Abstract
chest X-rays에서 방사선사 수준으로 폐렴을 탐지할 수 있는 알고리즘을 개발하였다.
CheXNet 알고리즘에서는 121-layer convolutional neural network를 사용(ChestX-ray 14 데이터셋 이용, 현존하는 가장 큰 chest X-ray dataset)
100000 frontal view, 14가지 질환이 있는 데이터셋
4 practicing academic radiologist들이 test set을 annotate해 두었고, 방사선사의 것과 CheXNet의 성능을 비교할 것이다.
F1 metric에서 CheXNet이 대부분의 경우 방사선사의 판독보다 앞섰다.
14가지 질환에 대해 CheXNet의 판독을 확장하여 최고의 성과를 거두었다.
Introduction
백만 성인이 폐렴으로 입원하고, 5만명 정도는 매년 사망한다.(CDC 2017)
Chest X-ray가 현재로서는 진단을 위한 최적의 수단이다.
그러나 chest X-ray에서 폐렴을 찾아내는 것은 방사선 전문가의 능력에 달린 만큼, 어려운 일이다.
이 work에서는 폐렴을 자동으로 탐지할 수 있는 모델(practicing radiologist를 능가하는)를 제시하였다.
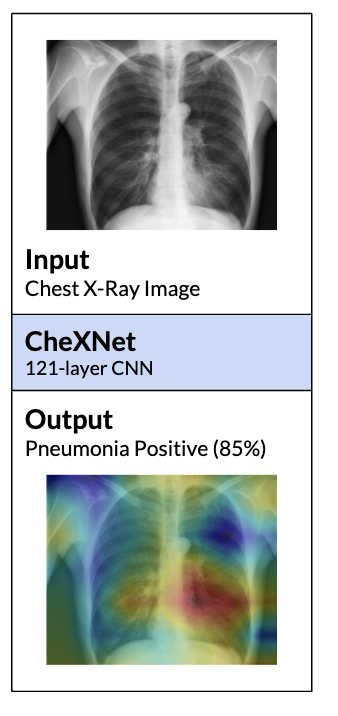
우리의 model, CheXNet의 경우 121 레이어의 CNN이다.
input은 chest X-ray이미지
output은 폐렴의 확률을 보여주며, heatmap으로 폐렴의 가능성이 높은 곳을 표시한다.
CheXNet을 최근 릴리즈된 ChestX-ray14 데이터셋으로 train하였다. (112,120 frontal-view chest X-ray image가 포함)
Dense Connections와 Batch Normalization을 사용하여 이러한 깊은 네트워크를 tractable하게 최적화하였다.
chest radiography에서 폐렴을 찾아내는 것은 방사선사에게 어쩌면 매우 어려운 일일 수도 있다.
X-ray 이미지에서의 폐렴의 모습은 모호하고, 다른 진단과 overlap될 수 있고, 다른 많은 benign abnormalities를 따라할 수 있다.
이러한 차이(discrepancy)들은 폐렴에 대한 방사선사마다의 진단을 다양하게 만든다(다르게 만든다)
방사선사의 performance를 측정하기 위해, 420개의 image의 subset에 대한 annotation을 모았다.(ChestX-ray 14 데이터셋에서)
이러한 420이미지들에서 우리는 radiologists 각자와 모델에 대한 성능을 각각 측정하였다.
모델이 폐렴 탐지 분야에서 average Radiologist Performance를 초과한 것을 알 수 있었다. ChestX-ray 14 데이터셋을 이용한 다른 모델과 비교⇒ 모든 14개의 질환에 대해 최고의 성능이 나왔다.
올바른 진단을 자동으로 수행할 수 있는 것은 헬스 케어와 clinical setting에 크나큰 이익을 가져다준다.
2. CheXNet
2-1. Problem Formulation(문제 정의)
폐렴 탐지 작업: Binary Classification(폐렴이다 or 아니다)
frontal-view chest X-ray image X를 input으로 하고 output를 binary label y {0, 1}로 한다.
L(X, y) = -w(+) ylogp(Y = 1|X) -w(-) (1-y)logp(Y = 0|X)
training set의 하나의 example에서 weighted binary cross entropy loss를 최적화한다.
p(Y = i|X)는 Network가 label i를 assign할 가능성을 의미한다.
w+: |P| / |P|+|N|
w-: |N| / |P|+|N|
2-2. Model Architecture and Training
CheXNet은 121레이어의 Dense CNN이다. ChestX-ray 14 데이터셋을 기반으로 한다.
DenseNets는 information의 flow를 향상하고, deep network를 tractable하게 하였다.
이 논문에서는 하나의 output를 가지는 final fully connected layer를 sigmoid nonlinearity 적용 후 변경하였다.
ImageNet 모델에서 사전 학습된 weight들로 초기에 설정되어 있다.
Network는 end-to-end로 학습되어 있고(Adam을 사용,, B1 = 0.9, B2 = 0.999)
mini-batch의 size는 16으로 지정.
learning rate: 0.001
decayed by a factor of 10 each time the validation los plateaus after an epoch.
가장 validation loss가 적은 모델로 선택한다.
Data
3-1 : 훈련용 데이터
ChestX-ray 14 dataset(Want et al.)을 사용한다.
14개의 다른 thoracic pathology labels이 있는 데이터셋.
이 논문에서는 폐렴에 대하여 annotate(표시된) 병리를 positive example로 그렇지 않은 것을 negative example로 레이블 하였다.
폐렴 탐지 task에서 training(28744환자, 98637 이미지), validation(1672환자, 6351이미지), test set(389환자, 420이미지)로 나누었다 (중복 없음)
224*224의 이미지로 network에 이미지 입력 전 다운스케일링 수행
Mean and standard deviation of images in the ImageNet Training set.
random horizontal flip을 통해 argement를 진행하였다.

3-2 Test:
420 frontal chest X-ray이미지를 모아서 진행하였다.
Annotation은 Stanford University의 4명의 현직 영상의학과 의사에게 진행
4, 7, 25, 28년 경력의 영상의학과 의사로 구성
sub-specialty fellowship trained thoracic radiologist
영상의학과 의사들은 환자의 배경 정보나 사전 지식에 전혀 접근할 수 없는 상태로 실험이 진행되었다.
레이블은 standardized data entry program으로 enter됨.
4. CheXNet vs. Radiologist Performance
4-1 Comparison
영상의학과 의사와 CheXNet의 폐렴 진단에서의 성능을 비교해 보았다.
4labels from radiologists and 1 label from CheXNet
F1 score을 계산한다(각각의 영상의학 의사와 CheXNet의)
bootstrap을 사용(to construct 95% bootstarp confidence intervals(CIs))
10,000 bootstrap samples에서 계산→ sampled with replacement from the test set
2.5th, 97.5th percentiles of the F1 scores as bootstrap CI.
CheXNet은 0.435의 F1 score
영상의학과 의사의 경우 0.387의 F1 score
CheXNet의 성능이 영상의학과 의사의 판독 성능보다 우수함을 결정하기 위해 평균 F1 score의 차이를 계산해 보기로 하였다.
95% CI on the difference는 0을 포함하지 않았다.
CheXNet와 영상의학과 의사의 F1 Score는 차이가 있었음을 알 수 있다.
0.051의 차이 존재(95% CI 0.005, 0.084) - CheXNet의 성능이 통계적으로 영상의학 의사보다 우수함을 알 수 있다
4-2 Limitations
세 가지의 한계점은 존재한다.
- frontal radiograph만이 의사와 모델에 주어졌다. (크게 보면 15%까지의 진단의 경우 정확한 진단을 위해 lateral view가 필요하다)
- 이러한 세팅이 성능에 대한 보수적인 추정을 하게 만들었다.
- 모델과 의사 모두 환자의 의료기록에 대한 접근이 허락되지 않았다. chest radiograph를 해석하는데 있어 성능의 하락을 보일 수 있다. 열과 기침을 동반한 폐의 이상은 폐의 경화라는 용어보다 더 상세한 폐렴이라고 진단하는 것이 맞을 것이다.
5. CheXNet vs. 이전의 State of the Art 모델(ChestX-ray14 Dataset)
3가지 변화를 통해 다종류의 폐질환을 감별할 수 있도록 모델을 확장하였다.
- one binary label을 출력하는 대신에, CheXNet은 vector t를 설정하여, 14가지의 class에 대한 질환이 있는지 여부를 표시하도록 하였다.(폐활량, 심장 비대, 통합, 부종, 삼출, 폐기종, 섬유증, 탈루, 침윤, 종괴, 결절, 흉막 비후, 폐렴, 기흉)
- 마지막 Fully Connected Layer를 14차원의 output으로 구성하였다. 이 출력은 elementwise sigmoid nonlinearity를 적용한 후 출력한다.
- loss function을 수정하였다. unweighted binary cross entropy loss의 합으로 계산한다.
70%의 훈련 데이터셋, 10% 검증, 20% 테스트 데이터셋
환자의 중복은 존재하지 않는다.
CheXNet은 모든 14개의 class에서 최상의 결과를 달성하였다.
Mass, Nodule, Pneumonia, Emphysema에서 기존의 모델을 특히 능가함.
6. Model Interpretation
Network Prediction을 해석하기 위해, heatmap을 만들었다.
CAM을 만들기 위해, image를 학습이 완료된 네트워크에 넣고 feature map을 뽑는다.(final Convolution Layer에서 출력된 것들로)
Final Weight를 곱하여 k개의 feature map의 구성요소를 모두 더한다.
7. Related Work
딥러닝과 large dataset은 퍼포먼스를 높일 수 있도록 활성화하였다.
당뇨 망막병증, 피부암 분류, 부정맥 탐지, 뇌 출혈 감지의 메디컬 분야에서도 활성화되었다.
Chest 방사선 이미지의 자동화된 진단은 폐결핵 검사, nodule detection, OpenI dataset을 이용한 많은 연구 또한 자행되었다.
8. Conclusion
폐렴은 이환율과 사망율에 많은 영향을 미치는 질환이다.
폐렴의 조기 진단과 치료는 사망 예방에 도움이 된다.
2억 case가 매년 발생하며, 가슴 X-ray가 실무에서 가장 많이 사용되는 스크리닝, 진단, 질병 관리 도구이다.
2/3의 인구가 방사선 진단의 혜택을 보지 못하며, X-ray를 해석할 수 있는 전문가가 부족하다.
frontal-view chest X-ray를 통하여 현존하는 영상의학과 의사 수준의 판독을 수행할 수 있는 알고리즘을 개발하였다.
simple extension으로 다양한 질병을 탐색할 수 있다. 전문가 수준의 자동화로 이 기술이 헬스케어와 영상의학 접근성이 제한된 지역에서도 메디컬 이미징에서의 접근성을 향상할 수 있을 것으로 기대한다.
