📌 ElasticSearch
Apache Lucene(아파치 루씬) 기반의 Java 오픈 소스 분산 검색 엔진이다. ElasticSearch를 통해 루씬 라이브러리를 단독으로 사용할 수 있으며, 방대한 양의 데이터를 신속하게 저장, 검색, 분석을 할 수 있다.
ELK(Elasticsearch / Logstash / Kibana) 스택으로 사용되기도 한다. ELK 스택은 다음과 같다.
- Logstash
- 다양한 소스(DB, csv 파일 등)의 로그 또는 트랜잭션 데이터를 수집, 집계, 파싱하여 Elasticsearch로 전달 - Elasticsearch
- Logstash로부터 받은 데이터를 검색 및 집계하여 필요한 정보를 획득 - Kibana
- Elasticsearch의 빠른 검색을 통해 데이터를 시각화 및 모니터링
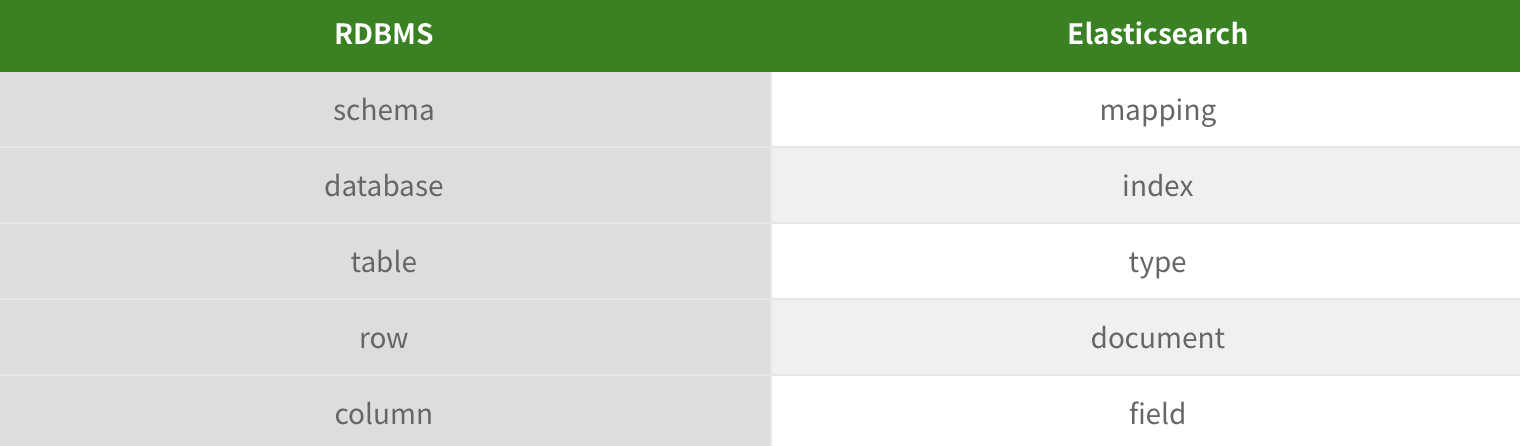
📌 ElasticSearch VS RDBMS
📌 ElasticSearch 핵심 개념
Document
Elasticsearch에서 데이터의 최소 단위이다. RDBMS에서의 row와 비슷하다. Document는 JSON 객체이며, 다양한 필드를 포함하고, document안에 document가 필드로 존재할 수 있다.
Field
Document안에 들어가는 데이터이다. RDBMS에서의 column과 비슷하다.
Type
여러 document가 모여서 하나의 type을 이룬다. RDBMS에서의 table과 비슷하다. Elasticsearch 6.1 부터는 하나의 index(여러 type이 모인 것)당 하나의 type만을 가질수 있게 되었고, 7.0 부터는 type이 사라지고 대신 고정자 _doc 으로 접근해야 한다
Index
데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들로 변환(indexing)하여 저장한 것. 여러 type이 모여 한 개의 index를 이룬다. RDBMS에서의 database와 table의 역할을 한다. RDBMS에서는 여러 database의 데이터를 한번에 조회할 수 없지만 Elasticsearch에서는 가능하다 (multitenancy). index는 shard라는 단위로 분산되어 저장된다. Lucene에서 index 파일들은 immutable(불변)하다. Update 시에는 내부적으로 수정될 document를 삭제후 다시 insert한다. 따라서 수정이 잦은 문서를 elasticsearch에 저장하는 것은 비효율적이다.
Shard
Index가 분산되어 처리되는 단위를 뜻한다. 각 shard는 물리적 노드들에 나뉘어서 저장된다. Shard는 두 종류로 나뉜다.
- Primary shard: 모든 document들은 하나의 primary shard에 저장된다. Primary shard의 기본 개수는 5개이다.
- Replica shard: Primary shard의 복제본이다. 원본 데이터에 fault 발생시 복구하기 위해 사용된다 (fault tolerance). Replica shard의 기본 개수는 1개이다.Segment
Segment는 shard가 물리적으로 나뉘어서 저장되는 단위이다. Document가 처음부터 segment에 저장되는 것은 아니다. Indexing된 document는 먼저 시스템의 메모리 버퍼에 저장되고, 이 때는 document가 검색되지 않는다. Elasticsearch의 refreash 과정을 거쳐야 segment 단위로 physically 저장되고 검색이 된다. Segment는 immutable 하며 document가 update 되면 새로운 segment가 생성된다. Segment가 많아질수록 search 할 때 성능이 낮아질 수 있다. 따라서 Elasticsearch 내부에서 background로 segment merging을 진행한다.
Mapping
Elasticsearch의 index에 들어가는 데이터의 type을 정의하는 것이다. RDBMS에서의 schema와 유사하다. Elasticsearch는 선 indexing 후 mapping을 지원하며, 새로운 필드가 추가되면 동적으로 해당 필드 indexing 후 mapping까지 해준다.
📌 Elasticsearch 이점
신속한 가치 실현
Elasticsearch는 간단한 REST 기반 API, 간단한 HTTP 인터페이스를 제공하고 스키마 없는 JSON 문서를 사용해 다양한 사용 사례에서 쉽게 시작하고 빠르게 애플리케이션을 구축할 수 있습니다.
고성능
Elasticsearch의 분산 성질로 인해 대량 볼륨의 데이터를 병렬로 처리할 수 있어 쿼리에 최고의 일치 항목을 빠르게 찾을 수 있습니다.
무료 도구 및 플러그인
Elasticsearch는 유명 시각화 및 보고서 도구인 Kibana가 통합되어 제공됩니다. Beats 및 Logstash와의 통합도 제공하여 소스 데이터를 쉽게 전환하고 Elasticsearch 클러스터에 로드할 수 있습니다. 언어 분석기 및 제안자 등 다양한 오픈 소스 Elasticsearch 플러그인을 사용하여 애플리케이션에 풍부한 기능을 추가할 수도 있습니다.
실시간에 가까운 운영
데이터 읽기 및 쓰기와 같은 Elasticsearch 운영은 보통 1초도 안 걸려서 완료됩니다. 덕분에 애플리케이션 모니터링 및 이상 탐지와 같은 실시간에 가까운 사용 사례에 Elasticsearch를 사용할 수 잇습니다.
쉬운 애플리케이션 개발
Elasticsearch는 Java, Python, PHP, JavaScript, Node.js, Ruby 및 기타 여러 다양한 언어에 대한 지원을 제공합니다.
