이번시간에는 데이터베이스에서 중요한 개념인 트랜잭션과 LOCK에 대해서 알아보도록 할게요.
목차
트랜잭션
- 트랜잭션이란 ?
- 트랜잭션 특징
- 트랜잭션 격리레벨
트랜잭션
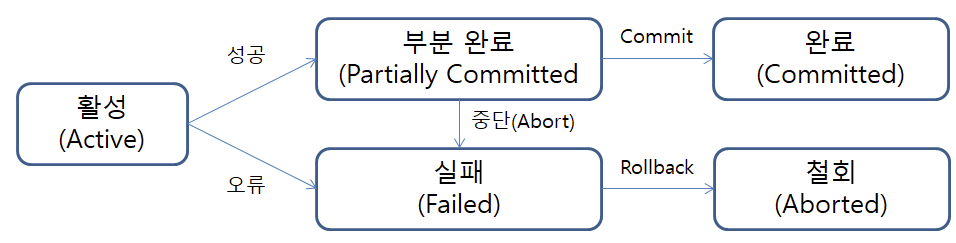
트랜잭션은 데이터베이스에서 수행되는 작업들이 하나의 논리적 단위로 묶인 것 입니다.
그래서 트랜잭션을 사용한다는 것 자체로 비용이 매우 크고, 주의해야할 점이 존재해요.
왜냐하면 트랜잭션을 보장하기 위해 여러 작업들(프록시 객체, 트랜잭션 시작, 종료, 롤백 등)이 들어가며 트랜잭션의 범위가 커짐에 따라 다른 스레드의 작업들이 대기하게될 수 있기 때문입니다.
예를 들어 돈을 이체하는 상황을 보겠습니다.
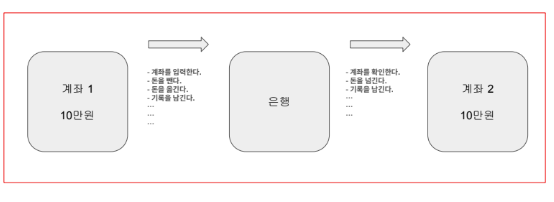
계좌 1과 2가 있으며, 계좌 1에서 이체를 그리고 계좌 2에서 그 돈을 받는 상황입니다.
이 이체하는 전 과정을 하나의 논리적인 단위로 묶는 것을 트랜잭션이라고 합니다.
트랜잭션 흐름
트랜잭션의 흐름은 4가지 정도로 이루어져있습니다.
- START TRANSACTION
- WRITE, READ
- COMMIT
- ROLL BACK
START TRANSACTION으로 트랜잭션을 시작하고 WRITE, READ로 연산을 수행하며, COMMIT으로 데이터베이스에 저장을 함으로써 트랜잭션이 종료가 됩니다.
하지만 트랜잭션이 시작되 이후 어떠한 이유로 중간과정에서 오류가 발생하여 일부분만 로직이 수행이 되었다면 ROLL BACK을 통해 이전상황으로 돌아갈 수 있게 됩니다.
이렇게 하나의 트랜잭션을 통해 트랜잭션 내에 존재하는 로직들은 하나의 논리적인 단위로써 사용할 수 있게 됩니다.
그러므로 이 하나의 논리적인 단위가 커지면 커질수록 여러개의 스레드들이 어떠한 작업을 동시에 실행하려고 할때 대기가 발생할 확률도 커지므로 이 트랜잭션의 범위를 줄이는 것이 중요합니다.
트랜잭션 특징
- 원자성
- 일관성
- 독립성
- 지속성
원자성
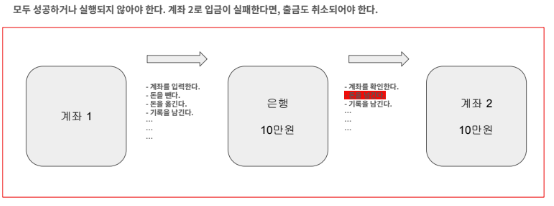
이전의 예시와 같이 이체하는 상황을 보게 되면 이체하는 전 과정을 논리적인 단위로 묶었기 때문에 이 과정 중 하나라도 실패하게 되면 전체 과정이 다시 로직 실행 이전 상태로 돌아가야 합니다.
이렇게 실패하게 될때 이전상태로 돌아가야하는 특징이 원자성입니다.
이체를 위해 계좌 1에 있는 10만원을 빼는 상황을 가정해보겠습니다.
트랜잭션이 시작되게 되면 MySQL은 InnoDB에 있는 원본 데이터에 -10만원을 하게 됩니다.
그리고 기전에 원본 데이터였던 잔액 10만원에 대한 데이터는 삭제되는 것이 아니고 Undo Log에 기록으로 남게 됩니다.
그리고 만약 트랜잭션이 위와 같이 진행되다가 돈을 넘기는 과정에서 실패하게 될 경우 Undo Log에 있는 내용으로 복구가 되는 방식으로 원자성을 보장하게 됩니다.
만약 실패하지 않고 모든 로직이 정상적으로 동작하였다면 이 트랜잭션은 커밋이 되며 데이터베이스에 최종적으로 저장이 됩니다. 이후에 다른 트랜잭션이 동일한 데이터를 읽을때에는 계좌1 에서는 0원을 읽게 됩니다.
일관성
일관성이란 시스템에서 규정한 규칙을 지킬 수 있는 능력을 의미합니다.
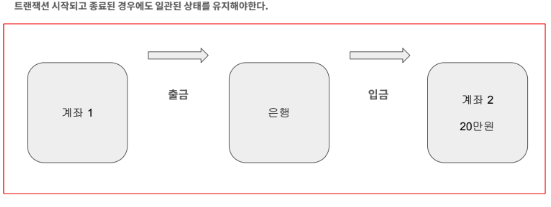
즉, 트랜잭션 종료 후에도 시스템에서 규정한 규칙을 준수하는 것을 의미합니다. (이체금액은 각 계좌의 잔액을 초과할 수 없다. 계좌 잔액은 0원이하로 내려갈 수 없다. 등)
이번에는 예를 들어 아래와 같이 외래키 제약조건을 살펴보겠습니다.
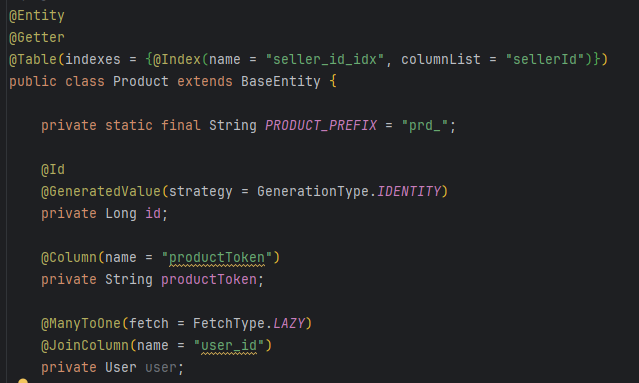
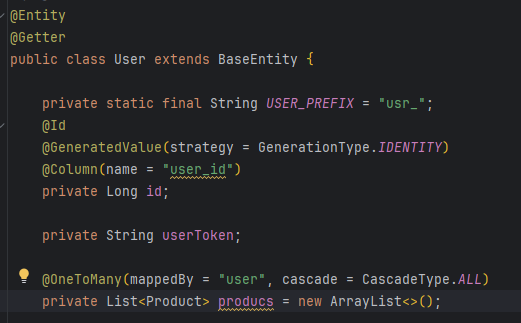
JPA에서는 이와 같이 외래키 제약조건을 둘 수 있게되요. 이 제약조건은 데이터 생성, 삭제 시 부모 테이블의 해당키 존재 여부를 매번 체크함으로써 일관성을 보장할 수 있게 됩니다.
하지만 이는 어느정도 trade off를 지니고 있습니다.
외래키를 설정하게 되면 JPA가 외래키 제약을 통해 데이터 무결성을 보장해주지만, 그만큼 성능상의 이슈가 있을 수 있게 됩니다. 만약 분산환경 데이터베이스에서 테이블을 분할해야하거나 병합해야하는 요구사항이 주어지게 되면 더욱 복잡성이 증가하게 됩니다. 그래서 실무에서는 외래키 제약조건을 선호하지 않는다고 합니다.
그리고 이 일관성 규칙은 문맥에 따라 달라지기도 합니다.
분산환경에서의 일관성은 데이터베이스 ACID의 C(일관성) 과는 또 다른 의미를 가질 수 있습니다.
분산환경에서의 데이터베이스 일관성은 CAP 이론의 C를 의미합니다.
CAP이론을 간략하게 살펴보겠습니다.
CAP은 일관성(Consistency), 가용성(Availability), 분할 내성(Partition tolerance)의 약자로, 이 세 가지 속성 중에서 동시에 모두를 만족시킬 수 없다는 이론입니다.
왜냐하면 일관성은 모든 노드가 동일한 시점의 데이터를 보유해야 한다는 것을 의미하고, 가용성은 모든 요청이 성공적으로 처리될 수 있어야 한다는 것을 의미합니다. 분할 내성은 네트워크 분할이 발생해도 시스템이 정상적으로 작동해야 한다는 것을 의미합니다.
CAP 이론에 따르면, 이 세 가지 속성 중 두 가지만을 만족시킬 수 있으며, 어떤 두 가지를 선택하느냐에 따라 시스템의 특성이 결정됩니다.
이는 분산 시스템을 설계할 때, 시스템의 요구 사항에 따라 적절한 속성을 선택해야 함을 의미합니다.
독립성
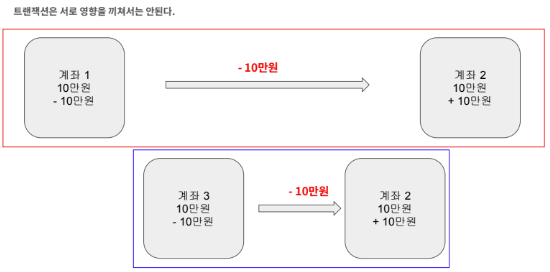
독립성이란 트랜잭션은 서로 영향을 끼쳐서는 안되는 것을 의미합니다. 서비스를 운영하다보면 여러 트랜잭션들이 동시에 발생하는 경우가 생길 수 있으며 이때 각 트랜잭션들은 서로에게 영향을 주지 않고 독립적으로 수행되어야 합니다.
예를 들어 계좌 1과 계좌 3이 동시에 계좌 2로 10만원씩 보냅니다.
이때 위 처럼 최종적으로 30만원이 되어야 하지만 데이터베이스에 데이터를 읽고 수정하는 과정에서 LOCK 없이 업데이트가 될 경우 결국 20만원만 저장이 될 수 있습니다.
이러한 이유로 인해 동시성을 제어해야하며, 격리수준을 적합하게 설정하는 것이 매우 중요합니다.
지속성
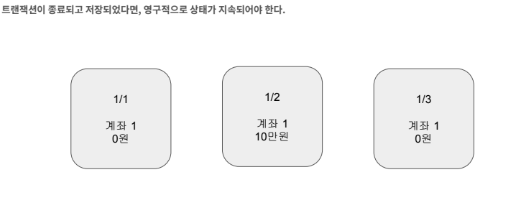
지속성이란 트랜잭션이 시작되고 커밋이 완료되면 트랜잭션의 결과는 어떠한 소프트웨어나 하드웨어 장애가 발생되더라도 데이터베이스에 저장이 되고 지속이 되어야 한다는 의미입니다.
만약 트랜잭션 커밋 후 데이터베이스에 저장되고 있는 도중 데이터베이스 서버가 불특정한 이유로 다운된다면 어떻게 될까요 ?
커밋이 되었으니 데이터베이스에 저장되어야 한다는 점이 보장되어야 할텐데 말이죠.
그렇다면 이를 어떻게 보장할까요 ?
-
트랜잭션의 시작과 로그 기록
트랜잭션이 시작되면, MySQL은 먼저 트랜잭션 로그 파일(Redo log)에 해당 트랜잭션의 변경 내용을 기록합니다. 이때 변경 내용은 아직 데이터 파일에는 반영되지 않습니다. 이 로그 파일에 기록된 내용은 디스크에 즉시 저장되어, 시스템이 갑작스럽게 다운되더라도 해당 로그 파일에 기록된 내용은 손실되지 않습니다. -
커밋과 데이터 파일 반영
트랜잭션이 커밋되면, MySQL은 트랜잭션 로그 파일에 커밋 로그를 기록합니다. 이 커밋 로그가 기록됨으로써 해당 트랜잭션의 모든 변경 사항이 확정되었음을 의미합니다. 이후 MySQL은 백그라운드에서 트랜잭션 로그를 참고하여 실제 데이터 파일에 변경 내용을 반영합니다. 이 과정은 즉시 일어나지 않을 수 있지만, 로그 파일에 이미 기록되었기 때문에 트랜잭션의 지속성은 보장됩니다. -
장애 발생 시 복구 과정
만약 트랜잭션 커밋 후 데이터베이스가 다운되면, MySQL은 재시작 시 트랜잭션 로그 파일을 읽어 복구 작업을 수행합니다. 트랜잭션 로그 파일에는 아직 데이터 파일에 반영되지 않은 커밋된 트랜잭션의 변경 내용이 포함되어 있습니다. MySQL은 로그 파일을 분석하여 커밋된 트랜잭션의 변경 사항을 다시 데이터 파일에 반영함으로써 트랜잭션의 지속성을 보장합니다.
즉, 다시 말해서
트랜잭션의 변경 내용을 먼저 로그 파일에 기록하고, 커밋 로그를 기록하여 커밋을 확정합니다. 서버가 다운되더라도 로그 파일을 통해 복구 작업을 수행하여 트랜잭션의 지속성을 보장합니다. 이 방식은 하드웨어나 소프트웨어 장애가 발생하더라도 트랜잭션의 결과가 데이터베이스에 안전하게 저장되도록 합니다.
Undo Log와 Redo Log의 차이는 ?
Redo Log는 데이터의 상태가 변경된 이후 상태의 정보이며, Undo Log는 데이터의 상태가 변경되기 전의 상태의 정보입니다.
예를 들어 A의 계좌에 잔액이 10만원이라고 가정합니다.
A -> B 로 5만원을 이체했다고 가정해보겠습니다.
A의 계좌 잔액은 10만원에서 -> 5만원이 되었으므로 이 과정에서 Redo Log에는 상태가 변경된 이후의 정보이므로 5만원 이 저장되게 되며 Undo Log에는 10만원 이 저장되게 됩니다.
트랜잭션이 진행되며 각각 필요한 상황에서 Redo Log와 Undo Log가 사용되게 됩니다.
격리 레벨 - 독립성
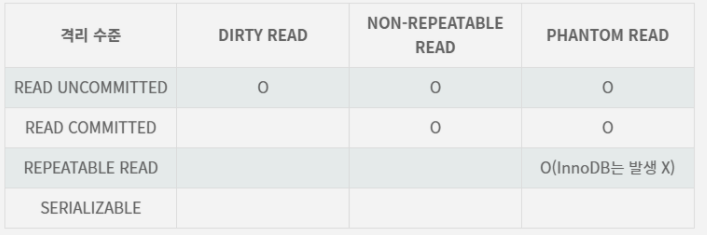
트랜잭션의 격리 레벨은 위 표의 왼쪽 격리 수준처럼 4가지가 존재합니다.
이러한 4가지 격리레벨은 오른쪽의 3가지 현상으로 구분이 됩니다.
이 3가지 현상 중 몇가지를 방지하고 있는지, 혹은 허용하는지를 놓고 이 격리레벨을 결정하게 되는 것입니다.
Dirty Read
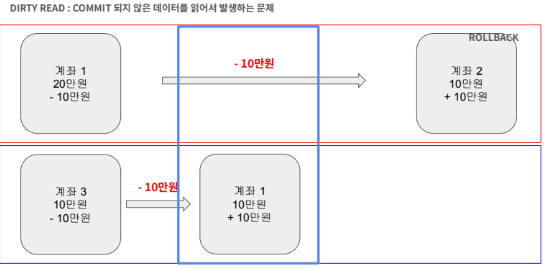
두가지의 트랜잭션이 있고 동일한 시점에 시작되었고 첫번째 트랜잭션은 실패하여 ROLL BACK 하였다고 가정합니다.
계좌 1이 계좌 2로 10만원을 송금하고 계좌 3이 계좌 1로 10만원을 송금하는 상황입니다.
첫번째는 실패하고 두번째만 성공하므로 각 계좌의 잔고는 아래와 같아야 할 것입니다.
- 계좌 1 : 30만원
- 계좌 2 : 10만원
- 계좌 3 : 0원
하지만 그러지 못하고 20만원으로 업데이트가 되는 상황이 발생할 수 있습니다.
왜냐하면 파란색 표시에 있는 내용처럼 update는 되었지만 commit되지 못한 데이터를 다른 트랜잭션이 읽었기 때문입니다.
이렇게 commit 되지 못한 상황의 데이터를 읽는 것을 Dirty Read라고 합니다.
Non Repeatable Read
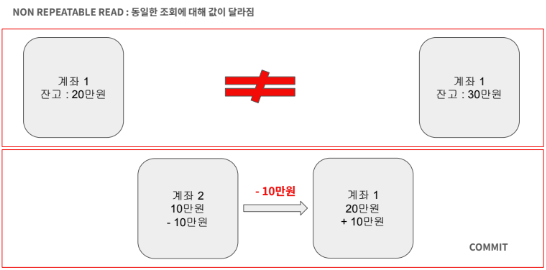
이번 예시는 첫번째 트랜잭션에서 계좌 1의 잔고를 여러번 읽는 작업을 진행하고 있다고 가정해보겠습니다.
이때 두번째 트랜잭션에서 계좌 2에서 계좌 1의 잔액을 변경하고 커밋을 하게 되면 첫번째 트랜잭션에서 읽었을때 다른 계좌 잔액을 볼 수 있습니다.
Non Repeatable Read는 하나의 트랜잭션에서 동일한 값을 읽을때 다른 값이 발생하는 현상을 의미합니다.
Phantom Read
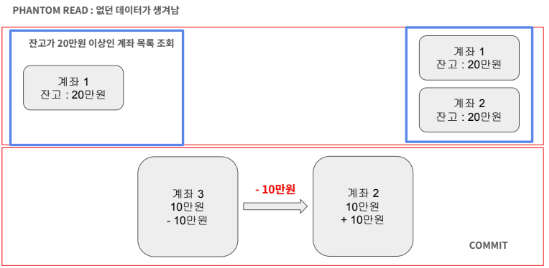
첫번째 트랜잭션에서는 전체 계좌에 대해 20만원이상인 목록을 여러번 조회한다고 가정합니다.
두번째 트랜잭션에서는 계좌 2에 10만원을 이체하는 트랜잭션입니다.
이럴 경우 하나의 트랜잭션에서 다른 결과를 얻는다는 점은 Non Repeatable과 동일하지만, Pathom Read는 없던 데이터가 생겨나는 현상을 의미합니다.
Non Repeatable은 조회 결과 값 자체가 변경되는 것을 의미하고 Panthom Read는 데이터가 추가되어 결과가 달라지는 것을 의미합니다.
격리레벨
이전에 보았던 표를 다시 보도록 하겠습니다.
Read Uncommitted는 커밋되지 않는 데이터도 읽기 때문에 3가지 모든 현상이 발생할 수 있습니다.
반면에 Read Committed는 커밋된 데이터만 읽으므로 Dirty Read가 발생하지 않습니다. 하지만 committed된 데이터를 읽으므로 Non Repeatable과 Phantom Read가 발생할 수 있습니다.
Repeatable Read는 커밋된 데이터만 보고 트랜잭션마다 버전ID를 부여하여 데이터를 관리하게 됩니다.
그래서 해당 트랜잭션의 버전과 다른 버전의 데이터의 경우에는 보이지 않게 되어 항상 동일한 Read를 보장하게 됩니다.
Serialiable Read 는 어떠한 현상도 발생하지 않는 것을 의미합니다.
표에서의 내용은 아래로 갈수록 이상현상은 줄어들지만 그와 동시에 동시 처리량이 낮아질 수 있습니다.
그리고 Repeatable Read를 사용하게 되는 경우 데드락이 많이 발생할 수 있어 Read Commited를 많이 사용하게 됩니다.
