문제 1. 다음에서 설명하는 것은 ER모델 중 어떤 항목에 대한 설명인가?
1) 모든 릴레이션(Relation)은 원자값(Atomic)을 가져야 한다.
2) 어떤 릴레이션(Relation)에서 속성 값이 가질수 있는 값의 범위를 의미한다.
3) 실제 속성값이 올바르게 되었는지 확인한다.
4) 속성명과 반드시 동일할 필요는 없다.1) 카디날리티(Cardinality)
2) 도메인(Domain)
3) 인스턴스(Instance)
4) 차수(Degree)
문제 1 해설
문제에서 설명하는 것은 "도메인(Domain)"에 대한 설명입니다. 따라서 정답은 2) 도메인(Domain)입니다.
설명해 드리자면,
1) 모든 릴레이션(Relation)은 원자값(Atomic)을 가져야 한다. - 이 설명은 데이터베이스의 제1정규형(1NF)에 대한 설명입니다.
2) 어떤 릴레이션(Relation)에서 속성 값이 가질 수 있는 값의 범위를 의미한다. - 이것은 도메인(Domain)에 대한 설명입니다. 도메인은 속성이 가질 수 있는 값의 집합을 의미합니다.
3) 실제 속성값이 올바르게 되었는지 확인한다. - 이것은 데이터의 유효성 검사나 인스턴스(Instance)의 상태를 확인하는 것과 관련이 있을 수 있습니다.
4) 속성명과 반드시 동일할 필요는 없다. - 이것은 보통 속성명이나 차수(Degree)와 관련된 일반적인 설명일 수 있으나, 문제의 맥락과 직접적으로 연결되는 것은 아닙니다.
따라서, 문제에서 주어진 설명은 속성 값이 가질 수 있는 값의 범위를 의미하는 도메인(Domain)에 가장 잘 맞습니다.
문제 2. 다음 중에서 도메인(Domain) 에대한 특징으로 옳지 않은 것은?
1) 릴레이션의 속성에 대한 데이터 타입과 크기이다.
2) 속성에 대하여 NOT NULL 제약사항을 설정하여 NULL 값을 허용하지 않는다.
3) 속성에 값을 입력 할 때 CHECK 기능을 사용해서 입력 값을 검사한다.
4) 하나의 릴레이션과 관계된 다른 릴레이션의 FK(Foreign key) 제약조건이다.
문제 2. 해설
도메인(Domain)에 대한 특징으로 옳지 않은 것은 4) 하나의 릴레이션과 관계된 다른 릴레이션의 FK(Foreign Key) 제약조건입니다.
도메인은 릴레이션의 속성이 가질 수 있는 값의 범위, 즉 데이터 타입과 크기, 그리고 해당 속성에 적용할 수 있는 제약 조건(예: NULL 허용 여부, 값의 범위 등)을 정의합니다. 따라서,
1) 릴레이션의 속성에 대한 데이터 타입과 크기이다. - 이는 도메인의 정의에 부합합니다.
2) 속성에 대하여 NOT NULL 제약사항을 설정하여 NULL 값을 허용하지 않는다. - 이 역시 도메인이 정의할 수 있는 제약사항의 예입니다.
3) 속성에 값을 입력할 때 CHECK 기능을 사용해서 입력 값을 검사한다. - 도메인은 속성 값의 유효성을 검사하는 데 사용될 수 있는 규칙을 정의할 수 있으므로, 이 역시 도메인의 특징입니다.
하지만,
4) 하나의 릴레이션과 관계된 다른 릴레이션의 FK(Foreign Key) 제약조건이다. - 이는 도메인의 특징이 아닙니다. 외래키(Foreign Key) 제약조건은 특정 릴레이션의 속성이 다른 릴레이션의 기본키(Primary Key)와 연관되어 있음을 나타내며, 두 릴레이션 간의 관계를 정의하는 것과 관련이 있습니다. 도메인과는 직접적인 관련이 없습니다.
문제 3. 다음 보기 중 슈퍼/서브타입 데이터 모델의 변환타입에 대한 설명으로 옳은 것은?
1) One To One이란 개별로 발생되는 트랜잭션에 대해서는 개별 테이블로 구성하고 테이블의 수가 많아진다.
2) Plus Type은 하나의 테이블을 생성하는 것으로 조인(Join)이 발생하지 않는다.
3) Plus Type은 슈퍼+서브타입 형식으로 데이터를 처리하는 경우로 조인성능이 우수하여 Super Type과 Sub Type변환 시에 항상 사용된다.
4) One To One type은 조인성능이 우수하기 때문에 관리가 편리하다.
문제 3. 해설
- 정답 : 1
One To One Type
- 슈퍼타입과 서브타입을 개별 테이블로 도출한다.
- 테이블의 수가 많아서 조인이 많이 발생하고 관리가 어렵다.
Plus Type
- 슈퍼타입과 서브타입 테이블로 도출한다.
- 조인이 발생하고 관리가 어렵다.
Single Type
- 슈퍼타입과 서브타입을 하나의 테이블로 도출하는 것이다.
- 조인성능이 좋고 관리가 편리하지만, IO 성능이 나쁘다.
문제 4. 다음 보기 중에서 데이터베이스 모델링에 대한 특징으로 옳지 않은 것은?
1) 내부화
2) 추상화
3) 단순화
4) 명확화
문제 4 해설
데이터베이스 모델링 특징
: 추상화, 단순화, 명확성
- 단추, 명확하게 차자
문제6. 속성
- 기본 속성: 데이터베이스 그냥 속성
- 설계 속성: 기본키가 되는 속성(ex: 아이디)
- 파생 속성: 평균값이나 사람이 더 편리하게 보게하기 위한 속성
문제 9. 다음은 데이터베이스 모델링 시에 성능을 고려한 모델링 활동이다. 성능을 고려한 데이터베이스 모델링 단계에서 가장 처음으로 수행해야 할 것과 가장 마지막으로 수행해야 할 것은?
가. 데이터베이스 모델링 시에 정규화를 수행한다.
나. 테이블에서 보관하는 데이터 용량과 트랜잭션의 유형에 따라서 반정규화를 한다.
다. 트랜잭션의 유형을 분석한다.
라. 데이터베이스 전체 용량을 산정해야 한다.
마. 성능관점에서 데이터 모델을 검증하고 확인한다.
바. 기본키와 외래키를 조정하거나, 수퍼타입과 서브타입을 조정한다.1) 가, 나
2) 다, 마
3) 다, 라
4) 가, 마
문제 9 해설. 성능을 고려한 데이터모델링 순서
- 데이터 모델링을 할 때 정규화를 정확하게 수행
- 데이터베이스 용량산정 수행
- 데이터베이스에 발생되는 트랜잭션 유형 파악
- 용량과 트랜잭션의 유형에 따라 반정규화 수행
- 이력모델의 조정, PK/FK 조정, 슈퍼타입/서브타입 조정 수행
- 성능관점에서 데이터 모델 검증
문제 11. 문제 11. 다음 보기 중 해시조인(Hash Join)에 대한 설명으로 옳지 않은 것은?
1) 해시조인은 두 개의 테이블 간에 조인을 할 때 범위검색이 아닌 동등조인(EQUI-Join)에 적합한 방식이다.
2) 작은 테이블(Build Input)을 먼저 읽어서 Hash Area에 해시 테이블을 생성하는 방법으로 큰 테이블로 Hash Area를 생성하면 과다한Sort가 유발 되어 성능이 저하될 수 있다.
3) 온라인 트랜잭션 처리(OLTP)에 유용하다.
4) 해시조인은 수행 빈도가 낮고 수행시간이 오래 걸리는 대용량 테이블에 대한 조인을 할 때 유용하다.
문제 11 해설
해시조인(Hash Join)에 대한 설명으로 옳지 않은 것은 3) 온라인 트랜잭션 처리(OLTP)에 유용하다입니다.
해시조인은 두 테이블을 조인할 때 사용되는 효율적인 방법 중 하나로, 주로 대용량 데이터 처리에 적합한 방식입니다. 해시조인은 먼저 작은 테이블을 스캔하여 해시 테이블을 메모리에 생성하고, 그 다음 큰 테이블을 스캔하면서 메모리에 있는 해시 테이블과 매칭하여 조인을 수행합니다. 이 방식은 범위 검색보다는 동등 조인(EQUI-Join)에서 더 효율적입니다.
1) 해시조인은 두 개의 테이블 간에 조인을 할 때 범위검색이 아닌 동등조인(EQUI-Join)에 적합한 방식이다. - 이 설명은 올바릅니다. 해시조인은 동등 조인에 최적화되어 있습니다.
2) 작은 테이블(Build Input)을 먼저 읽어서 Hash Area에 해시 테이블을 생성하는 방법으로 큰 테이블로 Hash Area를 생성하면 과다한 Sort가 유발되어 성능이 저하될 수 있다. - 이 설명도 정확합니다. 해시조인에서는 작은 테이블을 기반으로 해시 테이블을 먼저 생성하는 것이 일반적입니다.
4) 해시조인은 수행 빈도가 낮고 수행시간이 오래 걸리는 대용량 테이블에 대한 조인을 할 때 유용하다. - 이 설명 역시 해시조인의 특성과 장점을 정확하게 반영합니다.
반면에,
3) 온라인 트랜잭션 처리(OLTP)에 유용하다. - 이 설명은 옳지 않습니다. OLTP 시스템은 빠른 응답 시간과 높은 트랜잭션 처리량을 요구하는 환경으로, 해시조인은 주로 대용량 데이터를 처리하는 온라인 분석 처리(OLAP)나 배치 처리 같은 환경에서 유용합니다. OLTP 환경에서는 해시조인보다 다른 최적화된 조인 방법이나 색인 사용이 더 적합할 수 있습니다.
OLAP vs OLTP
OLAP(Online Analytical Processing)과 OLTP(Online Transaction Processing)는 데이터베이스 시스템의 두 가지 주요 사용 유형입니다. 이들 간의 주요 차이점은 처리하는 트랜잭션의 유형, 데이터에 대한 접근 방식, 시스템 설계 목적 등에서 나타납니다.
OLTP (Online Transaction Processing)
- 목적: 일상적인 트랜잭션 처리에 초점을 맞춘 시스템입니다. 예를 들어, 은행 거래, 온라인 주문, 예약 시스템 등이 있습니다.
- 트랜잭션 유형: 소규모의, 단순하고, 반복적인 트랜잭션을 처리합니다.
- 데이터 접근: 데이터는 상세하고, 현재의, 운영 데이터에 중점을 둡니다.
- 성능 요구사항: 빠른 응답 시간과 높은 트랜잭션 처리량이 요구됩니다.
- 데이터베이스 디자인: 정규화된 데이터베이스 구조를 사용하여 데이터의 무결성을 유지하고 중복을 최소화합니다.
- 주 사용자: 엔드 유저 및 클라이언트 애플리케이션입니다.
OLAP (Online Analytical Processing)
- 목적: 복잡한 분석, 비즈니스 인텔리전스 작업, 데이터 마이닝 등에 사용됩니다. 예를 들어, 판매 트렌드 분석, 재무 보고, 예측 모델링 등이 있습니다.
- 트랜잭션 유형: 대량의 데이터를 사용한 복잡한 쿼리와 분석 작업을 처리합니다.
- 데이터 접근: 데이터는 종종 대량의, 역사적인, 요약된 정보에 중점을 둡니다.
- 성능 요구사항: 높은 처리 능력과 복잡한 쿼리에 대한 최적화가 요구됩니다.
- 데이터베이스 디자인: 비정규화 또는 다차원 데이터 모델을 사용하여 분석과 보고를 용이하게 합니다.
- 주 사용자: 데이터 분석가, 비즈니스 애널리스트, 경영진입니다.
차이점 요약
- 용도 및 목적: OLTP는 일상적인 비즈니스 트랜잭션 처리에, OLAP는 비즈니스 분석 및 의사 결정 지원에 초점을 맞춥니다.
- 트랜잭션 유형 및 데이터 처리: OLTP는 빠른 소규모 트랜잭션 처리에, OLAP는 대용량 데이터를 활용한 복잡한 쿼리 및 분석 작업에 최적화되어 있습니다.
- 데이터베이스 설계: OLTP 시스템은 데이터의 무결성과 효율적인 트랜잭션 처리를 위해 정규화된 구조를, OLAP 시스템은 분석을 용이하게 하기 위해 비정규화 또는 다차원 구조를 사용합니다.
- 성능 요구사항: OLTP는 응답 시간과 트랜잭션 처리량이, OLAP는 처리 능력과 쿼리 최적화가 중요합니다.
- 사용자: OLTP는 엔드 유저와 일상적인 운영에 관련된 사용자를, OLAP는 데이터 분석과 의사 결정에 관련된 전문가를 대상으로 합니다.
문제 12. 다음 보기 중 Join기법에 대한 설명으로 가장 적절한 것은?
1) Nested Loop Join은 OLTP 시스템에서 데이터를 조인할 때 먼저 나오는 테이블의 선택도가 낮은 테이블을 참조하는 것이 유리하다.
2) Sort Merge Join은 오직 동등 Join(Equi Join)에서만 사용할 수 있다.
3) Hash Join은 결과 행의 수가 큰 테이블을 선행 테이블로 사용하면 Hash Area사이즈가 작아져서 성능에 유리하다.
4) Hash Join은 Sort Merge Join, Nested Loop Join보다 항상 성능이 우수하다.
문제 12 해설
Join 기법에 대한 설명으로 가장 적절한 것은 1) Nested Loop Join은 OLTP 시스템에서 데이터를 조인할 때 먼저 나오는 테이블의 선택도가 낮은 테이블을 참조하는 것이 유리하다 입니다.
각 Join 기법의 특성과 설명에 대해 살펴보겠습니다:
-
Nested Loop Join: 두 테이블 간의 조인 시, 한 테이블을 기준으로 루프를 돌며 다른 테이블과 매칭되는 행을 찾는 방식입니다. 이 방식은 선택도가 낮은 테이블, 즉 결과로 반환되는 행의 수가 적은 테이블을 기준 테이블로 사용할 때 효율적입니다. OLTP 시스템에서 소규모 데이터를 대상으로 조인할 때 유리합니다.
-
Sort Merge Join: 두 테이블을 각각 정렬한 후, 순차적으로 스캔하며 매칭되는 행을 찾는 방식입니다. 이 방식은 동등 조인(Equi Join) 뿐만 아니라, 비동등 조인(Non-Equi Join)에서도 사용될 수 있습니다. 따라서 2번 설명은 부정확합니다.
-
Hash Join: 한 테이블에서 해시 테이블을 생성하고, 다른 테이블을 스캔하며 해시 테이블과 매칭되는 행을 찾는 방식입니다. 해시 조인은 결과 행의 수가 적은 테이블을 해시 테이블로 사용할 때 메모리 사용량이 효율적이므로, 3번 설명은 부정확합니다.
-
성능 비교: 해시 조인, 소트 머지 조인, 네스티드 루프 조인 간의 성능은 사용되는 상황과 데이터의 양, 조인되는 테이블의 특성에 따라 달라집니다. 하나의 방식이 모든 상황에서 항상 우수하다고 말할 수 없기 때문에, 4번 설명은 올바르지 않습니다.
따라서, 가장 적절한 설명은 1번입니다.
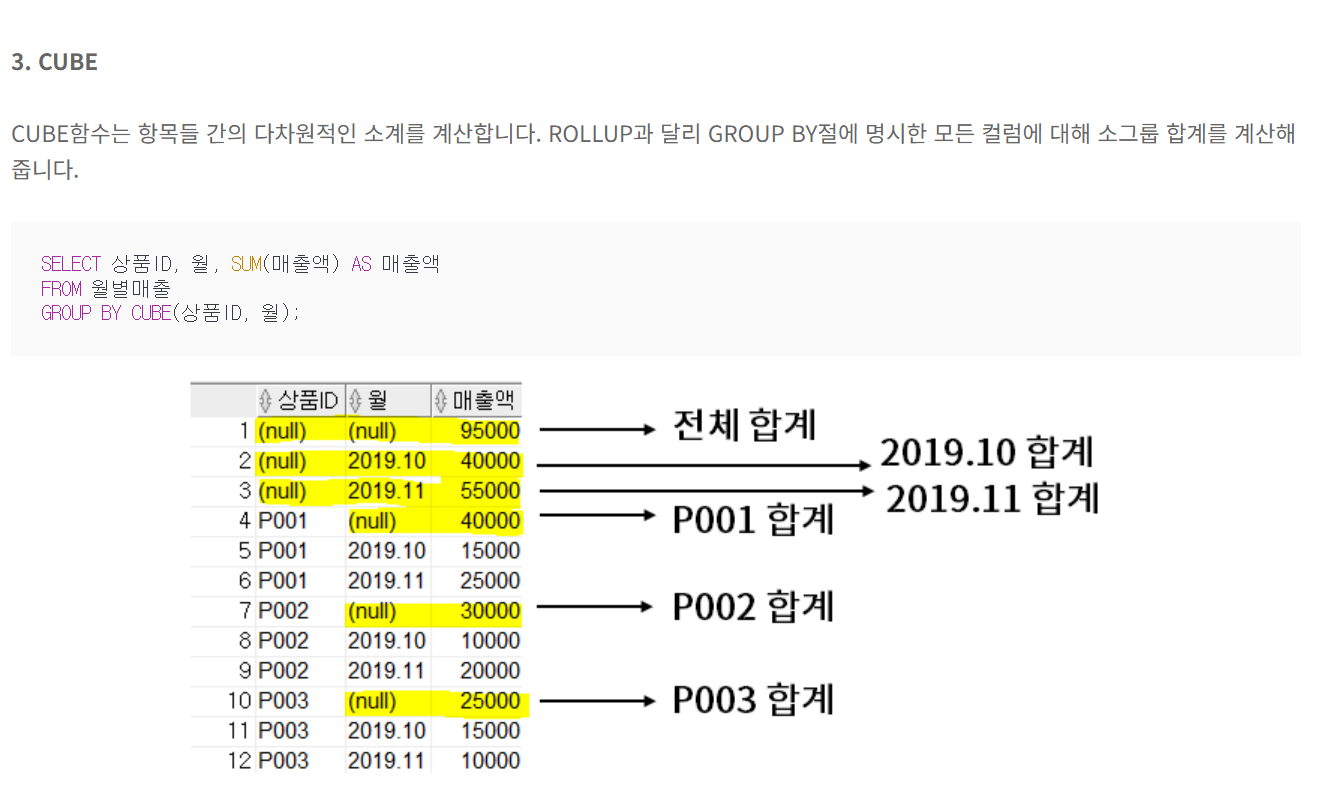
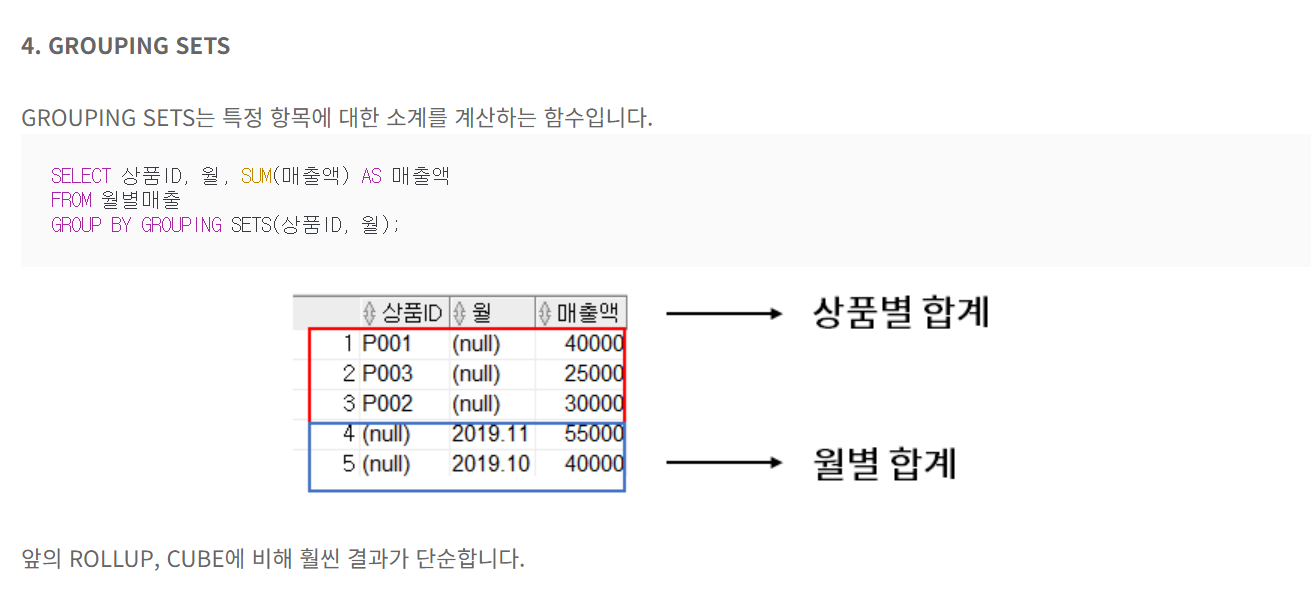
문제 13. ROLL UP, GROUPING SETS, CUBE