
포스팅에 잘못된 디버깅 내용과 그를 기반으로 잘못 작성된 내용이 있어 내용을 전반적으로 수정했다.
수정내역 (v0 -> v1)
- 주석 내용 분석 추가
- 잘못된 디버깅 내용 수정 (String hash 체크 및 Map 체크)
이건 솔직히 이해가 안된다... IDE 는 나한테 왜 그랬을까? - heap, stack 관련 내용 추가
최근 개발 관련 질문을 받고 내가 미처 깊게 못 바라본 내용이 많다는 생각이 들었다.
그래서 (github actions 을 또!!! 미루고) 이 시리즈를 먼저 작성해야겠다는 생각이 들었다.
equals() 와 hashCode()
먼저 이 두개의 뜻을 어떻게 이야기할 수 있을까?
Kotlin 에서 equals() 와 hashCode() 선언부를 찾으면 바로 나오는 부모 함수들의 주석을 보자
equals()
일부 다른 개체가 이 개체와동일한지 여부를 나타냅니다.
구현은 다음 요구 사항을 충족해야 합니다.
- 재귀
null이 아닌 값 x에 대해x.equals(x)는 true를 반환해야 합니다.대칭
null이 아닌 값 x 및 y 에 대해 x.equals(y) 는
y.equals(x)가 true를 반환하는 경우에만 true를 반환해야 합니다.전이
null이 아닌 값 x, y 및 z에 대해 x.equals(y)가 true를 반환하고
y.equals(z)가 true를 반환하면 x.equals(z)가 true를 반환해야 합니다.일관성
null이 아닌 값 x 및 y에 대해 x.equals(y)를 여러 번 호출하면
객체에 대한 equals() 비교에 사용된 정보가 수정되지 않는 한
일관되게 true를 반환하거나,일관되게 false를 반환합니다.- null과 같지 않음
null이 아닌 값 x에 대해x.equals(null)는 false를 반환해야 합니다.
hashCode()
개체에 대한hashCode 값을 반환합니다. hashCode 의 일반 계약은 다음과 같습니다.
동일한 개체에서 두 번 이상 호출하더라도hashCode() 는 일관되게 동일한 정수를 반환해야 합니다.
(equals() 가 변형되지 않았을 때를 한정 -> 사실 이 뜻이 맞는지를 잘 모르겠다.)equals() 에 따라 두 객체가 같으면, 두 객체 각각에 대해hashCode()를 호출하면
동일한 정수 결과가 생성되어야 합니다.equals() 가 다르더라도, 각hashCode()에서 각고유한 정수를 반환하지 않을 수 있다
하지만hashTable 성능을 위해서라면 이건 꼭필요한 조건이다.일반적으로 객체의 내부 주소를 정수로 변환하여 구현되지만,
이 구현 기술은 Java 프로그래밍 언어에서 필요하지 않습니다.
hashCode() 3, 4 의 경우 Object 의 설명도 일부 가져왔다.
하지만 여기서 포스팅을 끝내도 될 정도로 주석에는 많은 내용을 설명하고 있었다.
블록친 내용만 본다면 여기 포스팅에 작성될 내용과 똑같다.
그 외 특징으로는 아래와 같다.
1. Java에서 ==(동등성 비교) 의 경우 hashCode() 먼저 비교하여 다르면 아예 false 를 내버린다.
2. Kotlin Data class 에서, Array 프로퍼티가 있을 경우 equals(), hashCode() 구현을 권장한다.
이제 위 내용들을 참고하여 깊게 들어가보자
1. 일반 hashCode() 는 정말 주소값을 활용할까?
(위에 주석에서도 확인했겠지만) 맞는 말이다.
Object의 hashCode() 메소드는 heap 에 저장된 객체의 메모리 주소를 활용하여 int 형태로 리턴하기 때문이다.
의심이 간다면 위 주석에 언급된 내용을 못 믿는 것이므로, javadoc 의 hashCode() 부분의 This is typically implemented by converting the internal address of the object into an integer 를 보면 될 것이다.
2. primitive 타입의 경우 == 을 해도 문제가 없을까? ( + wrapper 타입 복습)
primitive 타입을 == 로 비교해도 문제 없는 이유를 언급한 글과 직접 비교한 글 을 참고하였다.
변수 선언부는 Java Runtime Data Area의
Stack 영역에 저장된다.
해당 변수에 저장된 상수는 Runtime Constant Pool 에 저장된다.Stack의 변수 선언부는 해당 Runtime Contant Pool 의 주소값을 가진다
만약 다른 변수도 같은 상수를 저장하고 있다면, 이 다른 변수도 같은 Runtime Contant Pool의 주소값을 가진다.
엄밀히 말하면 primitive type 역시 주소값 비교가 되는 것이다.
(= Runtime Constant Pool 의 주소값 비교)
위 말이 맞는지 직접 확인해보자. 깊은 이야기를 하기 위해 Wrapper 타입 변수도 언급할 예정이다.
1. Integer(int)
Integer i1 = new Integer(3);
Integer i2 = new Integer(3);
int i3 = 3;
int i4 = 3;
System.out.println(i1.hashCode());
System.out.println(i2.hashCode());
System.out.println(i3);
System.out.println(i4);
System.out.println(i1 == i2);
System.out.println(i1.equals(i2));
System.out.println(i2 == i3);
System.out.println(i2.equals(i3));
System.out.println(i3 == i4);위 코드의 결과를 이야기하면 아래와 같다.
- i1, i2, i3, i4 의
hashCode()는 전부 같다 - new 를 통해 새로운 공간을 할당받은 변수 비교(
i1 == i2) 이외에는 전부 true 이다.
상수인 i3, i4 가 Runtime Constant Pool 의 주소값을 갖는지는 알 수 없지만
저 두개의 값은 같으므로 정상적으로 실행된다는 건 확인할 수 있다.
그런데 여기서 궁금한 점이 생긴다.
1. 왜 Wrapper 타입 변수를 직접 비교하는 케이스(i1 == i2) 이외에는 전부 true 일까?
얕게 확인했을 경우 마지막 라인 (i3 == i4) 이외에는, 모두 false 가 나올걸로 예상했을 것이다.
왜 전부 true 일까?
Integer 과 Long 에서는 equals() 와 hashCode() 를 미리 구현해놓아서 그렇다.
아래는 Integer 에 구현된 equals() 와 hashCode() 이다.
public static int hashCode(int value) {
return value;
}
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}위의 미리 구현되어있는 로직으로 인해, 우리는 true 를 얻을 수 있다.
2. 그러면 i1, i2 는 왜 다를까?
Java 메모리학 차원에서 접근해보자
i1,i2,i3,i4 는 main() 함수내에서 실행될 것이기 떄문에 지역변수이다.
우리는 지역변수 및 매개변수 등은 stack 영역에 관리된다는 걸 알고 있을 것이다.
그리고 실제로 primitive 값 또는 Wrapper 타입 인스턴스의 참조값이 stack 영역에 들어갈 것이다.
(당연히 Wrapper 타입 인스턴스는 heap 영역 에 들어갈 것이다.)
그리고 Integer 은 불변 객체이다. 실제 생성자를 통해 들어가는 값은 아래와 같이 선언되어 있다.
private final int value;바꿀 수 없는(immutable) 값이므로 Integer(3) 을 통해 생성된 건 각각 인스턴스가 생기고
i1, i2 는 각각의 인스턴스들을 바라보게 될 것이다. 실제로 디버그상 캡처를 찍어보면 어떨까?
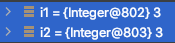
작고 귀여운 이 사진은 객체의 주소값이 동등성 비교에 영향을 끼친다는 말 과 더불어
i1, i2 가 다른 이유도 명쾌하게 설명해줄 수 있을 것이다.
2. String
String 타입은 어떨까?
String 타입은 primitive 타입은 아니지만, Integer 처럼 equals() 와 hashCode() 는 구현되어 있다.
String s1 = new String("a");
String s2 = new String("a");
String s3 = "a";
String s4 = "a";
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
System.out.println(s3);
System.out.println(s4);
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
System.out.println(s2 == s3);
System.out.println(s2.equals(s3));
System.out.println(s3 == s4);String 은 좀 다르게 s2 == s3 도 false 이다.
hashCode() 를 보아도 차이가 없고, equals() 도 true 인데 무엇이 문제일까?
이것도 메모리학 관점에서 보아야 한다.
new 형태로 처리한 인스턴스는 각각의 객체들이 생기고, "" 형태(리터럴 형태)로 주입한 건 String 상수 pool 에 들어간다.
이는 가리키는 참조값 자체가 다르므로 당연히..! false 이다.
참고로 String.hashCode() 의 경우 아스키코드값을 일일히 더하는 느낌이 든다.
자세한 내용은 직접 확인해보는 걸 추천한다.
3. 커스텀 클래스
커스텀 클래스는 얄짤없다.
Person p1 = new Person("", 3);
Person p2 = new Person("", 3);
System.out.println(p1.hashCode());
System.out.println(p2.hashCode());
System.out.println(p1 == p2);
System.out.println(p1.equals(p2));
...
static class Person {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}얄짤없이 hashCode() 도 전부 다르고 모두 false 이다.
커스텀 클래스인 경우에는 객체를 정상적으로 비교하려면 equals() 도 구현해주어야 할 것이다.
(이 자리를 빌어 Kotlin data class 의 감사함을 다시 한 번 느껴보자)
3. hashCode() 와 Hash Collection
위에 언급했던 javadoc 의 hashCode() 에는 아래의 이야기가 있다.
If two objects are equal according to the equals(Object) method, then calling the hashCode method on each of the two objects must produce the same integer result.
equals(Object) 메서드에 따라 두 객체가 같은 경우
두 객체 각각에 대해 hashCode 메서드를 호출하면 동일한 정수 결과가 생성되어야 합니다.
맨 위 hashCode() 주석 설명에서 언급했던 3번이다.
실제 Object 에 구현된 hashCode() 메서드를 사용하면
커스텀 클래스의 경우 hashCode() 가 무조건 다르게 나오는 걸 확인할 수 있다.
그리고 객체 비교를 원활히 하기 위해 우리는 equals() 를 구현하는 경우가 많다.
그런데 우리는 종종 equals() 와 hashCode() 는 일심 동체로 움직여야 한다고 이야기한다.
실제로 Kotlin data class 에서 array 타입 변수를 넣을 시
equals() 와 hashCode() 모두를 구현하라는 경고가 나온다.

왜 그런걸까? 이는 Hash Collection 과 연계해보면 이해할 수 있다.
여기에서는 주석 설명에서 언급되었던 HashTable 을 기준으로 설명해보겠다.
1. HashTable 로 확인해보기
Person p1 = new Person("", 3);
Person p2 = new Person("", 3);
Hashtable<Person, String> hashTable = new Hashtable<>();
hashTable.put(p1, "a");
hashTable.get(p1);위와 같이 HashTable 을 사용한다고 생각해보자.
우리는 hashTable 에서 어떻게 a 값을 가져올 수 있을까?
HashMap 의 get() 을 보면 아래와 같이 구현되어 있다.
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}보이는가? 3번째 줄에서 Object.hashCode() 를 활용하고 있다.
더불어 Object.equals() 도 활용하고 있다.
실제 내부 로직을 보면 나머지는 hashCode 값을 활용해 key index 를 구하고,
그 인덱스에 매치되는 값들의 linkedList 형태의 collection 에서
hashCode() 가 같으면서 equals() 가 true 인 값을 찾아 반환한다.
우리는 이 덕분에 equals() 와 hashCode() 가 긴밀한 관계를 갖는다는 걸 알 수 있고,
이것들이 HashTable 에도 크게 영향을 끼친다는 걸 알 수 있다.
2. hashCode() 를 일부로 통일시켜보기
만약 위의 Person 클래스에서 hashCode() 를 강제로 1 로 리턴하게 하고,
아래와 같이 작성하면 어떻게 동작할까?
Hashtable<Person, String> hashTable = new Hashtable<>();
hashTable.put(p1, "a");
hashTable.put(p2, "b");
hashTable.get(p1);놀랍게도 아무런 일도 없다.
hashCode 체크 로직에서는 이미 true 이고, equals() 는 정상적으로 동작하기 때문에 문제가 없는 것이다.
다만 hashCode() 차원에서 체크가 안되기 때문에, 불필요한 체크를 더 할 수는 있다.
참고로 HashMap 에서는 어떨까?
이 경우에도 문제가 없다.public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } /** * Implements Map.get and related methods. * * @param hash hash for key * @param key the key * @return the node, or null if none */ final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }여기에서도 equals() 를 사용하고 있기에 문제없이 가져올 수 있다.
로직적으로 문제가 없는데 왜 우리는 두 개를 같이 구현해서 문제를 해소해야 한다고 할까?
이건 주석과 hash 충돌 개념을 복기하면서 답을 얻을 수 있다. 우선 hashCode() 3번을 다시 보자
-
hashTable 성능을 위해서라면 이건 꼭필요한 조건이다.
성능이라고 했지 동작이라고 하지 않았다. 성능을 개선하기 위한거란 건 ok -
hash 충돌
우리는 hash 충돌에 대해 책에서 배운적이 있다.
해시 충돌을 막기 위해 value 부분을 list 형태로 해서 처리한다는 이야기를 본 적이 있을 것이다.
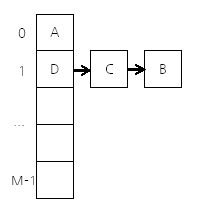
위 그림을 기억한다면 ok! 그런데 우리는 위에서 equals() 라는 안전장치 덕분에 문제 없이 값을 뽑아온다고 했었다.
그럼 이제 답은 나왔다. hashCode 가 1 인 개체들이 list 형태로 있고,
거기서부터 순차적으로 equals() 를 돌려 확인하는 것이다. (D -> C -> B)
우리가 Map, Table 개념을 쓰는 건 O(1) 을 바라고 쓰는 거지, O(N) 을 바라고 쓰는 건 아닐 것이다.
성능상으로 문제 없이 사용하기 위해 우리는 hashCode() 와 equals() 를 똑바로 구현해야 하고,
하나라도 새로 구현 시 모두 새로 구현해야 한다.
4. hashCode() 에서 31을 곱한 수를 더하는 이유
Kotlin data class 에서 hashCode() 와 equals() 를 generate 하거나 hashCode() 예제를 보면 대체로 아래와 같이 31 을 곱한다.
data class User(
val name: String,
val age: Int,
var array: Array<String>
){
...
override fun hashCode(): Int {
var result = name.hashCode()
result = 31 * result + age
result = 31 * result + array.contentHashCode()
return result
}
}간단하게 effective Java 에서 설명하고 있다고 한다.
수식의 31은 소수이기 때문에 선택한 것이다.
만일 이 값이 짝수면서 곱셈의 결과가 오버플로우 되었다면 해시 값이 유실되었을 것이다.
2(의 배수)를 곱한다는 것은 비트의 이동을 의미하기 때문이다.
소수를 사용했을 때 어떤 장점이 있는지는 분명하지 않지만 관례적으로 그렇게 한다.
31의 좋은 점은 비트 이동과 뺄셈으로 곱셈을 대체할 수 있어서 성능을 향상시킬 수 있다는 것이다.즉 31*i는 (i<<5)-i와 같다.
근래의 자바VM들은 이런 부류의 최적화를 자동적으로 수행한다.
5. interface 타입에서 equals() 를 사용할 수 있을까?
일단 사용 할 수 있다. 아래의 예제를 보자
interface B
data class C(val name: String) : B
...
val c1: B = C("")
val c2: B = C("")
c1 == c2 // kotlin 코드이므로 c1.equals(c2) 와 동일하다.위와 같이 사용될 경우 Any 타입의 equals() 로 연결된다.
그러나 최종적으로는 C의 equals() 가 실행되어 true 가 나올 것이다.
Java 의 경우에는 Object 타입의 equals() 로 연결된다.
(물론 Java 역시 하위클래스에서 구현한 equals() 에 따라 반환 값은 달라질 수 있다.)
그런데 간헐적으로 이런 사례가 있다.
필자는 DiffUtil 내에서 interface 를 비교하면서 발견했던 이슈였다
object : DiffUtil.ItemCallback<B>() {
override fun areItemsTheSame(oldItem: B, newItem: B): Boolean {
return oldItem == newItem
}
override fun areContentsTheSame(oldItem: B, newItem: B): Boolean {
return oldItem == newItem // == 에 빨간줄이 생긴다.
}
}위 코드의 경우 areContentsTheSame() 의 == 에 빨간줄이 생기면서 아래와 같은 에러가 발생한다.
Suspicious equality check: equals() is not implemented in B신기한 건 areItemsTheSame() 에서는 이런 에러가 발생하지 않는다는 것이고,
실제로 DiffUtil 의 areItemsTheSame(), areContentsTheSame() 을 비교해보아도 명세는 같다.
그리고 interface 에 equals() 함수를 override 하면 없어진다.
override 가 가능하다는 건 interface 는 이미 equals() 를 가지고 있다는 의미이기도 하다.
정리해보면 상당히 당황스러워질 수 있다...
안될꺼면 다 안되든가.... 그렇다고 찾지 못하는 것도 아니고... 뭘까?
사실은 Linter 가 트리거하지 못해 발생하는 Lint 에러이다.
사실 영어를 자세히 해석해보면 아래 내용과 같다.
의심스러운 동등성 검사 : B 에 equals() 가 포함되지 않았습니다.실제 의심만 할뿐 빌드나 Run 을 하면 정상적으로 동작된다...
처음에 이걸 보고 나는 엄청난 분노 게이지의 상승을 느낄 수 있었다. \ _ /
차라리 warning 이라고 뜨면 이해라도하지, 왜 컴파일 에러라고 떠서 사람을 긴장시키는 것인가.....
그리고 난 실제 에러로 착각했었다....
이에 대한 추천방식으로는 areContentsTheSame() 내에 타입검사를 조건문에 넣기,
equals 를 재정의한 새로운 인터페이스를 상속받기, 상위 클래스에 단순 선언하기 였다.
어짜피 선언하더라도 자식 클래스의 equals() 를 실행하기 때문에 로직상 문제는 없다고 한다.
IDE 설정에서 warning 을 지우거나 @SuppressLint("DiffUtilEquals") 추가도 있었지만 이는 별로 좋지 않는 방법이라 한다
혹여나 해당 부분으로 리뷰를 받게 되면 이 링크를 언급하며, equals() 를 추가시키거나 문제 없는 코드라고 어필하자.
참고
1. [java] hashcode()와 equals() 메서드는 언제 사용하고 왜 사용할까?
2. JavaDoc Object
3. 자바 hashCode()
4. Why does Java's hashCode() in String use 31 as a multiplier?
5. equals와 hashCode를 같이 재정의해야 하는 이유
6. Lint Error: Suspicious equality check: equals() is not implemented in Object DiffUtilEquals
7. [Java] equals() & hascode() 메서드는 언제 재정의해야 할까?
8. [JAVA] JAVA 메모리 이야기 - Stack 과 Heap
9. Java HashMap은 어떻게 동작하는가?
