3. 구직정보 취합
3.1 CSV 파일 생성
import csv # 3.1.1
def save_to_file(jobs):
file = open("jobs.csv", mode="w") # 3.1.2
writer = csv.writer(file) # 3.1.3
writer.writerow(["title", "company", "location", "link"]) # 3.1.4
for job in jobs:
writer.writerow(list(job.values())) # 3.1.5
return3.1.1 CSV(comma-separated values)는 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일
3.1.2 쓰기 파일 생성
3.1.3 csv를 'file'파일에 작성
3.1.4 첫 줄에 작성할 내용
3.1.5 key값을 제외한 value값만 가져옴
3.2 main 파일에 취합
from indeed import get_jobs as get_indeed_jobs # 3.2.1
from so import get_jobs as get_so_jobs # 3.2.2
from save import save_to_file # 3.2.3
so_jobs = get_so_jobs()
indeed_jobs = get_indeed_jobs()
jobs = so_jobs + indeed_jobs
save_to_file(jobs)3.2.1. indeed 사이트 구직정보 추출 파일(indeed.py)에서 get_jobs() 불러옴
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs3.2.2. Stack Overflow 사이트 구직정보 추출 파일(so.py)에서 get_jobs() 불러옴
def get_jobs():
last_page = get_last_page()
jobs = extract_jobs(last_page)
return jobs3.1.3. csv 생성 파일(save.py)에서 save_to_file(jobs) 불러옴
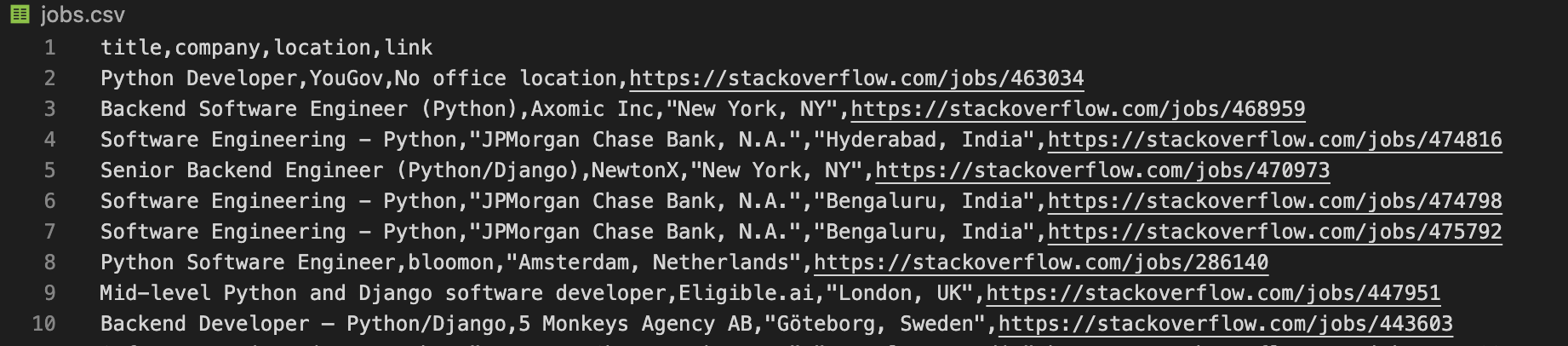
3.3 결과
메인파일을 실행하면 두 사이트에서 불러온 구직정보가 해당 폴더에 jobs.csv 파일로 생성되고 이는 excel을 통해 열람할 수 있다.