
개요
빅데이터분석기사 자격증은 한국데이터산업진흥원(Kdata)이 주관하는 국가 공인자격이다. 2020년에 처음 신설되어, 2021년 4월 17일에 첫 시험이 개최되었다. 빅데이터 전문가를 양성하기 위해 마련된 이 시험은 빅데이터 분석 기획, 수집, 저장, 처리, 분석 및 시각화에 대한 실무 역량을 검증한다.
응시 자격 요건
- 전공 무관 대학 졸업자 또는 졸업 예정자
- 관련 학과 2·3년제 졸업 후 2·3년의 직장 경력이 있는 자
- 종목 무관 기사 동급 이상의 자격을 취득한 사람
- 4년 이상의 직장 경력이 있는 사람
시험 구성
- 필기시험: 빅데이터 분석 기획, 탐색, 모델링, 결과해석 (각 20문항)
- 실기시험: 빅데이터 분석 실무 (수집/전처리/모형구축/모형평가)
합격 기준
- 필기시험: 전 과목 평균 60점 이상, 각 과목 40점 이상
- 실기시험: 100점 만점 중 60점 이상
필기시험
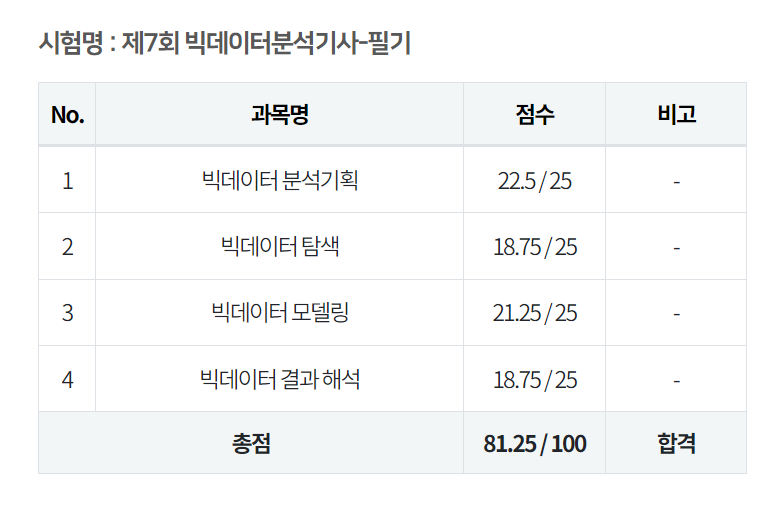
- 필기 합격후기 바로가기
https://maplambda.tistory.com/40

이기적 빅데이터분석기사 필기 참고서를 활용하였다. 그러나 이 책은 합격을 위한 책이라기보단 시험에 나올 가능성이 1%라도 존재하면 다 수록된 책인지라 합격을 원하면 이 책을 추천하지 않는다.
아래 링크 메타코드 유튜브에 빅데이터분석기사 필기 8시간 모음집이 올라오는데, 개인적으로 책 보지 말고 이 강의만 3회독 하더라도 개념과 문제가 전부 다 있기 때문에 이것만 보길 추천한다.
https://www.youtube.com/watch?v=wiPgDZU1jpE&list=PL7SDcmtbDTTw05pBC7fF_9DdDRJ2dTAU-
실기시험
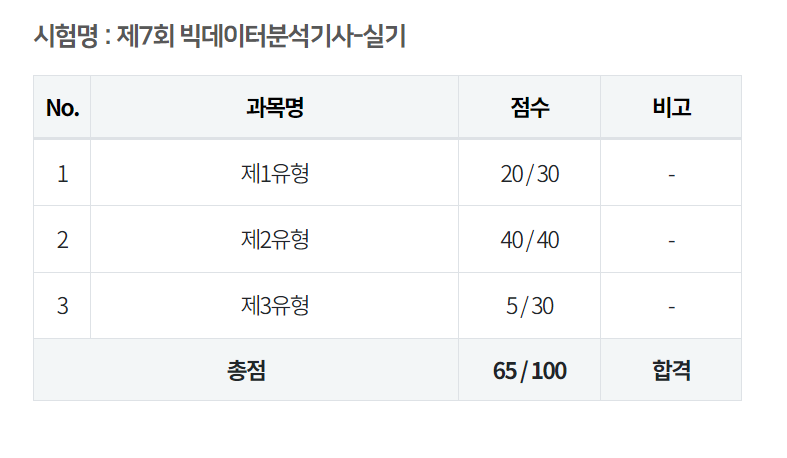
필기 시험을 응시할 때 메타코드의 도움을 정말 많이 받았다. 그래서 실기 시험은 일주일의 시간을 가지고 메타코드 실기 9시간 강의를 2회독 하는 것으로 공부를 하였다.
메타코드 강의 자체가 워낙 양질의 강의인지라 실기 역시 많은 도움을 받았지만, 필기만큼은 아니었다. 단답형 문제가 사라지고 데이터 가설검증 파트가 이번에 처음 나오는 신유형인지라 강의에서 나오는 실습문제만으론 부족했고, 오히려 이기적 책을 제외한 다른 책을 참고하여 공부하면 좋았겠다는 생각을했다.
유형
작업형 1: 데이터 수집 및 가공 (30점) - 대량의 데이터를 불러와 분석하는 역량을 평가한다.
이번 시험에선 총 1유형에서 총 3문제가 나왔고, 2문항을 풀었다. pandas를 활용하는 유형으로, 두 문제는 무난하게 나왔지만 1-2 문제는 시계열 데이터의 연관계수를 구하는 문제였고, 정말 처음 보는 유형이라 틀릴수밖에 없었다.
작업형 2: 데이터 전처리 및 모형 구축 (40점) - 시험에서 가장 큰 배점을 차지하는 부분이다.
회귀 문제가 나왔고, 랜덤포레스트 회귀식으로 풀었다. 이번 시험에선 다행히 결측치가 없었고, 오히려 이상치를 전처리하고 문제를 풀면 오히려 r2 score가 낮게 나와 이상치 처리도 안했다. 다만 약 10개의 컬럼을 하나씩 제거하면서 r2 score를 재봤는데 두개의 컬럼을 지우는 것이 최고의 r2 score 값을 나타내어 두개 컬럼을 지우고 회귀를 하였다. 제일 높게 나온게 0.84정도 나온듯하다. 그리고 test 데이터와 train 데이터를 다시 모두 합치고 새로 학습시키고 csv 파일을 제출하는 과정을 거쳤다.
그러나 주변 지인들에게 어떻게 풀었는지, 몇점 맞았는지 물어본 결과 pd.get_dummies 함수만 써 전처리를하고, RandomForest만 사용해도 모두 만점이란 결과를 받았다고하므로, 그냥 결측치가 없다면 결측치만 채워넣고 학습을 진행하자. 그래도 만점 받을 수 있는듯하다.
작업형 3: 데이터 가설검정 (30점) - 이번 시험부터 추가된 유형.
다중로지스틱 회귀 문제와 가설검정하는 문제가 나왔다. 다중로지스틱은 multi_class{‘auto’, ‘ovr’, ‘multinomial’}, default=’auto’ 파라미터가 있다는 것을 발견했고, multi_class='multinominal'을 사용했는데 statsmodel api로 다중로지스틱 회귀를 한 것과 전혀 다른 결과값이 나왔고, 고민하다가 multi_class를 쓴 것이 결과적으로 틀렸고, statsmodel을 쓰는 것은 맞았다. 그러므로 웬만하면 statsmodel을 쓰쓰도록하자.
후기
필기책을 보면서 정말 막막하다는 생각을 많이 했는데 책에 나온 지식들을 습득하며 앞으로 인공지능모델을 학습하는 것에 자신감이 붙었다. 앞으로 어떻게 모델링을 해야할지, 데이터를 어떻게 전처리를 해야할 지 어렵겠지만 배운 지식을 바탕으로 한발짝 더 증진하도록 하자.
빅데이터분석기사를 함께 공부한 모든 수험생 분들 고생하셨습니다.
