배경
최근 프로젝트 진행 중 동시성 제어 이슈를 경험하게 되었다. 문제를 해결하기 위해 테스트 코드를 작성하는 상황에서 @Transactional 의 내부 동작을 제대로 알지 못해 어려움을 겪었다.
Spring에서 @Transactional을 사용해 비즈니스 로직을 처리했던 과정이 실제 DB Transaction 처리 로직에 어떻게 적용되는지 이해하기 위해 데이터베이스의 Transaction에 대해서 알아보자.
이번 포스팅은 Database System Concepts라는 책의 원서 내용을 바탕으로 작성되었고, 첨부된 사진 자료 모두 해당 교재에서 가져왔다. (의미 훼손을 줄이기 위해 영어가 많이 포함되어 있다)
출처: Database System Concepts 6th edition: Silberschatz, Korth and Sudarshan
Transactions
Transaction은 일반 사용자 관점, 그리고 시스템 관점에서 두 개의 정의로 나눌 수 있다.
- User view: Logical unit of work
- System view: A program unit that accesses and possibly updates various data items.
간단히 생각하면 사용자 관점에서는 흔히 행해지는 일의 단위라고 보면 된다.
아래와 같은 예시를 보면 조금 편하게 이해할 수 있을 것이다.
- A계좌에서 B계좌로 50만원 송금하기.
- 모든 직원의 월급을 5% 올리기.
- 비행기 좌석이 남아있는지 확인하고 예약하기
위의 모든 예시들은 사용자 관점에서는 단지 흔한 일이고, 시스템 관점에서는 필요한 데이터에 접근하고, 값을 수정하는 일이 행해지는 단위라고 보면 된다.
우리같은 사람은 위의 행위들이 문제없이 일어나기를 기대하고 있다.
따라서 DBMS는 반드시 transaction으로 정의된 일련의 과정들이 제대로 동작하도록 보장해야 한다!
DBMS는 ACID properties라고 부르는 4가지 특징을 지키면서 transaction이 제대로 동작하도록 한다.
ACID
Transaction을 처리하는 과정에는 꽤나 많은 걸림돌이 존재한다.
만약 system에 충돌이 발생해 꺼지거나, disk에 문제가 생기는 경우, 혹은 system에 error가 발생하는 경우 모든 컴퓨터가 그렇듯 원하는 결과를 기대할 수 없다.
또한, DB는 일반적으로 성능을 위해 buffer를 두고 buffer에 어느정도 데이터가 쌓인 경우 실제 disk에 값을 저장하게 되는데, 이 또한 transaction을 제대로 수행하기 위해 고려해야 할 사항이다.
만약 여러 요청이 동시다발적으로 들어오는 경우(concurrent execution) 여러 transaction이 동시에 동작해야하는데 이 사이에서도 제대로 동작함을 보장해야 한다.
위와 같은 상황에서 DBMS는 사용자가 기대하는 transaction을 수행하기 위해 4가지 중요한 속성을 정의하고 이를 지키도록 한다.
Atomicity
가장 많이 들어 보았을 내용으로 직역하면 원자성이다. (여담이지만, 실제 원자를 뜻하는 atom의 어원이 "더 이상 쪼개질 수 없다"는 뜻의 고대 그리스어인 a-tomos에서 왔다)
여기서 가장 중요한 키워드는 "All or nothing" 이다. 즉, transaction이 수행된다면, 내부 동작이 전부 수행되거나, 하나도 수행되지 않거나 둘 중 하나만 하도록 보장한다는 것이다.
아래 transcation 예시를 보자.
Begin transaction
read(A,a)
a = a-50
write(A,a)
// Crash!!!!
read(B,b)
b = b+50
write(B,b)
End transaction위에서 언급했던 A의 계좌에서 B의 계좌로 50만원을 송금하는 상황이다.
만약 A 계좌에서 50만원을 차감한 상황에서 B의 계좌에 옮기기 전에 system의 오류로 충돌이 나면 어떻게 될까
B는 돈을 받지 못한 상황에서 A만 50만원을 잃어버린 것이다.
Atomicity를 보장하기 위해서 DBMS가 할 수 있는 일은 두 가지이다.
- A의 계좌에서 뺀 50만원을 다시 복구한다. (Roll back)
- 시스템이 복구되면 crash 지점 이후의 동작을 계속 수행하여 b 계좌에 50만원을 추가한다. (Roll forward)
위의 두 가지 수행을 통해 DBMS는 첫 번째 ACID 속성인 Atomicity을 보장한다.
Consistency(Correctness)
두 번째는 정합성이라고 불리는 부분으로 데이터에 모순이 없는 상태를 보장하는 속성이다.
비슷하게 transcation 예시를 통해 살펴보자.
Begin transaction
read(A,a)
a = a-100
write(A,a)
End transactionA의 계좌의 잔액을 가져와서 100만원을 출금하는 상태이다.
별 문제가 없어 보이지만, 만약 A의 잔액이 20만원 뿐이라면 어떻게 될까?
계좌 잔액이 0원 이상이어야 된다는 무언의 규칙이 깨진 것이다!(마이너스 통장같은 생각은 하지말자...)
즉 Consistency는 transcation 전에 유지되던 consistent state가 transcation 수행 후에도 유지되도록 보장하는 속성이다.
사실 해당 부분은 DBMS보다는 프로그래머에게 책임이 존재한다.
DBMS 입장에서는 A의 데이터가 계좌 잔액인지, 날씨인지, 반 학생 수인지 알 필요도 없고, 안다고 해서 각각이 지켜야 할 규칙이 무엇인지도 모르기 때문이다.
Isolation
세번째 속성인 고립성은 하나의 transaction이 다른 transaction에 의해 방해받지 않음을 보장하는 속성이다.
DBMS가 처리해야할 transaction의 종류는 생각보다 많을 수 있다. 서로 다른 transcation은 때로는 동일한 데이터 자원에 접근할 수도 있고, 수정할 수도 있다.
이런 상황에서 각각의 transaction이 제대로 동작하게 하는 방식 중 가장 쉬운 방법은 들어온 순서대로 순차적으로(serial) 처리하는 것이다.
꽤 괜찮은 해결책인 것 같지만 모든 transaction을 순차적으로 처리하게 되면 속도가 느려질 수 밖에 없다.
그렇다고 해서 특정 transaction을 수행하면서 동시에 다른 transaction을 수행하면 공유 자원에 대해 동시에 접근이 일어나므로 문제 상황이 발생할 수 있다.
아래와 같은 상황을 보자. (동일한 행은 같은 시간대를 의미한다)
//Transaction T1// //Transaction T2//
Begin transaction
read(A,a1) Begin transaction
a1 = a1-50 read(A,a2)
write(A,a1) a2 = a2-100
read(B,b1) write(A, a2)
b1 = b1+50 End transcation
write(B,b1)
End transactionT1의 경우 A의 계좌에서 B의 계좌로 50만원을 옮기는 상황, T2의 경우 A의 계좌에서 100만원을 출금하는 상황이다.
T1과 T2에 대한 요청을 순차적으로 진행했을 때 기대하는 A의 계좌 잔액은 150만원이 차감된 상태일 것이다.
하지만 실제 T2가 A의 값을 읽은 시점이 T1에 의해 50만원이 차감되기 이전이고, A는 T2에 의해 마지막으로 100만원이 차감된 상태가 저장된다.
따라서 해당 위의 일정대로 진행된 두 transaction의 결과로 A는 단지 100만원만 차감된다.
어? 그러면 무조건 transaction은 serial하게 진행되야 하는 것 아냐? 라고 생각할 수 있지만, 동시에 실행하더라도 문제 상황이 발생하지 않을 수 있다!
//Transaction T1// //Transaction T2//
Begin transaction
read(A,a1)
a1 = a1-50
write(A,a1) Begin transaction
read(B,b1) read(A,a2)
b1 = b1+50 a2 = a2-100
write(B,b1) write(A,a2)
End transaction End transcation이렇게 조절하게 되면 동시에 실행되었지만 T2가 A의 값을 읽는 시점에 T1이 A를 수정한 시점이 되기 때문에 위에서 발생한 문제를 해결할 수 있다.
이렇듯 DBMS는 여러 transaction 들을 concurrent하게 실행하면서도 다른 transaction을 방해하지 않도록 잘 조절하여 serial execution보다 성능을 개선한다!
해당 부분에 대해서는 아래 Schedule에서 더 다룰 예정이다.
Durability
마지막 속성은 지속성으로 완료된 transcation에 의한 결과는 지속적으로 반영되어야 함을 뜻한다.
Transaction이 완료된 이후에는 crash, system error 등의 상황이 닥쳐도 결과를 제대로 유지할 수 있어야 한다.
그렇기 위해서 DBMS는 여러 recovery 기술을 적용하고 있다.
로그를 통해 복구하는 기술의 기반인 대표적인 규칙 WAL(Write Ahead Logging) 에 대해서만 간단하게 살펴보자.
DBMS의 작업 중 Transcation 내부 read, write가 실행되더라도 실제 Disk를 통해 수행되지는 않는다.
Read를 통해 데이터를 가져오는 경우 main memory 영역에 있는 buffer에 먼저 저장하고, buffer에서 작업을 진행한다.
그리고 transction 등이 종료되었을 때 output 명령어를 통해 buffer에 저장된 값을 disk에 반영하게 된다.
WAL은 buffer에 저장된 데이터의 변경이 disk로 옮겨가기 이전에, transaction의 행위에 대한 log가 반드시 먼저 stable storage에 저장되도록 하는 규칙이다.
WAL은 아래와 같은 세 가지 규칙을 준수한다.
- Log record는 생성된 순서대로 stable storage에 저장된다.
- Transaction T는 반드시 "T commit" 이라는 log record가 stable storage에 저장되었을 때 commit state로 변경된다.
- Main memory buffer에 존재하는 데이터가 disk로 output되기 이전에 모든 record가 반드시 stable storage로 output 되어야 한다.
DBMS의 log record는 아래처럼 기록되며, 해당 내용을 바탕으로 DB의 값이 손실되더라도 recovery 로직을 통해 복구가 가능하다. (데이터 보다 log가 먼저 저장되도록 보장함으로서 recovery가 가능한 구조를 만들어낸다)
log record
<T0 start>
<T0, A, 0, 10>
<T0 commit>
<T1 start>
<T1, B, 0, 10>
<T2 start>
<T2, C, 0, 10>
<T2, C, 10, 20>
<checkpoint {T1, T2}>
<T3 start>
<T3, A, 10, 20>
<T4 start>
<T4, D, 0, 10>
<T3 commit>Transaction state
DBMS는 각 transaction의 올바른 수행과 ACID 보장을 위해 transcation에 5가지 state를 부여한다.
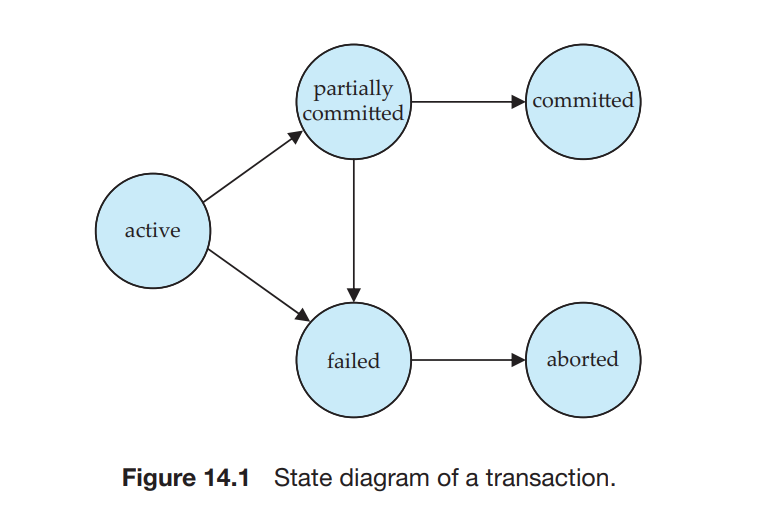
각 상태에 대해서 살펴보자.
- Active: 가장 초기 상태로, transaction이 수행되는 동안 해당 상태를 유지한다.
- Partially committed: transaction의 마지막 행위가 수행된 상태이다.
- Failed: 여러 상황에 따라 transaction이 더이상 수행될 수 없는 상태이다.
- Aborted: transaction이 roll back 된 후 DB가 transaction 시작 시점으로 복원된 상태이다.
- Aborted 상태에서 가능한 옵션은 두 가지이다.
1. Transaction 다시 시작하기
2. transaction kill
- Aborted 상태에서 가능한 옵션은 두 가지이다.
- Commited: transaction이 성공적으로 완료된 상태이다.
Concurrent Executions
DBMS는 trasaction의 처리속도를 높이기 위해 여러 transaction이 동시에 수행될 수 있도록 지원한다.
하지만 위에서 얘기했듯이 concurrent execution은 반드시 고립성을 지키면서 발생해야 한다.
이에 DBMS는 DB의 consistency를 해치지 않으면서 동시에 여러 transaction을 수행할 수 있는 매커니즘을 활용한다.
Schedules
이해를 위해 transcation에 속해있는 operation은 read와 write밖에 없다고 가정하자.
그리고 각각의 read, write는 메모리에 있는 buffer의 데이터를 통해서 이루어지고, 후에 disk에 반영된다.
Schedule은 간단하게 동시에 실행되는 transaction의 명령어들을 나열한 것이다. 위에서 Isolation을 설명할 때 보여준 두 개의 transaction이 하나의 schedule로 구성되어 있던 것이다!
Serial Schedule
Schedule의 가장 간단한 버전은 바로 Serial Schedule이다. 고립성을 완벽하게 지킬 수 있으면서, 직관적이다.
하나의 transaction을 완전히 수행하고, 다른 transaction을 수행하는 schedule로 아래와 같이 나타낼 수 있다.
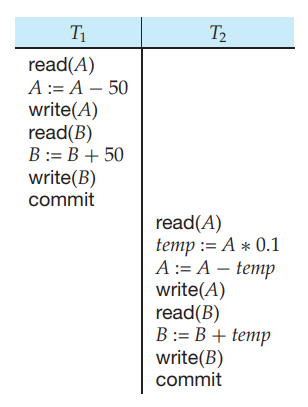 | 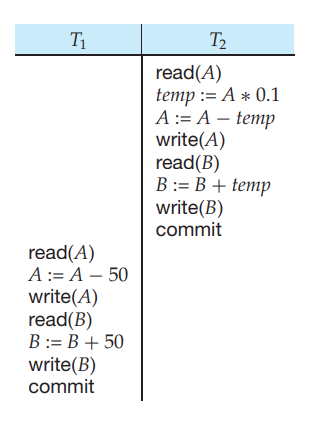 |
|---|
과연 첫 번째 schedule이 반드시 이렇게 순차적으로 진행되어야만 할까?
Serializable Schedule
아래 세 번째 schedule을 보자.
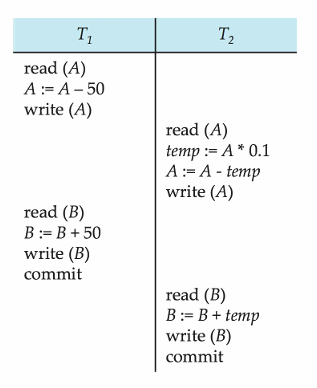
Concurrent 하게 진행되었지만 실제 결과는 첫 번째 schedule과 동일하다!
이렇게 Concurrent 한 schedule이라도 Serial Schedule과 동일한 결과를 나타내면 이를 Serializable Schedule이라고 한다.
Conflict Serializability
사실 read만 존재하는 transaction이라면 그 어떤 transaction이 와도 concurrent하게 처리할 수 있다.
우리가 concurrency를 고민하는 이유는 바로 write 때문이라고 할 수 있다. 특정 transaction이 write를 수행하게 되면 다른 transaction은 이를 읽는 시점에 따라 값이 달라질 수 있기 때문이다.
서로 다른 transaction(T1, T2)의 instruction(I1,I2)이 아래와 같은 상황 하에 있다면 conflict라고 얘기한다.
- 두 instruction 모두 동일한 자원 Q에 접근할 때.
- 둘 중 하나가 write(Q) instruction인 경우
즉 두 instruction 모두가 read인 경우를 제외하고는 conflict인 것이다.
두 instruction 사이에 conflict가 존재한다는 것은 곧 두 instruction 사이에 시간적인 순서가 강제된다는 뜻이다!
다른 말로는 non-conflict인 instruction 들은 하나의 schedule 내에서 마음대로 순서를 바꿔도 된다는 것이다!
따라서 우리는 Serial Schedule에서 non-conflict인 instruction의 순서를 바꾸어서 concurrent하게 진행할 수 있다. (Conflict Serializability)
Transaction 격리 수준
위의 Schedule을 통해서 우리는 각 transaction이 동시에 수행될 수 있음을 알게 되었다.
각각의 개별 Transaction이 혼자 수행되었을 때 data consistency를 해치지 않는다면, DBMS는 serial schedule과 논리적으로 동등한 schedule을 만들어서 concurrent하게 진행하면서도 data consistency를 유지할 수 있다.
하지만, Serial Schedule과 논리적으로 완벽히 동등한 schedule의 경우 때때로 너무 적은 concurrency를 만들어낸다.
이에 consistency 수준을 낮추고 non-serializable schedule을 만들어내더라도 concurrency를 높일 수 있는 설정을 제공한다. 다만, 실제 DBMS가 보장하는 ACID중 C,I가 깨질 수 있으므로 프로그래머가 data의 정합성을 지키기 위해 더 노력해야 한다.
SQL Standard는 transaction의 4가지 격리 수준을 제공함으로써 상황에 맞게 격리 수준을 조절하도록 허용한다.
1. Serializable
해당 수준은 모든 Schedule이 serializable하게 진행되도록 보장하는 것이다. 당연히 가장 높은 격리 수준을 가지게 되지만 concurrency가 떨어진다.
즉, 다른 transaction이 conflict에 의해 설정된 시간 순서에 따라 또 다른 transaction의 특정 instruction이 수행되기를 기다리고 있다는 뜻이다.
따라서 수행 시간 측면에서 가장 느리지만, 데이터 정합성과 고립성에서 가장 높은 수준을 보여준다.
2. Repeatable read
해당 수준은 transaction이 시작되기 이전에 commit된 내용만 읽도록 보장하는 수준이다.
Transaction이 시작되면 해당 시점의 database 스냅샷을 만들어두고, 이를 통해 commit된 데이터만 읽도록 보장할 수 있다.
MySQL InnoDB는 해당 격리 수준을 채택해서 사용하고 있다.
3. Read committed
이는 시점에 상관없이 commit 된 데이터만 읽어오도록 보장하는 수준이다. 위의 Repeatable Read와 다른 점이 있다면, 한 transaction 내에서 동일한 데이터에 대해 read 진행 시 값이 달라질 수 있다는 것이다.
Concurrent 하게 일어나는 두 개의 transaction T1, T2에서 T1이 A에 대한 값을 read하고,
T2가 A의 값을 변경하고 나서 다시 T1이 A를 read하면 값이 바뀔 수 있다는 뜻이다!
4. Read uncomitted
해당 수준은 commit되기 전이라도 schedule 상에서 write가 된 값은 읽어올 수 있게하는 수준이다.
이는 특정 transaction이 roll-back 된다고 해도 다른 transactiond이 roll-back이전의 값을 읽은 채로 로직을 수행할 수 있기 때문에 위험한 상황을 일으킬 수 있다.
위의 네 가지 격리 수준 모두 Read와 관련이 되어있다. 그 이유는 그 어떤 격리 수준도 dirty writes는 허용하지 않기 때문이다.
즉, commit이나 abort되지 않은 transaction의 write 내용이 존재하는 상태에서 다른 transaction이 write하는 상황을 허용하지 않고 있다!
정리
DB transaction에서 중요하게 다루어지는 키워드에 대해서 공부를 진행해 보았다.
수 많은 transaction을 동시에 처리하기 위해 고민해야할 부분과 이에 따른 trade-off를 이해하고 동시성 이슈같은 상황이 왜 발생하는 지 이해할 수 있었다.
다음에는 격리 수준을 구현하는 방법 중 하나인 Lock에 대해서 공부하고자 한다.
