배경
객체지향을 공부하면서 내가 나름 느낀 가장 많이 등장했던 키워드는 변경이라고 생각한다.
객체들 사이에 서로 책임을 가지고 믿고 위임하는 것도 중요한 얘기지만, 결국 이런 의존 관계 사이에서 변경의 전파를 막는 것에 대해 얼마나 고민하느냐가 중요했던 것 같다.
변경에 유연한 코드의 중요성에 대해서 느끼고 있지만 그럼에도! 가끔은 이정도까지 해야하나? 싶은 순간들이 있었던 것 같다. 이 객체는 변경될 여지가 없는 것 같은데 굳이 interface를 두어야 하나? 혹은 Client 객체가 이정도는 알아도 되지 않을까? 하는 고민이 있었다. 그 고민의 이유는 바로 유지보수가 쉬운 코드와 현재 코드를 작성하는 작업량에 대한 trade-off 때문인 것 같다.
그런 측면에서 오늘 clean architecture에 대한 강의를 듣고 정리하는 시간은 꽤 의미 있을 것 같다. 조금은 납득가지 않았던 부분과, 나도 모르게 DIP를 깨고 있었던 개념들이 무엇이 있었는지 느낄 수 있었다. 강의 내용을 토대로 클린 아키텍쳐의 필요성을 느껴보는 식으로 글을 작성하고자 한다.
Architecture의 중요성
이전까지는 코드는 사실 원하는 결과를 잘 내기만 하면 된다고 생각했다. 결과를 내는데 시간이 많이 걸린다면 알고리즘을 개선하면 된다고 생각했고, 객체지향적인 부분이나 아키텍쳐에 대한 고민은 사실 많이 하지 않았다.
하지만, 우리가 만드는 프로그램은 결국 특정 서비스를 만들기 위함이다. 그 서비스는 결국 사용자의 요구사항, 회사의 기획에 따라 꾸준히 바뀌며 새로운 내용이 추가될 것이다. 그런 상황에서 단순히 돌아가게만 만드는 코드는 나중에 큰 후회를 불러올 수도 있다.
그래서 나 나름대로는 객체지향의 원칙, 클린 아키텍쳐의 개념이 자꾸 등장하는 것은 결국 투자의 개념으로 이해하려고 한다.
현재 작업량을 조금 더 늘리더라도 미래에 일어날 확률이 큰 변경에 대비하는 것, 유지 보수에 들어갈 수 많은 시간과 비용을 지금 현재의 작업으로 최소화 하겠다는 것. 이것이 단순히 프로그램의 동작 여부를 떠나서 우리가 항상 해야할 고민이 되지 않을까 하는 생각이 든다.
모든 소프트웨어는 변경이 일어난다.
커머스 앱의 예시를 들어 단순히 할인률 숫자가 변경되는 작은 변경부터, 할인 정책 자체가 변경되는 큰 변화들이 코드에서는 변경을 만들어낸다. 이러한 변경이 생겼을 때 돌아가게만 만든 코드는 새로운 변화를 따르는 또 다른 '돌아가는 코드'를 만들어내야 한다. 극단적으로 기존의 코드를 전혀 활용하지 못할 수도 있다는 것이다. 이런 필요성을 수 년간 느꼈기 때문에 지금에서 많은 사람이 지키려고 노력하는 객체지향의 원칙, 클린 아키텍쳐라는 스테디 셀러가 등장한 것이라고 생각한다.
물론 지금 당장 내가 하려고 하는 프로젝트에는 조금 과분하다고 느껴지는 내용도 많고, 당장에 적용할 이유를 찾지 못하는 경우도 많다. 아직까지 하고 있는 프로젝트는 실제 서비스도 아니고, 지속성에 대한 논의도 하지 않은 상태이기 때문이다.
그렇지만, 실제 내가 한 서비스를 담당하는 개발자라고 생각하며 매순간 코드의 부분마다 의심하고 고민해보자.
프랑스 철학자 데카르트는 방법서설에서 두 가지 중요한 개념을 반복하는데, 그 중 하나가 '무엇이든지 의심하라!'이다. 내가 습관적으로 하고 있었던, 혹은 강의에서 배웠기 때문에 반복해왔던 코드들에 대해서 의심해보자. 의심해야 고민할 수 있고, 그 고민 속에서 나름의 이유를 찾아야지만 의미가 있다. 뛰어난 개발자들이 작성하는 코드가 멋있고 깔끔해보이는 이유는, 우리가 겪지 않은 수많은 시간 속에서 그들이 그만큼 의심하고 고민했기 때문일 것이다.
의존성 규칙
지금까지 의존성에 대해 많은 얘기를 했지만, 의존성이 결국 중요한 키워드가 되는 이유는 변경의 전파를 만들어내기 때문이다. 이는 객체 사이의 의존성에 대해서도 성립하는 얘기지만, 조금 더 넓은 범위에서 모듈간의 관계에 대해서도 동일하게 작용한다.
변경의 전파를 최소화하기 위해서 항상 저수준의 모듈이 고수준의 모듈을 의존하도록 해야한다. 여기서 고수준 모듈이란 변경될 가능성이 낮은 모듈을 의미하고, 저수준 모듈은 변경될 가능성이 높은 모듈을 의미한다!
예를 들어, 우리가 자주 사용하는 String 클래스의 경우 굉장히 고수준의 모듈이다. 만약 String 클래스의 변경이 자주 일어난다면, 우리는 매번 String을 사용했던 코드의 부분을 수정해야 할 것이다.
정리하자면 우리는 코드를 작성할 때 항상 의존성 규칙을 지키면서 작성해야 한다!
의존성 규칙
저수준의 모듈이 고수준의 모듈을 의존하도록 해야한다.
Spring을 접하게 되면서 흔히 사용하는 3가지 layer 구조가 있었다. 반 기계적으로 이렇게 layer를 분리하고 의존성을 주입했지만 이제 그 이유를 한 번 살펴보자.
Controller -> Service -> Repository(interface) <- RepositoryImpl
첫 번째 화살표의 경우Controller 보다는 Service가 변경의 가능성이 더 낮기 때문에 이런식으로 의존성을 설정하는 것이다.
Q. 그렇다면 왜 바로
Repository를 의존하지 않고 interface를 두어서 의존하도록 했을까?
코드를 작성하다보면 때에 따라 고수준 모듈이 저수준 모듈을 의존해야 하는 상황이 발생한다. 이는 단지 모듈 간의 협력 과정에서 고수준의 모듈이 저수준 모듈을 필요로 할 때 자연스럽게 생긴다.
그러나 이렇게 계속 두게 되면 우리는 의존성이 만들어내는 변경의 전파에서 빠져나올 수 없다.
이런 상황에서도 의존성 규칙을 지킬 수 있게 해주는 것이 DIP이다.
의존성 역전의 원칙(DIP)
객체지향의 SOLID 원칙을 설명할 때 DIP를 이렇게 얘기했었던 것 같다.
구현체에 의존하지 말고 interface에 의존하라!
근데 사실 모든 의존성에서 DIP를 적용해서 interface를 만들게 되면, 코드의 유지보수도 힘들어질 뿐더러 의존성 규칙을 잘 적용하고 있는 부분에서는 더 큰 비용이 발생한다고 생각한다.
다시 얘기하면, 의존성 규칙을 위배하는 관계에서 우리는 DIP를 적절히 활용해 의존성 규칙을 반드시 지키도록 할 수 있다.
아래 구조를 다시 한 번 살펴보자.
Controller -> Service -> RepositoryImpl
지금 같은 상황에서 사실 RepositoryImpl 부분은 어떤 DB를 설정할지에 따라서, 어떤 ORM을 사용할 지에 따라서 변경 가능성이 상대적으로 많은 저수준의 모듈(Service에 비해서!)이다.
비즈니스 로직이 제대로 설정이 된 상태에서 어떤 문제로 DB를 변경해야 하는 순간 우리는 Service layer의 코드를 모두 손봐야 하는 상황이 생길 수 있다는 것이다.
즉, 상대적으로 고수준인 Service가 저수준인 RepositoryImpl을 의존하면서 의존성 규칙이 깨졌고, 우리는 그 대가로 변경의 전파를 피할 수 없게 된 것이다.
그렇다고 해서 Service가 RepositoryImpl의 내용에 의존하지 말아야 할까? 그건 아닐 것이다. 비즈니스 로직을 이용하기 위해서는 DB와의 상호작용이 반드시 필요하고, 그 역할에 책임을 갖는 Repository layer의 힘을 빌려야 한다.
이럴 때 DIP를 통해 의존성 규칙을 지키면서 원하는 결과를 이룰 수 있다.
Controller -> Service -> Repository(interface) <- RepositoryImpl
이런 구조가 완성이 되면 이제 Service는 저수준인 interface에 의존하게 된다. Service입장에서는 어떤 DB를 쓰던, 어떤 ORM을 쓰던 상관없이 필요한 역할의 존재에 대해서만 알고 있기 때문에 이제는 Repository layer에 변경이 일어나도 Service에 변경이 전파되지 않는다.
만약 DB가 변경된다면 새로운 RepositoryImpl 구현체를 설정하면 되고, 의존성 주입을 통해서 런타임 시점에 해당 객체를 주입받으면 된다!
뭔가 많은 변화가 일어난 것 같지만 실제 우리가 중요하게 기억해야 할 부분은 아래 내용이다!
DIP로 역전된 의존성은 소스코드(컴파일)의 의존성만 변경되었고, 실제 어플리케이션의 동작 흐름은 그대로이다!
결국 원하는 것을 그대로 이루면서 의존성 규칙을 통해 변경의 전파도 막을 수 있다는 뜻이다!
Clean Architecture
개발자들에게 정말 유명한 책 중 하나인 클린 아키텍쳐의 저자 로버트 C. 마틴의 블로그를 살펴보자
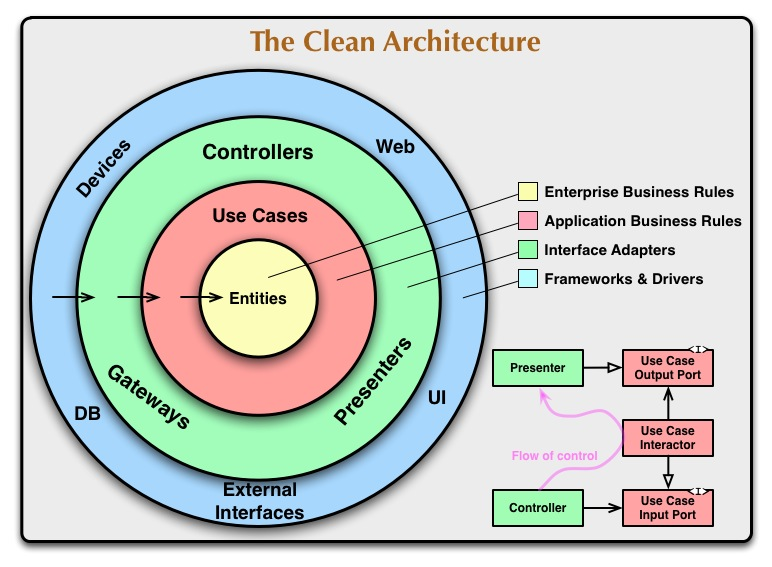
왼쪽의 원형 다이어 그램을 보면 원 내부로 들어갈 수록 고수준의 모듈임을 의미한다. 화살표의 방향은 서로의 의존성을 보여주고 있고, 바깥쪽(저수준)에서부터 안쪽(고수준)으로 의존성 방향이 놓여져 있음을 알 수 있다.
블로그 내용을 통해서 내부에 존재하는 Entitiy와 Use Case에 대해서 알아보자.
Entity
여기서 말하는 Entity는 회사 차원의 비즈니스 규칙을 정의해 둔 것이고, 함수, 메소드를 포함한 객체, 혹은 여러 자료구조들이 포함된 형태로 주어진다.
여기서 중요하게 보아야 할 부분은 Enterprise wide business rules 라고 하는 부분이다 (직역하면 의미가 변질될 것 같아 그대로 가져왔다). 결국 개발적인 부분을 완전히 배제하고 보더라도 정해져 있어야 하는 회사 차원의 규칙을 모듈로 만들어 둔 것이다!
그러니 회사 내부 다른 수많은 어플리케이션에서 이를 사용할 수 있어야 하고, 사용해도 아무런 문제가 없어야 한다.
위의 설명만 보더라도 당연히 굉장히 고수준의 모듈임을 알 수 있다.
회사가 아니라 개인의 프로젝트라 하더라도 Entity는 굉장히 high-level의 rule을 담는 모듈이 될 것이다. 그리고 이러한 모듈은 변경의 전파에 대해 최대한 안전한 상태로 존재해야 한다!
Use Cases
하지만 business rule은 한 두가지가 아닐 것이고 특정 rule은 특정 어플리케이션에 특화된 규칙일 수도 있을 것이다. 이러한 규칙을 Use Case라고 한다.
Use Case는 어플리케이션에 특화된 규칙을 지키기 위해 Entity를 통해 enterprise wide한 business rule을 적절히 사용할 수 있을 것이다.
필요한 목적을 달성하기 위해 각자의 규칙이나 절차를 실행하지만, 그 사이에서
Entity를 호출해 일부 동작을 위임할 수 있다.
하지만, 그렇다고 해서 Use Case의 변경이 Entity에 영향을 주는 것은 원하지 않는다. 반복해서 얘기하지만, Entity는 코드적인 부분을 배제하고 보더라도 변경이 되지 않아야 하는 것들이 집합되어 있는 공간이다.
정리
Clean Architecture라는 부분에 대해서 아직 많이 부족하긴 하지만, 객체지향을 이해하고 그 연장선의 관점에서 보았을 때 핵심은 변하지 않았다.
변경의 전파를 최소화 할 수 있도록 노력해야한다!
그림의 아주 일부분에 해당하는 부분만 얘기했지만 충분히 모듈간의 수준, 의존성 규칙에 대한 필요성을 느낄 수 있었던 것 같다.
시간이 된다면 여러 아키텍쳐들이 각각 어떻게 의존성 규칙을 지키려고 노력하는지, 이런 구조들이 가져오는 trade-off는 무엇이 있는지 공부해보고 필요성을 또 한 번 느껴볼 수 있는 글을 작성해보고 싶다.
