개인 프로젝트하는데 FireStore 어떻게 쓰지?
간편한 사용성과 강력한 쿼리 기능 등으로 개인 프로젝트에서 Firebase의 FireStore가 많이 사용되는데, FireStore을 어떻게, 잘 Android 프로젝트에 적용해야하나 고민을 했다.
텃텃에 적용하며 느낀점은,
-
FireStore 이해하기 -
서비스에 따라
FireStore 구조 잡기 -
CRUD 방법잘 이해하기
세 가지면 FireStore을 프로젝트에 잘 적용할 수 있다.
기본적인 세팅 방법은 FireStore 공식 문서에 잘 나와있으니 적용해보면 좋을 것 같다.
FireStore 이해하기
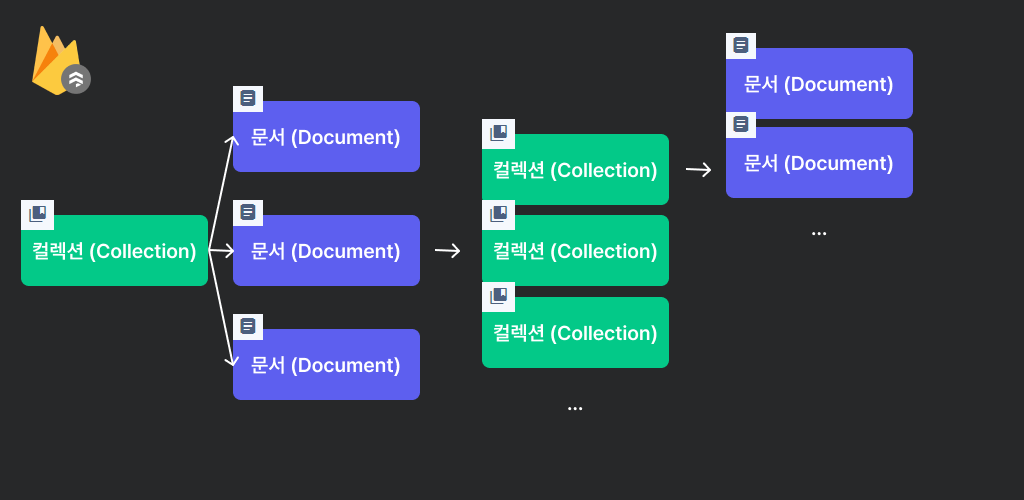 FireStore의 기본적인 구조는
FireStore의 기본적인 구조는 컬렉션 (Collection)과 문서 (Documment)의 집합체이다.
컬렉션은 문서의 집합이고, 문서에만 데이터를 저장할 수 있다.
FireStore를 처음 시작하면 컬렉션 시작이란 버튼을 볼 수 있는데, 첫 노드가 컬렉션이기 때문이다. 그래서 CRUD는 필요한 문서에 도달할 때까지, 이 컬렉션과 문서를 따라가면 된다.
예를 들어, User와 Post 그리고 각 Post에 해당하는 Comment를 저장할 것이다.
-
User 컬렉션: 최상위 컬렉션에
users란 컬렉션을 만들고, 하위 문서(Document)에 User 데이터를 저장하여 관리 -
Post 컬렉션: 최상위 컬렉션에
posts란 컬렉션을 만들고, 하위 문서(Document)에 Post 데이터를 저장하여 관리 -
Comment 컬렉션: A란 Post 문서 하위에
comments란 컬렉션을 만들고, 하위 문서(Document)에 Comment 데이터를 저장하여 관리
그러면 이런 의문이 들 수 있다.
각 Post 문서(Document)에 CommentList를 두면 안되나?
사실 이 방법도 맞다.
Post와 Comment 데이터를 Post 문서에 모두 포함하든, 하위 컬렉션에서 관리하든, Comment도 최상위 컬렉션에서 관리하든 정답은 없다.

 하지만 각 문서 (Document)에는 최대 크기가 있다.
하지만 각 문서 (Document)에는 최대 크기가 있다.
그래서 Comments 데이터의 사이즈에 1MiB가 충분하다면 Post 문서에 모두 포함하는게 적합할 것이고,
1MiB가 부족하다면 Comments 하위 컬렉션을 두는 것이 적합할 것이다.
하위 컬렉션의 크기는 상위 문서 크기에 포함되지 않기 때문이다.
FireStore의 구조를 이해했다면, 필요한 서비스에 적합한 데이터 구조를 선택해보자
텃텃의 FireBase 구조
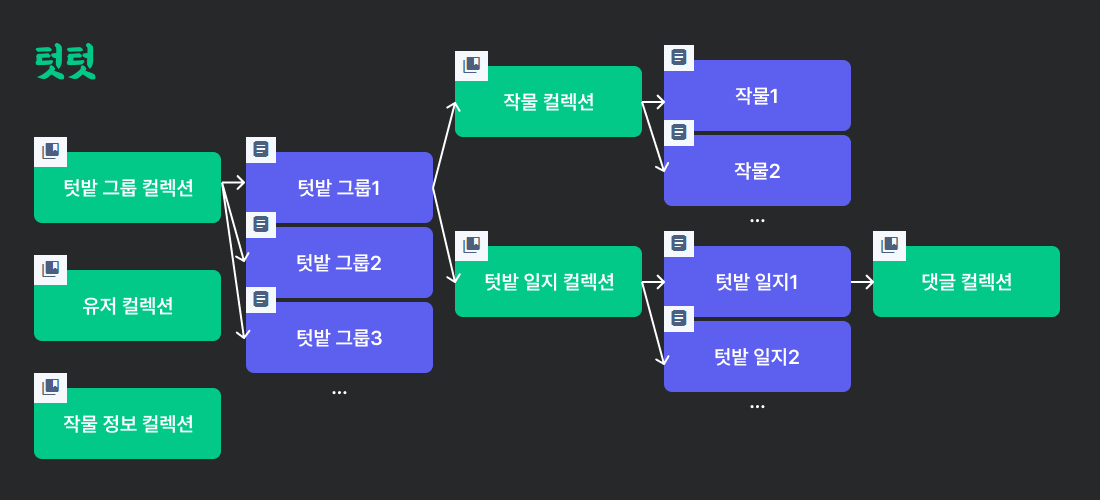
텃텃은 그룹 기반 텃밭 생활 서비스이다.
작물 정보 컬렉션은 개발자(나)가 제공하는 작물 정보로 모든 유저가 사용하므로 최상위 컬렉션에 위치한다.
유저 컬렉션을 최상위 컬렉션에 둔 이유?
텃텃을 사용하려면, 그룹에 참여해야한다. 가입은 했지만 아직 그룹에 참여하지 않은 경우를 생각해 최상위 컬렉션에 두었다.
대신, 각 그룹에 속한 UserId를 저장해두었다. 서비스 진입 시점에 해당 UserId를 바탕으로 그룹 멤버 정보를 캐싱하므로, 유저 정보가 변경된 경우에도 대응할 수 있다는 장점이 있다.
텃밭 일지 컬렉션을 작물 컬렉션 하위에 두지 않은 이유?
텃밭 일지는 각 작물에 대해 작성할 수 있다.
이 경우, 텃밭 일지 컬렉션을 작물 컬렉션 하위에 두는 것이 더 적합하다.
기획 때, 해당 텃밭 그룹의 모든 텃밭 일지를 한 번에 모아주는 기능을 다음 업데이트에 하기로 결정했기 때문에 두 컬렉션을 나누었다.
대신, 각 텃밭 일지 문서(Document)에는 작물Id가 포함되어 whereEqualTo 쿼리를 사용하여 각 작물에 해당하는 텃밭 일지를 불러오고 있다.
댓글 컬렉션을 따로 분리한 이유?
댓글에 경우 200자까지 입력할 수 있다.
그래서 댓글의 양이 많아진다면, 한도량인 1MiB가 넘을 수 있다고 판단하여 댓글 컬렉션을 따로 분리했다.
FireStore 구조를 정하기 전에, 서비스 확장됐을때나 한도량을 생각하며 정하는 것을 추천한다.
유저가 사용 중일때 구조를 바꾸는 것은 쉽지 않아 보이기 때문에..
CRUD 방법 잘 이해하기
먼저 필요한 문서를 찾아야 CRUD를 할 수 있다.
필요한 문서에 접근하는 방법은
Firebase.firestore.collection("컬렉션 이름").document("문서 이름")FireStore의 최상위 노드는 컬렉션이기 때문에, 항상 collection()부터 시작한다.
FireStore 접근 방법은 두 가지로 나뉜다.
-
collection()으로 끝남: CollectionReference를 반환 -
document()로 끝남: DocumentReference를 반환
READ 읽기
두 가지 방법으로 데이터를 읽을 수 있다.
-
get(): 데이터를 한 번만 가져온다. -
addSnapShotListener(): 실시간 업데이트 수신을 대기한다.
두 가지 방법 모두 CollectionReference에 대해 실행한다면 List<SnapShot>을, DocumentReference에 대해 실행한다면 SnapShot를 반환한다.
반환된 SnapShot에 대해 toObject(데이터 타입)으로 사용하는 DTO로 쉽게 변환할 수 있다. 다만, 해당 DTO에 한 가지 규칙이 필요하다.
DTO의 각 field는 기본값을 가져야 한다.
data class User(
val id: String = "",
val gardenId: String = "",
val name: String = "",
val profile: StorageImage = StorageImage(),
)텃텃의 User DTO이다. 각 field는 기본값을 갖는데, profile처럼 Primitive Type이 아닌 경우는 어떻게 할까?
data class StorageImage(
val url: String = "",
val name: String = ""
) {
constructor() : this("", "")
}이런 식으로 constructor()를 따로 명시해야 한다.
toObject(데이터타입)은 SnapShot을 deSerialized 시킬 때, 기본값이 필요하기 때문이다.
참고
-
List타입은
emptyList()로 설정해주면 된다. -
Boolean field명이
is로 시작할 경우,@field:JvmField어노테이션을 붙여준다.
CREATE 생성
데이터 추가는 CollectionReferecne에 대해서 add() 또는 DocumentReference에 대해서 set()을 통해 할 수 있다.
-
add(): 문서에 유의미한 Id를 두지 않을 경우 -
set(): 문서에 Id를 둘 경우
만일, 새로운 유저를 추가할 때는 이렇게 할 수 있다.
Firebase.firestore.collection("유저 컬렉션 이름").document("문서 이름").set(User())그런데 아직 추가하지 않은 User의 문서 이름은 어떻게 아는걸까?
CollectionReference에서 새로운 문서Id를 얻을 수 있다.
val userCollection = Firebase.firestore.collection("유저 컬렉션 이름")
val documentId = userCollection.document().id
userCollection.document(documentId).set(User.copy(id=documentId))이렇게 문서 Id를 얻어 User와 함께 저장하면, RUD에 더 편리하다.
UPDATE 업데이트
데이터 업데이트는 DocumentReference에 대해 update()를 사용한다.
만일 User와 같이 커스텀 객체를 업데이트하려면, Map<String, Any?>형식이 필요하다.
예를 들어, User의 이름을 업데이트 하려고 한다.
Firebase.firestore.collection("유저 컬렉션 이름").document(userId).update(mapOf("name" to typedName))"field 명 to 실제 값" 형식으로 넣어준다.
텃텃에선 User는 name과 profile만 변경 가능해서 다음과 같이 User 확장함수를 만들어 사용한다.
fun User.toMap(): Map<String, Any?> = hashMapOf(
"name" to name,
"profile" to profile
)참고
- 배열 요소 업데이트
// regions 배열에 "greater_virginia" 추가
washingtonRef.update("regions", FieldValue.arrayUnion("greater_virginia"))
// regions 배열에 "east_coast" 제거
washingtonRef.update("regions", FieldValue.arrayRemove("east_coast"))- 숫자 값 늘리기
// population field "50" 늘리기, 줄이고 싶다면 그대로 "-50" 사용
washingtonRef.update("population", FieldValue.increment(50))DELETE 삭제
데이터를 삭제하려면, DocumentReference에 대해 delete()로 할 수 있다.
물론 CollectionReference에 대한 delete()도 가능하지만, 권장되지 않는다.
심지어 컬렉션이 삭제돼도 하위 문서와 컬렉션은 남아있게 된다. 그래서 컬렉션의 모든 요소를 삭제하려면 각각의 하위 문서와 컬렉션에 대한 삭제가 필요하다. 그리고 모든 요청은 사용량을 늘리고, 삭제하는 데이터가 많으면 요금 폭탄을 맞을 수도 있다.
 이럴 때마다 정말 백엔드의 존재가 간절해진다..
이럴 때마다 정말 백엔드의 존재가 간절해진다..
일괄 트랜잭션 및 일괄 쓰기
한 번에 여러 개의 작업을 하고 싶은 경우 다음을 이용한다.
-
일괄 트랜잭션: 여러 개의get()작업과 이어서 수행되는set(), update(), delete()등의 여러 쓰기 작업으로 구성,runTransaction사용 -
일괄 쓰기: 문서를 읽을 필요가 없는 경우set(), update() 또는 delete()작업의 조합을 포함하는 단일 배치로 여러 쓰기 작업을 실행,runBatch사용
한 마디로 여러 작업을 한 번에 수행하고 싶은데, 읽기 작업이 선행되면 runTransaction을, 읽기 작업이 없다면 runBatch를 사용한다.
일괄 트랜잭션
 다음은 FireStore 문서 예시이다.
다음은 FireStore 문서 예시이다.
val sfDocRef = db.collection("cities").document("SF")
db.runTransaction { transaction ->
val snapshot = transaction.get(sfDocRef)
val newPopulation = snapshot.getDouble("population")!! + 1
transaction.update(sfDocRef, "population", newPopulation)
// Success
null
}.addOnSuccessListener { Log.d(TAG, "Transaction success!") }
.addOnFailureListener { e -> Log.w(TAG, "Transaction failure.", e) }일괄 쓰기
다음은 텃텃의 로직이다.
val ref = gardensRef.document(gardenId)
val userRef = usersRef.document(userId)
Firebase.firestore.runBatch { batch ->
batch.update(ref, FireBaseKey.GARDEN_GROUP_ID, FieldValue.arrayUnion(userId))
batch.update(userRef, FireBaseKey.USER_GARDEN_ID, gardenId)
}.await()텃밭 그룹의 멤버 아이디 리스트에 해당 userId를 추가하면서,
유저의 텃밭 아이디를 해당 텃밭 그룹Id로 업데이트하고 있다.
마치며
Android에서 FireStore을 사용할 때, 직접 적용하며 이해한 바를 기록해봤다.
FireStore는 사용성, 쿼리 기능 등으로 개인 프로젝트할 때 정말 유용한 툴이다.
서비스에 맞는 구조를 잡고 적절하게 CRUD 할 줄 안다면, 데이터 전송 속도가 꽤 준수한 앱을 만들 수 있을 것이다. 백엔드 팀원과 함께하면 더 빠르겠지만..
다음 FireStore 관련 포스팅은 클린 아키텍처 + Hilt 개발 환경에서 어떻게 FireStore를 적용할 지 다뤄보겠다.
