Callstack 과 Heap
Callstack이란?
변수의 주소와 값을 저장해두는 공간이다.
Heap이란?
객체와 배열, 그리고 함수를 저장하는 공간이다.
이때 Heap과 Callstack은 서로 분리된 관계는 아니다
(여기서부턴 제 생각)
조금 있다 언급할 것이지만 JS는 모두 객체로 이루어져 있다는 사실이 존재한다.
하지만 문자 형태는 지정해줄 수 있기 때문에 차이가 발생한다고 생각했다.
따라서 모든 객체 즉, 변수들은 CallStack에 저장이 되고 문자형이 객체와 배열, 그리고 함수인 것들은 Heap으로 불린다고 생각했다.
변수 생성
literal문법
이는 기본적인 문법이다.
ex) const str = "Hello"와 같이 지정하는 것을 literal문법이라 칭한다.
정확히는 ${type} literal문법이라 할 수 있다.(위의 경우 String literal)
Constructor Function
그렇다면 다른 방법은 없을까? 물론 있다.
그것이 바로 Constructor Function이다.
ex) const str = new String("Hello") 처럼 사용이 가능하다
이것도 역시 literal문법과 마찬가지로 ${type} Constructor Function이라고 부른다.
하지만 literal문법과의 차이점이 존재한다.
바로 Constructor Function은 객체를 생성한다는 점이다.
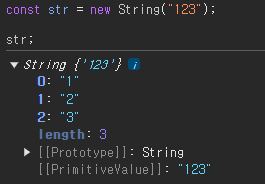
consle창에 결과를 확인해보면 쉽게 확인할 수 있다.
Constructor Function은 기본적으로 Pascal Case를 따른다
또한 BigInt와 Symbol을 생성하는 Constructor Fuction은 존재하지 않는다.
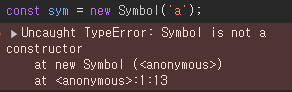
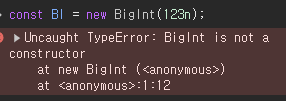
그렇다면 literal문법과 Constructor Function은 완전히 다른 것인가?
그렇지 않다.
JS는 기본적으로 모든 것들이 객체로 이루어져 있다.(이는 나중에 정리해보겠습니다.)
객체
객체란?
자꾸 객체 객체 거리는데 객체는 무엇인가?
객체는 key와 value가 한 쌍을 이루는 property들의 모임이다.
또한 내부에 함수를 포함하는 것도 가능하다
하지만 객체는 순서를 보장하진 않는다고 한다.
내부 함수 작성법은 세 가지가 있다.
1. normal function
f : function(p) {
...
}2.arrow function
f : (p) ⇒ {
...
}3.concise method
f(p) {
...
}arrow function과 concise method는 비교적 최근에 나왔다.
그렇다면 각자의 특징을 살펴보자
우선 normal function으로 작성하게 되면 prototype(constructor)를 포함하여 생성된다
이는 성능적인 관점에서 감점 요인이다.
그렇다면 arrow function 과 concise method는 어떨까?
예상했듯이 포함하지 않는다 -> 이는 성능의 이점을 유도한다.
그렇다면 arrow function과 concise method의 차이는 없는가?
이 둘의 가장 큰 차이는 this의 실행에 있다.
우선 arrow function은 this를 binding하지 않아 상위 context에서 this를 찾는다.
사실 수업을 들으면서 이 문장이 이해되지 않아 나름대로 정리를 해보았다.
arrow function에 사용되는 this는
inherit된다는 느낌이 강했다.sayHi3() { function sayBye() { console.log(this); } sayBye(); } //이때는 this가 window를 가르키게 된다 sayHi3() { function sayBye = () => { console.log(this); } sayBye(); } //이때는 this가 obj를 가르키게 된다 //기본적으로 객체 내부에 있는 함수라 가정첫 번째는 concise method 두 번째는 arrow function을 이용하여 나타낸 것이다.
하지만 this의 결과값은 매우 다르다
이유는arrow function의 경우상위 context인sayHi3()의this를 할당받아 작동한다. (sayHi3()의 this는 obj이다)
그렇다면concise method의 경우는 어떠한가?
concise method내부에 있는 sayBye()는 사실 window에 속한 함수이다.
그 이유는 간단하다sayBye는obj에 의해 호출된 것이 아니니까!
이렇게 생각하니 조금은 이해가 됐었다.
이를 좀 더 확실하게 확인해보고 싶으면 window.sayBye()를 입력해보는 것도 좋다.
배열
배열은 앞서 언급했던 객체와는 다르게 ndex 존재하여 순서가 정의다.
배열도 Constructor Function으로 생성이 가능하다
ex) const arr = new Array(n) 이때 n은 배열의 크기를 나타낸다.
함수
함수는 호출되는 순간 값이 생성되고 실행이 완료되는 순간 값이 사라진다.
function sum(a, b) {
let c = a + b;
}
let result = sum(1, 2);
console.log(result); //undefined위의 결과가 undefined로 나타난다.
그렇다면 저 c라는 값을 영원히 얻지 못하는 것인가?
function sum(a, b) {
let c = a + b;
return c;
}
let result = sum(1, 2);
console.log(result); //이제야 비로소 3이라는 결과를 정상적으로 출력할 수 있다.
두 코드의 차이는 return에 있다
함수 내부에서 계산되는 값들을 외부로 반환하고 싶으면 return을 사용하면 된다
참고로 a,b는 parameter 1,2는 argument라고 칭한다
형 변환
암시적 형변환
함수에서 어떠한 연산을 할 때 자동적으로 즉, 암시적으로 형변환이 일어난다.
123 + ""-> 문자형으로 변환'123'/1||'123'*1||+'123'-> 숫자형으로 형 변환!1(false를 반환)||!!1(true를 반환)-> boolean형으로 형 변환
명시적 형 변화
전달받은 값을 의도를 갖고 원하는 타입으로 변환해주는 경우
-
문자열 변환
String(${value}) -
숫자열 변환
수학과 관련된 함수와 표현식에서 자동으로 형 변환이 일어난다.
ex)'6'/'2' = 3과 같은 경우가 있다.
이는곱셈과뺄셈에서도 동일하게 적용되지만+에서는 차이가 있다.
ex) '6' + '2' = '62'가 된다. 이는 문자 접합이 일어났다고 말한다
Number(${value})
parseInt(${value})
주의할 점'str' - 1 -> NaN 반환-> 이는 계산할 수 없으므로null은0으로 변환된다Number(' 9 ') -> 9undefined -> NaN으로 반환- `Number('123abc') -> NaN 반환
-
boolean 변환
Boolean(${value})
falsy한 value(숫자 0, 빈 문자열(''), null, undefined, NaN)은false로 변환된다
이 외의 값들은true로 변환된다
주의할 점'0'의 경우 빈 문자열이 아니므로 true로 변환된다' '의 경우 공백문자를 포함한 문자열이므로 빈 문자열이 아니다 따라서 true를 반환한다
연산자
기본 연산자
우선 종류와 설명을 적도록 하겠다
- : 덧셈 연산자
- : 뺄셈 연산자
- : 곱셈 연산자
- / : 나눗셈 연산자
- % : 나머지 연산자
- ** : 거듭제곱 연산자
이때 신기했던 점은 나눗셈 연산자는 기존에 알고 있던 사실은 정수 부분만 반환한다 였는데
JS에선 소수점까지 나타내준다.
또한 거듭제곱 연산자도 역시 특이했다.
거듭제곱 연산자는 Math.pow와 같은 역할을 한다.
주의할 점
ex) 2+2+'1'
이 값의 결과를 예상해봤을땐 5 혹은 221을 생각할 수 있다.
하지만 이는 41이라는 결과를 반환한다
이유는 계산 순서에 있다.
앞에서 부터 차근차근 계산해보면 2+2는 숫자끼리의 연산이므로 4가 반환된다.
하지만 4+'1'로 바뀌었을땐 자연스럽게 41이라는 결과를 생각할 수 있게된다.
이는 기본 사칙연산 규칙을 따르기 때문이다.
할당 연산자
이는 매우 간단하다 그냥 변수에 값을 할당해주는 역할이다.
ex) let x = 2*2+1
복합 할당 연산자
let counter = 10;
counter = counter + 1;
---
let counter = 10;
counter += 1;위 코드는 서로 같은 역할을 한다.
하지만 코드의 간결성을 따지자면 아래가 더 간결하다
이를 복합 할당 연산자 라고 부른다.
증감 연산자
변수의 앞(전위형)or뒤(후위형)에서 사용되어 값을 변화시킨다.
ex) num++ || ++num
그렇다면 둘의 차이가 무엇일까
우선 결과먼저 말하자면 결과엔 차이가 없다.
하지만 차이는 값을 반환하는 구간에서 있다.
전위형의 경우 값을 반환할 때 1을 증가시켜 반환한다.
하지만 후위형의 경우 값을 반환할때는 변화가 없지만 반환된 이후 1이 증가한다.
ex) num-- || --num 처럼 감소도 가능하다
삼항 연산자
이후 나올 조건문과 상당히 유사하다
ex)let ternary = (condition) ? 'trueValue' : 'falseValue';
이는 condition이 만족한다면 trueValue를 아니라면 falseValue를 반환하는 연산자이다.
배열의 객체 연산
배열끼리의 연산에서는 매우 주의해야 한다.
arr1 = [1,2,3];
arr2 = [4,5,6];
console.log(arr1+arr2);//1,2,34,5,6이는 내부에 있는 값들을 단순하게 이어붙이는 작업 하고 문자형로 반환한다.
이를 해소하기 위해서 과거엔 concat함수를 사용했다.
arr1 = [1,2,3];
arr2 = [4,5,6];
console.log(arr1.concat(arr2)); //[1, 2, 3, 4, 5, 6]하지만 최근엔 spread operator 혹은 spread syntax라 불리는 method를 사용한다
arr1 = [1,2,3];
arr2 = [4,5,6];
arr3 = [...arr1 , ...arr2];
console.log(arr3); //[1, 2, 3, 4, 5, 6]...${arrayName}처럼 사용하고 이는 배열의 모든 값을 나열한다는 의미이다
비교 연산자
종류를 먼저 확인해보면 느낌이 올 것이다
- >
- <
- <=
- >=
- ==
- !=
==와 != 은 생소할 수 있지만 간단하다
일치와 불일치를 나타내는 연산자이다.
문자끼리의 비교도 가능하다
ex) 'A'<'Z' (true)
이는 사전식처럼 보일 수 있지만 그렇지 않다.
ex) 'a' < 'A' (false)
이는 유니코드 순으로 판단하기 때문에 벌어지는 일이다
일치 연산자
- ===
이는 단순하게 값만 비교하는 ==과 다르게 변수의 자료형까지 모두 비교하기 때문에 정확한 판단을 할 수 있다.
NaN 비교
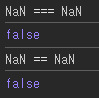
분명 입력한 값이 NaN으로 모두 같은데 왜 다르다고 하는 것인가?
이는 수학과적 관점에선 적분상수라고 이해했다
어떠한 함수를 부정적분을 했을때 초기값이 없이는 정확히 알기는 어렵다
그렇기에 무수히 많은 함수가 생기지만 이를 적분상수로 퉁칠 수 있었다.
NaN도 비슷한 느낌이다.
따라서 이를 비교하고자 isNaN이라는 함수가 존재한다.
조건문
if else문
기본적인 틀은
if(condition1) {
...
} else if(condition2) {
...
} else {
...
}와 같이 사용한다
이는 condition1이 만족한다면 내부의 실행문을 실행한다.
만약 만족하지 않았다면 다음 조건인 condition2를 확인한다. 이후 실행은 동일하다
else를 만나기 전까지 모든 condition들이 만족하지 않았다면 else내부의 실행문을 실행한다
이는 앞서 언급한 삼항 연산자로도 수정이 가능하다
하지만 가독성에 주의해야한다
