
비트와 바이트 문자인코딩 개념 정리 10분 🙆♀️ | 컴공 기본 상식 가좌아 (메가와 메비의 차이를 알고 있뉘?)
✅ 해당 영상을 보고 정리하여 작성한 내용입니다.
💻 비트와 바이트
사실 컴퓨터가 이해할 수 있는 최소의 정보 단위는 0과 1로, 컴퓨터는 0과 1의 조합으로 이루어진 정보들을 처리할 수 있다.
컴퓨터가 처리할 수 있는 가장 작은 단위의 정보를 나타내는 것을 Bit 입니다.
Bit 에는 '0' 또는 '1' 담을 수 있으며 신호가 있고 없고 불이 꺼지고 켜지고, 0과 1을 이런 정보들만 기본적으로 처리할 수 있다.
2진수 (Binary Digit)
- 1bit : 0, 1 2가지 데이터를 담을 수 있다.
- 2bits : 총 4가지를 담을 수 있다. (2x2)
- 3bits 총 8가지
- 8bits : 총 256개 다른 정보를 나타낼 수 있다.
프로그래밍에서 또는 컴퓨터에서 데이터를 처리할 때 가장 기본적인 단위를 1Byte로 얘기를 많이 하는데, 1Byte는 8Bits로 구성이 되어 있기 때문에 256개 다른 정보를 담을 수 있다.
📂 2진수와 10진수 변환
익숙한 숫자 29를 2진수로 나타내려면, 2로 나누어지지 않을 때 까지 2로 나눕니다.
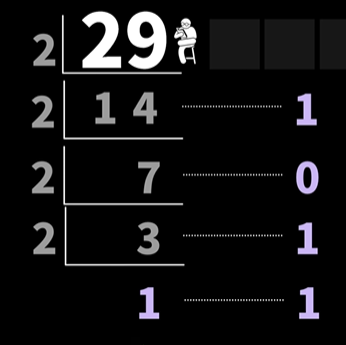
- 29를 2로 나누어 발생한 나머지 값을 연결하게되면 '11101' 2진수로 변환이 가능
2진수를 10진수로 변환 하고 싶다면?
- 각각의 비트의 위치에 가중치를 곱한 다음, 그 값을 모두 더하변 10진수로 변환이 가능
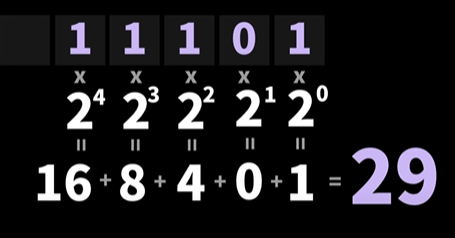
📂 문자코드
이렇게 숫자는 2진수로 변환이 되는데 그렇다면 문자는? 🤔
- 'A' > 1000001
- 'N' > 1001110
아스키 ASCII
- 아스키 문자열 코드에 들어 있는 문자열들은 1Byte로 표현이 가능하다.
- 아스키는 모든 문자열을 지원하지 않는다.(한국어 지원 X)
유니코드 Unicode
- 다양한 문자열을 포함한다.
- 유니코드에 들어있는 문자열은 1Bytes에 담을 수 없기 때문에 2Byte, 또는 그 이상의
Byte를 이용해서 전체적인 문자열을 나타낼 수 있다. - 문자열뿐만 아니라 우리가 사용하는 심볼과 이모지도 포함이 되어 있다.(한국어 지원)
👨💻 프로그래밍 언어 예제
컴퓨터는 0과 1 두 가지의 종류 중 하나만 담을 수 있는 Bit라는 가장 최소의 단위를 가지고 있고, 이 Bit를 여러 개 묶어서 더 많은 데이터를 저장할 수 있다.
컴퓨터 프로그래밍에서는 1Byte 를 가장 최소의 단위로 잡고 본다.
Bit와 Byte에 대해서 잘 이해하는 것이 왜 중요할까? 🤔
프로그래밍에서 변수를 선언할 때 어떤 데이터 타입이냐에 따라서 메모리에 얼마나 크게 공간이 확보되는 지가 정해진다. C, GO, Rust, 임베디드나 메모리가 넉넉하지 않은 환경에서 동작하는 프로그램이 같은 경우에는 이런 데이터 타입을 알맞게 선택해서 효율적으로 작성하는 것이 중요하다.
ex) 1과 같이 한자리 숫자를 담는 경우 2Byte, 4Byte 타입의 변수를 사용하면 메모리 낭비
언어 별 데이터 타입 크기 및 기억 범위
https://naminal.tistory.com/130
프로그래밍 언어도 제각기 어디에 쓰이느냐에 따라서 다양한 데이터 타입이 세분화되어 있다.
🎥 메가와 메비의 차이
1Byte 이상 영상을 주고받을 때 쓰는 사이즈에 대해서 알아보자

-
2진수 단위로 곱해진 사이즈는 운영체제에서 우리가 사이즈를 확인할 때 볼 수 있다.
-
사람들한테 조금 더 익숙한 10진수 단위로 곱해진 사이즈들은 외장 디스크나 유에스비에 표현된 사이즈는 주로 10진수 단위로 곱해진 것을 말한다.
10진수 단위의 1000Byte와 2진수 단위의 1024Byte와 같은 차이 등과 같이 데이터의 표기 차이로 USB의 사용 메모리에 혼돈이 있었다.
- 1998년 IEC 단체에서 다른 표기법을 제안

📋 문자인코딩 (Text Encoding)
우리가 어떻게 현존하는 많은 문자열들을 바이너리 형태로 나타낼 건지 규격을 약속하는 것을 문자 인코딩이라고 합니다.
예전에는 나라마다 다양한 텍스트 인코딩이 존재하였는데, 서로 다른 인코딩 규격 때문에 웹사이트가 깨지거나 한글 문서가 읽어지지 않는 문제점들이 많이 발생했다.
UTF-8 (Universal Coded Character Set + Transformation Format – 8-bit)
-
켄 톰프슨과 롭 파이크(GO언어 창시) 개발
-
기존의 아스키뿐만 아니라 모든 유니코드들을 나타낼 수 있는 웹사이트에서도 기본적으로 사용되고 있고, 통상적으로 많이 사용되고 있는 텍스트 인코딩
-
가변길이 유니코드 인코딩 방식
길이가 정해져 있지 않고 필요에 의해서 길이가 길어질 수 있다.
ex) 모든 아스키 코드는 7bit로 나타낼 수 있기 때문에 UTF-8에서 1bit 표현 할 수 있다
ex) 유니코드 같은 경우는 최소 2byte 부터 4byte트 까지 표현할 수 있다.
가변길이기 때문에 바이트가 더 필요하다면 데이터의 범위를 더 늘려서 더 많은 문자열을 나타낼 수 있다.
UTF-16(16-bit Unicode Transformation Format)
- 기본적으로 2바이트를 사용
- 아스키와 같이 1바이트로만 충분히 표현할 수 있음에도 충분하고 2바이트를 소모하기 때문에 UTF-8가 통상적으로 더 많이 이용되고 있다.
