 코루틴을 실행하도록 하는 함수입니다.
asyncio 에서 이러한 코루틴들을 돌리고 멀티태스킹을 관리하는 주체를 Event loop(이벤트 루프) 라고 합니다. run() 매개변수 안에 코루틴을 직접 실행시킴으로써 이벤트 루프를 생성하고 해당 코루틴을 메인 엔트리로 등록하고 해당 코루틴이 끝이나면 이벤트 루프를 종료하는 것입니다. 이 이벤트 루프는 기본적으로 스레드 당 하나이기 때문에, 한 번만 호출되는 것이 이상적이라고 합니다. 메인 스레드에 하나의 이벤트 루프가 생기면 이 친구 하나가 각종 스레드 풀과 프로세스 풀까지 관리를 하면서 동시성을 확실하게 수행하는 구조입니다. 따라서 run() 함수도 현재 스레드에 다른 이벤트 루프가 동작 중이면 호출할 수 없다고 합니다.
위와 같이 코루틴을 실행시킬 경우, hello 가 나오고 1초 뒤에 world가 나오게 됩니다. asyncio.sleep(1) 이라는 코루틴이 종료된 후에 실행할 print('world') 를 동기적인 코드로 작성할 수 있습니다. (asyncio.sleep()은 새로운 코루틴으로써 자신의 코루틴을 1초 동안 멈추 도록 하는 코루틴입니다.)
자 그럼, 이어서 다음 코드를 보도록 합시다.
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"started at {time.strftime('%X')}")
await say_after(1, 'hello')
await say_after(2, 'world')
print(f"finished at {time.strftime('%X')}")
asyncio.run(main())결과는 다음과 같습니다.
started at 15:54:20
hello
world
finished at 15:54:233초가 걸렸네요? 우리가 기대하던 대로 동시적으로 수행하지는 않습니다!!!😨 하하 여러 코루틴을 동시적으로 실행하기 위해서는 이 코루틴을 Task 객체로 감싸줘야 합니다. Task는 코루틴을 concurrently 하게 스케줄하기 위한 것으로, 더 low-level 한 Future 객체를 상속한 것입니다. 코루틴이어도 각 코루틴을 await 하면 이벤트 루프는 그저 해당 코루틴이 끝날 때까지를 기다렸다가, 다음 코루틴을 실행할 뿐입니다. 동시성을 위해서는 코루틴 여러 개를 한 번에 이벤트 루프에 등록해야 하는데 이를 위해 Task로 감싸야 하는 것이죠. 공식문서 피셜, 일반적인 어플리케이션 레벨의 코드에서는 Task를 쓰지 Future은 쓸 필요가 없다고 하네요~
async def main():
task1 = asyncio.create_task(say_after(1, 'hello'))
task2 = asyncio.create_task(say_after(2, 'world'))
print(f"started at {time.strftime('%X')}")
await task1
await task2
print(f"finished at {time.strftime('%X')}")started at 16:29:20
hello
world
finished at 16:29:22위와 같이 이번에는 총 2초가 걸린 것을 확인할 수 있습니다. asyncio.create_task() 함수는 코루틴을 Task 객체로 감싸는 것과 동시에 그것의 실행을 스케줄 합니다. 이렇게 하면 코루틴 main이 IDLE 상태, 즉 실행되고 있지 않은 상태일 때 Event loop 는 task1과 task2를 실행시키게 됩니다. task1이 동작하자마자 1초 동안 IDLE 한 상태가 되니, task2를 동작시키게 되고 1초가 지난 후 task1이 완료되면 그 다음 task2가 남은 1초의 IDLE 상태가 끝나고 반환되는 흐름을 가집니다. 물론 await 으로 기다려주지 않으면 main 코루틴은 기다림 없이 가차없이 자기 일을 종료하고 끝내게 됩니다.
번외로, 위와 같은 코드를 파이썬 3.11 이상의 버전부터는 아래와 같이 asyncio.TaskGroup 으로 사용할 수 있다고 합니다. 여러 개의 tasks를 생성하여 동시에 돌리고 그들의 완료를 기다려주는 가장 모던한 방법이라고 하네요:)
async def main():
async with asyncio.TaskGroup() as tg:
task1 = tg.create_task(say_after(1, 'hello'))
task2 = tg.create_task(say_after(2, 'world'))
print(f"started at {time.strftime('%X')}")
print(f"finished at {time.strftime('%X')}")하나의 스레드이지만 asyncio의 이벤트 루프를 통해 I/O-bound 작업들을 태스크(코루틴)로써 동시적으로 처리할 수 있었습니다. 어차피 CPU에 올라타지 않는 작업들을 스레드보다 훨씬 더 가벼운 코루틴을 통해서 보다 효과적으로 동시성을 달성한 것이지요. 부록으로, asyncio에서는 async 가 붙지 못한 일반 함수들을 위해서 asyncio.to_thread() 를 제공하고 있습니다. 코루틴으로써 동작하지는 못하니까 새로운 스레드에 할당해주는, 위에서 보았던 threading 모듈을 보다 손쉽게 제공해주는 것이지요. 물론 말씀 드렸다시피, GIL로 인해서 CPython에서만큼은 크게 의미가 없지만요...😅
파이썬의 웹 프레임워크인 Starlette 에서 위의 내용을 확인할 수 있습니다. 경로로 지정되어 호출되는 함수가 async def 라면 코루틴을 통해서, def 라면 외부의 스레드 풀을 사용해서 작업을 처리하고 이를 await 하죠. 먼저 응답을 보내고 실행하기 위한 Background tasks도 마찬가지 입니다.

출처: Starlette - background.py - class BackgroundTask
Concurrency & Parallelism
여기서 한 번 짚고 넘어가야 할 부분이 바로 동시성과 병렬성 의 차이입니다. Asynchronous 라는 개념은 엄밀히 따지면 동시성이라고 합니다. 동시성과 병렬성 모두 서로 다른 일들이 거의 같은 시간 내에 일어난다는 개념 때문에 완전히 같다고 생각하기 일쑤입니다.
먼저 더 간단한 병렬성은 말 그대로 여러 개의 작업들이 진짜로 같은 시간에 돌아가는 것을 뜻합니다. 컴퓨터에서 이를 달성하기 위해서는 여러 개의 코어, 즉 프로세서가 있어야 합니다. 하지만 동시성은 꼭 같은 시간일 필요는 없습니다. 동시성은 작업의 시작과 종료에 걸치는 기간이 겹치는 것에 초점을 맞춥니다. 예를 들어 만약 프로세서가 하나라면 하나에서 여러 작업들이 이루어져야 하죠. 만약 A가 끝나고 B가 끝난다면 이는 동시성을 만족하지 못합니다. 하지만 A를 진행하다 잠시 멈추고 B를 진행한다음 다시 A로 돌아와 작업을 마친다면 이는 동시성을 만족한 것입니다. 물론 A가 멈출 필요 없이 병렬적으로 진행된다면 더욱 빠르고 효과적일 것이고, 이것이 FastAPI에서 병렬적이지 않은 NodeJS보다 높은 성능을 낸다고 자부하는 이유 중에 하나입니다.
정리해서, 최종적으로 코루틴이란 커널에서 스케줄링하는 스레드와 달리, 하나의 스레드에서 개발자가 직접 스케줄링 하여 서로 상호 협조적으로 일시 정지와 재개를 반복하며 멀티태스킹을 할 수 있도록 해주는 동시적(비동기)인 아름다운 개념이 되겠습니다.😉
참고한 글들 (...이외 수많은 글들)
너무 많아 일일히 첨부 불가....🤮

명확한 해설 감사합니다.
비슷한 task를 진행중인데 많은 도움이 되었어요 :)