S3
S3 이론
S3란?
Simple Storage Service. 인터넷용 스토리지 서비스
인피니티 스토리지라고도 부름.
인터넷 스토리지이기 때문에 s3에 저장한 데이터는 언제 어디에서나 접근 가능
많은 양의 데이터를 저장하고 검색할 수 있음
s3 버킷의 이름은 유일한 이름이여야함
service level agreement : 서비스와 고객간의 약속
아마존 s3 sla는 99.99999% 내구성을 제공하도록 설계되어있음 ( 한번 저장된 데이터는 거의 유실되지 않음 )
S3의 장점
-
빠른 속도, 높은 확장성, 신뢰성
-
버킷 만들기 : 데이터를 저장하는 버킷을 만들고 해당 버킷의 이름을 지정.
: 버킷은 데이터 스토리지를 위한 아마존 s3의 기본 컨테이너 -
데이터 저장 : 버킷에 데이터를 무한정으로 저장함.
: 객체를 원하는 만큼 업로드 가능하며, 각 객체에 최대 5TB 데이터 포함 가능
: 각 객체는 고유한 개발자 할당 키를 사용하여 저장 및 검색 -
데이터 다운로드 : 데이터를 직접 다운로드하거나 다른 사람이 다운로드할 수 있도록 함.
-
권한 : 데이터를 Amazon S3 버킷으로 업로드 또는 다운로드하려는 사용자에게 액세스 권한을 부여하거나 해당 권한을 거부할 수 있음. 3가지 유형의 사용자에게 업로드 및 다운로드 권한을 부여할 수 있음.
인증 메커니즘을 사용하면 데이터가 무단으로 액세스되지 않도록 보호하는 데 도움이 될 수 있습니다. -
표준 인터페이스 : 모든 인터넷 개발 도구 키트에서 사용할 수 있도록 설계된 표준 기반 REST 및 SOAP 인터페이스를 사용합니다
S3 주요 개념
버킷
- 아마존 s3에 저장된 객체에 대한 컨테이너
- 모든 객체는 어떤 버킷에 포함됨
- url를 사용해서 주소를 지정할 수 있음
- 예시 ) https://awsexamplebucket1.s3.us-west-2.amazonaws.com/photos/puppy.jpg => /photos/puppy.jpg 객체는 us-west-2 리전에 위치한 awsexamplebucket1 버킷에 저장됨
- 리전 종속적
- s3의 이름은 고유해야함
- 사용 용도
1. Amazon S3 네임스페이스를 최상위 수준으로 구성함
2. 스토리지 및 데이터 전송 요금을 담당하는 계정을 식별함
3. 액세스 제어에 사용됨
4. 사용량 보고를 위한 집계 단위로 사용됨
객체
- Amazon S3에 저장되는 기본 개체
- 객체 = 객체 데이터 + 메타 데이터
- 메타 데이터 : 객체를 설명하는 이름 - 값 페어의 집합 , 마지막으로 수정한 날짜 , 등이 표준 http 메타데이터가 포함됨
- 객체는 키 및 버전 ID를 통해 버킷 내에서 고유하게 식별됨키
- 버킷 내의 고유한 식별자
- 버킷 + 키 + 버전 (선택사항 )으오 고유하게 주소 지정 가능Regions
- S3에서 사용자가 만드는 버킷을 저장할 지리적 AWS 리전 선택가능
- 리전 선택 시 고려 사항 : 지연 시간 최적화 / 비용 최소화 / 규정 요구 사항 준수
- 특정 리전에 저장된 객체는 해당 리전 벗어나지 X
- 여러 버킷을 여러 리전에 만들고 싱크할 수 있는 기S3 스토리지 클래스
1. 자주 액세스하는 객체를 위한 스토리지 클래스
1-a. S3 standard : 디폴트 스토리지 클래스
1-b. Reduced Redundancy : s3 standard storage class 보다 더 적은 죽복성으로 저장될 수 있음.
: 중요↓ , 재현 가능한 데이터 용으로 설계됨
2. 자주 액세스하는 객체와 자주 액세스하지 않는 객체를 자동으로 최적화하는 스토리지 클래스
S3 Intelligent-Tiering
: 성능 영향 또는 운영 오버헤드 없이 가장 비용 효율적인 스토리지 액세스 계층으로 데이터를 자동으로 이동하여 ㅅ토리지 비용을 최적화하도록 설계뙴
: 두 액세스 계층에 객체를 저장 ( 자주 액세스하는 데이터에 최적화된 계층 / 자주 액세스하지 않는 데이터에 최적화된 비용이 저렴함 계층 )
: 객체당 소액의 월별 모니터링 및 자동화 요금으로 S3 Intelligent-Tiering 스토리지 클래스에서 객체의 액세스 패턴을 모니터링하고 연속 30일 동안 액세스하지 않은 객체를 자주 액세스하지 않는 액세스 계층으로 이동
: 검색 요금 X, 계층 간 이동 요금 X
3. 자주 액세스하지 않는 객체를 위한 스토리지 클래스
: 수명이 길고 자주 액세스하지 않는 데이터용으로 설계됨
: 백업을 저장하는 경우
3-a. S3 Standard-IA
3-b. S3 One Zone-IA
4. 객체 아카이빙을 위한 스토리지 클래스
4-a. s3 glacier
4-b. s3 glacier deep archiveGlacier
저비용 데이터 아카이빙을 위해 설계됨
S3 standard storage class와 동일한 내구성과 복원성 제공
S3 Clacier
- 분 단위로 데이터의 일부를 검색해야하는 아카이브에 사용
- 최소 스토리지 기간 90일 ( 최소기간 이전에 삭제/덮어쓰기/다른 스토리지 클래스로 이전 -> 90일 요금 부과됨 )
0 신속 검색 사용 -> 1~5분 이내에 액세스 가능
S3 Glacier Deep Archive
- 거의 액세스할 필요 없는 데이터 보관할 때 사용
- 최소 스토리지 기간 180일
- 기본 검색시간 12시간
- 가장 저렴한 스토리지 옵션
S3 실습
S3 생성하기
-
provider.tf 생성
provider "aws" { region = "ap-northeast-2" } -
s3.tf 생성
resource "aws_s3_bucket" "s3" { bucket = "devoposart-terraform-101-eunyoung" tags = { Name = "devopsart-terraform101" } } -
terraform init
-
terraform plan
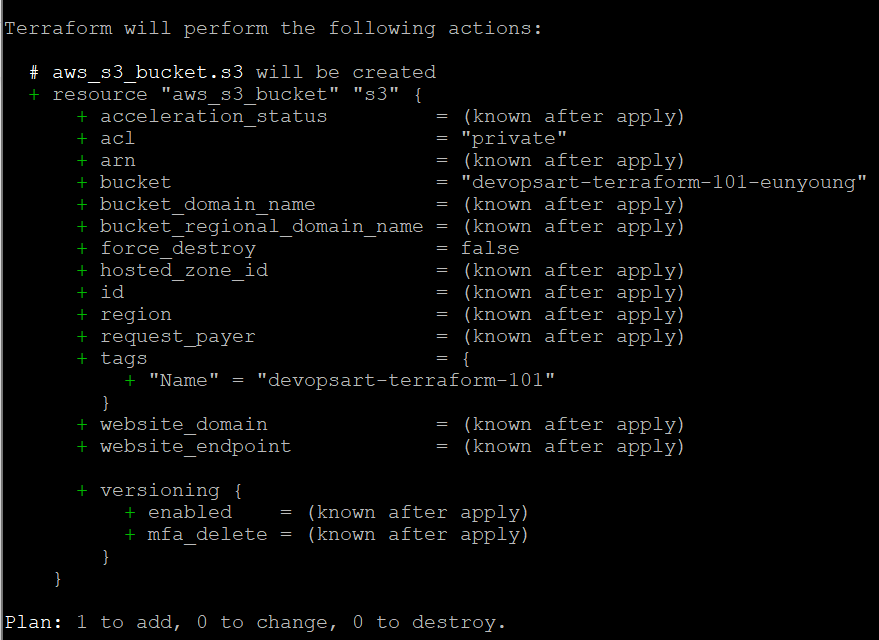
-
terraform apply
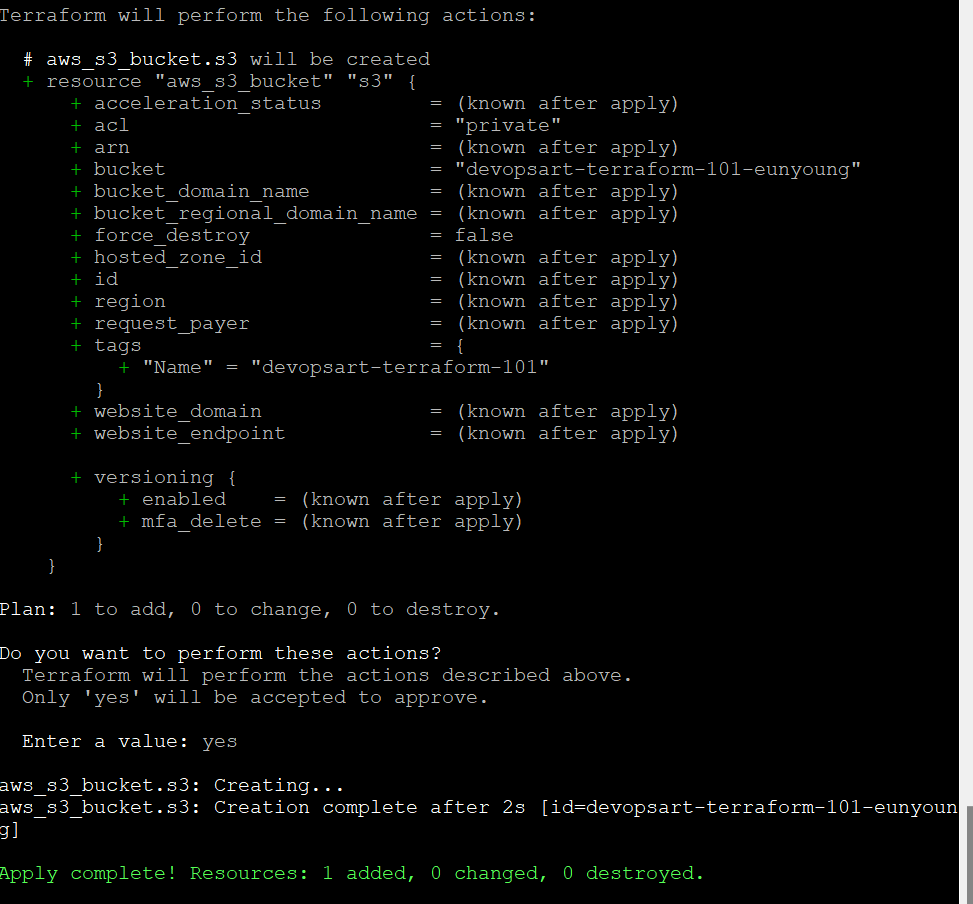
-
aws 콘솔에서 s3 잘 만들어졌는지 확인
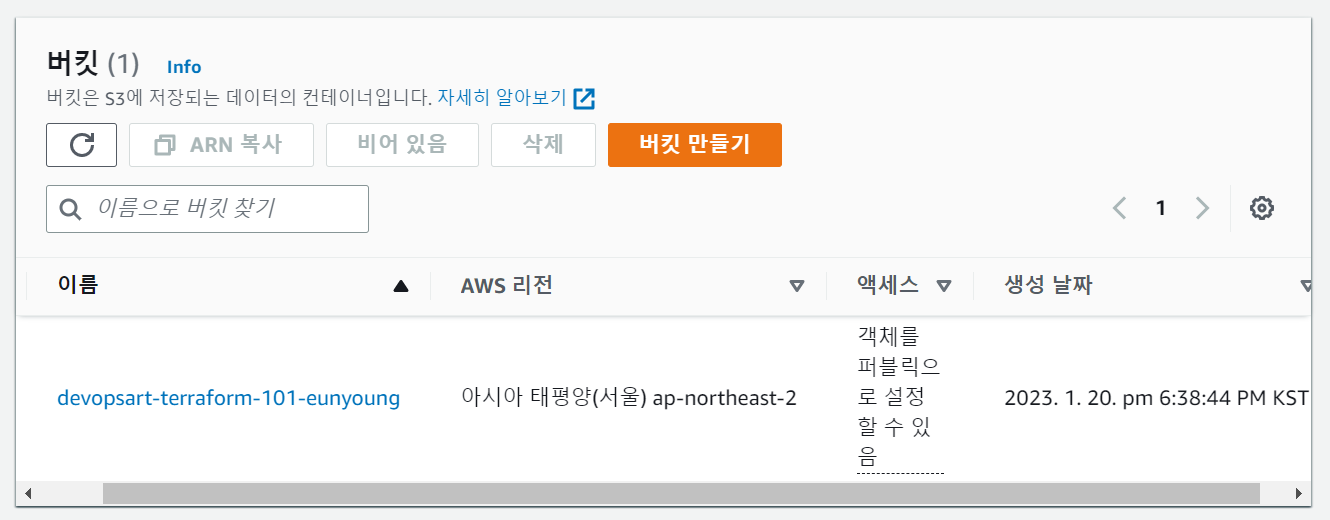
s3의 기능 확인하기
-
aws s3 help : s3를 활용하여 사용할 수 있는 다양한 명령어 확인 가능
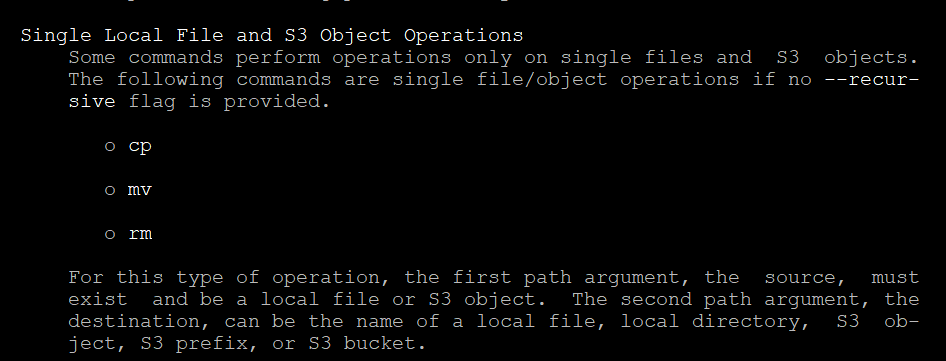
-
s3에 파일 업로드하기
1.vim index.html파일 생성
2.s3 cd 업로드할파일명 s3://bucket이름/url지정
s3 cd index.html s3://devopsart-terraform-101-eunyoung/
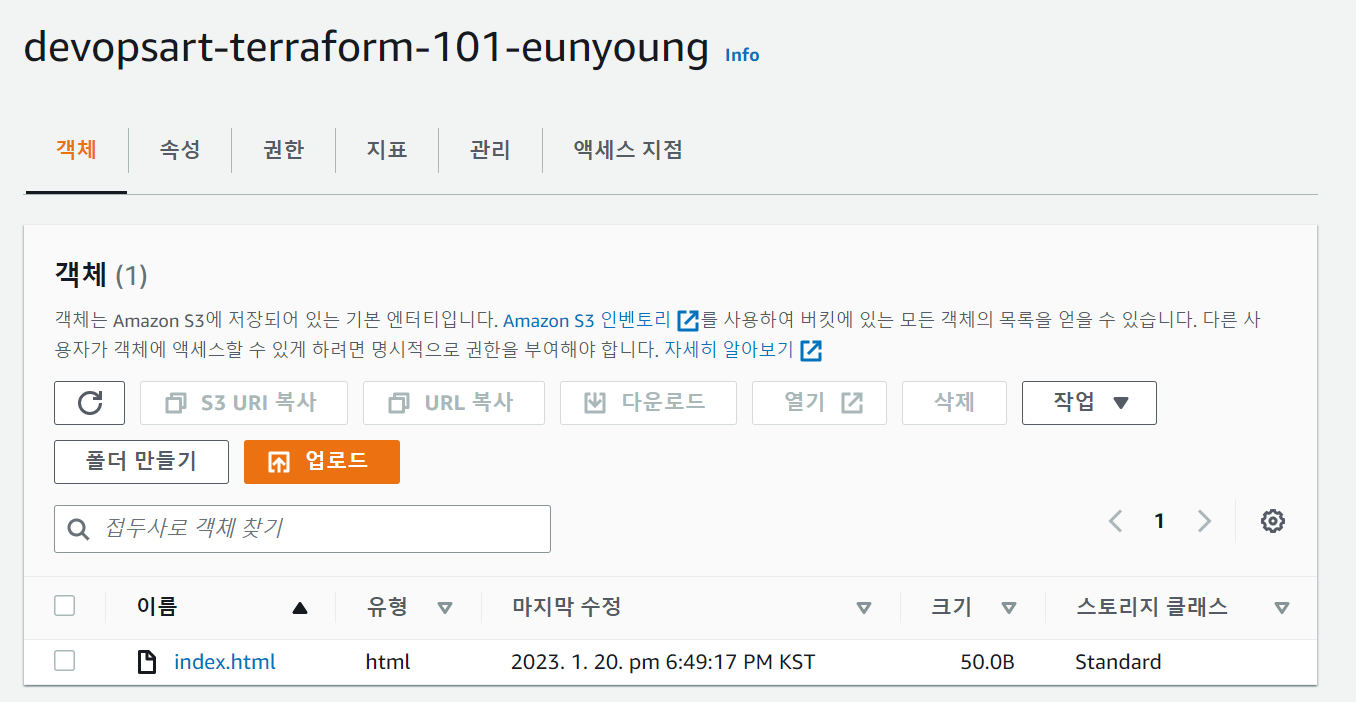
-
s3에 있는 파일 ec2 인스턴스에 다운받기
- 권한이 있어야만 다운받을 수 있음
1. touch testfile 파일 생성
2. vim testfile 파일 내용 추가
3. 파일 s3 버킷에 업로드
예시 코드 )s3 cd testfile s3://devopsart-terraform-101-eunyount/path/
4. ec2 서버에서 testfile 삭제 rm -rf testfile
5.se cp [ 파일이 버킷에 저장된url ] [ 저장할 위치 ]
예시 코드 ) s3 cp s3://devopsart-terraform-101-eunyount/path/testfile .
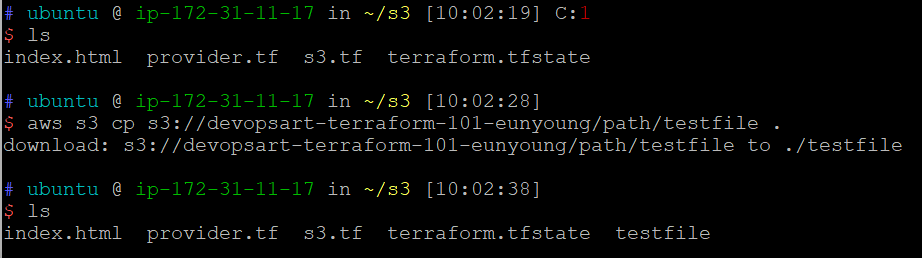
-
s3에 업로드한 객체에 권한 부여하기
- 객체 url을 그냥 브라우저 창에 입력햇을 시 Access Denied 뜸

- 권한 부여하는 방법
1. 허용(Permission) 룰에 추가하기
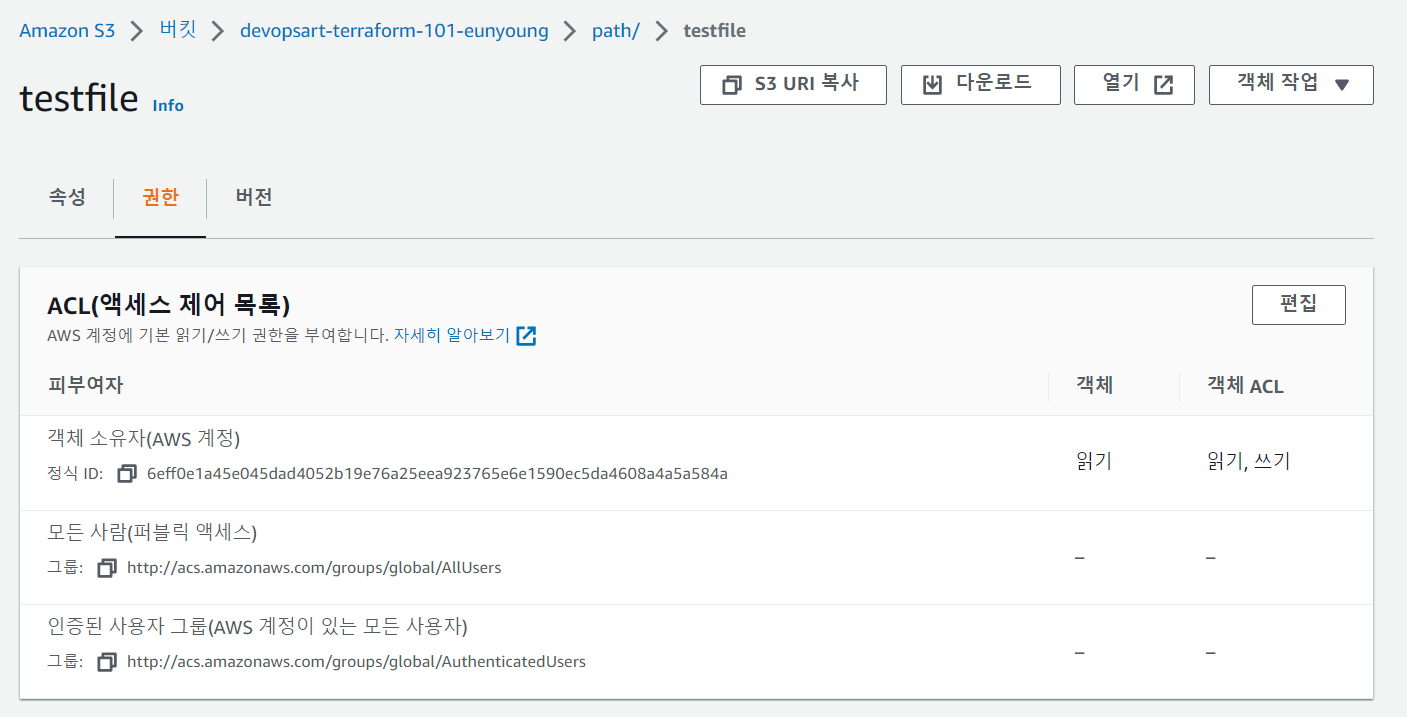
- 작업 눌러서 public으로 만들기 누르기
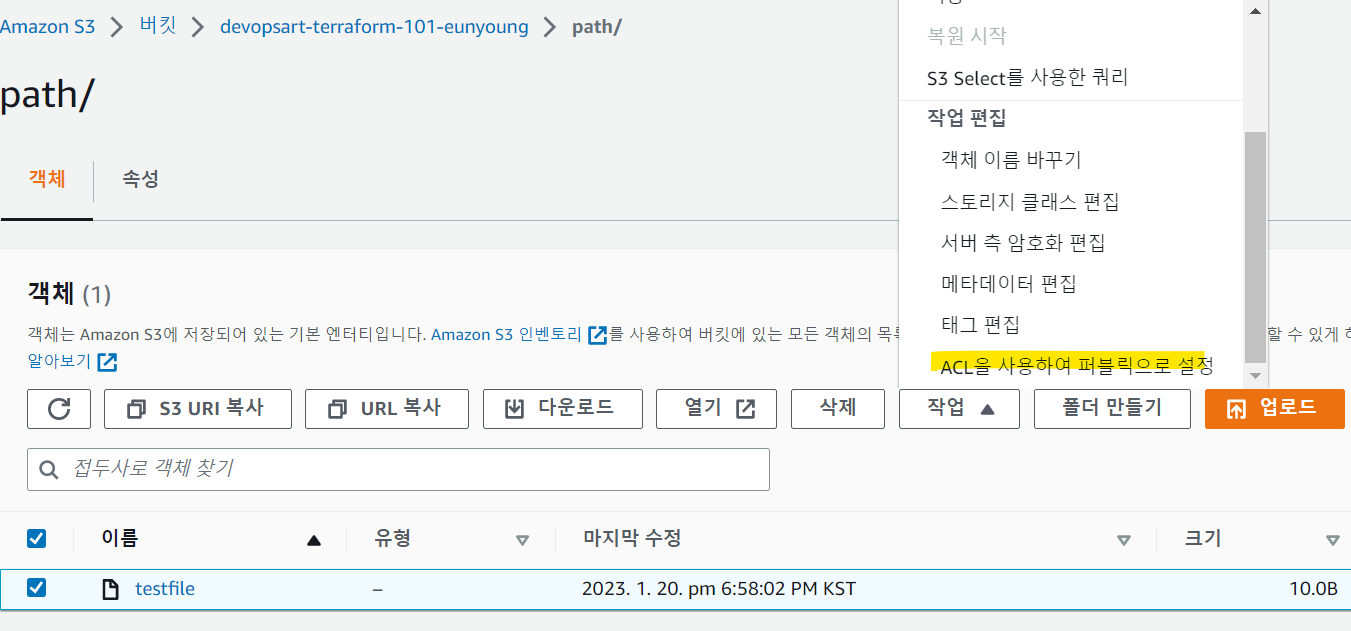
=> 권한 모든 사람에게 부여했을 시 url로 파일 볼 수 있음

현업에서는 권한별로 버킷을 분리하는 방식으로 관리
- S3를 웹사이트처럼 이용하기
- 버킷 -> properties ->정적 웹 사이트 호스팅

