azure gpu ✅
- colab 프로 결제해도 환경 구축하기에 한계가 있다

- 데이터 넣으면 데이터 전처리 알아서 해줌 (AutoML)
- 학습 시키면 하이퍼 파라미터 튜닝 알아서 해줌 (AutoML)
Azure Machine Learning Studio
- studio 시작하기
titanic 분류
- titanic.csv 다운로드 : https://github.com/datasciencedojo/datasets/blob/master/titanic.csv
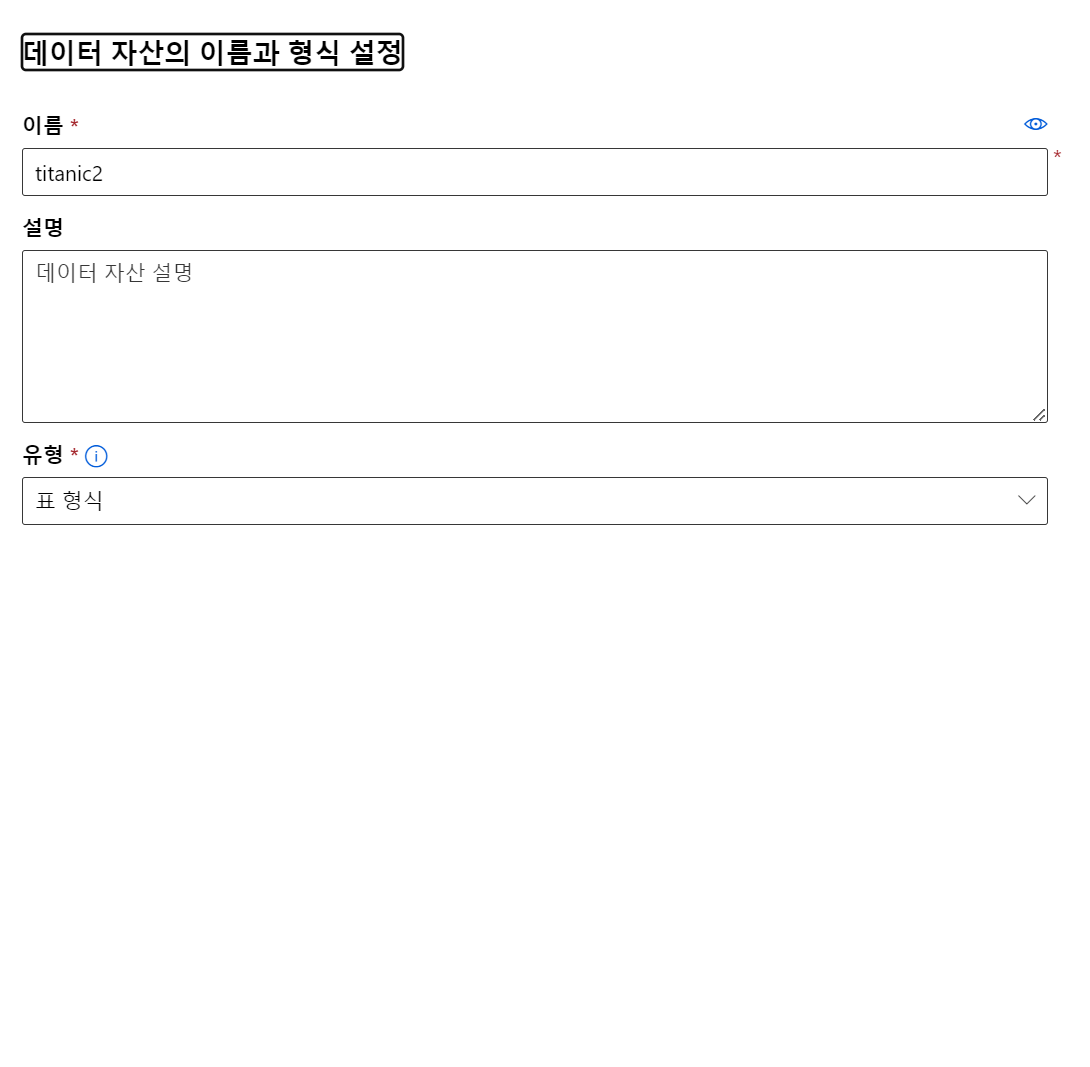
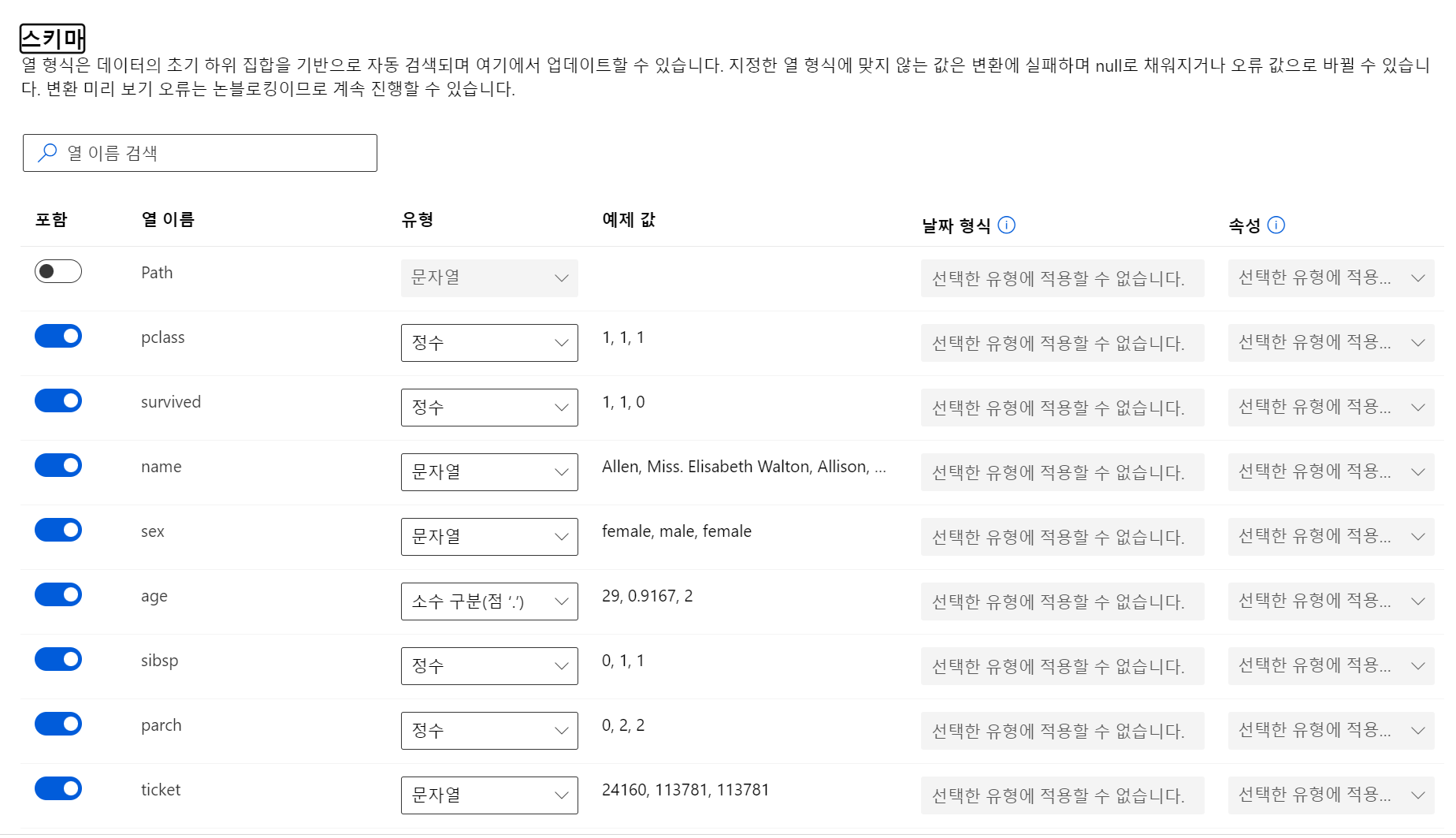
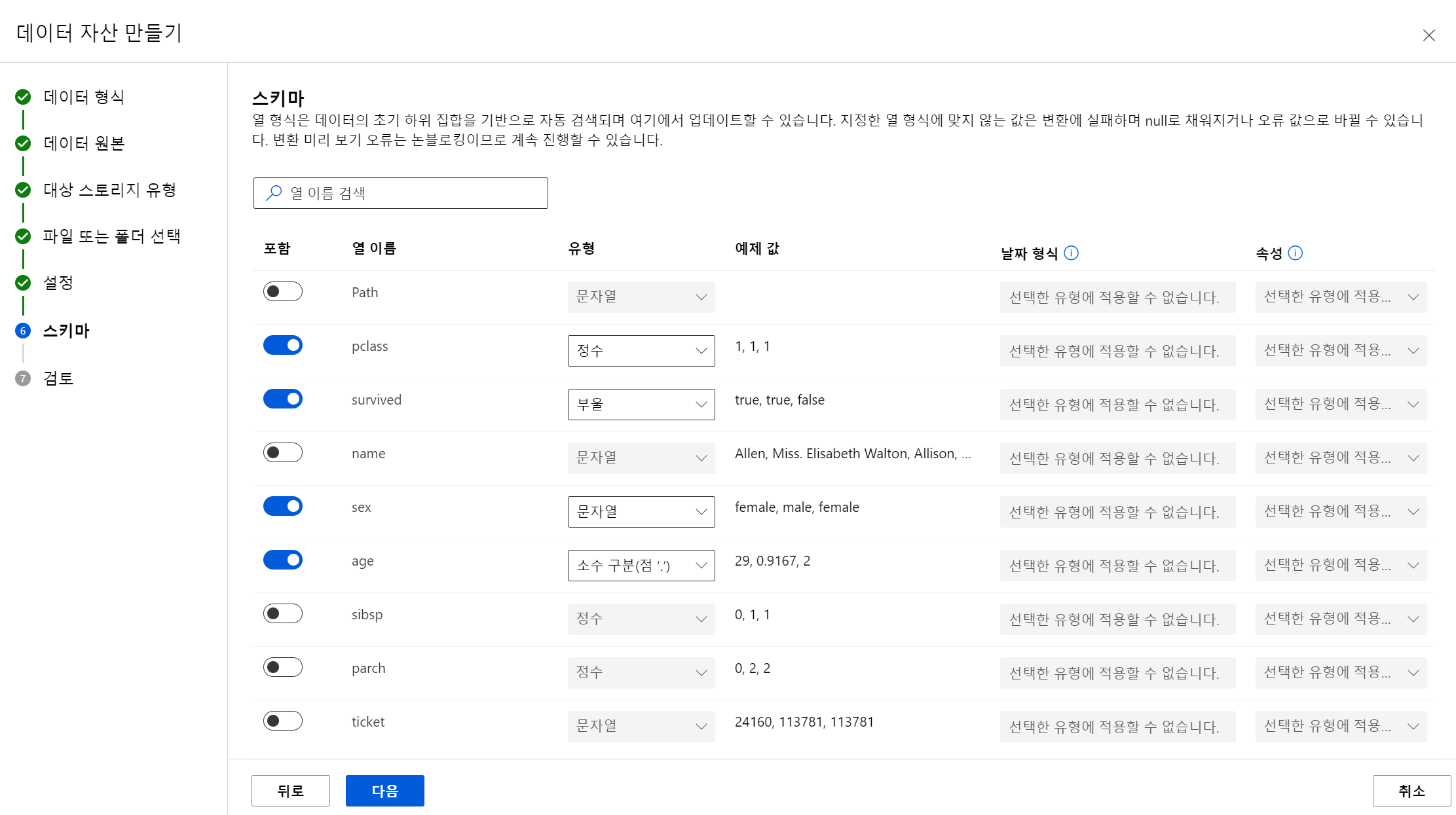
데이터 세트 만들기
- url_file vs 데이터 세트(표)
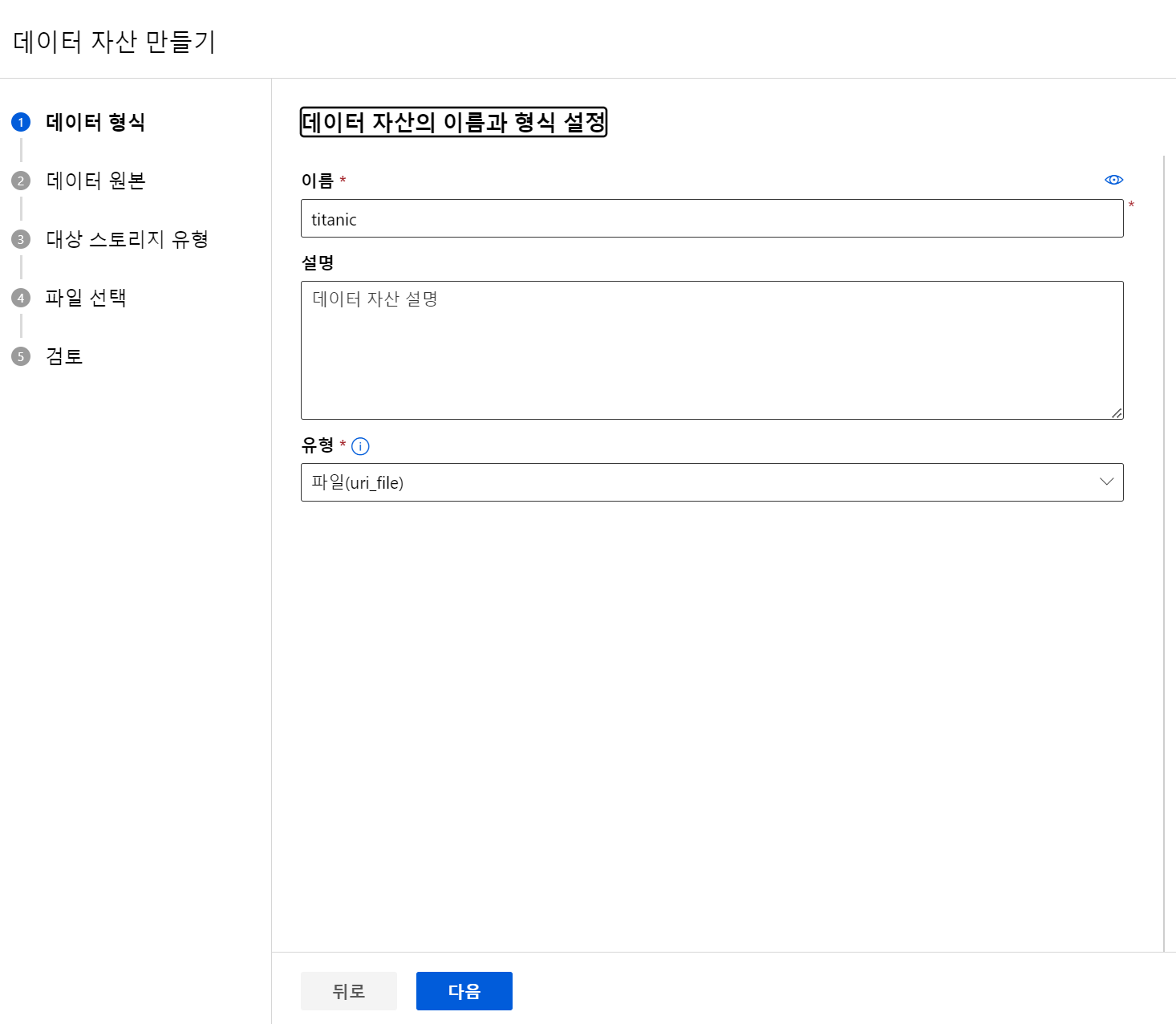
자산 - 데이터 - 만들기 - url_file
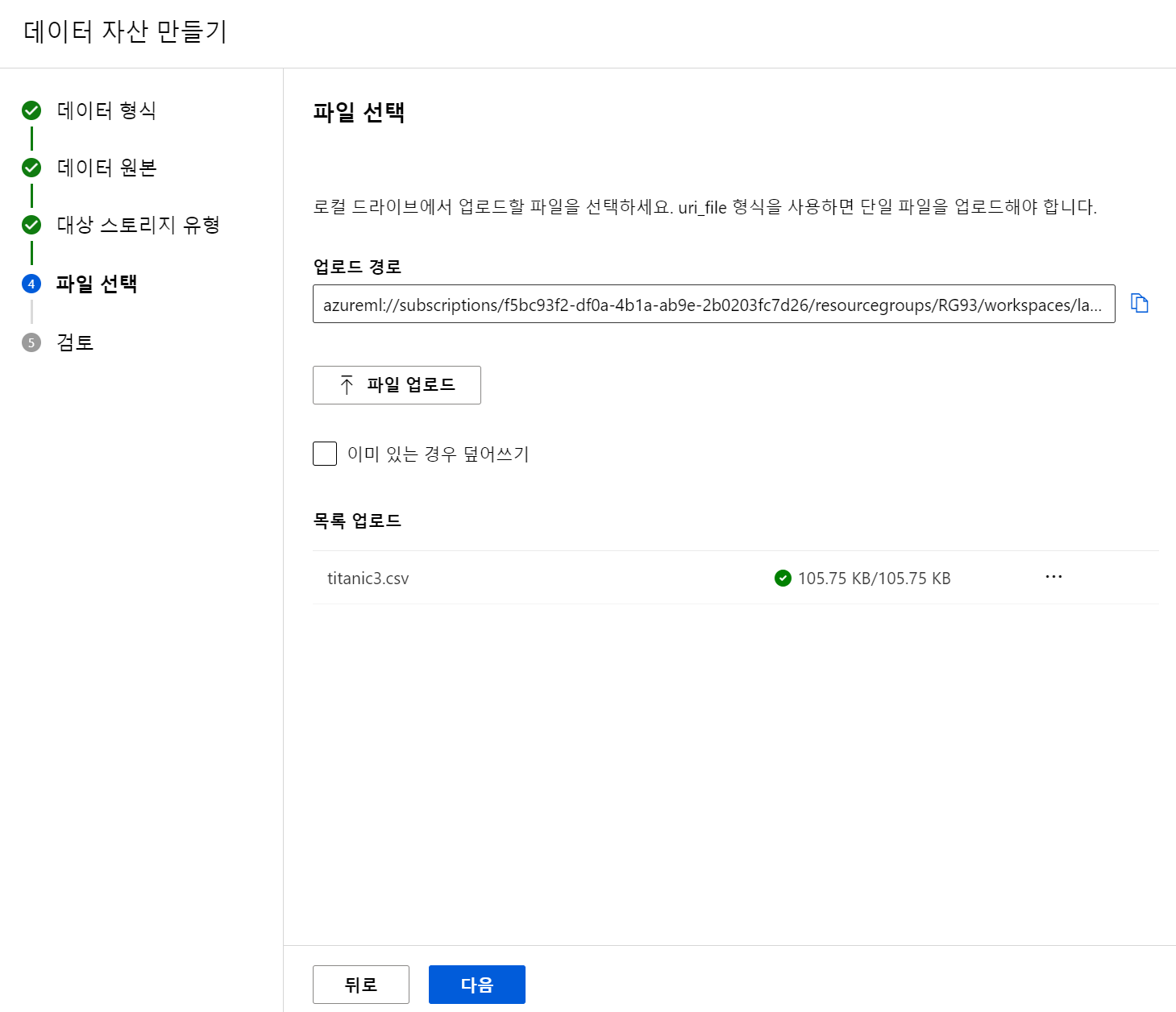
자산 - 데이터 - 만들기 - 표 형식
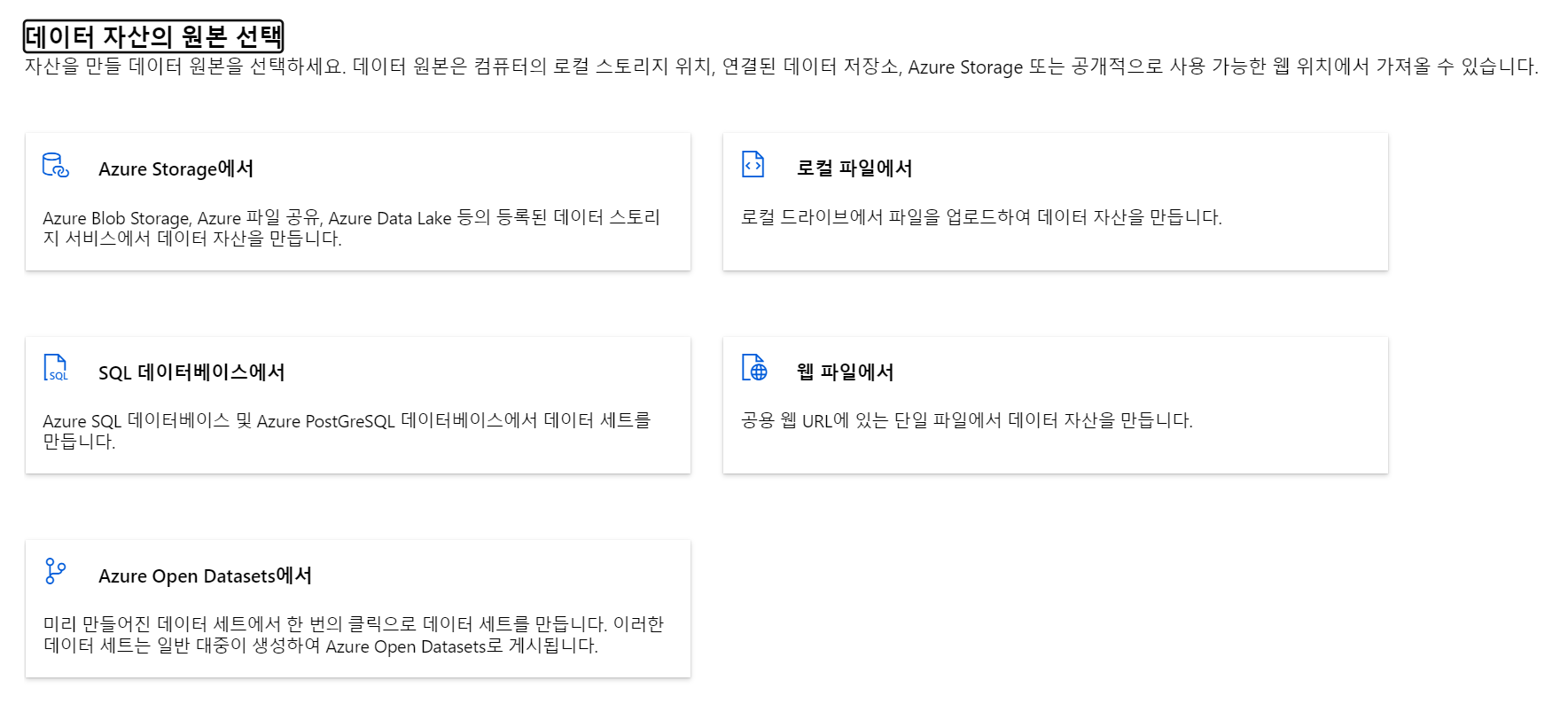
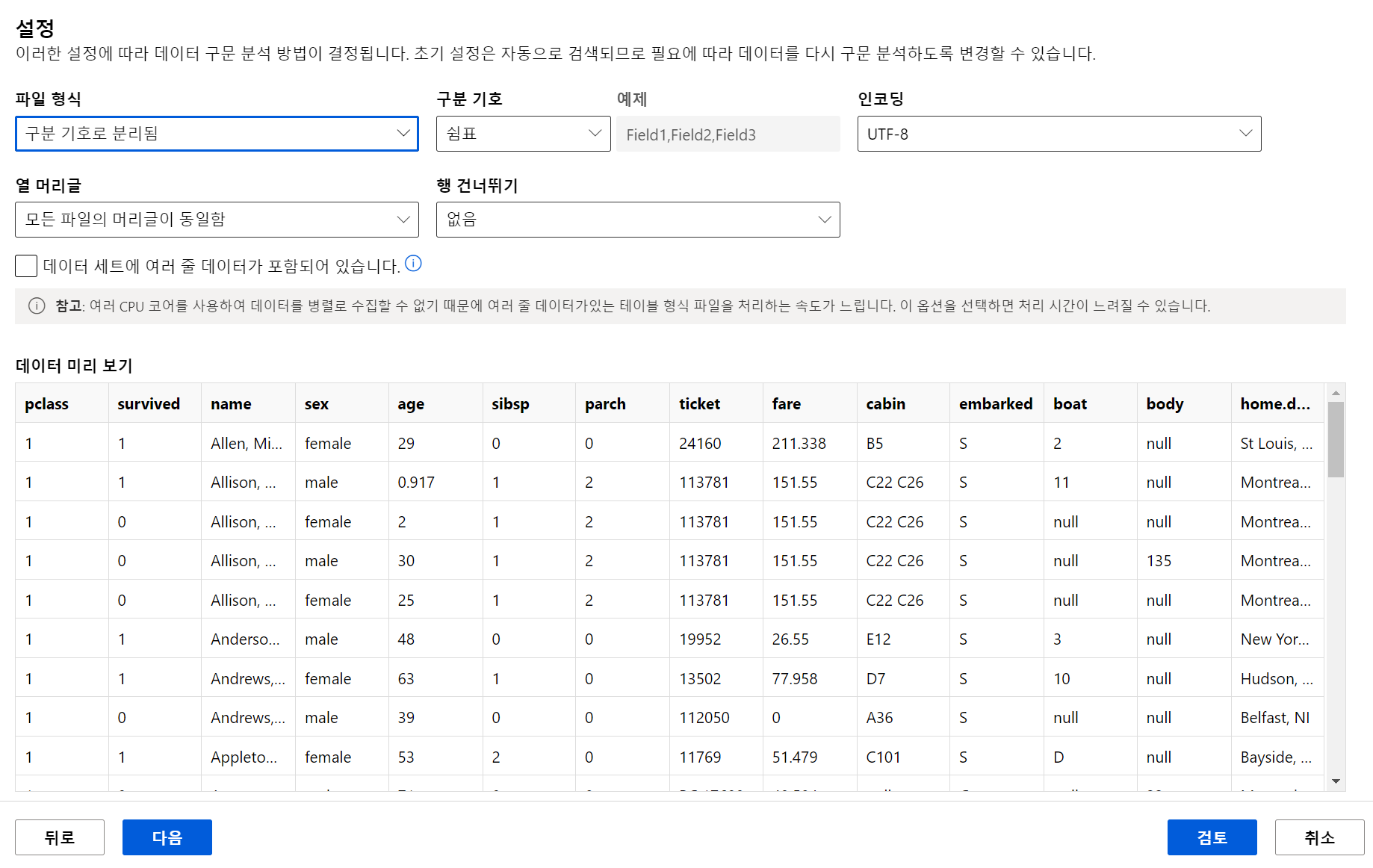
- db에서 끌어올 수 있는듯
- 데이터 세트로 만드는 것이 다음과 같이 설정도 가능하고 더 편하게 쓸 수 있다.
- 쉽게 필요한 컬럼만 가져와서 사용할 수 있다.
디자이너 ✅

- 다른사람이 한 모델들 불러와서 사용 가능하다
- 새로 만들기 (+) 버튼 클릭
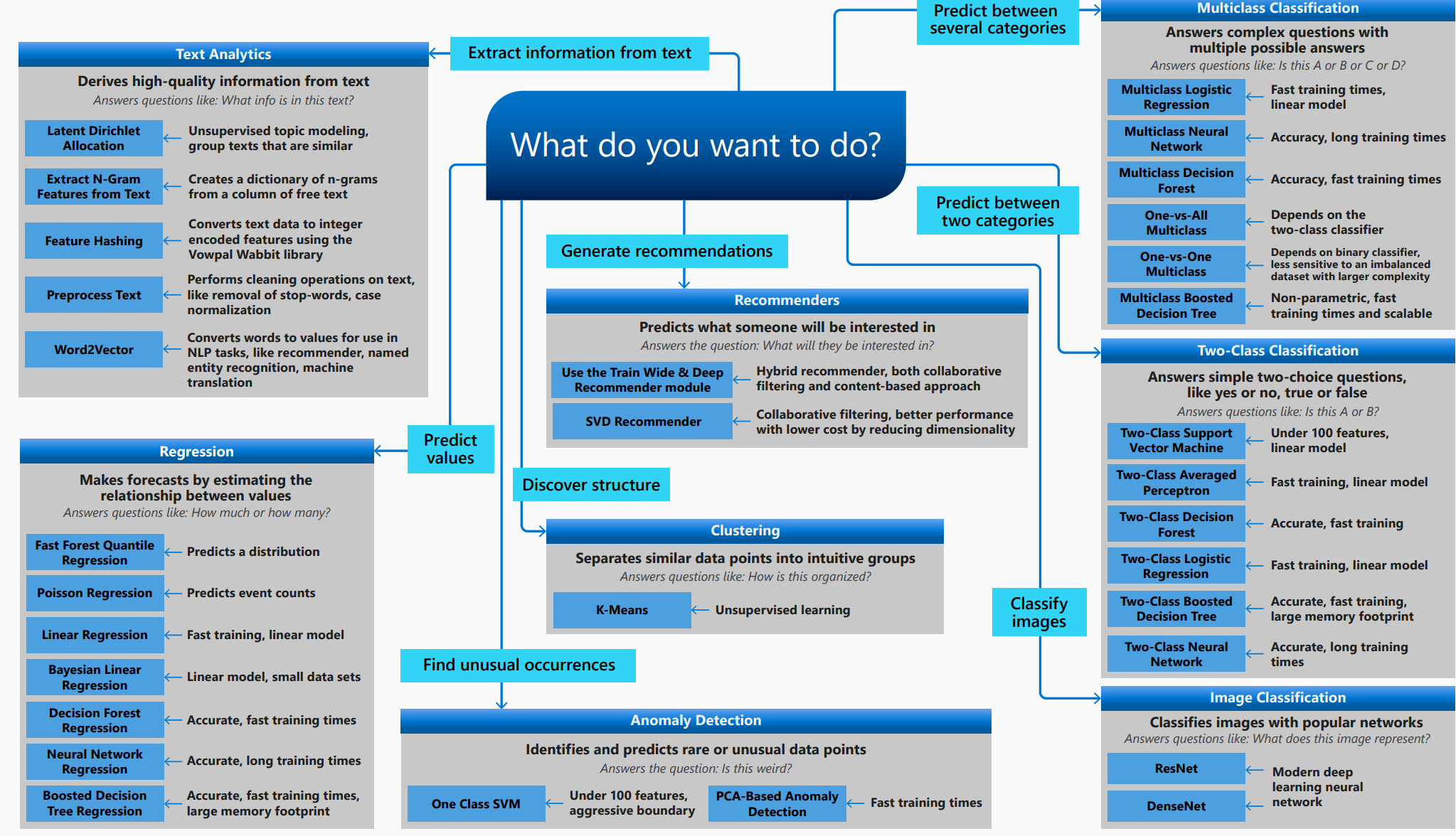
Machine Learning Algorithm Cheat Sheet
- 머글을 위한 머신러닝 방법 찾기
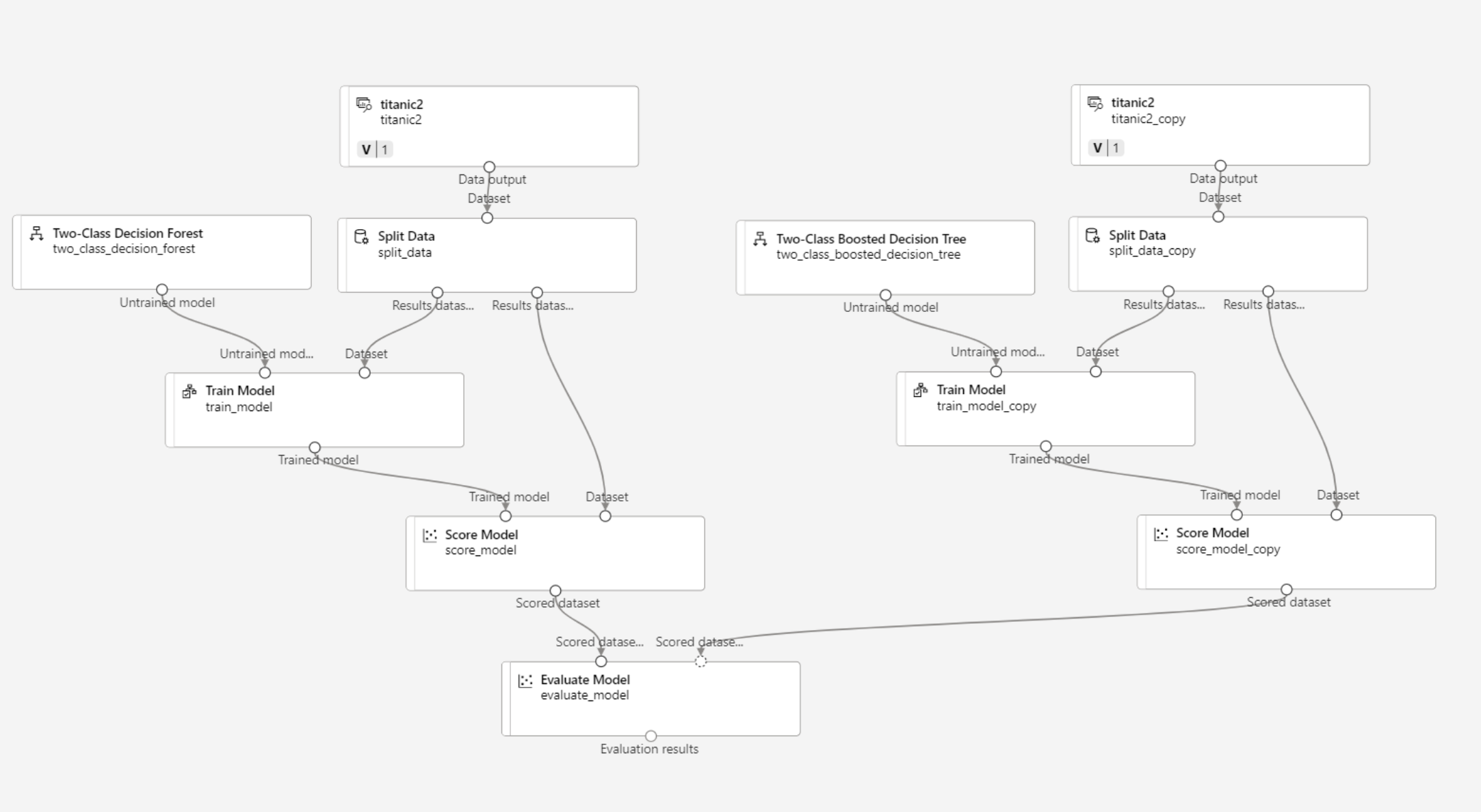
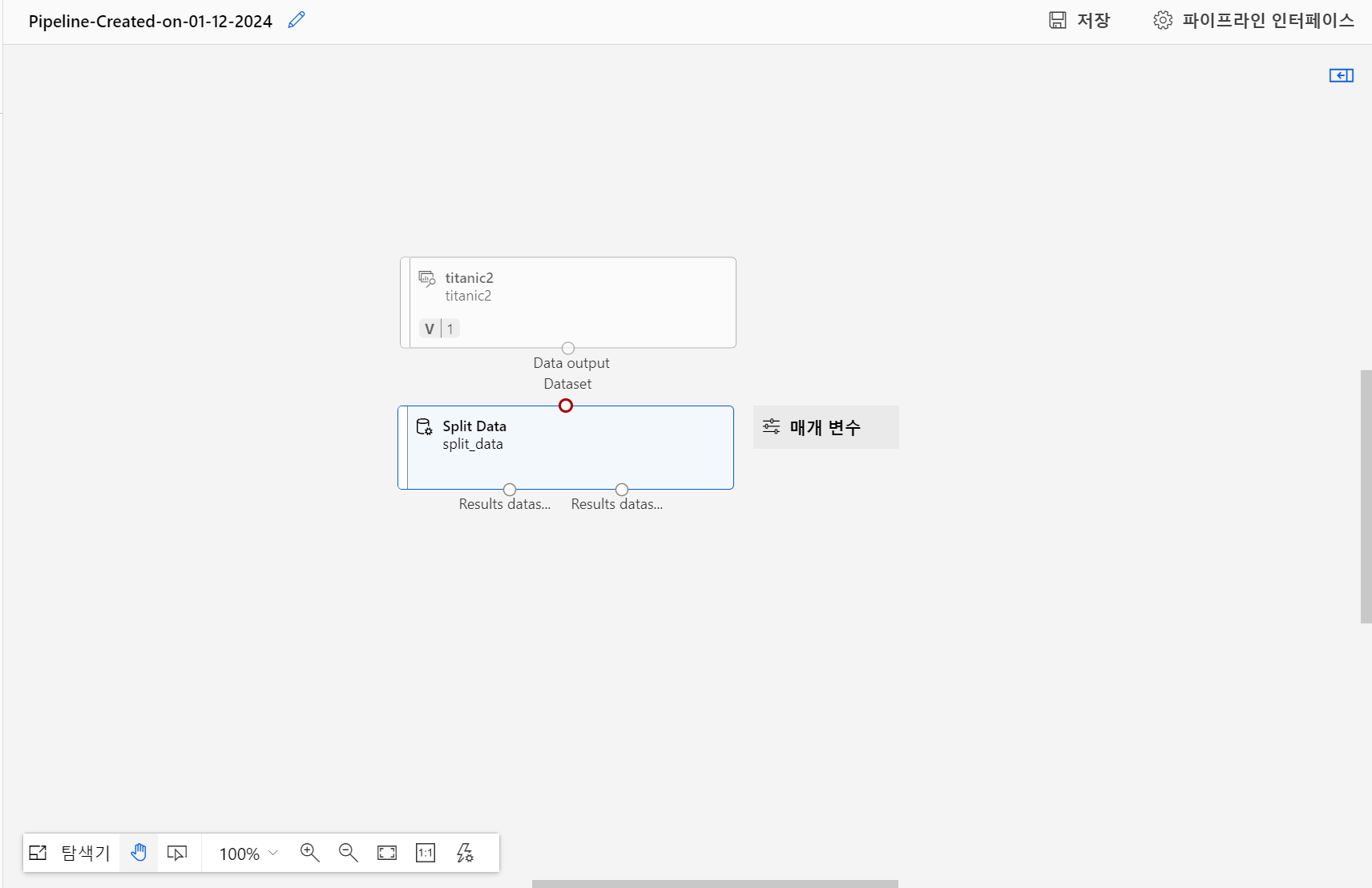
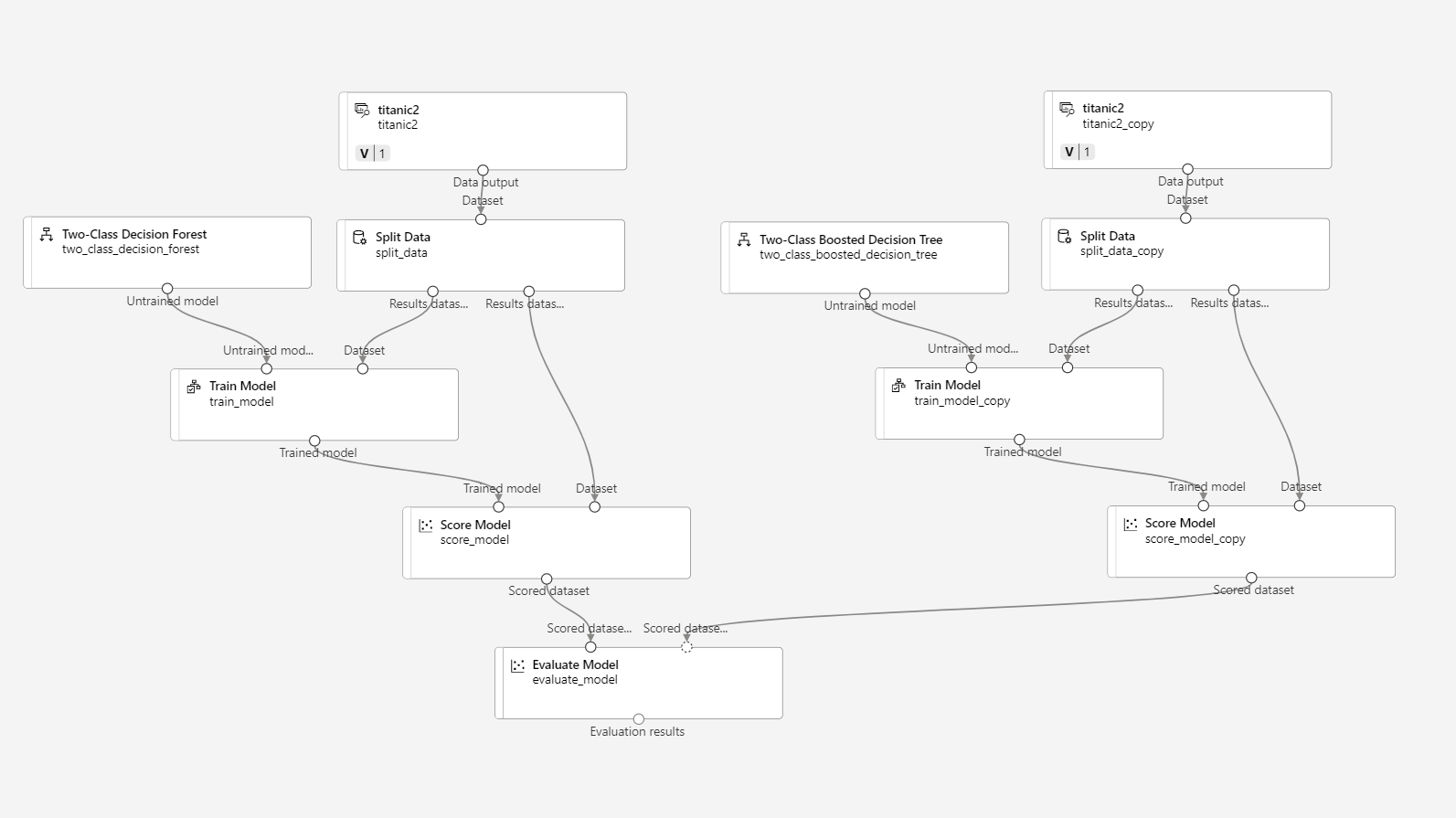
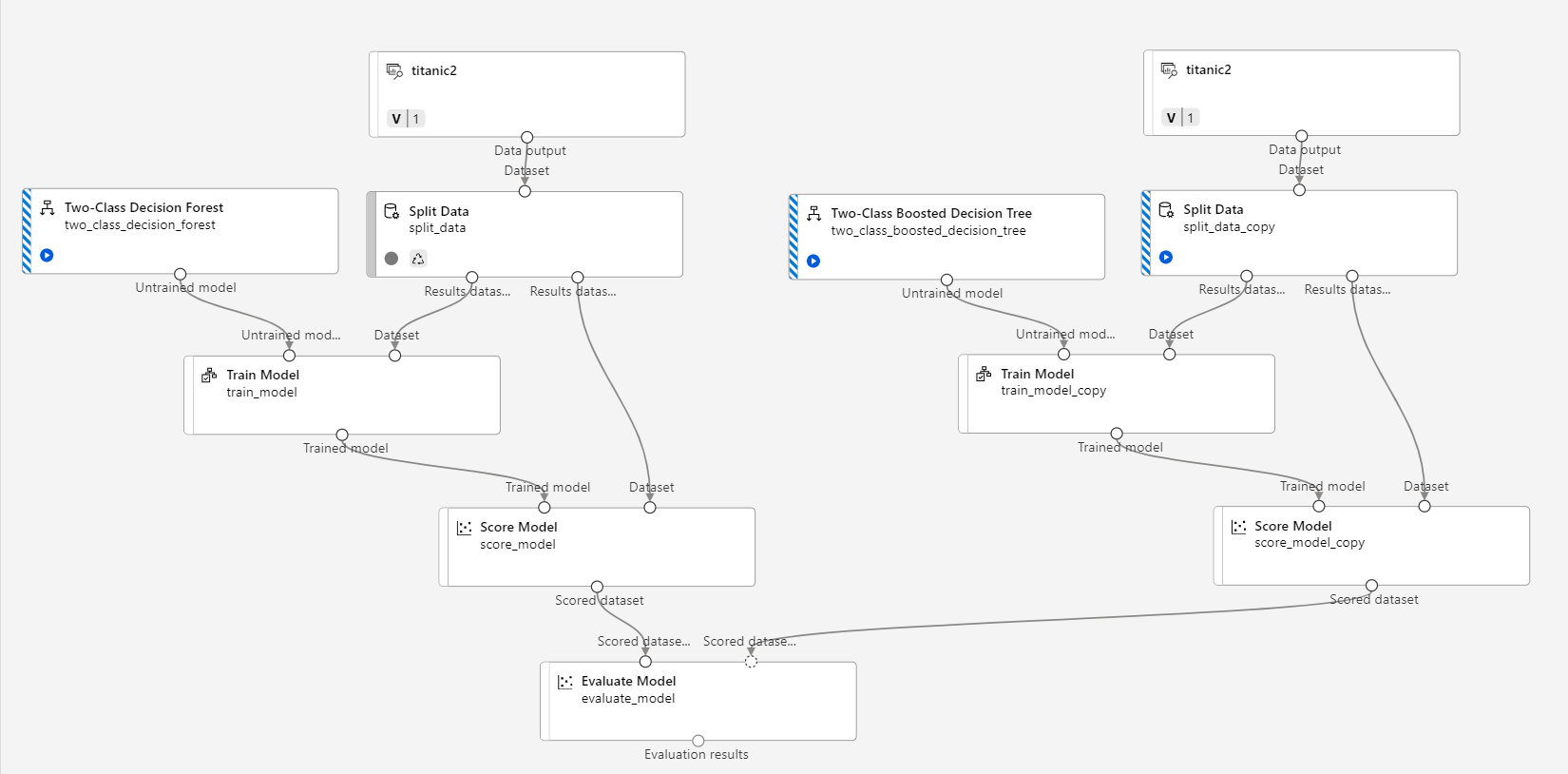
디자이너를 적당히 조합하여 다음과 같은 모델을 만들었다.
컴퓨팅
- 새로 만들기 클릭
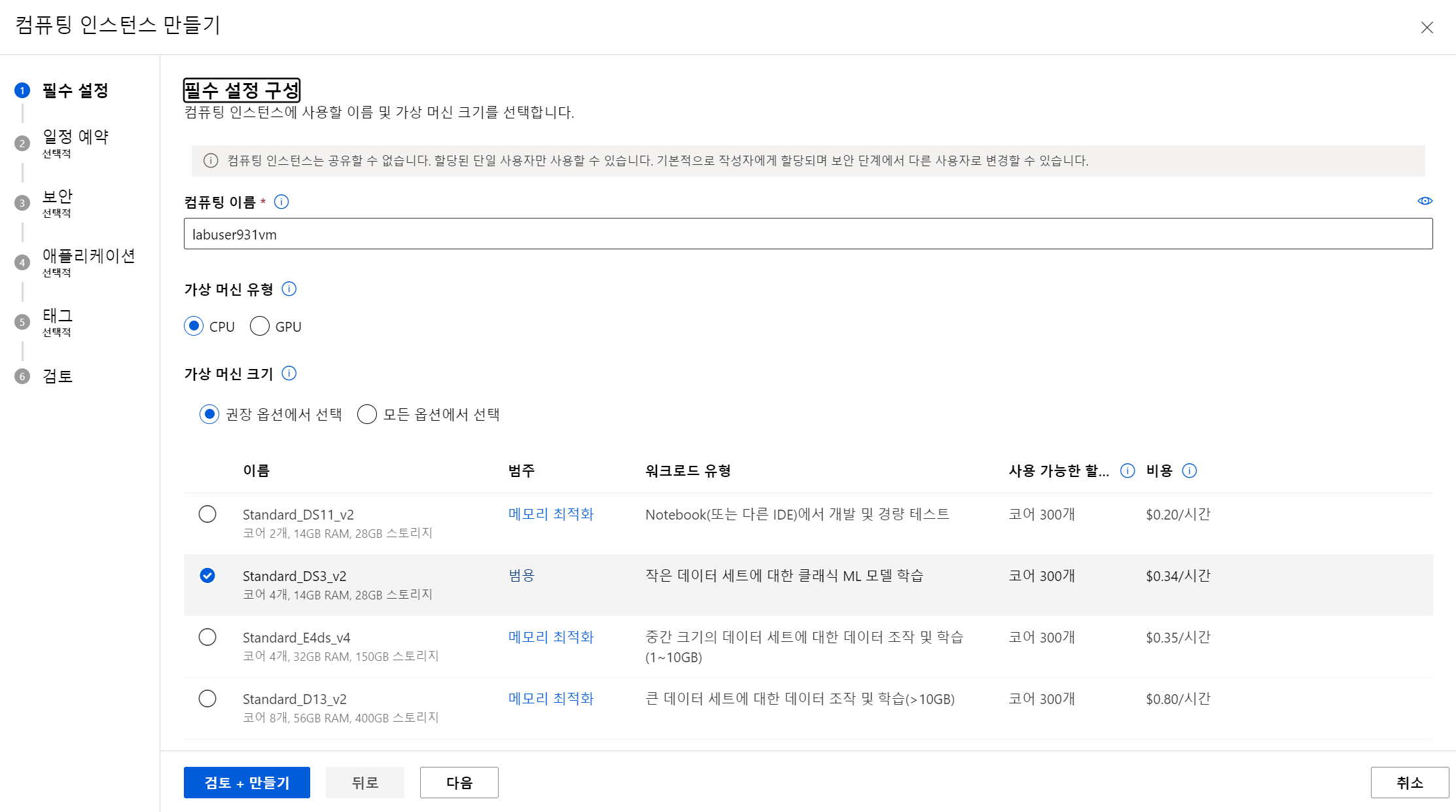
- gpu로 선택하려면 ? 버튼으로 이메일 보내서 gpu 할당해달라고 메일 보내야함

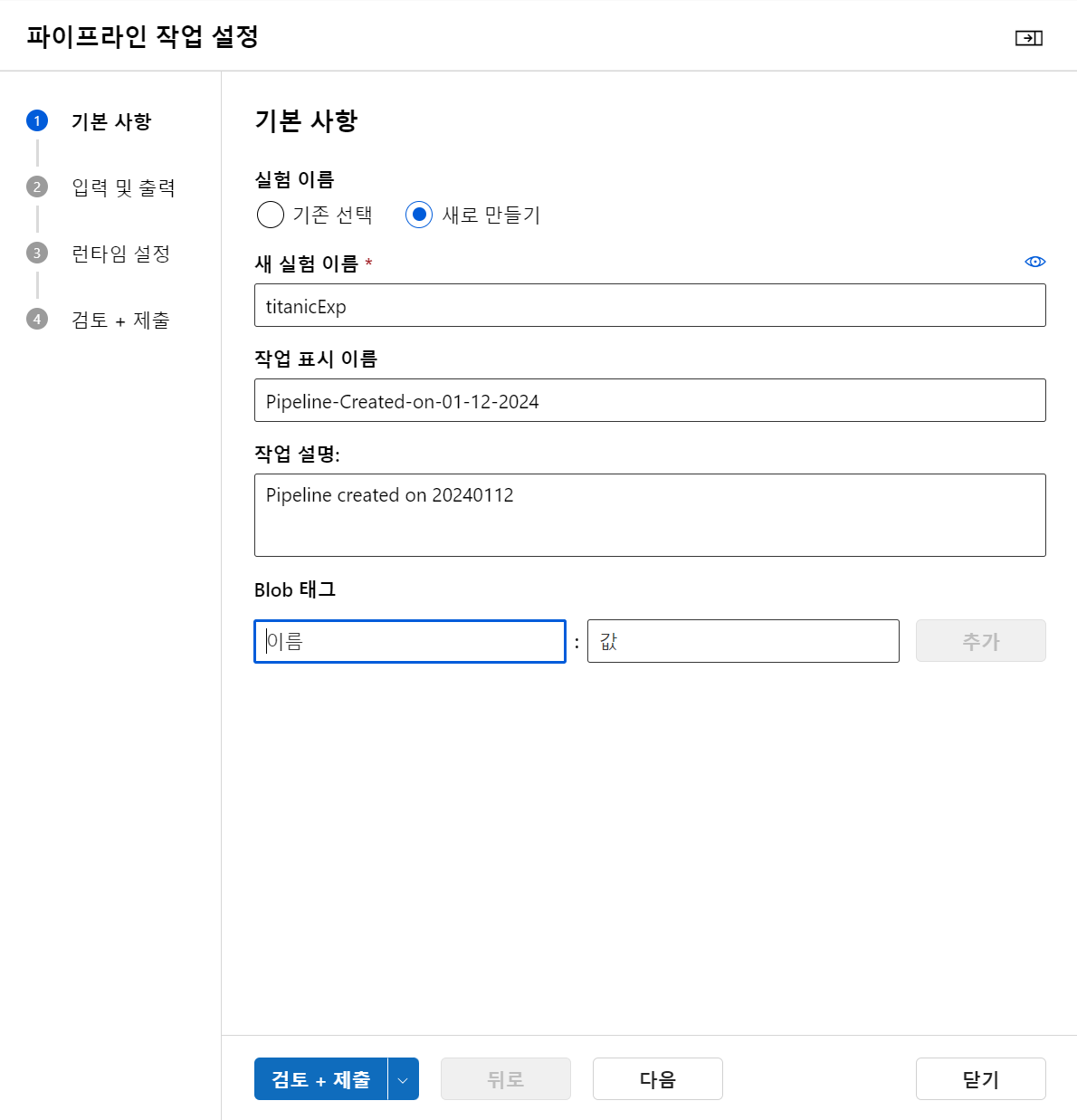
- 다시 디자이너로 돌아와서 구성 및 제출하면 된다.
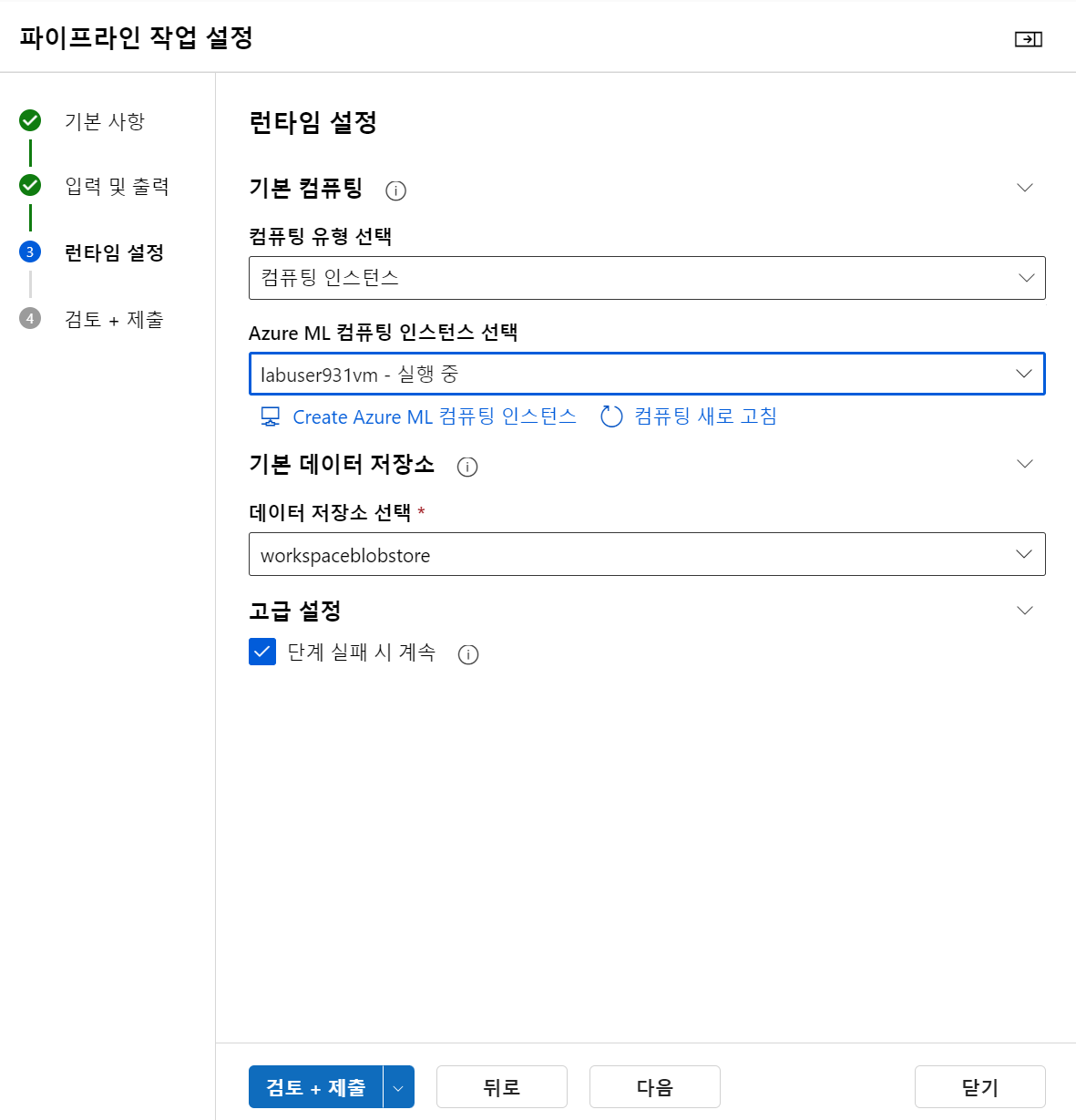
작업
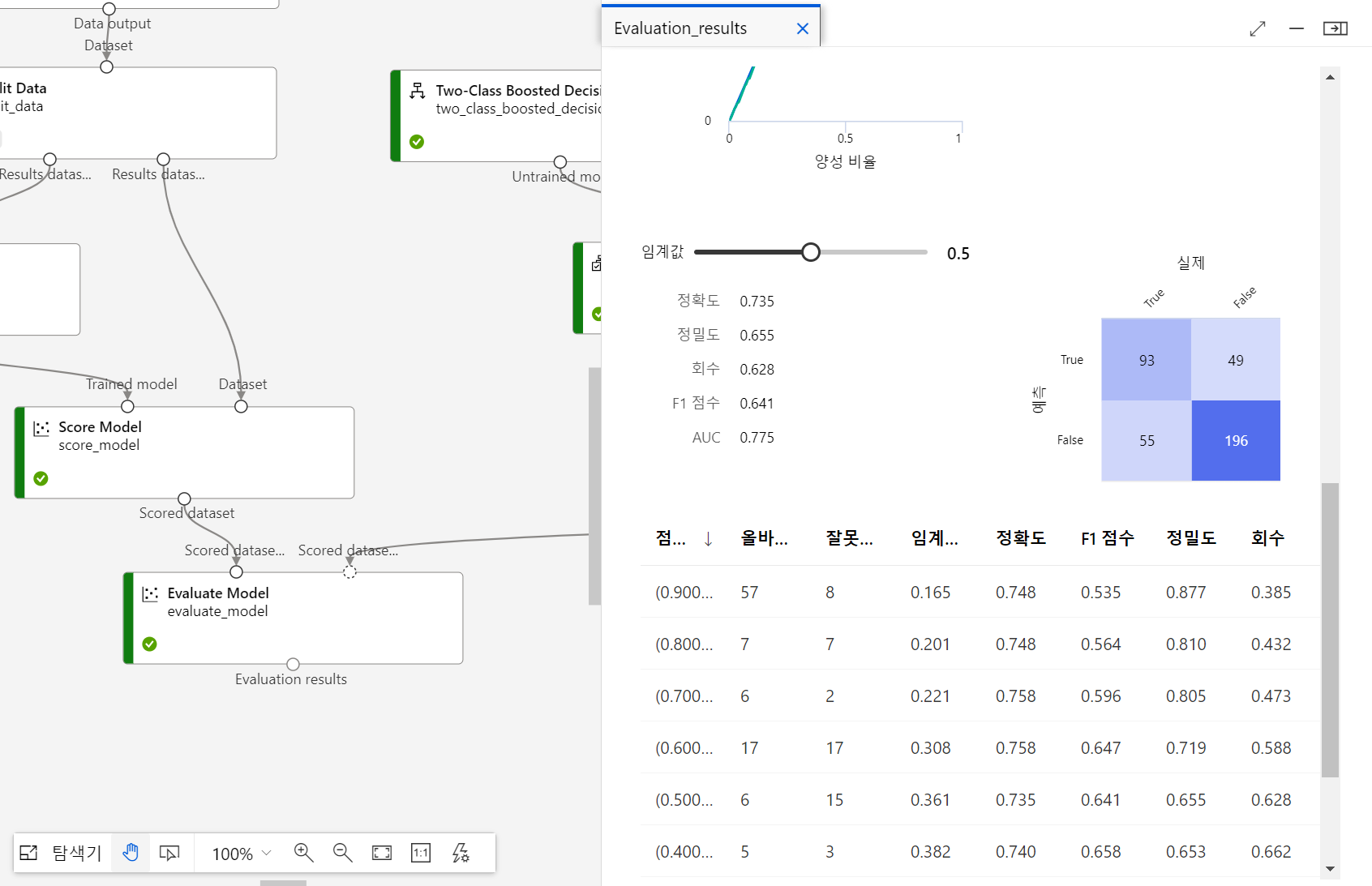
- 제출하면 다음과 같이 머신러닝 하는 것을 시각적으로 확인할 수 있다.
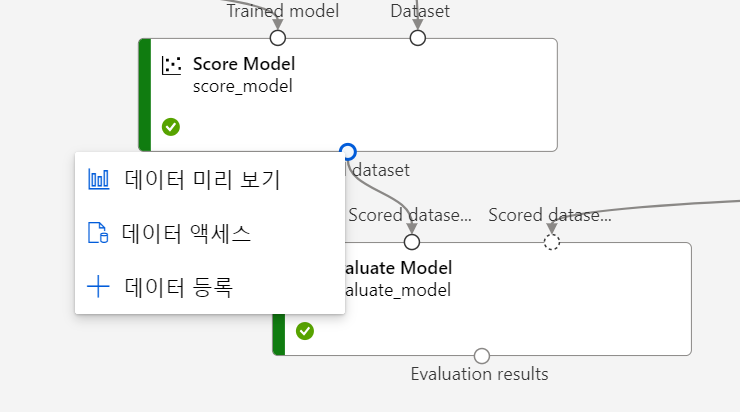
- 데이터 미리보기로 평가 지표 시각화 가능
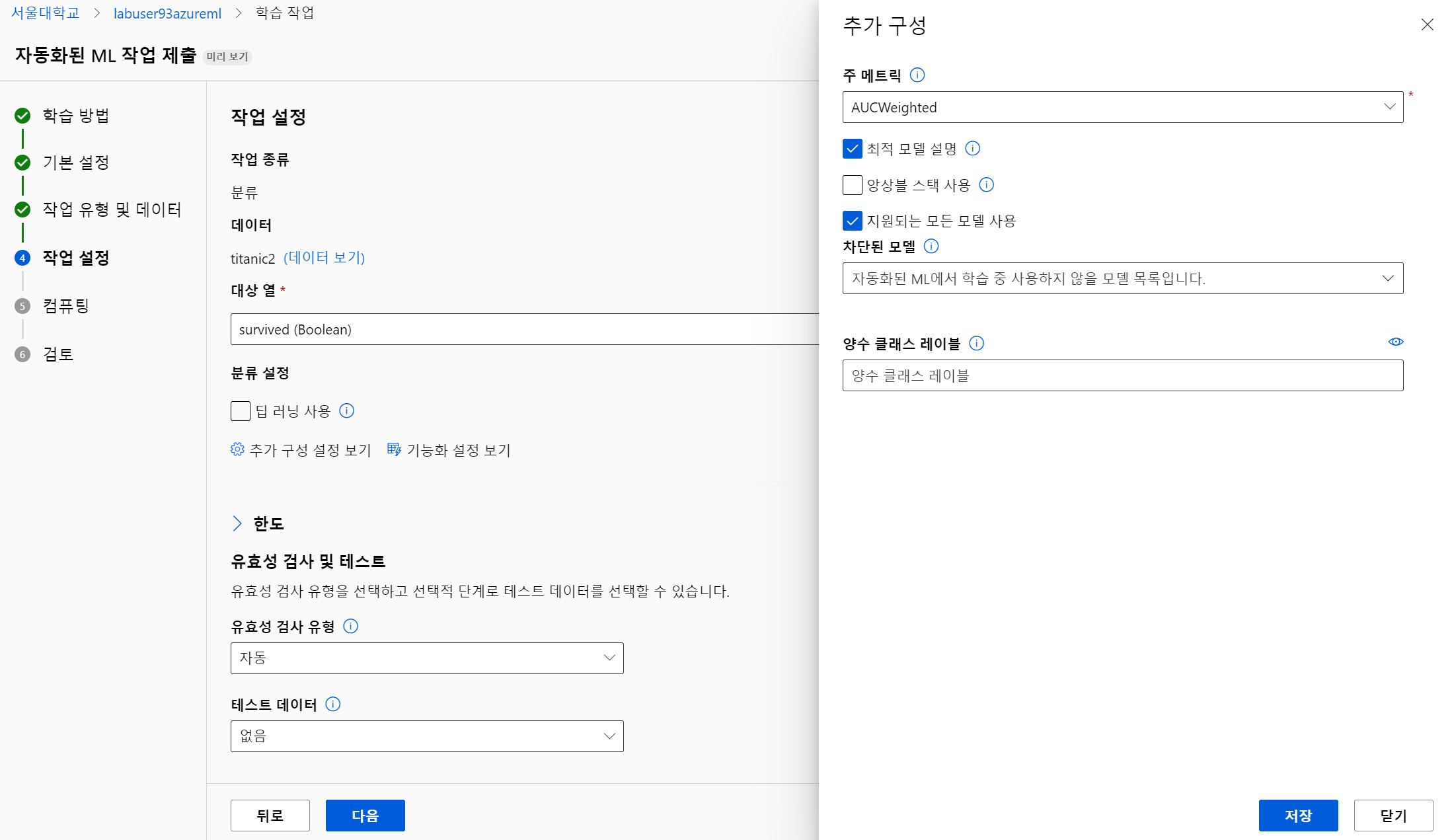
자동화된 ML 👍✅
- AutoML
- 두꺼운 법인카드만 있으면 짱이다

-
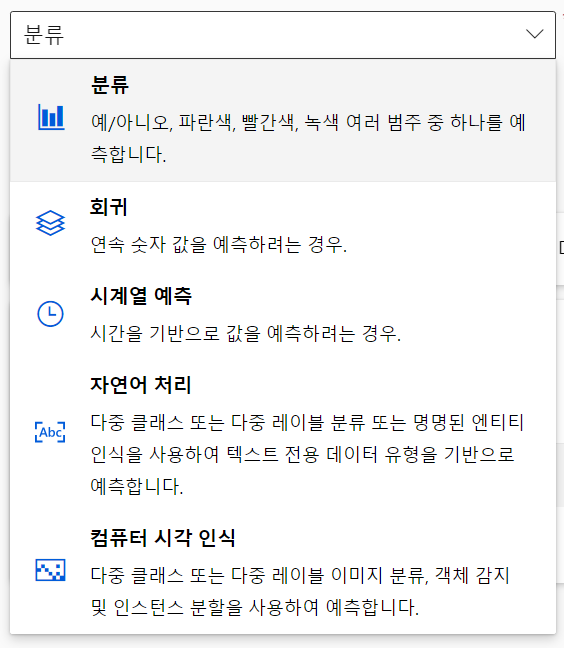
분류, 회귀, 시계열 예측, 자연어 처리, cv 가능하다
-
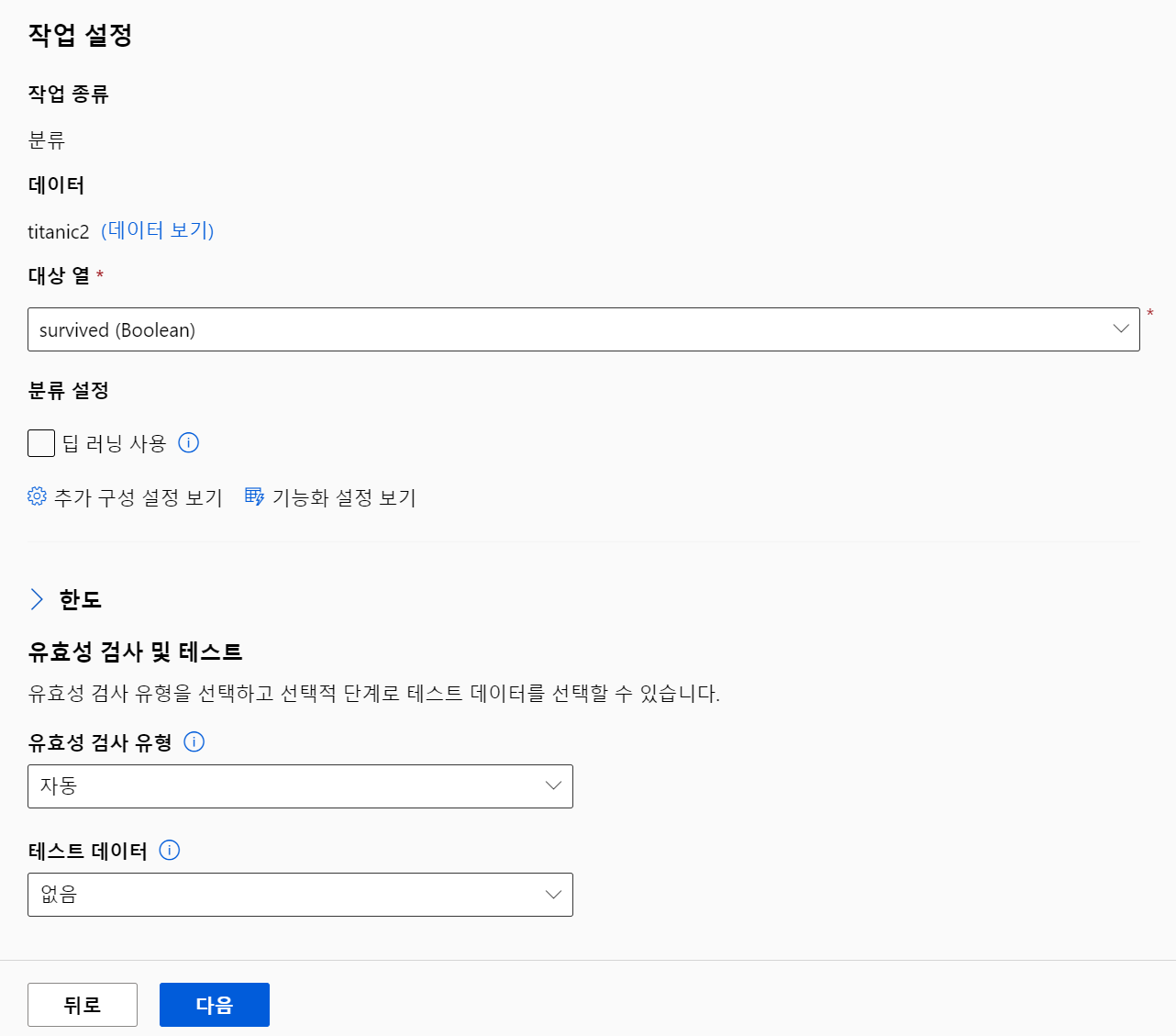
라벨 데이터 설정
-
점수를 어떤 기준으로 할 것인지 체크
NoteBooks ✍️
- 새 파일 만들기
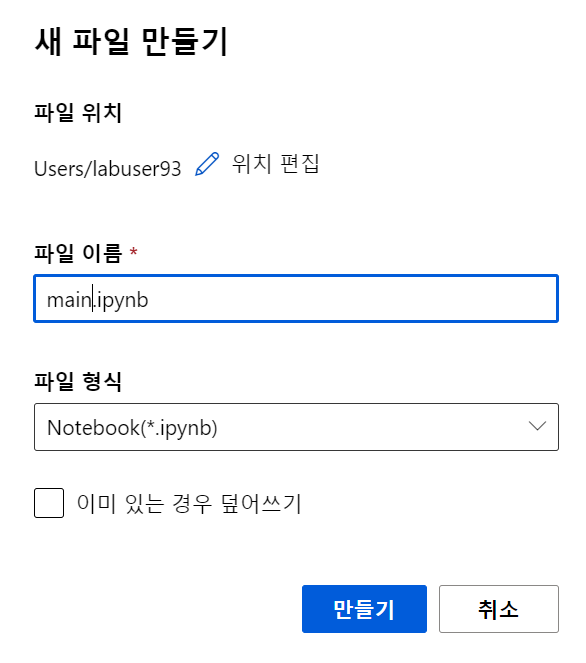
- 환경 : Python 3.8 - AzureML
작업 공간 만들기
from azureml.core import Workspace
from azureml.core import Experiment
ws = Workspace.from_config()
print('Workspace name: ' + ws.name,
'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep='\\n')
experiment = Experiment(workspace=ws, name="diabetes-experiment")- job 탭에서 작업공간 만들어진 것 확인할 수 있다.
- 이후는 원래 하듯이 ml 돌리면 된다.
학습 코드
from azureml.opendatasets import Diabetes
from sklearn.model_selection import train_test_split
x_df = Diabetes.get_tabular_dataset().to_pandas_dataframe().dropna()
y_df = x_df.pop("Y")
X_train, X_test, y_train, y_test = train_test_split(x_df, y_df, test_size=0.2, random_state=66)
print(X_train)
best model 다운로드
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
from sklearn.externals import joblib
import math
alphas = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]
for alpha in alphas:
run = experiment.start_logging()
run.log("alpha_value", alpha)
model = Ridge(alpha=alpha)
model.fit(X=X_train, y=y_train)
y_pred = model.predict(X=X_test)
rmse = math.sqrt(mean_squared_error(y_true=y_test, y_pred=y_pred))
run.log("rmse", rmse)
model_name = "model_alpha_" + str(alpha) + ".pkl"
filename = "outputs/" + model_name
joblib.dump(value=model, filename=filename)
run.upload_file(name=model_name, path_or_stream=filename)
run.complete()
print(f"{alpha} exp completed") 데이터셋 등록
import numpy as np
from azureml.core import Dataset
np.savetxt('features.csv', X_train, delimiter=',')
np.savetxt('labels.csv', y_train, delimiter=',')
datastore = ws.get_default_datastore()
datastore.upload_files(files=['./features.csv', './labels.csv'],
target_path='diabetes-experiment/',
overwrite=True)
input_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, 'diabetes-experiment/features.csv')])
output_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, 'diabetes-experiment/labels.csv')])모델 등록
import sklearn
from azureml.core import Model
from azureml.core.resource_configuration import ResourceConfiguration
model = Model.register(workspace=ws,
model_name='diabetes-experiment-model',
model_path=f"./{str(best_run.get_file_names()[0])}",
model_framework=Model.Framework.SCIKITLEARN,
model_framework_version=sklearn.__version__,
sample_input_dataset=input_dataset,
sample_output_dataset=output_dataset,
resource_configuration=ResourceConfiguration(cpu=1, memory_in_gb=0.5),
description='Ridge regression model to predict diabetes progression.',
tags={'area': 'diabetes', 'type': 'regression'})
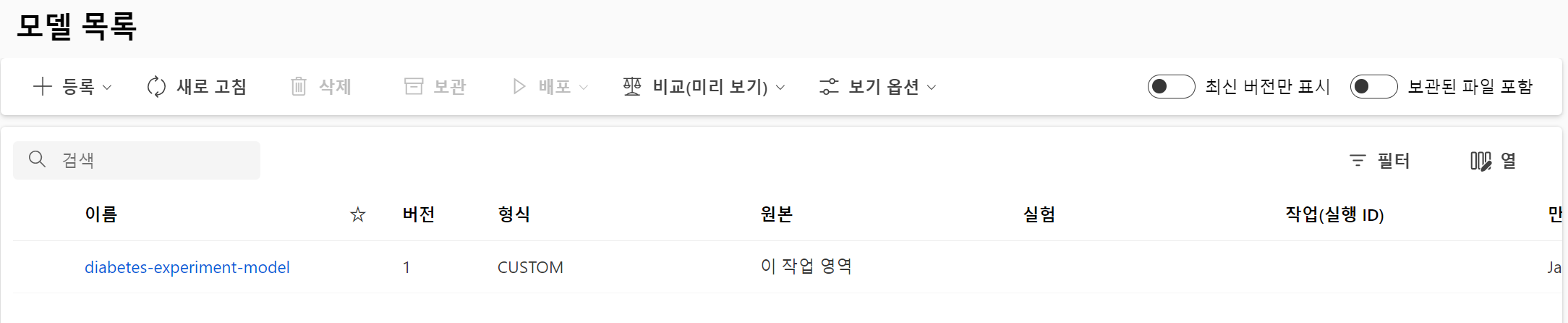
print('Name:', model.name)
print('Version:', model.version)
- 다음과 같이 모델이 웹에 모델이 등록된 것을 확인할 수 있다
모델 배포
- 도커 컨테이너로 배포하여 사용할 수 있게 한다
service_name = 'diabetes-service'
service = Model.deploy(ws, service_name, [model], overwrite=True)
service.wait_for_deployment(show_output=True)
배포 서비스 테스트
import json
input_payload = json.dumps({
'data': X_train[0:2].values.tolist(),
'method': 'predict'
})
output = service.run(input_payload)
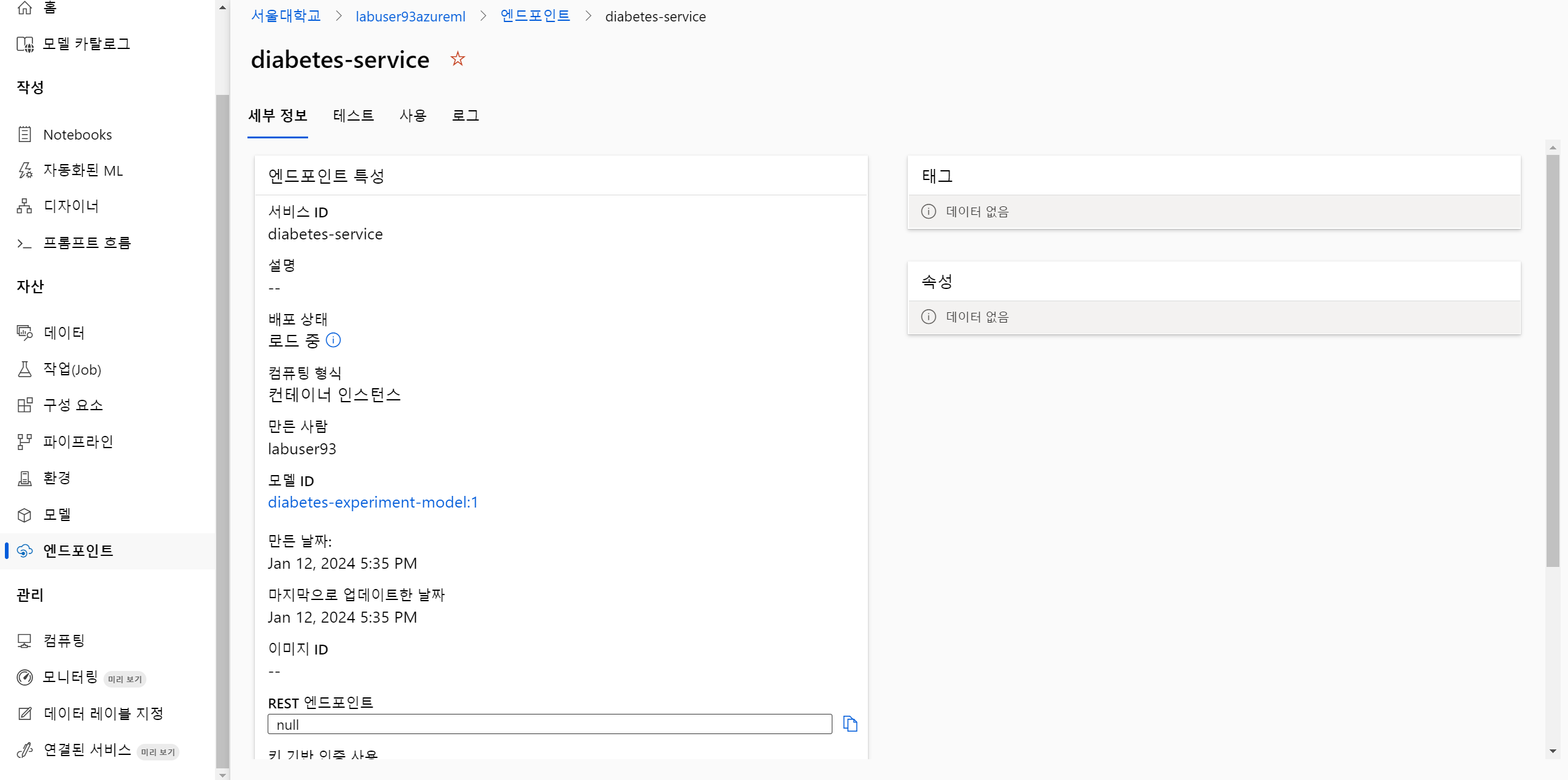
print(output) 엔드포인트에서 확인
- 학습된 모델 엔트포인트를 확인할 수 있다.

개발자 블로그 ^0^