특정 예측 모델의 성능을 수치로 표현하기 위해 Confusion Matrix(이하 CM)를 주로 사용합니다.
사내에서 음성 인식 모델이 얼마나 정확하게 인식하는지에 대해 모델별로 분석하기 위해 CM 을 사용하였습니다.
먼저 이 CM의 개념에 대해서 살펴보겠습니다.
개념
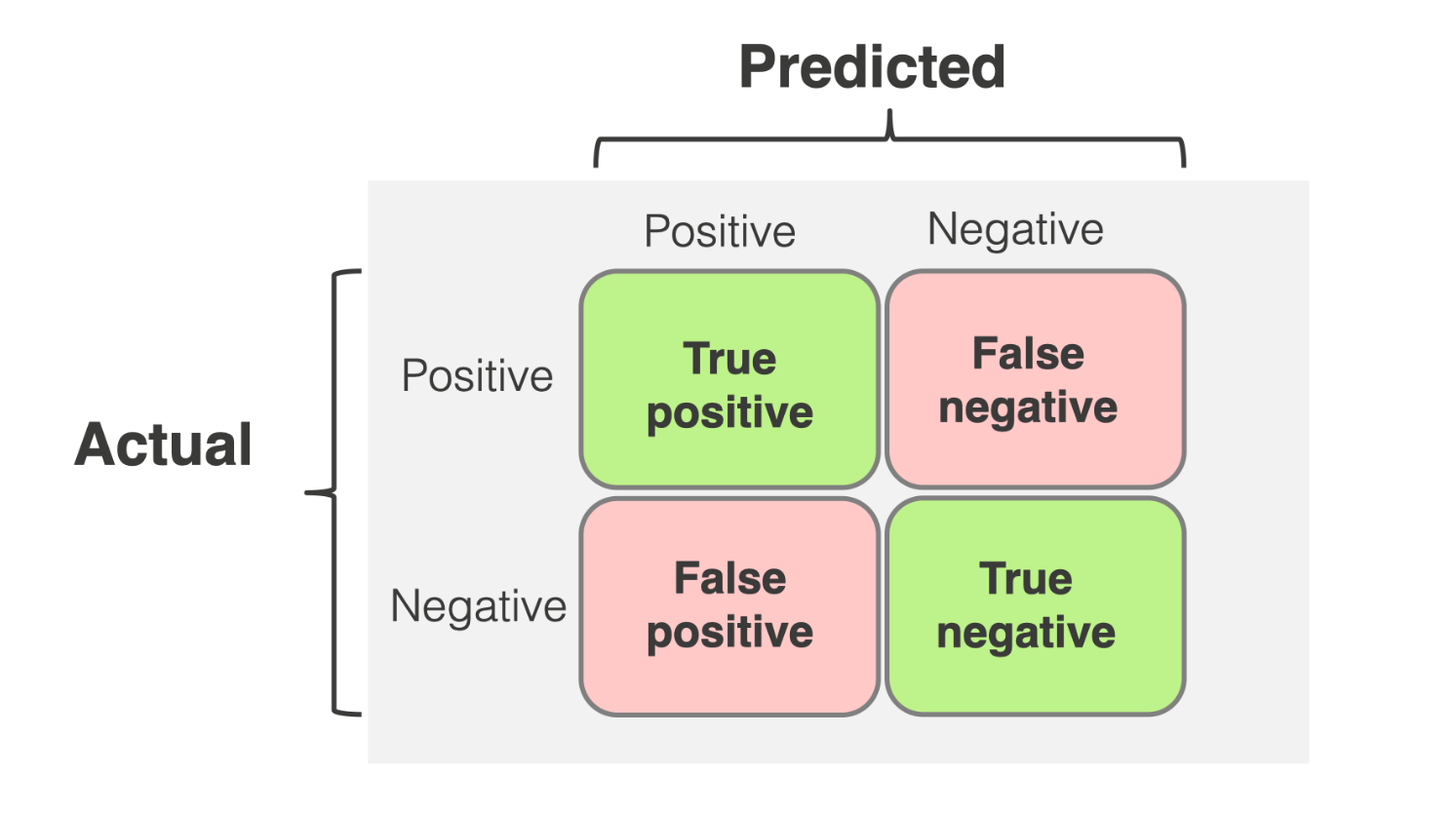
모델의 답과 실제 답을 비교 측정할때에는 총 4가지 케이스가 나오게 됩니다.
여기서 실제 답이란 ground truth 머신러닝 및 데이터 과학 분야에서 모델의 학습, 평가, 검증을 위한 기준으로 사용되는 '실제 정답' 데이터를 의미합니다.
이는 모델의 예측값과 비교되는 객관적인 기준값이며, 현실 세계의 정확한 상태나 참값을 나타냅니다. 즉, 이 값을 우리는 모델이 맞췄는지 틀렸는지에 대한 기준으로 정합니다.
1번째는 실제 답을 모델도 답이라고 판단하는 케이스 True Positive
2번째는 틀린 답을 모델도 틀렸다고 판단하는 케이스 True Negative
3번째는 틀린 답을 모델은 답이라고 잘못 판단하는 케이스 False Positive
4번째는 실제 답을 모델은 오답이라고 잘못 판단하는 케이스 False Negative여기서 3번과 4번 케이스에 대해서 저는 많이 헷갈렸습니다.
이렇게 이해하니 한결 나아졌습니다.
저희는 CM을 2 부분으로 나눌 수 있습니다. [True/False]와 [Positive/Negative] 로 말이죠.
1번째 True False 부분은 모델의 예측 결과입니다. 이 부분이 True이면 모델이 예측에 성공한 것이고, False는 예측에 실패한 것입니다.
그래서 1번째 부분이 True 일 경우에는 자연스럽게 이해할 수 있습니다. 2번째에 따라오는 내용에 따라 Positive일 경우 긍정예측을 맞춘것이고, Negative일 경우 부정 예측을 맞춘것입니다.
하지만 앞이 False 일 경우 예측에 실패했다는 뜻이며 이때 2번째 부분을 주의깊게 살펴봐야 합니다.
- Positive 란 긍정적인 뜻이니 모델이 긍정적으로 판단을 시도했지만 False로 실패
즉 틀린 답을 모델은 긍정적으로 답이라고 판단- Negative 란 부정적인 뜻이니 모델이 부정적으로 판단을 시도했지만 False로 실패
즉 실제 답을 모델은 부정적으로 오답이라고 판단False Positive는 틀린 답을 모델이 긍정적으로 정답이라고 잘못 판단
False Negative는 정답을 모델이 부정적으로 오답이라고 잘못 판단
으로 생각해보았습니다.
이 각각의 값들을 사용하여 모델 성능을 나타내는 precision, recall, f score를 계산할 수 있습니다.
| Actual / Predicted | 예측 Positive | 예측 Negative |
|---|---|---|
| 실제 Positive | TP 8 | FN 2 |
| 실제 Negative | FP 5 | TN 3 |
만약 위와 같은 결과를 가진다고 가정해보겠습니다.
precision은 번역하면 '정밀도' 로 모델이 Positive라고 응답한 내용중 실제 정답의 비율은 어느정도인가 ? 에 대한 확률입니다. 즉 기준이 모델의 응답이 됩니다. 모델이 응답한 것 중 실제 정답의 비율을 구하기 때문입니다.
- 분모는 TP[맞다고 예측한 것 중 실제로 맞는 것] + FP[맞다고 예측한 것 중 사실 오답인 것] => 8 + 5 = 13이 됩니다.
- 분자는 TP[맞다고 예측한 것 중 실제로 맞는 것] 로 8 이 됩니다.
그래서 precision은 8/13 으로 61.5% 가 됩니다.
recall은 번역하면 '재현율' 로 실제 정답 중에서 모델이 정답이라고 맞춘 비율이 어느정도인가 ? 에 대한 확률입니다. 즉 기준이 실제 정답이 됩니다. 실제 정답중에서 모델이 맞춘 정답의 비율을 구하기 때문입니다.
- 분모는 TP[맞다고 예측한 것 중 실제로 맞는 것] + FN[틀렸다고 예측한 것 중 사실 정답인 것] => 8 + 2 = 10 이 됩니다.
- 분자는 TP[맞다고 예측한 것 중 실제로 맞는 것] 로 8 이 됩니다.
그래서 recall은 8/10 으로 80% 가 됩니다.
발표 회고
아래는 간략하게 발표한 내용에 대한 회고 입니다.
PT 발표가 아래와 같았다면 더 좋았을 것 같다.
자 여기 precision, recall, fscore 라는 지표가 있습니다.
이 지표는 이 모델의 성능을 나타내는 지표입니다.
이 지표들을 보기전에 이해해야할 내용들이 몇가지 있는데요. 쉽게 예를 들어 설명해보겠습니다.
예를 들어 골 영상을 보고 이 영상이 골인지 아닌지를 판단하는 모델이 있다고 가정해볼게요.
그러면 총 4가지 케이스가 나오게 됩니다.
1번째는 실제 골을 모델이 골이라고 판단하는 케이스 TP
2번째는 노골을 모델이 노골이라고 판단하는 케이스 TN
3번째는 실제 골을 모델이 노골이라고 판단하는 케이스 FN
4번째는 노골을 모델이 골이라고 판단하는 케이스 FP
여기서 저희가 집중할 내용은 오류를 얼마나 잘 탐지하느냐 입니다.
왜냐하면 저희는 native speaker의 말을 얼마나 잘 이해하느냐가 아니라 nonnative speaker 인 영어 학습자들을 대상으로 하기 때문에 오류를 얼마나 잘 탐지하느냐가 저희가 포커싱할 내용이 되어야 했습니다.
그래서 실제로 보시는 값들을 보고 처음에 왜이리 값들이 낮지 ? 라고 생각할 수 있습니다.
이 값들은 오류를 얼마나 잘 탐지하느냐에 대한 내용입니다.
그래서 다시 말하면 맞는 것을 맞다고 판단하는 값에 대해서는 대부분 90% 가 넘습니다. 하지만 오탐율은 그에 비해 낮습니다 보시는것 처럼 보통 2~30% 입니다.
지금 저희가 테스트한 내용은 비원어민들의 테스트셋을 대상으로 하였고 그래서 오류도 좀 있는 편입니다.
위 4가지 케이스를 이해하고 다시 precision, recall, fscore로 돌아가보겠습니다.
여기서 말하는 precision은 얼마나 오류를 잘 예측했는가 입니다. 즉 모델이 말한 노골 중 실제 노골의 비율은 얼마인가 ? 입니다. 즉 precision은 베이스가 모델이 말한 내용이 됩니다.
그래서 이 precision의 방정식은 TN / TN + FP 가 되겠죠.
즉 실제 노골중에 모델이 노골이라고 한 비율입니다.
recall의 방정식은 재현율로 실제 노골중에 얼만큼 모델이 노골이라고 판단했는지에 대한 비율입니다. 즉 recall의 베이스는 실제 노골이 됩니다. 방정식은 TN / TN + FN
그래서 이 recall 방정식은 재현율로 실제 노골중에 얼만큼 모델이 노골이라고 판단했는지에 대한 비율입니다.
이 됩니다.
그래서 예를 들면 가장 상단의 precision이 0.26 인것을 보면, 아 이 모델과 prompt이 예측한 결과중 26% 정도가 실제로 틀린 내용이구나. recall이 0.5 인것을 보면 이 모델은 실제 틀린 것을 50% 정도 잡아내구나 를 알 수 있습니다.
여기서 precision이 recall보다 낮다는 것은 그만큼 오류를 많이 뱉는다는 것입니다. 실제 오류가 있는것 보다 말이죠.
이런식으로 최신 모델이 나오고 팀 내부에서 새로운 prompt 가 나올때마다 주기적으로 테스트를 해보며 기록하고 있습니다.