
이미지 출처 : purestorage
아래 내용은 NoSQL 데이터베이스가 빠른 이유 | LSM Tree 완전정복 유튜브를 정리한 내용입니다.
안녕하세요. 이번시간에는 비 관계형 데이터베이스인 NoSQL 의 LSM Tree 동작원리에 대해 알아보겠습니다.
Lsm tree
- Log structured storage engine 중 한가지이며 이 기반으로 동작
- Log파일이란 append only 파일을 의미합니다. 새로운 내용은 항상 끝에 추가됩니다.
즉, 기본적으로 Log structured storage engine 에서 순차적으로 향상시킨 것이 LSM Tree가 될 수 있습니다.
LSM Tree 동작원리를 알기 위해 아주 기본적인 engine형태에서 점진적으로 발전시켜 나가서 LSM Tree가 어떻게 동작하는지를 알아보겠습니다.
키워드
주요 키워드는 아래와 같습니다.
- Log File
- SStable
- Compaction
- Memtable
- Sorted
기본 Bash Function
다음과 같은 bash Function이 있다고 가정해봅니다.

db_set()은 key value 스토어에 새로운 key value pair 를 추가, 업데이트하는 것을 의미합니다.
db_get()은 key를 주면 그 key에 들어가 있는 value를 리턴해주는 함수입니다.
아래와 같이 db_set() 으로 key value를 넣고 db_get() 으로 값을 찾게 된다면 '{"name" : "ephiepark"}'가 찾아지게 될 것입니다.
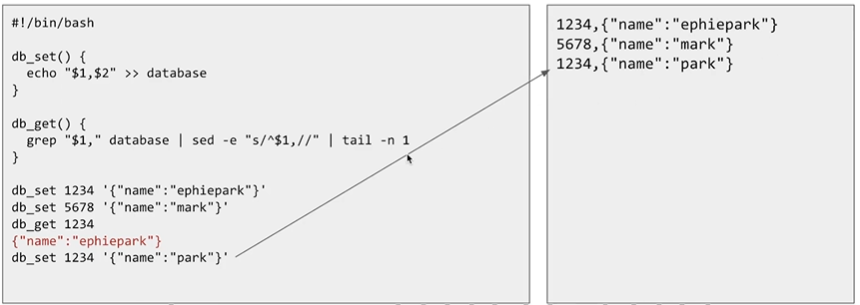
그리고 db_set 1234 '{"name" : "park"}' 를 하게 되면 기존의 데이터를 업데이트하는 것이 아니라 '{"name" : "park"}' 데이터를 맨 마지막에 append를 해주게 됩니다. 왜냐하면 append-only 파일이기 때문입니다.
데이터를 수정하는 것은 불가능하며 추가만 가능합니다.
이후 db_get 1234를 하게 되면 마지막에 추가된 '{"name" : "park"}' 가 리턴되게 됩니다.
db_set 퍼포먼스 즉 write 은 빠릅니다. 왜냐하면 log 파일 끝에 추가만 되므로 디스크가 빠르게 처리할 수 있기 때문입니다. 하지만 이 storage engine은 get 이 느립니다. 왜냐하면 db_get 요청이 올때마다 full scan을 해야하기 때문입니다.
어떻게 개선할 수 있을까요?
Index 사용
Index를 만들어서 사용하면 빠르게 get을 할 수 있게 됩니다.
Index는 쿼리 퍼포먼스를 높이기 위해 추가적으로 가지고 있는 데이터 구조 입니다.
Index 사용시 장점과 단점
장점 : read 퍼포먼스를 더 좋게 만듦
단점 : Index는 결국 실제 원본 데이터 외에 추가적으로 가지는 데이터 구조이므로 메모리와 디스크 용량을 가지게 됩니다. 그리고 Index는 새로운 데이터가 write을 할 때 원본 데이터와 Index는 서로 일관되어야 하기 때문에 함께 update를 해줘야하므로 Index가 많을수록 wrtie 퍼포먼스가 좋지 않을 수 있습니다.
Hash Index
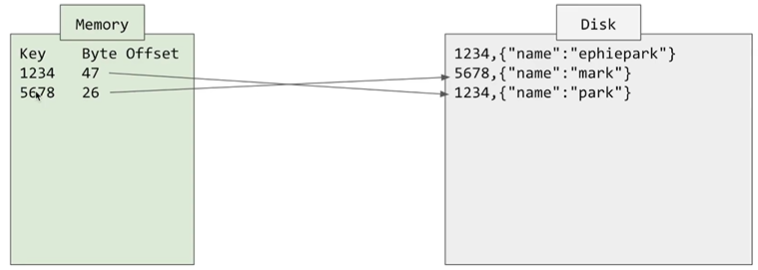
그래서 In memory hashmap를 index로 사용할 수 있음 key로 데이터의 key를 저장하고 value로 데이터의 주소값인 byte offset 을 저장하게 됩니다.
그래서 1234를 찾게 되면 Offset위치인 47로 Disk에서 바로 Look up을 할 수 있게 됩니다.
Look up이란 특정 값을 찾기 위해 데이터베이스를 검색하는 과정을 의미합니다
이렇게 되면 full scan을 하지 않고도 db_get 퍼포먼스도 빠르며 append-only 파일이므로 데이터 추가 퍼포먼스도 빨라지게 됩니다.
실제 Bitcask라는 key/value store에서 이런 방식을 사용한다고 합니다.
하지만 이 방식에는 문제가 있습니다.
10초만 고민해보겠습니다.
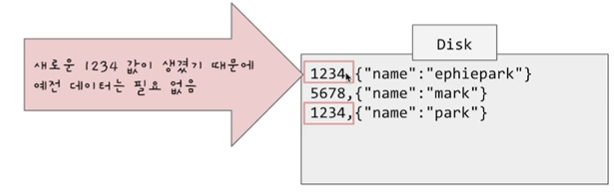
바로 많은 update가 발생할 경우 사용하지 않는 불필요한 데이터가 Disk를 차지하게 되는 것입니다.
아래 사진과 같이 1234 값이 새로 생겼기 때문에 이전 1234에 대한 value는 필요가 없어지게 됩니다.
Segment file 과 Compaction
Segment file은 Database 의 데이터 파일들을 하나로 가지는 것이 아니라 일정 크기가 되었을때 새로운 데이터파일을 만드는 것을 의미합니다. 이렇게 되면 좋은점은
이전의 segment file은 더이상 바뀌지 않게 됩니다. (Immutable)
바뀌지 않게 됨이 보장되므로 불필요한 데이터를 쉽게 삭제할 수 있게 됩니다.
이 삭제하는 과정을 Compaction이라고 합니다.
아래 그림에서 겹치는 Key가 있을 경우 해당하는 Key를 지워줄 수 있습니다.
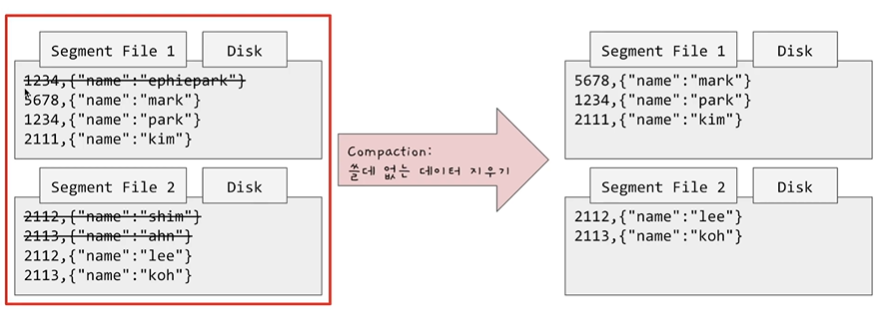
그렇게 되면 완성된 모습은 아래 그림과 같습니다.
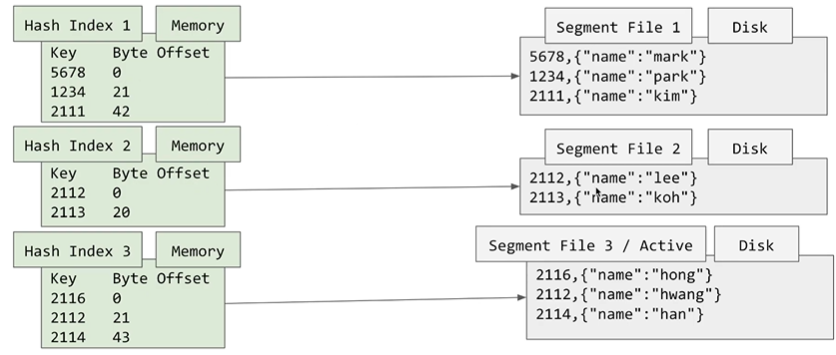
Hash Index가 segment file 별로 존재하게 됩니다. 즉 Index가 segment file별로 존재하며 이 index를 통해 Disk의 데이터를 조회할 수 있게 됩니다.
여기서 read 요청이 오게 될 경우 전체적인 Flow는
- Key가 가장 최근의 segment file에 있는 인덱스에 존재하는지 확인
- 없다면 ? 그 다음 segment file의 인덱스
- 없다면 ? 그 다음 segment file의 인덱스
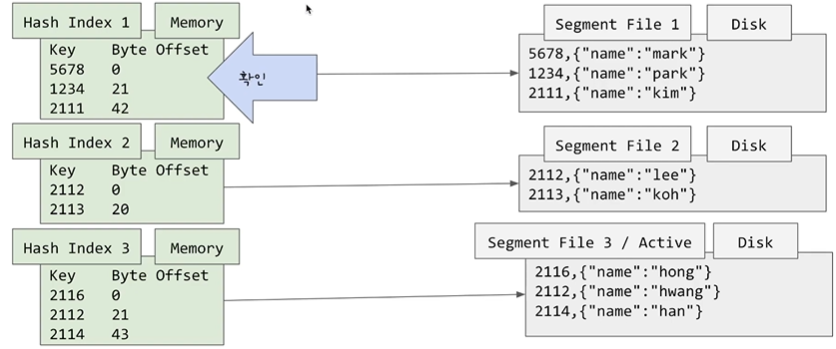
와 같이 Index를 시간순으로 최근의 Index부터 과거까지 조회하며 찾을 경우 Index의 value인 Offset을 통해 Disk에 접근하게 됩니다.
이렇게 간단한 Log Structured Storage Engine을 만들어보았습니다.
하지만 여기에서도 문제점이 있을 수 있습니다.
- 모든 hash key들을 memory에서 들고있어야 합니다.
- Hashmap으로 index를 구현했으므로
- 만약 Key가 메모리에 들어가지 못할 경우 Index에서 Key를 찾을 수 없으므로 Full Disk Scan이 발생하게 되어 시간이 오래 걸립니다.
- Range query하기가 어렵다
- Segment file 내에서는 중복이 없지만 segment file 끼리는 중복이 발생하므로, 그리고 segment file의 index는 정렬이 되어있지 않으므로
LSM Tree
SST Sorted String table

기존의 segment file에는 유저가 write한 순서대로 저장이 되었지만 SST는 Key로 Sort 되어 있는 순서대로 저장됩니다.
이렇게 되면 저장시 정렬이 되어야 하는데 어떻게 append-only로 끝에만 추가할 수 있는가 ? 라는 의문이 들게 됩니다.
새로운 데이터를 추가할때에는 SST 에 바로 추가하여 정렬하는 것이 아니라 Memory에 있는 binary tree 이진트리에 저장함 이때 아래 사진과 같이 이진 트리는 self balancing binary tree 으로 균형은 항상 보장이 되며 이후 정렬도 쉽게 할 수 있게 됩니다.
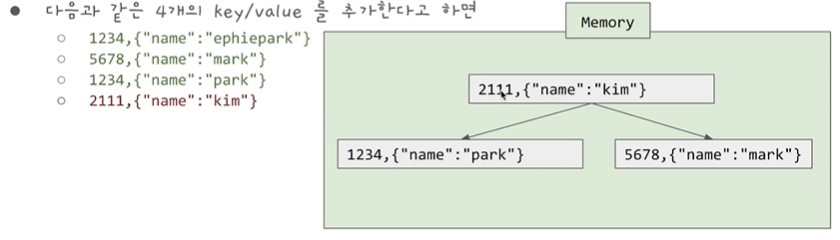
여기서 이 Memory 에 저장되는 tree를 Memtable이라고 합니다.
이후 memtable이 일정 size를 넘어가게되면 그때 SSTable을 Disk에 만들게 됩니다.
Disk에 데이터를 쓸때 이 binary tree의 장점을 보게 됩니다. binary tree에 데이터를 저장함으로써 key가 sort된 순서대로 읽기가 쉬우며 append-only 방식으로 데이터를 저장하게 됩니다.
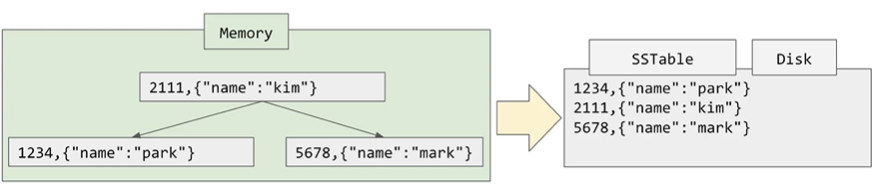
즉 데이터가 저장될때 binary tree라는 중간 저장 장치를 하나 더 둔셈이 됩니다.
하지만 만약 저장하는 중에 데이터베이스에서 crash가 발생하면?
지금 보시게 되면 Memtable이 메모리이므로 데이터베이스가 다운되면 메모리에 있는 데이터들이 모두 삭제되는가 아닌가 ? 하는 의문이 들 수 있습니다.
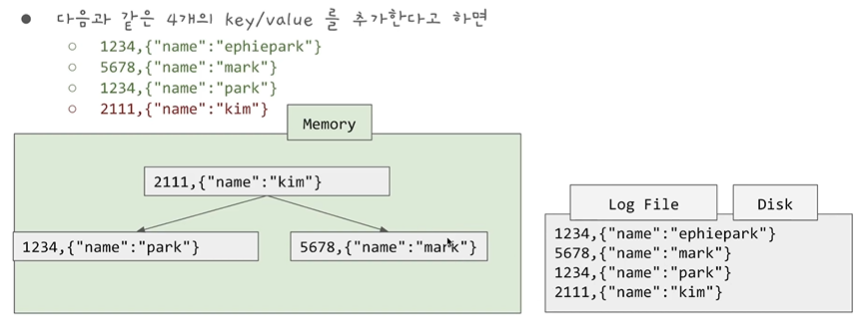
사실 Log file에 MemTable에 저장하기 전 아까 이전과 같이 Log 파일에 데이터를 유저가 입력한대로 저장을 해놓고 있습니다. 그러다가 MemTable을 통해 SSTable이 만들어지게 되면 그때 이 Log 파일들을 삭제하는 방식으로 해결할 수 있습니다.
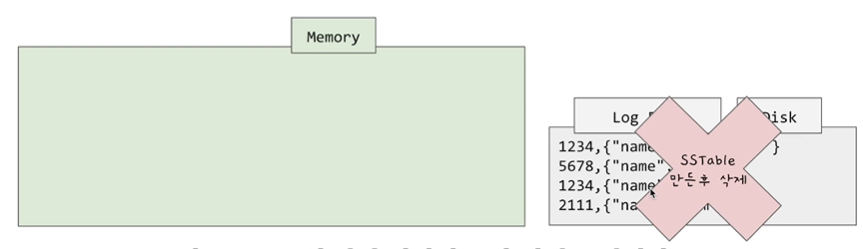
그러므로 만약 데이터베이스에 Crash가 발생하여 다운이 된다 하여도 이 Log 파일을 바탕으로 다시 Memtable을 만들 수 있습니다. 이 Log 파일은 유저가 입력한순서대로 저장되므로 write 속도도 빠릅니다. 그리고 한 번 저장된 SSTable은 Immutable 불변입니다.
그러면 LSM Tree 에서 Read 요청을 어떻게 해결할까요 ?
처음에는 MemTable에서 Key를 찾습니다. 그리고 SSTable로 가서 찾게 됩니다.
이렇게 할 수 도 있지만 read 퍼포먼스를 조금 더 높이기 위해 Sparse Index 를 사용할 수 있습니다.
LSM Tree Read / Sparse Index
아까와 Index의 형태가 비슷하다고 생각할 수 있는데 다른점이 있습니다.
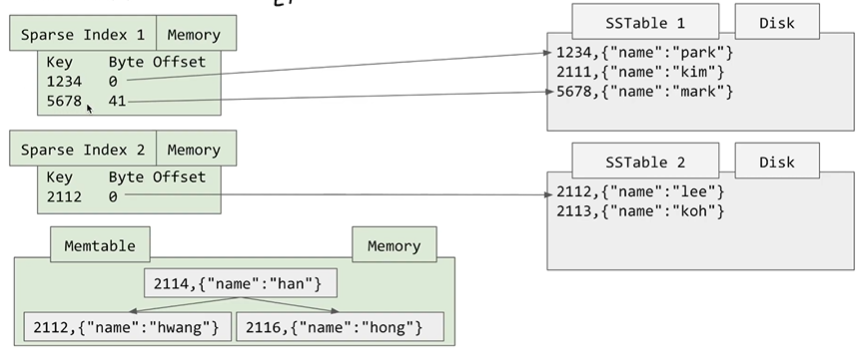
모든 Key에 대해 Index를 가질 필요가 없습니다. 왜냐하면 SSTable의 데이터들이 정렬되어있기 때문입니다.
예를 들어 2111에 대해 찾고싶다면 1234와 5678 사이에 2111가 있다는 것을 알고 있으므로 가장 가까이에 위치하는 Offset을 찾아서 그 사이에 대해서만 Scan을 하면 되므로 모든 Key를 저장하지 않아도 된다는 장점이 있습니다.
LSM Tree의 전체 구조는 다음과 같습니다.
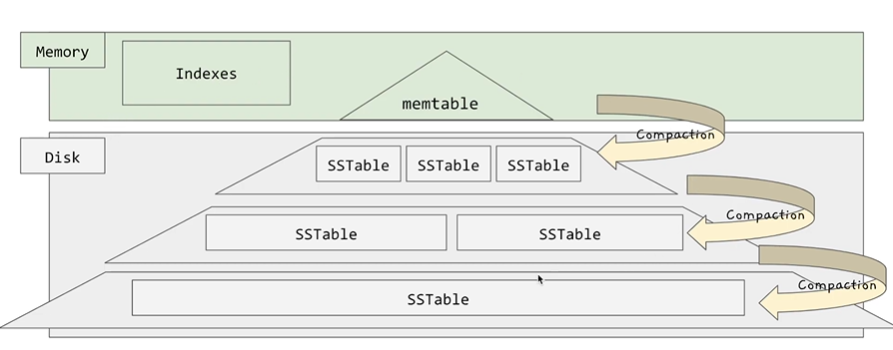
Memory에 Index들, Memtable이 저장되고 이를 Compaction하여 여러 SSTable들로 나뉘게 됩니다.
SSTable은 일정 사이즈가 되면 새로운 SSTable이 생겨나므로 데이터가 많아질 수 록 SSTable이 점점 많아지게 됩니다. 이렇게 되면 단점은 read할때 순차적으로 여러 Index들과 SSTable들을 읽어야 하므로 읽어야 하는 범위가 많아지게 됩니다.
그래서 가장 상위의 SSTable도 일정 개수가 차게 되면 Compaction을 통해 SSTable들을 또 다른 큰 SSTable로 묶어주는 것입니다. 이러한 과정을 반복하다보면 최종적으로 여러개의 레벨로 SSTable이 구성되게 됩니다.
LSM Tree 에 대한 정리
- Write이 빠릅니다. LSM Tree에서 write은 MemTable과 Log 파일에만 저장하면 되므로 빠릅니다.
- Index가 부분적으로 있어도 됩니다. (모든 Key가 있을 필요 없음)
- Range 쿼리가 가능함 (Disk(SSTable) 에 저장시 Memtable을 통해 SSTable에는 Sorted되어 저장되므로)
- SSTable들을 서로 Merge하기 쉽다. 이미 Sorted 되어 있으므로
- NoSQL 데이터베이스들이 쓰기 throughput(처리량) 이 높은 이유가 LSM Tree를 사용하기 때문
LSM Tree 에 대한 나의 생각
LSM Tree는 데이터 쓰기와 읽기에 대해 높은 처리량(Throughput)을 달성하기 위해 고안된 결과물이라고 생각합니다. 이를 위한 주요 조건은 다음과 같습니다:
- Append-only
- Range query
- Crash 발생 시 복구
Append-only와 MemTable
데이터 저장 속도를 높이기 위해 Append-only 방식으로 데이터를 저장해야 합니다. 이를 위해 데이터를 디스크에 바로 저장하지 않고, 중간 단계로 MemTable을 사용하여 메모리와 로그 파일에 데이터를 저장합니다. 이후 MemTable(메모리 내 이진 트리)이 일정 크기에 도달하면 SSTable로 변환하여 디스크에 저장합니다. 이 방식이 LSM Tree의 핵심이라고 생각합니다.
Range 쿼리와 Sparse Index
데이터를 빠르게 조회하기 위해서는 정렬된 상태로 저장되어야 하며, 이를 위해 MemTable에서 정렬 작업을 수행합니다. 또한, 복구를 위해 로그 파일을 저장하는 방식이 인상적이었습니다.
MemTable의 역할
만약 MemTable이라는 중간 단계가 없이 정렬되지 않은 상태로 데이터를 저장한다면, 저장 속도는 빠를 수 있지만, 인덱스를 찾지 못하는 경우 전체 스캔(Full Scan)이 발생하여 읽기 속도가 크게 저하될 것입니다. 따라서 정렬된 SSTable에 데이터를 저장하는 것은 필수적이며, MemTable이 이 요구사항을 해결해줍니다.
SSTable과 Compaction
SSTable의 계층 구조를 통해 읽기 요청 시 여러 개의 SSTable을 조회해야 하는 문제를 해결합니다. 여러 개의 SSTable을 다시 큰 SSTable로 병합(Compaction)하는 개념을 도입하여 효율적인 데이터 조회를 가능하게 합니다. 이 계층적 구조로 조회 문제를 해결하는 것이 인상적이었습니다.
LSM Tree를 사용하는 데이터베이스들의 종류
아래는 ChatGPT의 답변입니다.
NoSQL로 많이 사용하는 Redis나 MongoDB는 LSM Tree를 사용하지 않습니다.
Redis
Redis는 메모리 내 데이터 구조 저장소로, 다양한 데이터 구조를 효율적으로 관리하기 위해 여러 내부 구조를 사용합니다. 주요 구조는 다음과 같습니다:
기본 데이터 구조
- Redis는 문자열, 해시, 리스트, 셋, 정렬된 셋 등 다양한 기본 데이터 구조를 지원합니다. 이러한 데이터 구조는 모두 메모리 내에 저장되며, 매우 빠른 읽기/쓰기 성능을 제공합니다.
RDB와 AOF
- Redis는 영속성을 위해 두 가지 주요 메커니즘을 사용합니다: RDB (Redis Database) 스냅샷과 AOF (Append-Only File) 로그.
RDB: 주기적으로 메모리의 전체 데이터를 디스크에 스냅샷으로 저장합니다.
AOF: 모든 쓰기 명령을 순차적으로 파일에 기록하여 복구 시 이를 재생합니다.
Skip Lists와 Hash Tables
- Redis는 내부적으로 스킵 리스트와 해시 테이블을 사용하여 데이터 구조를 구현합니다.
예를 들어, 정렬된 셋(ZSET)은 스킵 리스트와 해시 테이블을 조합하여 구현됩니다.
MongoDB
MongoDB는 기본적으로 WiredTiger 저장 엔진을 사용하며, 이는 B-tree 기반의 구조를 사용합니다. 주요 특징은 다음과 같습니다:
B-tree
- WiredTiger는 데이터를 B-tree에 저장하여 빠른 읽기 및 쓰기 성능을 제공합니다. 인덱스는 기본적으로 B-tree 구조로 구현되어 있으며, 이는 효율적인 데이터 조회를 가능하게 합니다.
압축:
WiredTiger는 다양한 압축 기법을 제공하여 디스크 사용량을 줄이고 I/O 성능을 향상시킵니다. 이는 데이터베이스의 전체 성능을 최적화하는 데 도움이 됩니다.
동시성 제어
- WiredTiger는 다중 버전 동시성 제어(MVCC)를 사용하여 높은 동시성 처리를 지원합니다. 이를 통해 여러 쓰기 및 읽기 작업이 동시에 수행될 수 있습니다.
쓰기 버퍼링
- WiredTiger는 쓰기 작업을 메모리에 버퍼링하여 디스크로의 쓰기 작업을 배치 처리(batch processing)함으로써 성능을 최적화합니다. 이는 디스크 I/O 성능을 향상시킵니다.
요약
Redis
- 메모리 내 데이터 구조 저장소
- 문자열, 해시, 리스트, 셋, 정렬된 셋 등의 데이터 구조 지원
- 내부적으로 스킵 리스트와 해시 테이블 사용
- 영속성을 위해 RDB 스냅샷과 AOF 로그 사용
MongoDB
- 기본적으로 WiredTiger 저장 엔진 사용
- B-tree 기반의 인덱스 및 데이터 저장 구조
- 다중 버전 동시성 제어(MVCC)와 쓰기 버퍼링을 통한 성능 최적화
- 다양한 압축 기법 제공
LSM Tree
LSM Tree(Log-Structured Merge Tree) 구조를 사용하는 데이터베이스는 주로 쓰기 성능을 최적화하기 위해 설계되었습니다. 다음은 LSM Tree 구조를 사용하는 몇 가지 주요 데이터베이스입니다
Cassandra
Apache Cassandra
- LSM Tree 구조를 사용하여 고도의 쓰기 성능과 확장성을 제공합니다. 이는 특히 대규모 데이터 집합을 다룰 때 유리합니다.
HBase
- Apache HBase는 Hadoop 기반의 분산형 데이터 저장소로, LSM Tree 구조를 사용하여 빠른 쓰기 성능과 높은 확장성을 유지합니다. 이는 대규모 분산 데이터베이스 환경에서 매우 유용합니다.
RocksDB
- RocksDB는 Facebook에서 개발한 고성능 키-값 저장소로, LSM Tree를 사용하여 빠른 쓰기와 읽기 성능을 제공합니다. 이는 특히 SSD와 같은 고속 스토리지 장치에서 최적의 성능을 발휘합니다.
LevelDB
- Google에서 개발한 LevelDB는 LSM Tree 구조를 사용하는 키-값 저장소로, 빠른 쓰기와 읽기 성능을 제공합니다. 이는 다양한 응용 프로그램에서 사용됩니다.
