컴파일링
들어가기 전에
우리가 작성한 C 코드를 실행하기 위해서는 컴파일링을 해줘야 합니다. C문법로 작성된 텍스트 형식의 파일은 컴파일링시 구체적으로 어떤 단계를 거쳐서 컴퓨터가 해석 가능한 파일로 변환될까요?
학습 목표
컴파일링의 네 단계를 설명할 수 있습니다.
핵심 단어
- 컴파일링
- 어셈블링
- 링킹
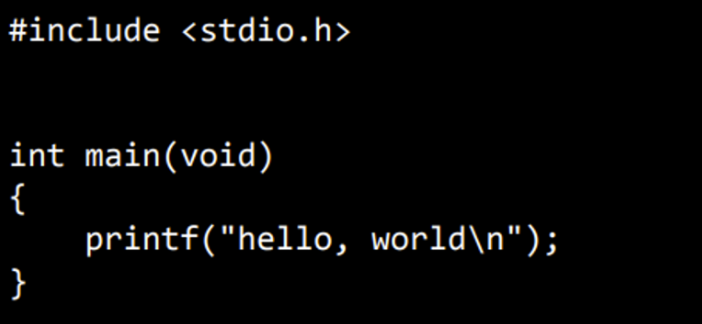
main함수 - 이 함수를 들어간다는 것은 프로그램 시작점으로써 스크래치의 실행 버튼을 클릭하는 것과 같습니다.
printf 함수를 사용하려면 stdio.h 라이브러리가 필요합니다. 다시 정확히 말하면 stdio.h는 헤더 파일로 c 언어로 작성되어있으며 파일명이 .h로 끝나는 파일입니다.
이전에 배운 명령어 중 make hello 명령어는 컴파일 과정을 자동으로 처리해주는 것으로 아래 네 단계를 거칩니다.
preprocessing, compiling, assembling, linking
precompile(preprocessing)전처리는 예를들어 #include와 같은 줄을 포함하면 전처리기는 새로운 파일을 생성하는데 이 파일은 c코드 형태이며 stdio.h 파일의 내용이 #include 부분에 포함된다고 합니다.
compile 컴파일은 c언어의 코드를 어셈블리라는 아주 저 수준의 프로그래밍 언어로 바꿔주는 것입니다. 어셈블리란 c보다 연산의 종류는 적지만 이 연산들을 함께 사용하여 c에서 동작하는 것들을 수행하도록 합니다. 어셈블로코드로 변환시켜줌으로써 컴퓨터가 이해할 수 있는 언어와 최대한 가까운 프로그램으로 만들어 줍니다.
assemble 어셈블은 어셈블리 코드를 오브젝트 코드로 변환시키는 것입니다. 즉 컴퓨터cpu가 이해할 수 있는 연속된 0과 1들로 바꿔주는 것을 의미합니다.
link 링크는 프로그램은 하나의 파일로만 이루어질 수 없기때문에 (cs50.h math.h)여러개의 파일로 이루어지므로 하나의 오브젝트 파일로 합쳐야 합니다. 이 합치는 과정을 링크라고 합니다.
이 네 단계를 거치면 최종적으로 cpu가 이해할 수 있는실행 가능한 하나의 파일이 완성되며 이를 컴파일이 완료되었다고 합니다.
디버깅
들어가기 전에
우리가 소스코드를 작성하다보면, 때때로 우리 의도와는 다른 오류나 결과를 맞닥뜨리게 됩니다. 이를 “버그”라고 하는데요, 버그를 효과적으로 찾고 해결하는 방법에 대해 알아 보겠습니다.
학습 목표
디버깅 하는 여러 방법을 설명할 수 있습니다.
핵심 단어
- 디버깅
- help50
- debug50
버그는 코드에 들어있는 오류로 프로그램의 실행에 실패하거나 원하는 대로 동작하지 않는것을 의미합니다.
디버깅은 코드에 있는 버그를 찾아내고 고치는 과정입니다.
디버깅은 break point(중지점,프로그램이 멈추는 특정)을 통해 원하는 지점에서 멈춘 후 그 지점 이후에서 어떤 일이 일어나는지 단계별로 볼 수 있습니다.
#include <stdio.h>
int main(void)
{
for(int i=0; i<=10; i++) #breakpoint
{
printf("i is now %i:", i);
printf("#\n");
}
}break point를 line 5에 줌으로써 이 지점부터 어떤 일이 일어나는지를 단계별로 볼 수 있습니다.
ide cs 50 디버거를 이용할때는 debug50 ./debuggy1 을 통해 실행할 수 있습니다.
코드의 디자인
들어가기 전에
규모가 큰 프로그램을 작성할 때는 보통 한 사람이 아닌 여러 사람들이 함께 작업을 진행하게 됩니다. 이 때는 내가 기여한 부분이 프로그램에 오류를 발생시키지 않도록 주의를 기울여야 합니다. 또한 코드의 내용 뿐만 아니라 그 형식도 신경써야 합니다. 같은 내용이라 하더라도 어떻게 표현하느냐에 따라 코드를 이해하고 수정하는 속도가 달라질 수 있기 때문입니다. 코드의 정확성과 디자인을 어떻게 잘 관리할 수 있을지 배워봅니다.
학습 목표
코드의 정확성과 디자인을 관리하는 방법을 설명할 수 있습니다.
핵심 단어
- check50
- sytle50
- 고무 오리
배열
들어가기 전에
우리가 특정 자료형의 변수를 선언하면 이는 메모리상 어딘가에 특정 크기만큼의 자리를 차지하게 됩니다. 만약 비슷한 종류의 값을 모아서 저장하고 싶다면 어떻게 해야 할까요? 메모리상에서 여러 값을 연이어서 저장하고 사용하는 방법과 그 이점을 알아보겠습니다.
학습 목표
배열을 정의하고 사용하는 방법을 설명할 수 있습니다
핵심 단어
- 배열
메모리
c는 여러 자료형이 있으며 각각 다른 크기의 메모리공간을 차지합니다.
bool: 불리언 1바이트
char: 문자, 1바이트
int: 정수, 4바이트
float: 실수, 4바이트
long:(더큰)정수, 8바이트
double:(더큰)실수, 8바이트
string:문자열, ?바이트
컴퓨터에는 RAM 이라는 메모리가 있으며 물리적인 공간을 의미합니다. 아래 사진에서 노란색 사각형들이 메모리 역할을 하고 이 작은것들이 모여 우리가 알고있는 큰 공간의 메모리를 의미합니다.

예를들어 char 타입의 변수를 하나 생성하고, 그 값을 입력한다고 하면 위 사진에서 한 사각형 안에 그 변수의 값이 저장되는 것입니다.
배열
아래와 같이 세 개의 정수를 저장하고 출력한다고 하였을때 발생하는 일들을 살펴보겠습니다.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
// Scores
int score1 = 72;
int score2 = 73;
int score3 = 33;
// Print average
printf("Average: %i\n", (score1 + score2 + score3) / 3);
}위의 경우 3개의 변수를 코드 작성하기 전에 이미 알고 있었고 변수의 수가 적으므로 int score1 = 33; 와 같이 쓸 수 있지만 변수가 늘어난다면 매번 이렇게 작성할 수 없을 것이다. 그러므로 여기서 배열이라는 개념을 사용할 수 있다.
#include <cs50.h>
#include <stdio.h>
int main(void)
{
// Scores
int scores[3];
scores[0] = 72;
scores[1] = 73;
scores[2] = 33;
// Print averageint scores[3]; 이라는 코드는 int자료형을 가지는 크기 3의 배열을 scores라는 이름으로 생성하겠다는 의미입니다. 하지만 위와 같은 코드는 여전히 점수의 개수가 바뀌는 상황에서 제약이 많습니다.
들어가기 전에
우리가 특정 자료형의 변수를 선언하면 이는 메모리상 어딘가에 특정 크기만큼의 자리를 차지하게 됩니다. 만약 비슷한 종류의 값을 모아서 저장하고 싶다면 어떻게 해야 할까요? 메모리상에서 여러 값을 연이어서 저장하고 사용하는 방법과 그 이점을 알아보겠습니다.
학습 목표
배열을 정의하고 사용하는 방법을 설명할 수 있습니다.
핵심 단어
- 배열
- 전역 변수
전역변수
만약 아래 코드에서 scores 배열의 크기를 정해주는 N이라는 변수를 새로 선언하였습니다.
만약 N이 고정된 값(상수)라면 그 값을 선언할 때 const를 앞에 붙여 상수임을 알게 할 수 있으며 동시에 main위에 작성하였으므로 전역 변수라고 지정해줄 수 있습니다.
관례적으로 이런 전역 변수의 이름은 대문자로 표기합니다.
#include <cs50.h>
#include <stdio.h>
const int N = 3;
int main(void)
{
// 점수 배열 선언 및 값 저장
int scores[N];
scores[0] = 72;
scores[1] = 73;
scores[2] = 33;
// 평균 점수 출력
printf("Average: %i\n", (scores[0] + scores[1] + scores[2]) / N);
}하지만 여전히 배열의 인덱스-위치 마다 점수를 지정해줘야 하는 불편함이 있습니다. 이를 사용자로부터 값을 받아와 메모리에 값을 크기에 맞게 할당해주는 프로그램을 작성해보겠습니다.
#include <stdio.h>
#include <cs50.h>
float average(int length, int array[]);
int main(void)
{
int n = get_int("Number of scores: ");
int scores[n];
for(int i = 0; i<n; i++)
{
scores[i] = get_int("Score%i : ", i+1);
}
printf("Average: %.1f\n", average(n, scores));
}
float average(int length, int array[])
{
int sum = 0;
for(int i = 0; i<length; i++)
{
sum += array[i];
}
return (float) sum / (float) length;
}위 코드에서 배열의 크기를 사용자에게 직접 받고 배열의 크기만큼 루프를 돌면서 각 인덱스에 해당값을 사용자에게 동적으로 입력받아 저장합니다.
그리고 average 라는 함수를 따로 선언하여 평균을 구합니다.
average 함수는 length 와 array[], 즉 배열의 길이와 배열을 입력으로 받습니다. 함수 안에서는 배열의 길이만큼 루프를 돌면서 값의 합을 구하고 최종적으로 평균값을 반환합니다.
문자열과 배열
들어가기 전에
우리는 여태껏 문자열을 저장하기 위해 string 자료형을 사용하였습니다. ‘문자열’이라는 단어는 다시 말해 문자가 ‘나열되어 있다’ 또는 ‘배열되어 있다’ 라는의미로 추측해 볼 수 있습니다. 이런 관점에서 봤을 때 string 자료형은 C에서 정확히 어떻게 정의되어 있을까요? 배열이라는 개념이 문자열과 어떻게 연결되는지 알아보도록 하겠습니다.
학습 목표
문자열이 C에서 정의되는 방식과 메모리에 저장되는 방식을 설명할 수 있습니다.
핵심 단어
- 문자
- 문자열
문자열은 크기가 정해져있지 않습니다. 따라서 매번 직접 입력하지 않아도 되며 컴퓨터는 이를 \0을 통해 문자열의 끝을 표시해줍니다.
\0이 매번 문자열에 저장됨으로써 “EMMA”라는 문자열은 5bytes라는 크기를 가지게 됩니다.
#include <stdio.h>
#include <cs50.h>
int main(void)
{
string names[4];
names[0] = "EMMA";
names[1] = "RODRIGO";
names[2] = "BRIAN";
names[3] = "GALAXY";
printf("%s\n", names[0]);
printf("%c%c%c%c", names[0][0], names[0][1], names[0][2], names[0][3]);
}위 코드를 통해 문자열을 인덱싱할 수 있습니다.
첫번째 printf는 문자열 string이며 두번째 printf는 character 로 볼 수 있습니다
문자열의 활용
들어가기 전에
여태까지의 강의에서 문자열의 기본적인 개념들을 학습하였습니다. 이번 강의에서는 문자열을 좀 더 깊이 활용하는 방법을 배워보겠습니다. 문자열 안에 포함되어 있는 문자를 검색하기 위해서는 어떻게 해야 할까요? 또 특정 문자를 다른 문자로 바꾸기 위해서는 어떻게 해야 할까요? 이런 질문들에 답해보도록 하겠습니다.
학습 목표
문자열을 탐색하고 일부 문자를 수정하는 코드를 구현할 수 있습니다.
핵심 단어
- strlen
- toupper
문자열의 길이 탐색
사용자로부터 문자열을 입력받아 한 글자씩 출력하는 프로그램을 만들어 보았습니다. 이때 인덱스를 하나씩 증가시키면서 해당하는 문자를 출력하면 되지만 문자열의 끝은 어떻게 알 수 있을까요 ?
한가지 방법은 인덱스의 문자가 널 종단 문자, ‘\0’와 일치하는지 검사하는 것 입니다.
즉 for(int i = 0; s[i] != ‘\0’; i++){…} 와 같은 루프를 사용하면 됩니다
하지만 아래 코드와 같이 strlen()이라는 함수를 사용할 수 도 있습니다.
#include <cs50.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
string s = get_string("Before: ");
printf("After: ");
for (int i = 0, n = strlen(s); i < n; i++)
{
if (s[i] >= 'a' && s[i] <= 'z')
{
printf("%c", s[i] - 32);
}
else
{
printf("%c", s[i]);
}
}
printf("\n");
}말 그대로 32를 매번 빼주어 소문자와 대문자를 일치시키는 코드입니다.
이와 동일한 작업을 수행하는 ctype 라이브러리에 toupper() 함수가 정의되어있습니다. 이를 사용하면 아래와 같습니다.
#include <cs50.h>
#include <ctype.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
string s = get_string("Before: ");
printf("After: ");
for (int i = 0, n = strlen(s); i < n; i++)
{
printf("%c", toupper(s[i]));
}
printf("\n");
}명령행 인자
들어가기 전에
make나 clang과 같은 프로그램을 실행할 때 컴파일하고자 하는 코드 외에도 컴파일 후 저장하고자 하는 파일명과 같이 추가적인 정보를 함께 줄 수도 있습니다. 이런 정보들을 명령행 인자 라고 부릅니다. 우리가 작성하는 프로그램에서도 명령행 인자를 받을 수 있도록 설계할 수 있습니다.
학습 목표
명령행 인자를 받는 프로그램을 C로 작성할 수 있습니다.
핵심 단어
- 명령행 인자
- argv
- argc
항상 int main(void) 와 같이 기계적으로 void로 입력하는 대신에 아래와 같이 argc, argv로 정의해보겠습니다
#include <cs50.h>
#include <stdio.h>
int main(int argc, string argv[])
{
if(argc == 2)
{
printf("hello, %s\n", argv[1]);
}
else
{
printf("hello, world\n");
}
}이렇게 되면 인자를 입력받는것에 따라 main 함수의 결과를 어떻게 출력할 것 인지가 결정됩니다.
함수인자를 입력하는 방법은 실행시 뒤에 작성 ./argv jonghun 하면 됩니다.
여기서 첫번째 변수 argc는 main함수가 받게 될 입력의 개수입니다.
argv[] 는 그 입력이 포함되어있는 배열이며 argv[]는 배열이 됩니다.
argv[0]는 기본적으로 프로그램의 이름이 저장됩니다.
만약 추가의 입력이 주어진다면 argv[1], 2, 등등 순차적으로 저장될 것입니다.
이러한 입력들을 인자라고 하며 출력시 hello, jonghun이 됩니다.
이는 인자에 jonghun라는 값이 추가로 입력되었고, 따라서 argc 는 2, argv[1] 은 “jonghun”가 되기 때문입니다.
