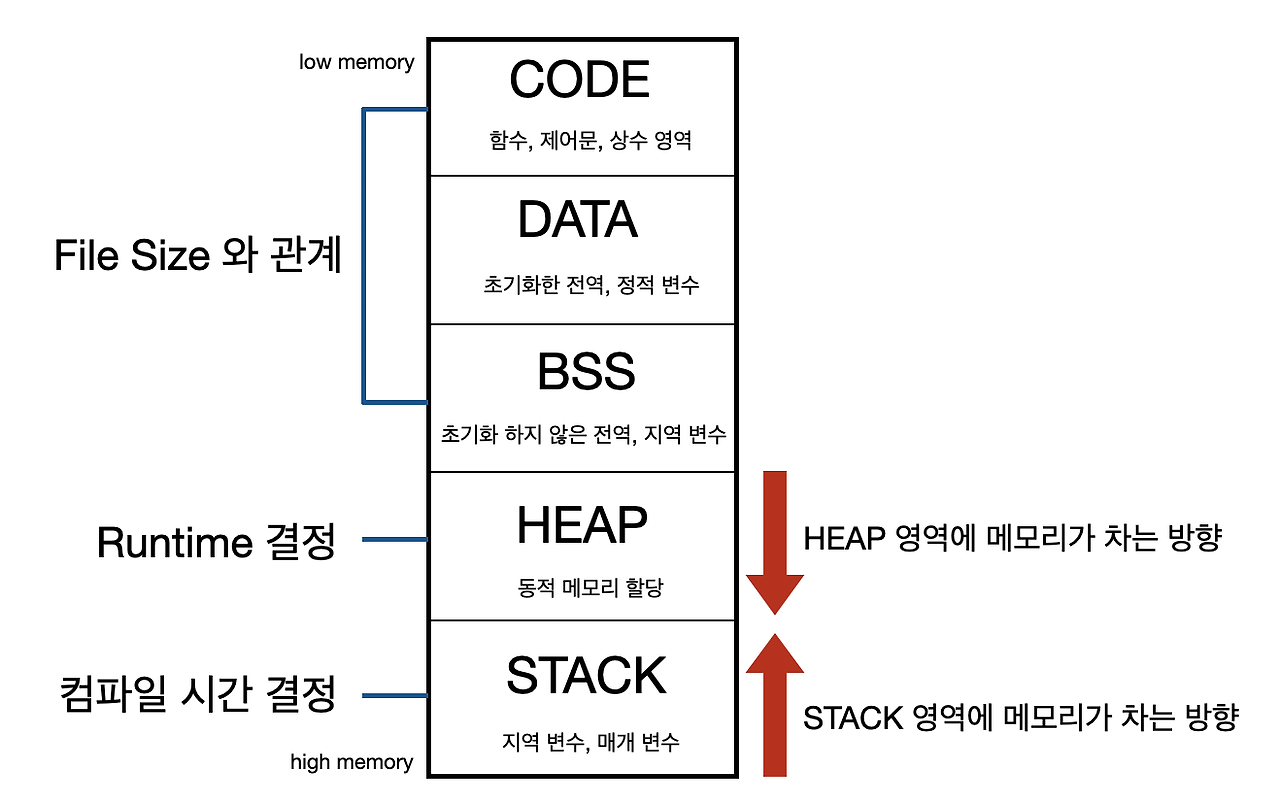
데이터 영역은 크게 5가지로 나눌 수 있다.
- 실행하는 프로그램의 코드가 저장되는 Code 영역
- 초기화된 전역 변수, Static 변수가 저장되는 Data 영역
- 초기화 되지 않은 전역 변수, Static 변수가 저장되는 BSS(Block Started by Symbol) 영역
- 사용자가 직접 관리하고 동적 할당하는 Heap 영역
- 지역 변수나, 매개변수가 저장되는 Stack 영역
메모리 영역은 Code영역(예 : 0X0000)에서 Stack(예 : 0XFFFF)로 갈수록 메모리 주소가 커진다.
Code 영역
Code 영역은 말그대로 프로그램이 실행하는 Code가 저장되는 영역이며, Text 영역으로도 불린다.
이러한 Code들은 0과 1로 이루어진 기계어 형식이며, 수정을 막기 위해 Read-Only로 저장된다.
코드가 저장되는 순서는 다음과 같다
- 소스 코드 -> 어셈블리 코드
- 사람에 의해 작성된 코드가 컴파일러를 통해 어셈블리 코드로 변환
- 어셈블리 코드 -> 기계어 코드
- 어셈블러에 의해 기계어로 변환
- 기계어 : CPU가 직접 해석하고 실행할 수 있는 Binary 명령어
- 기계어 코드 -> Code 영역에 저장
- 실행 가능한 Binary 파일(예:ELE, PE)이 생성되고, 실행 시 코드 영역에 로드
고수준 코드 -> 어셈블리어 -> 기계어 변환 과정
//소스 코드 int x = 5; x = x + 2;//어셈블리 코드 mov eax, 5 ; x에 5을 저장 add eax, 2 ; x에 2을 더함// 기계어 (바이너리 코드) B8 05 00 00 00 ; mov eax, 5 (opcode: B8, operand: 05) 83 C0 02 ; add eax, 2 (opcode: 83, operand: C0 02)
Data 영역
Data영역은 프로그램의 초기화된 전역 변수와 Static 변수가 저장되는 메모리 영역이다.
Data영역은 프로그램이 실행되기 전에 초기화되며, 실행 종료 까지 유지된다.
메모리의 크기 결정과 메모리 할당을 구분지어야 한다.
Data영역을 예로 들자면, Data 영역의 크기는 컴파일 타임에 고정된다.
하지만 Data영역의 메모리 할당과 소멸은 프로그램 시작, 종료시에 이뤄진다.
Data영역의 주요 특징은 4가지다
- 초기화된 데이터 저장
- 프로그램에서 명시적으로 초기값을 갖는 전역 변수와 static 변수가 저장
int a = 10; // 초기화된 전역 변수
static int b = 20; // 초기화된 static 변수 - 프로그램 시작시 초기화
- Data 영역에 저장된 변수들은 프로그램이 실행되기 전에 초기값으로 초기화
- 프로그램이 종료될때까지 값 유지
- 정적 메모리 할당
- Data 영역의 변수들은 실행 시간 동안 메모리에서 고정된 공간 차지
- Heap, Stack처럼 동적으로 할당되거나 해제되지 않음
- 읽기 / 쓰기 가능
- 실행 중에 값을 변경할 수 있도록 읽기/쓰기 가능
BSS 영역
BSS 영역은 Data 영역과 다르게 초기화 되지 않은 전역 변수와 Static 변수를 저장하는 영역이다.
이러한 전역변수, 정적변수는 C언어 기준으로 자동으로 0으로 초기화 된다.
#include <stdio.h>
int a; // 전역 변수, 초기화되지 않으면 0으로 초기화됨
void foo()
{
static int b; // static 변수, 초기화되지 않으면 0으로 초기화됨
printf("a: %d, b: %d\n", a, b);
}
int main()
{
foo();
return 0;
}또한 BSS 영역의 변수들은 값이 없고 단지 크기만 있는데, 실행 파일에 값이 기록되지 않으며, 이는 파일의 크기를 줄이기 위해서 이다.
Heap 영역
Heap 영역은 동적 메모리 할당을 위해 사용하는 메모리 영역으로, 주로 프로그램 실행 중에 크기가 결정되는 메모리 블록을 관리한다.
프로그램 실행중에 동적으로 메모리 할당을 받으며 이는 런타임에 메모리를 할당받고 해제할 수 있다는 뜻이다.
동적 메모리 할당
Heap은 프로그램 실행중 메모리를 할당받으며, malloc(), new와 같은 함수를 사용해서 런타임중에 동적 할당이 가능하다.
동적 메모리 할당에 관해서는 더 자세하게 공부하여 게시할 예정이다.
//예시
int main() {
// 동적으로 메모리 할당 (힙에 메모리 할당)
int* p = new int; // 'p'는 힙에 int 크기만큼 메모리를 할당받음
// 메모리에 값 할당
*p = 25; // 할당된 메모리 공간에 25 값을 저장
// 출력
std::cout << "Value stored in heap memory: " << *p << std::endl; // 25 출력
// 동적으로 할당한 메모리 해제
delete p; // 힙 메모리에서 할당된 공간을 해제
return 0;
}p는 Stack에 할당된 포인터 변수이고, 이 포인터가 가리키는 메모리는 힙에 할당된다
이쯤에서 stack과 data가 헷갈렸는데, 간단하게 정리하면 다음과 같다
- 자료형이나 자료구조에 관계없이, [전역 변수]나 [Static 변수]는 Data 영역에 할당된다.
- [지역 변수]나 [매개 변수]는 Stack 영역에 할당된다.
Heap 정리
Heap 영역은 프로그램 실행중(Runtime) 동적으로 메모리를 할당받는 공간이다.
Heap 영역을 사용하는 이유?
- 런타임에 필요한 메모리를 크기를 결정할 수 없어서
-> 컴파일 타임에는 어떤 데이터의 크기나 수명이 정해지지 않을 수 있기 때문에, Heap 필요
Heap 메모리의 특징
- 동적 할당
- Heap 메모리는 Runtime에 동적으로 할당
- 할당된 메모리는 개발자가 명시적으로 해제하지 않는 한 유지된다.
- C#의 경우, GC 덕분에 명시적으로 해제하지 않아도 관리가 가능하다.
- 할당된 메모리는 연속되지 않아도 된다
- Stack과 달리, Heap은 불연속적인 메모리 블록에 할당될 수 있다.
- Stack과 달리, Heap은 불연속적인 메모리 블록에 할당될 수 있다.
- 메모리 크기를 유연하게 조절할 수 있음
- 메모리 크기를 할당 및 재할당할 수 있다.
- 예를 들어 동적으로 배열 크기를 늘리거나, 줄이는 작업이 가능하다.
- 메모리 크기를 할당 및 재할당할 수 있다.
- 메모리 해제는 명시적으로 필요
- 개발자가 메모리를 해제하지 않으면 메모리 누수(Memory Leak)가 발생할 수 있다.
- C#, Java등에서는 Garbage Collector(GC)가 자동으로 메모리를 관리한다.
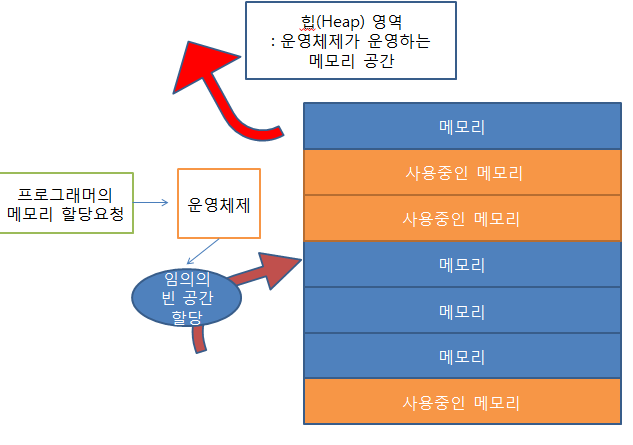
Heap이 채워지는 방식
Heap 영역은 메모리를 동적으로 할당면서 점진적으로 채워진다
Heap 할당 구조는 보통 다음과 같은 방식으로 동작한다.
1. Heap 영역의 시작 주소는 프로그램 실행과 함께 정해진다(런타임)
2. 메모리 요청이 들어오면, 운영체제는 Heap 영역에서 비어있는 메모리 블록을 찾아서 할당한다.
3. 메모리 블록은 연속적이지 않아도 되므로, 빈 공간이 있으면 나중에 메모리 요청에 재사용된다.
4. 메모리를 반환하면 해당 블록이 비어 있는 상태로 표시되며 다른 요청에서 재활용된다.
Heap Overflow, 메모리 할당 실패
Heap Overflow란?
프로그램이 할당된 Heap 영역의 메모리를 초과해서 사용할때 발생
-> 개발자가 할당된 메모리 범위를 넘어서는 데이터를 쓰거나 읽을 때 발생하는 문제
Heap Overflow는 일반적으로 Buffer Overflow의 일종이다
Heap 메모리가 부족할때(메모리 할당 실패)
Heap 메모리가 부족한 상황은 Heap Overflow와 조금 다르다
메모리 할당 실패는 Heap 영역에 사용 가능안 메모리가 없어서 새 메모리를 할당할 수 없는 경웅에 발생한다.
구분하자면 Heap Overflow는 프로그래머의 실수, 메모리 부족은 시스템 리소스 문제로 구분할 수 있다.
Stack 영역
Stack 영역은 함수의 호출과 관계되는 지역변수, 매개변수가 저장되는 영역이다.
Stack 영역의 특징
- 함수 호출시 자동으로 할당
- 함수가 호출되면, Stack 프레임이 생성되어 함수의 매개변수, 반환 주소, 지역 변수 등이 스택 영역에 저장
- 함수의 실행이 끝나면 해당 Stack 프레임이 제거
- 자동 관리
- Stack 영역은 운영체제와 컴파일러가 자동으로 관리하기 때문에, 프로그래머가 메모리를 명시적으로 할당하거나 해제할 필요가 없음.
- 지역 변수 저장
- Stack에 저장되는 변수는 지역 변수나 함수의 매개변수이다. 지역 변수는 함수가 실행되는 동안에만 유효하고, 함수가 종료되면 자동으로 사라진다.
- 빠른 접근 속도
- Stack은 메모리에서 연속된 공간에 할당되기 때문에, 접근 속도가 빠르다
- 메모리 크기 제한
- Stack 영역은 컴파일시에 크기가 정해지며, 너무 많은 데이터를 할당하면 Stack Overflow가 발생한다.
Stack 영역의 구조
Stack은 High Memory에서 Low Memory 방향으로 할당된다.
함수가 호출될 때마다 생성되는 Stack Frame의 구조는 아래와 같다
- 함수의 매개변수(High Memory)
- 함수에 전달된 인자 값이 Stack에 저장
- 함수의 반환 주소
- 함수가 종료된 후, 원래 실행되던 위치로 돌아가기 위해 반환 주소를 저장
- 저장된 레지스터 값
- 함수 실행 중 변경될 수 있는 레지스터 값을 저장. 나중에 복구를 위해 필요.
- 지역 변수(Low Memory)
- 함수 내에서 선언된 지역 변수들이 저장
매개변수가 High Memory에 할당되는 이유?
함수 호출시, 매개변수는 호출자(Caller)가 준비해서 Stack에 먼저 저장한다.
그 다음에 함수의 반환 주소와 레지스터 값이 저장된다.
이후에 함수 내에서 선언되는 지역 변수들이 가장 마지막에 할당되며 이는 Low Memory에 위치한다.
Stack Overflow
간단한 예시로 재귀 함수를 끝없이 호출하면 Stack이 꽉 차서 터져버린다.
void infiniteRecursion()
{
infiniteRecursion(); // 종료 조건이 없어서 계속 호출된다요
}
int main()
{
infiniteRecursion(); // 스택 오버플로우 발생
return 0;
}이처럼 함수가 무한히 호출되면 Stack Frame이 계속 쌓이게 되어 Stack Overflow가 발생한다.
