이하 구디아카데미 김지훈 강사님의 수업자료와 강의 내용 정리, 실습한 내용을 정리함
아직은 재밌는 SELECT, 갈수록 어려워진다는데 계속 재밌었으면 좋겠다 🎶
subQuery
- 서브쿼리는 '쿼리 안의 쿼리' 라는 뜻이다.
- 서브쿼리는 사전에 추출된 내용에서 재검색 하거나, 검색된 내용을 가상 컬럼을 만들어 추가할 수 있다.
- 즉, 서브쿼리를 사용하는 이유는 가져온 데이터를 재 정제하기 위함이라 볼 수 있다.

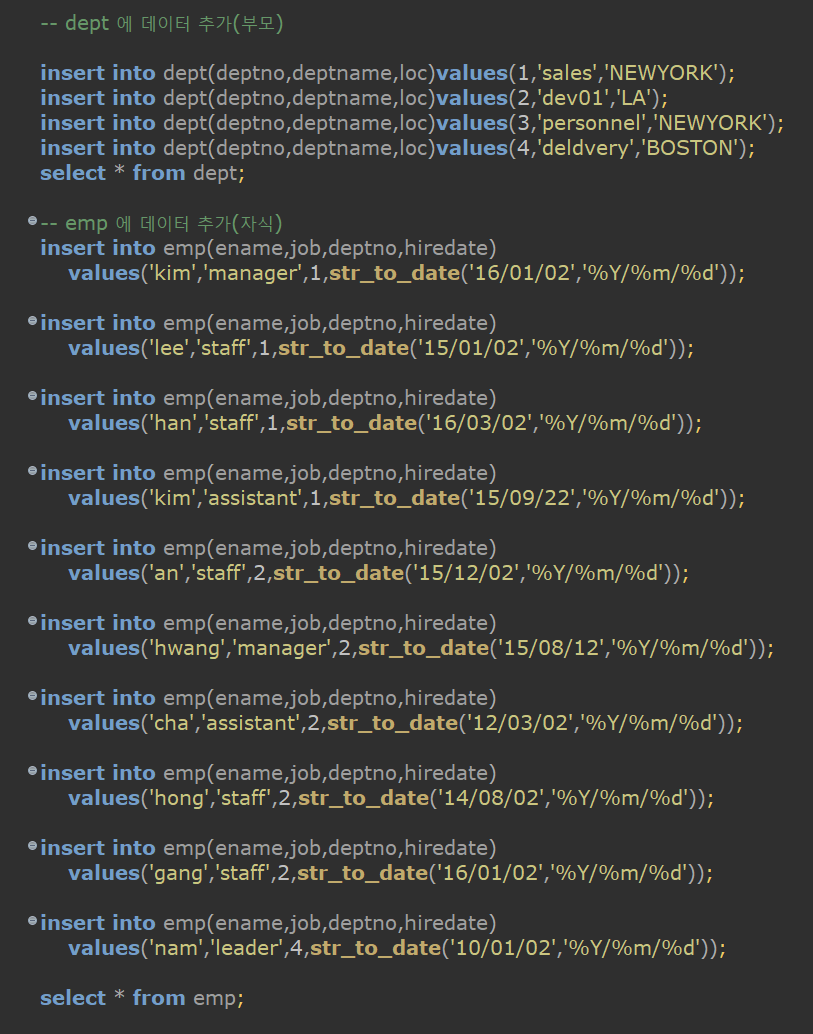
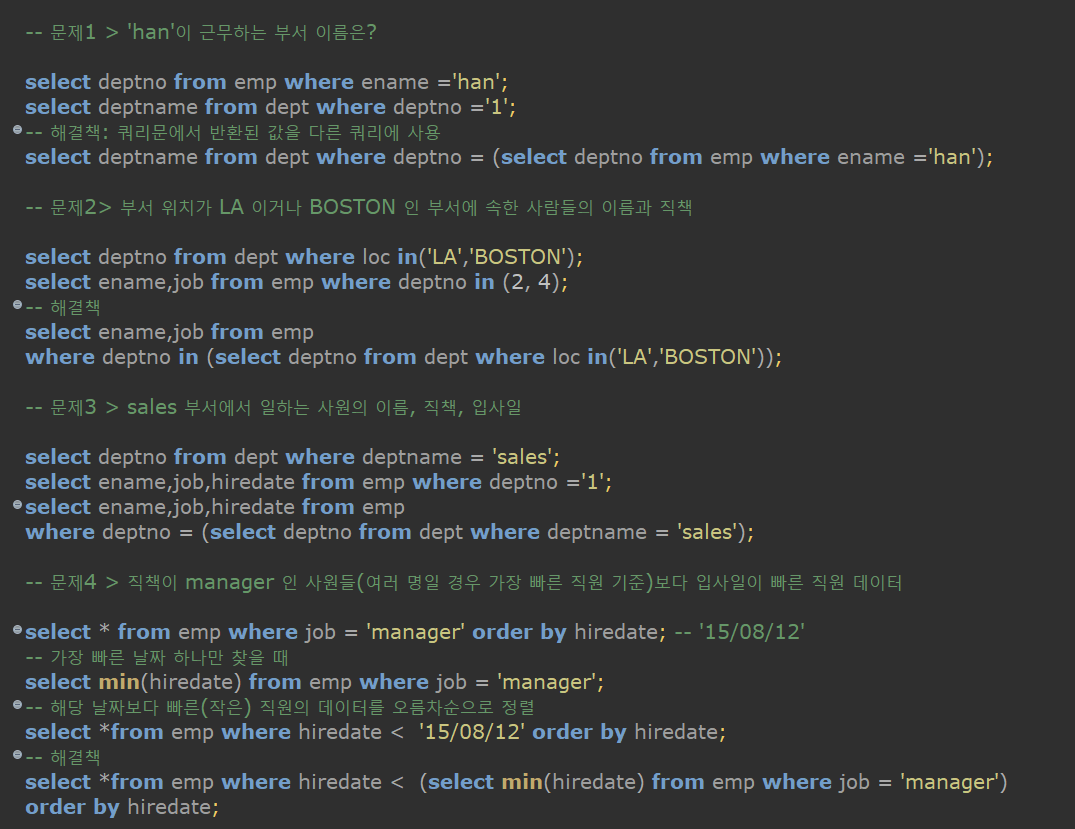
- 문제 1
- deptno 을 가져온다 / emp 테이블에서 / ename 이 han 인; = deptno 값은 1
- deptname 을 가져온다 / dept 테이블에서 / deptno 가 1인; = deptname 값은 sales
- deptname 을 가져온다 / dept 테이블에서 / deptno 가 (ename 이 한인 것을 emp 에서 deptno 로 가져온 값)인;
- 문제 2
- deptno 을 가져온다 / dept 테이블에서 / loc 가 LA 거나 BOSTON 인; = deptno 값은 2, 4
- ename 과 job 을 가져온다 / emp 테이블에서 / deptno가 2이거나 4인;
- ename 과 job 을 가져온다 / emp 테이블에서 / deptno가 (loc 가 LA 거나 BOSTON 인 것을 emp 에서 deptno 로 가져온 값)인;
- 문제 3
- deptno 을 가져온다 / dept 테이블에서 / deptname 이 sales 인; = 값은 1
- ename, job, hiredate 를 가져온다 / emp 테이블에서 / deptno 가 1인; = 값은
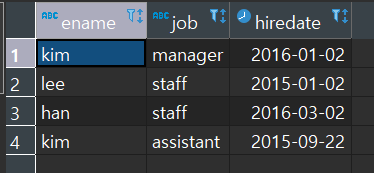
- ename, job, hiredate 를 가져온다 / emp 테이블에서 / deptno 가 (deptname이 sales 인 것을 dept 테이블에서 deptno 로 가져온 값)인;
- 문제 4
- emp 테이블에서 모든 컬럼을 가져와라 / job 이 매니저인 / hiredate 를 오름차순으로 해서
- 가장 작은(빠른) hiredate 를 가져와라 / emp 테이블로부터 / job 이 매니저인
- emp 테이블로부터 모든 컬럼을 가져와라 / hiredate 작은 (emp 테이블에서 잡이 매니저인 것 중 hiredate 가 가장 빠른 것보다) / 오름차순으로
-
문제 5
-
deptno 을 중복제거하고 가져와라/ emp 테이블로부터;
-
deptno 의 수를 가져와라 / emp 테이블로부터 / deptno 가 1인 녀석; = 값은 4
-
deptno 의 수를 가져와라 / emp 테이블로부터 / deptno 가 2인 녀석; = 값은 5
-
deptno 의 수를 가져와라 / emp 테이블로부터 / deptno 가 4인 녀석; = 값은 1
-
deptname 을 가져와라, dept 테이블로부터, deptno 이 1인 녀석; = 값은 sales
-
deptname 을 가져와라, dept 테이블로부터, deptno 이 2인 녀석; = 값은 dev01
-
deptname 을 가져와라, dept 테이블로부터, deptno 이 4인 녀석; = 값은 deldvery
-
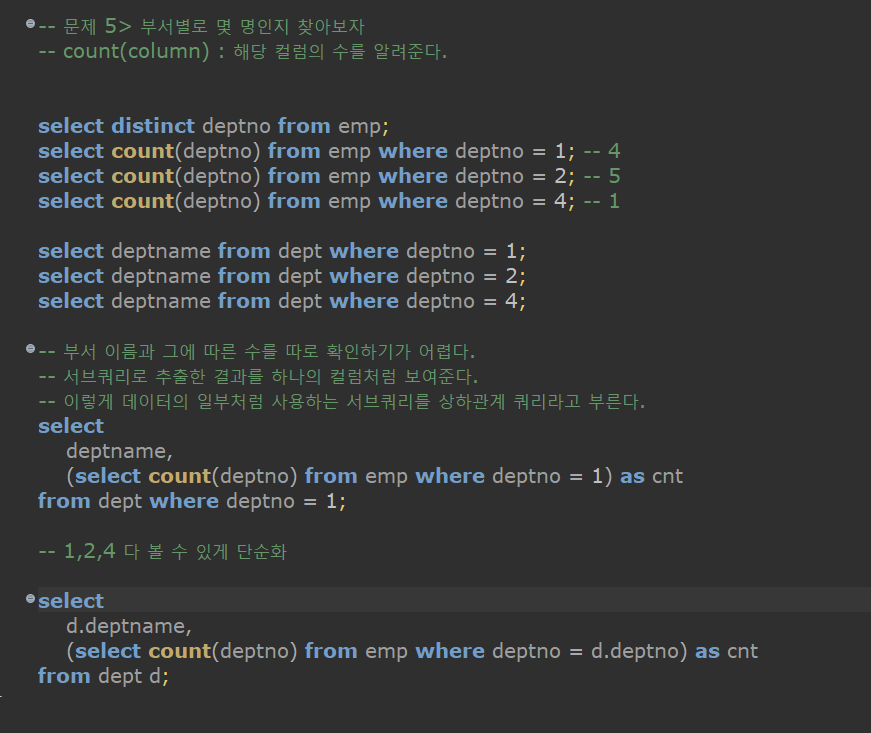
deptname과, (deptno 이 1인 녀석의 수를 emp 테이블로부터, 그리고 cnt 라고 보여 주자) 을 가져와라
/ dept 테이블로부터 / deptno 이 1인
-
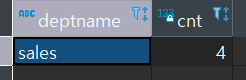
d 테이블의 deptname 과, deptno가 d테이블의 deptno인 녀석의 수를(cnt 라고) 가져와라 / dept d 테이블로부터
-
join
- 서브쿼리만을 사용하면 쿼리가 굉장히 복잡해지기 때문에 join 을 활용한다.
- 둘 이상의 테이블을 연결해서 데이터를 검색하는 방법
- 각 테이블에는 공통되는 컬럼이 적어도 하나 이상은 존재해야 하낟.
- 일반 적으로는 pk 와 fk 를 이용하여 join 한다.
cross join
- cross join 은 카다시안 곱을 수행한다.
- 카다시안 곱을 행한 조합을 반환한다.
- emp(10)* dept(4) =40
- FROM [테이블1] CROSS JOIN [테이블2]
- cross join 은 생략이 가능하다.
- d 테이블의 deptno 컬럼과 d 테이블의 deptname 컬럼과 e 테이블의 enname 을 가져와라 / emp e 테이블과 dept d 테이블로부터
두 테이블의 모든 조합을 반환하기 때문에 의미 있는 데이터를 추출하기 어렵다.
그래서 특정 조건을 주어 아래 join 등을 수행한다.
Equi join
- 가장 일반적인 조인 (=)을 사용한다.
등가조인
- emp 테이블에도 있고, dept 테이블에도 deptno 가 있으면 가져와라
- d 테이블의 deptno 와 d 테이블의 deptname 과 e 테이블의 ename 을 가져와라 / e, d 테이블로부터, e 테이블의 deptno 와 d 테이블의 deptno 가 같은 녀석(1, 2, 4)의;
내부조인(INNER JOIN)
-
조인에 대한 조건을 on 으로 사용하고
-
조인하는 테이블 사이에 inner join 을 넣는다.(inner 는 생략 가능)
-
d 테이블의 deptno 와 d 테이블의 deptname 과 e 테이블의 ename 을 가져와라 / e 테이블과 d 테이블로부터, e 테이블의 deptno 와 d 테이블의 deptno 가 같은 녀석(1, 2, 4)의;
-
on 대신 using 을 조건으로 사용할 수 있다.
-
using 안에는 사용될 컬럼명을 넣을 수 있으며, 서브 쿼리도 넣을 수 있따.
-
d 테이블의 deptno 와 d 테이블의 deptname 과 e 테이블의 ename 을 가져와라 / e,d 테이블로부터 / 둘 모두 deptno 가 있는
NATURAL JOIN
- 동일한 값을 가진 컬럼을 내부적으로 자연스럽게 조인하므로 조건을 주지 않는다.
- 다만 동일한 컬럼은 단축명을 주지 말자
- d 테이블의 deptno 와 d 테이블의 deptname 과 e 테이블의 ename 을 가져와라 / e 테이블과 d 테이블 모두에 있는 키 값의
OUTER JOIN

-
Equi JOIN 에서 할 수 없는 걸 한다.
-
기준(데이터를 더 보여줘야 할 곳)이 되는 곳을 지목
-
outer 는 생략 가능
-
FROM [tableA][LEFT|RIGHT|FULL] OUTER JOIN [tableB] ON [조건절]
-
LEFT OUTER JOIN (왼쪽을 기준으로 더 있는 값을 보여줌)
-
RIGHT OUTER JOIN(오른쪽을 기준으로 더 있는 값을 보여줌)
-
FULL OUTER JOIN(양쪽 서로에게 없는 값들을 보여줌 - nariaDB 에서는 지원 X)
-
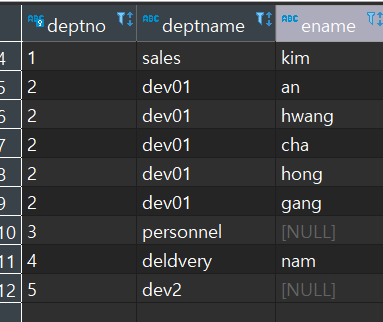
d 테이블의 deptno 와 d 테이블의 deptname 과 e 테이블의 ename 을 가져와라 / 오른 쪽에 있는 d 테이블을 기준으로 deptno 를 가져오고 e 테이블에도 동일한 deptno 이 있으면 가져와라
-
d 테이블의 deptno 값이 더 많으므로 그에 맞추어 e 테이블의 값도 같이 가져와서 정보가 없을 경우 null 을 띄움
-
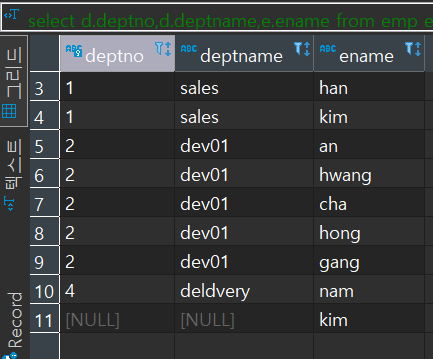
반대의 경우, 왼쪽에 있는 e 테이블을 기준으로 있는 deptno6이 d테이블에 없으므로 결과에서 deptno, deptname 이 null 이 됨
-
SELF JOIN(자기조인)
- EQUI JOIN 과 같으나 대상 테이블이 스스로라는 것이 차이점이다.
- 자기조인은 두 데이터 간에 카다시안 곱을 수행한다.
select a.deptno, b.ename, a.job </br> from emp a, emp b where a.deptno = b.deptno;
집합(set)
- 우리는 두 개의 테이블을 집합연산 할 수 있다.
- UNION 은 중복 확인을 위해 전체 검색 후 정렬하여 검사를 수행하기 때문에 성능에 좋지 않다.
(UNION 은 중복을 허용하지 않는 합집합이다. 중복 제거 시 속도가 저하되어 사용을 권장하지 않는다.) - set은 집합을 의미한다.

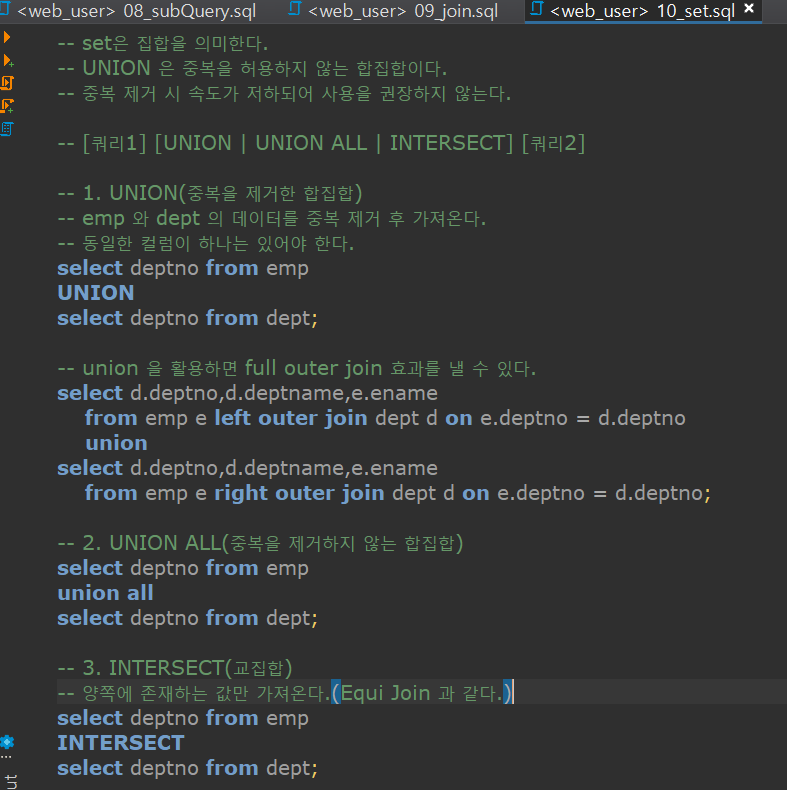
UNION(중복제거 합집함)
- emp 와 dept 의 데이터를 중복 제거 후 가져온다.
- 동일한 컬럼이 하나는 있어야 한다.
- emp 테이블의 detpno 와 dept 테이블의 detpno 를 중복 제거하고 가져와라
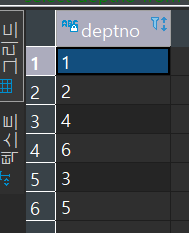
- d 테이블의 deptno 와 d 테이블의 deptname 과 e 테이블의 ename 을 가져와라 / 왼쪽에 있는 d 테이블을 기준으로 deptno 를 가져오고 e 테이블에도 동일한 deptno 이 있으면 가져와라/
아래와 합집합으로/ - d 테이블의 deptno 와 d 테이블의 deptname 과 e 테이블의 ename 을 가져와라 / 오른쪽에 있는 d 테이블을 기준으로 deptno 를 가져오고 e 테이블에도 동일한 deptno 이 있으면 가져와라/
- 결과 : 테이블 내의 모든 값(full outer join)
- 결과 : 테이블 내의 모든 값(full outer join)
UNION ALL(중복을 제거하지 않는 합집합)
- 양 테이블에 있는 모든 deptno 을 가져옴

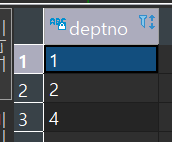
INTERSECT(교집합)
- 양쪽에 존재하는 값만 가져온다.(Equi Join 과 같다.)
MINUS (차집합)
-
mara db 에는 차집합 함수가 없어 NOT IN 을 활용한다.

-
중복을 제외한 deptno 을 dept 테이블에서 가져와라;
-
중복을 제외한 deptno 를 emp 테이블에서 가져와라;
-
emp 테이블의 deptno 를 가져와라, deptno 인, dept 테이블의 deptno 가 포함되지 않게;
-
dept 테이블의 deptno 를 가져와라, deptno 인, emp 테이블의 deptno 가 포함되지 않게;
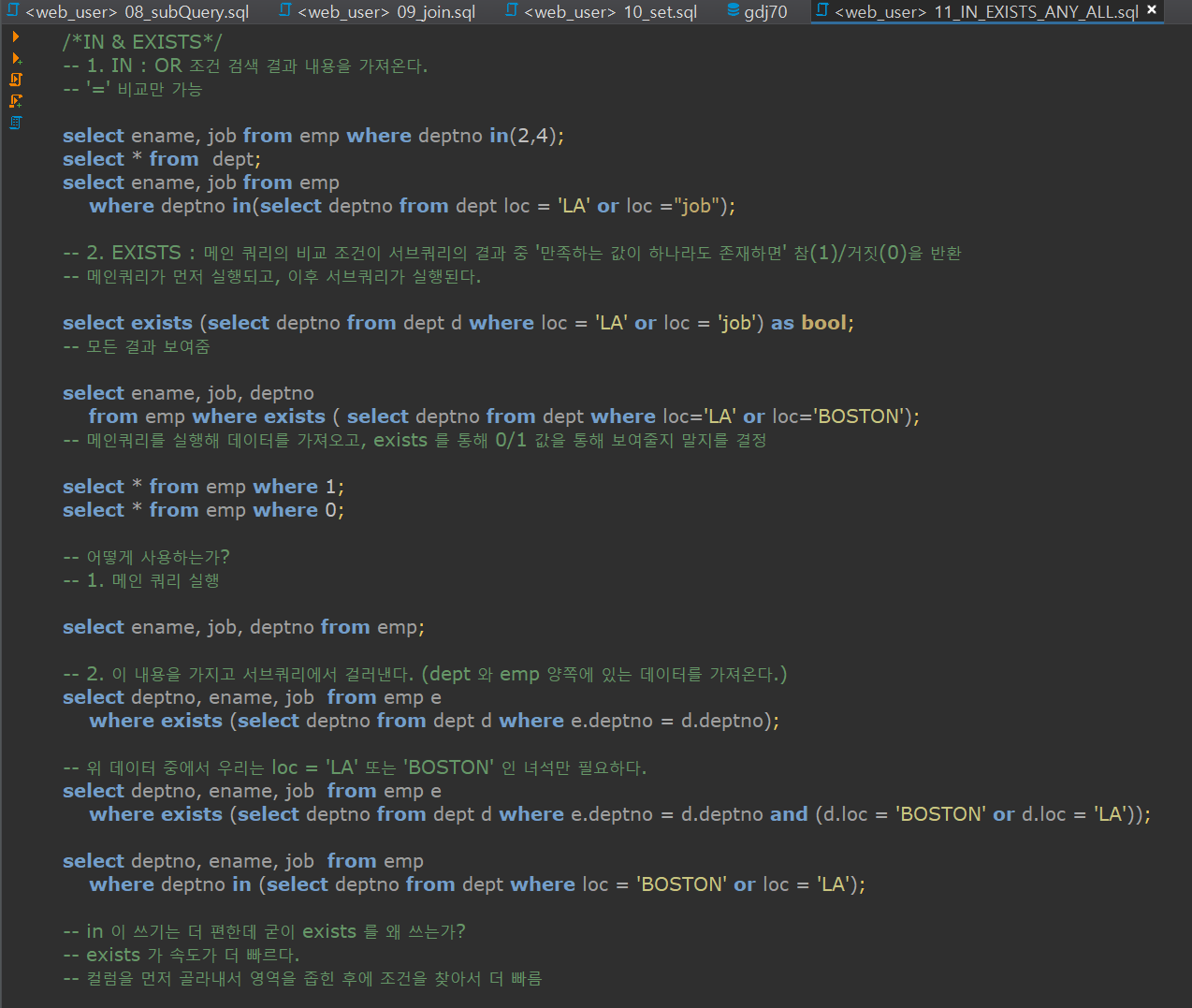
IN / EXISTS
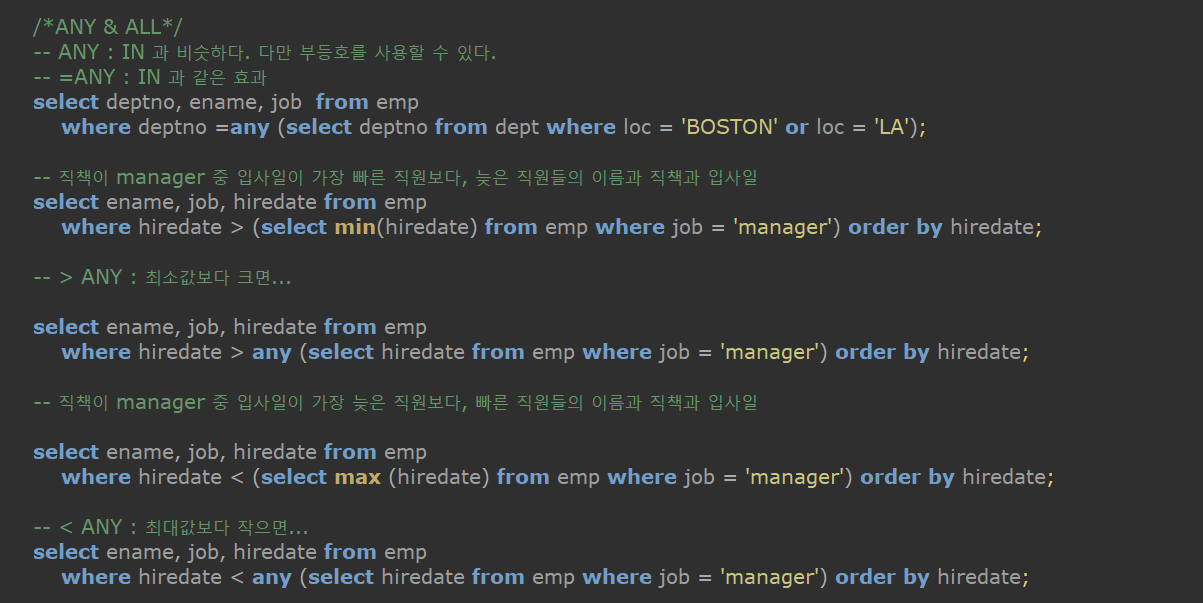
ANY / ALL
- 서브쿼리란 무엇인가? 사용하는 이유는?
- 쿼리 안의 쿼리, 가져온 데이터를 재정제하기 위해
1-1. 상하관계 쿼리란? - 서브쿼리로 추출한 결과를 하나의 컬럼처럼 보여준다.
- 데이터의 일부처럼 사용하는 서브쿼리를 상하관계 쿼리라고 부른다.
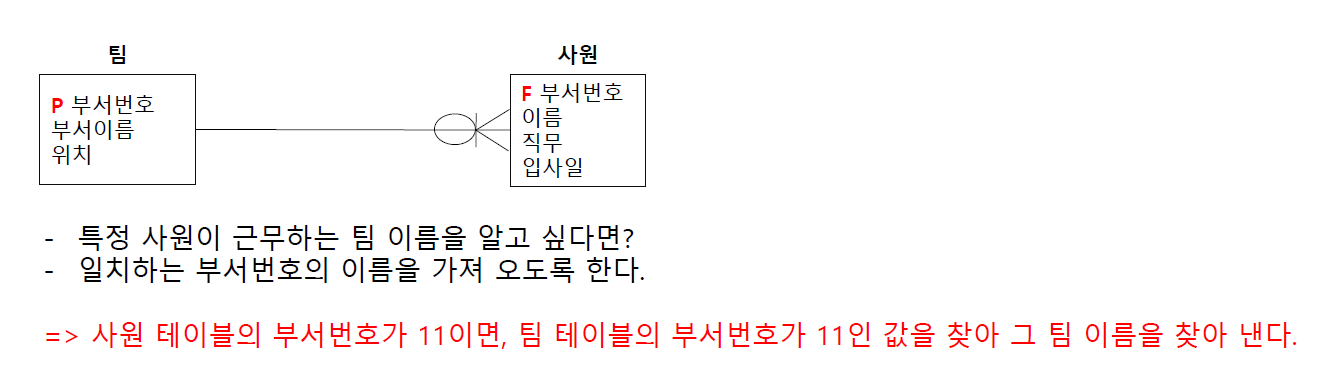
- Join의 정의와 특징은?
- 둘 이상의 테이블을 연결해서 데이터를 검색하는 방법이다.
- 각 테이블에 공통되는 컬럼이 적어도 하나 이상은 존재해야 한다.
- 일반적으로는 pk 와 fk 를 이용하여 join 을 한다.
- 등가조인을 사용했을 때 주의할 점은?
- 두 테이블의 모든 조합을 반환하기 때문에 의미 있는 데이터를 추출하기 어렵다.
- Inner join과 Outer join의 차이점은?
- inner join 은 양쪽 모두에 있는 컬럼의 값을 가져오고
outer join 은 데이터를 더 보여줘야 할 곳이 있는 기준이 되는 테이블을 지목해서 보여줄 수 있다.
- Outer join중에 Left outer join과 Right outer join의 차이점은?
- 왼쪽 기준으로 더 있는 값을 보여줌 / 오른쪽 기준으로 더 있는 값을 보여줌
- Natural join은 조건을 주지 않는 대신 제약 조건이 있었는데, 무엇인가?
- 동일한 컬럼은 닥축명을 주면 안 된다.
- COUNT 함수의 기능에 대해 서술하시오.
- 해당 컬럼의 수를 알려준다.
- Set의 정의와 구성 요소 4가지를 서술 하시오.
- 집합을 의미한다.
- UNION - 중복제거 합집합 / UNION ALL : 중복을 제거하지 않는 합집합 / INTERSECT : 교집합 / MINUS : 차집합
- UNION의 장점과 사용할 때 주의해야 할 사항에 대해 서술하시오.
- union 을 활용하면 full outer join 효과를 낼 수 있다. 각 데이터를 모두 훑어 중복 제거 후 가져오므로 속도가 느려질 수 있다.
- UNION을 사용하면 속도가 느려져 사용을 권장하지 않는다고 하였는데 이에 대한 대체 방법은 무엇인가?
- union all 로 데이터 확보 후 사용
- IN 이 사용하기 더 편한데도 EXISTS 사용하는 이유는?
- 속도가 더 빠르기 때문에
- IN 과 ANY 의 차이점은 무엇인가?
- in OR 조건 검색 결과 내용을 가져오며 등호 비교만 가능하고 ANY 는 or 조건 검색 결과를 가져오는 건 동일하나 부등호를 사용할 수 있다.
- EIXSTS 의 정의와 사용시 쿼리의 실행 순서는 어떻게 되는가?
- 메인 쿼리의 비교 조건이 서브쿼리의 결과 중 '만족하는 값이 하나라도 존재하면' 참(1)/거짓(0)을 반환
- 메인쿼리가 먼저 실행되고, 이후 서브쿼리가 실행된다.
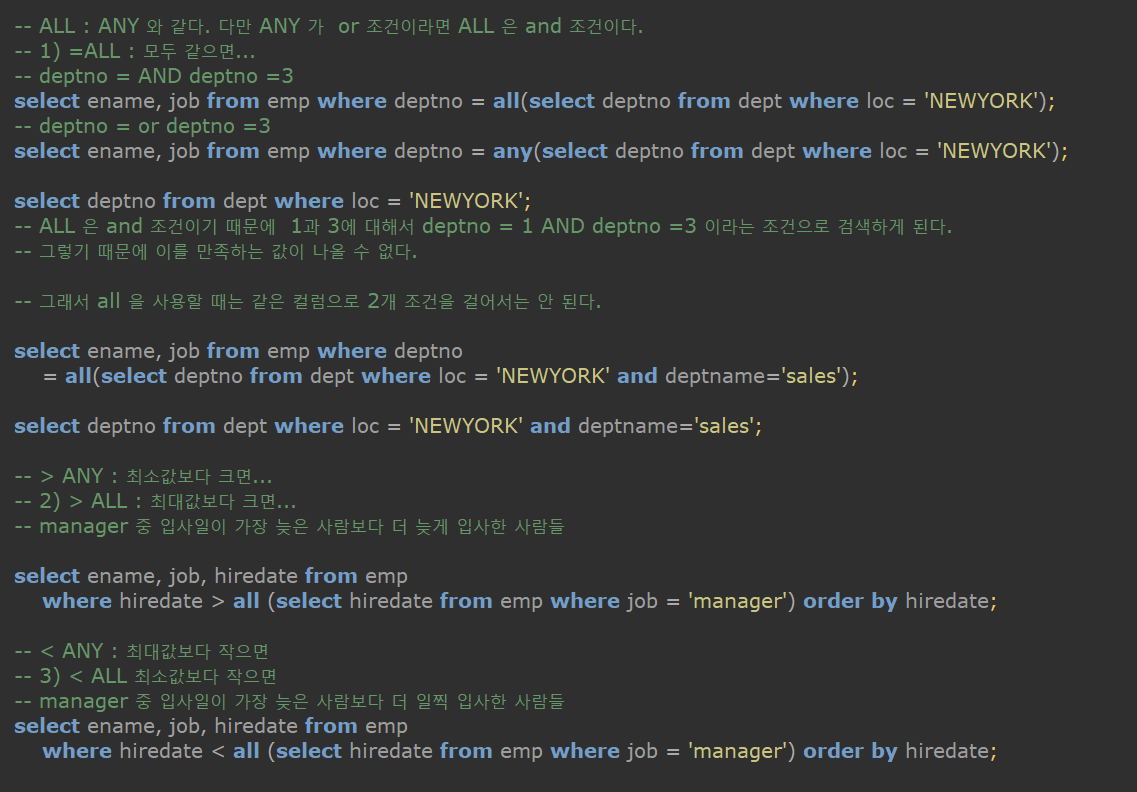
- ALL 을 사용할 때 주의해야 하는 점은 무엇인가?
- ALL 은 and 조건이기 때문에 1과 3에 대해서 deptno = 1 AND deptno =3 이라는 조건으로 검색하게 된다.
그렇기 때문에 이를 만족하는 값이 나올 수 없다.
그래서 all 을 사용할 때는 같은 컬럼으로 2개 조건을 걸어서는 안 된다.
