
이번시간에는 인덱스에 관련된 강의 내용을 정리하며 인덱스가 무엇이며 어떤 특징과 동작을 하는지에 대해 자세하게 알아보았습니다
[SQL Unplugged 2013] 쉽고 재미있는 인덱스 이야기/ 씨퀄로 이장래
다룰 내용
- 기본 용어 및 약속
- 시작하는 이야기
- 순수, 그대로의 이야기
- 부자 인덱스 이야기 (클러스터형 인덱스)
- 가난한 인덱스 이야기 (비 클러스터형 인덱스)
- 정리
기본 용어 및 약속
데이터베이스와 테이블
데이터베이스
- 데이터파일과 로그 파일로 구성 됨
- 데이터 파일 mdf, ndf 확장자
- 로그 파일 Idf 확장자
- 다양항 형태의 개체들을 포함
테이블
- 데이터베이스 내에 존재하는 대표적인 개체
- 시스템 테이블 & 사용자 테이블
- 실제 데이터를 물리적으로 포함하고 있음
- 행(rows) 과 열(Columns)로 구성됨
데이터베이스는 데이터의 집합체이며 그 데이터를 관리하기 위해 로그들로 구성되어있다
데이터베이스에 포함되어 있는 개체
- 테이블
- 인덱스
- 뷰
- 프로시져
- 함수 등등
테이블은 데이터베이스의 작은 단위이며 테이블 또한 데이터들의 집합
Query SELECT 문을 날리면 이 Query는 어디로 날아갈까
- 테이블 ? → 아님 이번 인덱스를 보게되면 이 생각이 바뀌게 됨
- 정답
- 테이블로 날리면 안됨, 날릴수는 있지만 쿼리를 테이블로 날린다는 것은 전체를 다 탐색한다는 의미임 그만큼 시간이 많이 소요되므로 비효율적
- 쿼리는 인덱스로 날려야 함, 인덱스로 날려서 탐색범위를 최대한 줄여 빠르게 조회하여야 함
- 정답
- 페이지의 8KB 안에 INSERT한 레코드가 기록이 되고 우리가 데이터를 SELECT 할때 이 페이지의 RECORD가 SELECT되는 것임
페이지
- 데이터 파일을 구성하는 논리 단위
- SQL Server의 기본 데이터 저장단위 (8KB - 고정된 사이즈)
- 데이터를 쓸 때 행은 페이지에 기록됨
- 데이터를 읽을 때 페이지 내의 모든 행이 읽혀짐
- 페이지 내의 행이 많을 수록 I/O 효율 증가
- 0 - n 사이의 순차적인 번호 → 페이지 번호
테이블에 데이터를 INSERT하게 되면 INSERT가 된 RECORD는 해당 행, 페이지에 기록이 됨
페이지의 8KB 안에 INSERT한 레코드가 기록이 되고 우리가 데이터를 SELECT 할때 이 페이지의 RECORD가 SELECT되는 것임
만약 8KB안에 고정된 사이즈에 10개의 레코드가 들어가 있으면 ?
- 해당 페이지를 읽을때 10개를 읽는 것임
만약 100개의 레코드가 들어가 있으면 ?
- 한번 읽을때 100개를 읽는 것임
즉, 한개의 페이지내에 레코드가 많을 수록 I/O 효율이 증가한다는 의미가 이 의미
1개의 페이지 내에 100개의 레코드 VS 10개의 각 페이지 내에 10개의 레코드
위 둘 중 어떤것이 더 효율적일까 ?
- 페이지 내 레코드가 많으면 많을수록 한 번에 읽을 수 있는 양이 늘어난다는 의미이므로 100개의 레코드가 있는 것이 더 좋다
이 내용이 성능(performance)의 시작임
SELECT 시 최소의 페이지를 SELECT 할때 효율이 좋아지고 성능이 좋아짐
많고 많은 알고리즘이 결국 이 페이지 검색을 최소화 하기 위함 - 탐색 범위를 줄인다
1개의 페이지를 조회하는 시간은 하드웨어적으로 정해져있고 소프트웨어로 조회할 페이지를 최소화하는것이 개발자가 해야할 일 같다
페이지는 번호를 가지고 있음 0-N , 페이지 번호는 순차적임

이제 중요한 인덱스에 대해 알아보자
인덱스가 뭘까 ???
이렇게 가정을 해보겠다
나는 축구를 좋아하니 아스널 VS 맨시티 빅매치에서 경기장에 시작도 전에 사람들이 모두 경기를 관람하기 위해 좌석에 앉아있는 상황이다
이때 경기장에서 이종훈을 찾아야 한다면 …?
혼자 찾을 생각에, 경기장을 전부 뒤져볼 생각에 막막하던 찰나
경비아저씨께 여쭤보았다
그랬더니 기적이 ?
D열 14번 좌석에 있단다
경비아저씨의 이름은 ??
인덱스
인덱스
인덱스는 —- 이다
- 인덱스는 주민센터다
- 인덱스는 도서 검색 시스템이다
- 인덱스는 다리다
빨리빨리
인덱스 장점
- 빠른 데이터 검색
- 찾는 데이터를 가지고 있다면 직접 전달
- 없다면 어디 있는지 알려 줌
- 데이터 중복 방지
- PK 제약
- UNIQUE 제약
- 잠금 최소화
- 최소 범위의 잠금을 가능하게 해줌
- 동시성을 높여줌
인덱스의 단점
- 물리적인 공간 차지
- 인덱스는 테이블처럼 데이터를 가짐
- 테이블처럼 물리적인 공간을 차지
- 인덱스에 대한 유지 관리 부담
- SELECT문은 인덱스를 좋아함
- INSERT문은 인덱스를 별로 좋아하지 않음
- 데이터가 극히 적다면
- 인덱스가 있어도 사용되지 않을 수 있음
이유는 ?
인덱스도 페이지를 가지고 있음
데이터 베이스에서 페이지를 가지고 있는 개체는 딱 2가지
- 테이블
- 인덱스
결국 디스크의 물리적인 공간을 차지 하는 것은 2가지 밖에 없음
- 테이블
- 인덱스
뷰에는 사이즈가 없음
뷰는 테이블에 저장되어 있음
인덱스 유지 관리의 필요성
- 인덱스는 전지전능하지 못함
- 인덱스 조각화 문제 해결 필요
- 내부 조각화
- 외부 조각화
- 인덱스 유지 관리 자동화
인덱스를 이해하자!!
만약 내가 인턴을 한다면 회사 내 데이터베이스의 테이블이 몇개일까 ?
수백개 수천개일 것이다
그리고 이들은 둘중에 하나의 형태를 띈다
힙의 형태 VS 클러스터형 인덱스
힙은 데이터를 가지고 있는 테이블이다
SELECT를 할때 누군가가 도와줘야한다
- 축구장 경비아저씨처럼
도와주는 사람이 비 클러스터형 인덱스
클러스터형 인덱스(Clustered Index)
- 테이블당 한 개만 생성이 가능
- 행 데이터를 인덱스로 지정한 열에 맞춰서 자동 정렬
- 영어 사전처럼 책의 내용 자체가 순서대로 정렬이 되어 있어, 인덱스 자체가 책의 내용과 같음
비 클러스터형 인덱스(Nonclustered Index)
- 테이블당 여러 개를 생성할 수 있다
- 비클러스터형 인덱스는 그냥 찾아보기가 있는 일반 책과 같다
인덱스 생성
- 인덱스는 열 단위로 생성된다
- 하나의 열에 인덱스를 생성할 수 있고, 여러 열에 하나의 인덱스를 생성할 수 있다
- 테이블 생성시 하나의 열에 Primary Key를 지정하면 자동으로 클러스터형 인덱스가 생성된다
- 제약조건 없이 테이블 생성시 인덱스를 만들 수 없으며, 인덱스가 자동 생성되기 위한 열의 제약조건은 Primary Key 혹은 Unique 뿐이다
빨간 화살표는 정렬의 의미임
테이블에다가 인덱스를 추가하는 것임
비 클러스터형 인덱스는 최대 999개 까지 가능함
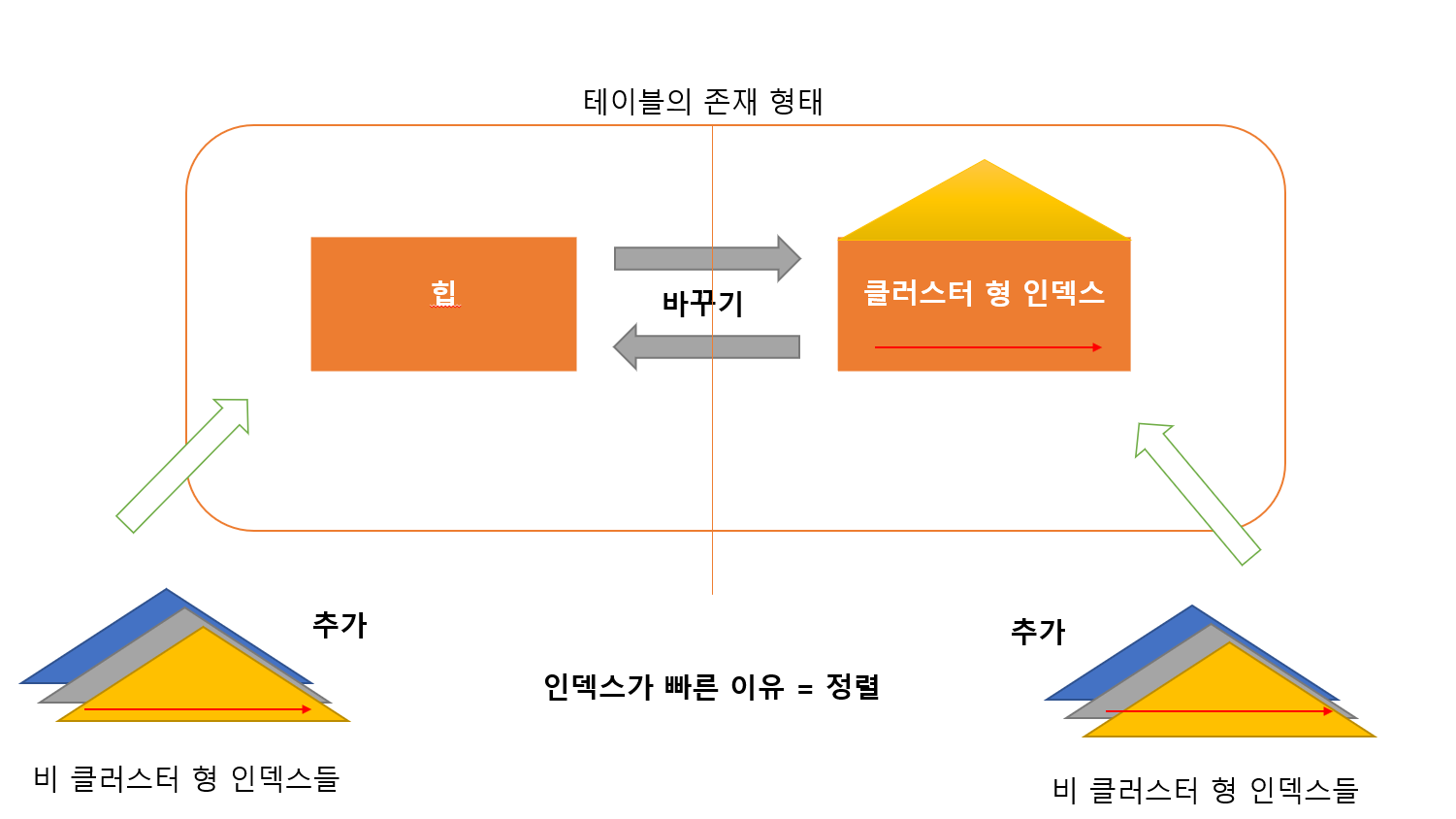
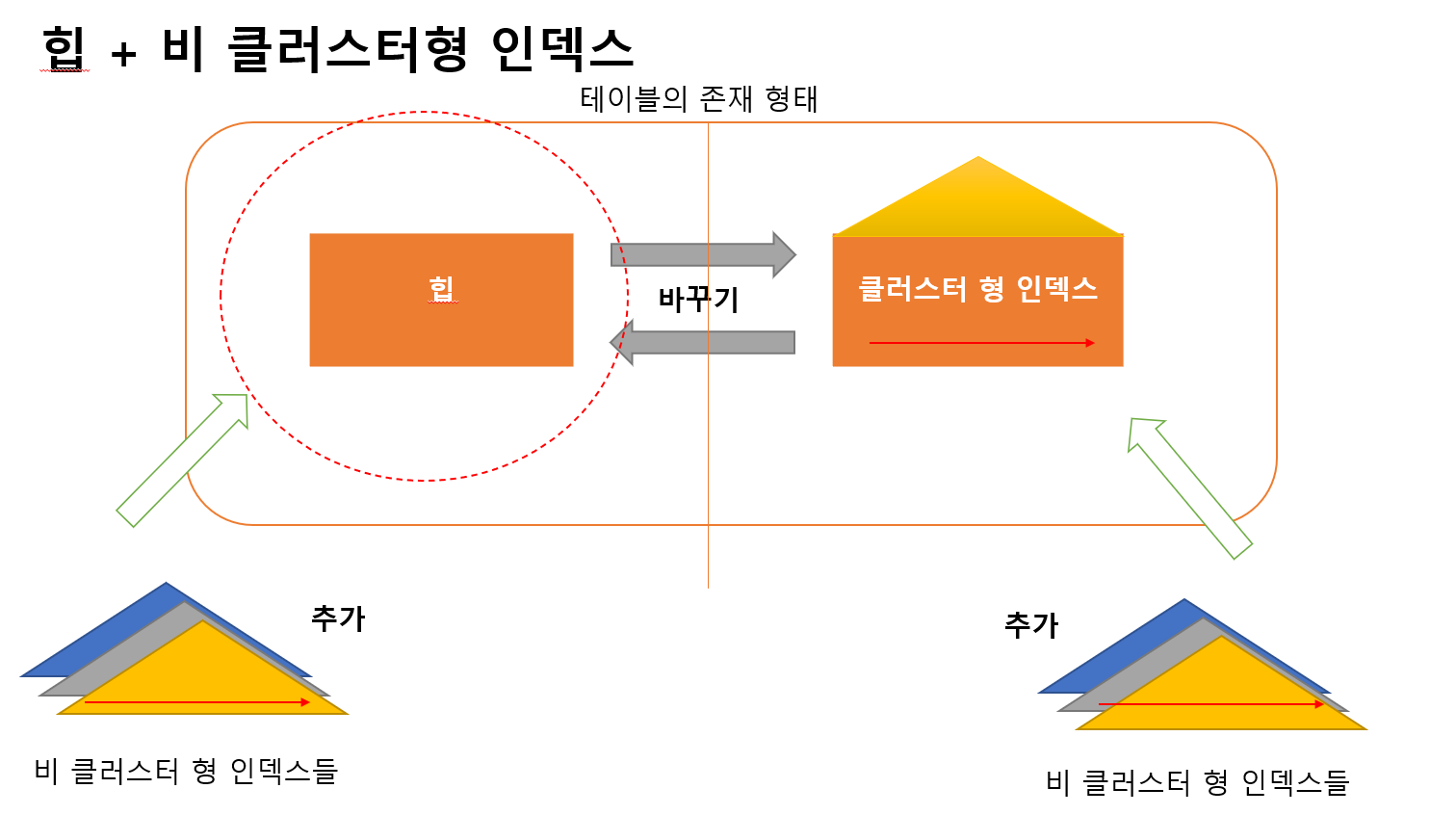
힙
힙은 정렬의 기준 없이 저장 된 테이블의 존재 형태
- 데이터 페이지 내의 행들 간에 순서가 없음
- 데이터 페이지들 간에도 순서가 없음
클러스터 형 인덱스가 없는 테이블

힙의 장점과 단점
INSERT문이 좋아하는 테이블의 형태
- 새로운 행을 기존 페이지의 빈 곳에 추가하면 됨
- 빈 공간이 없으면 새로운 페이지에 추가하면 됨
SELECT문이 싫어하는 테이블 형태
- 데이터가 극히 적으면 상관이 없음
- 데이터가 많으면 원하는 데이터 찾기가 너무 힘듦
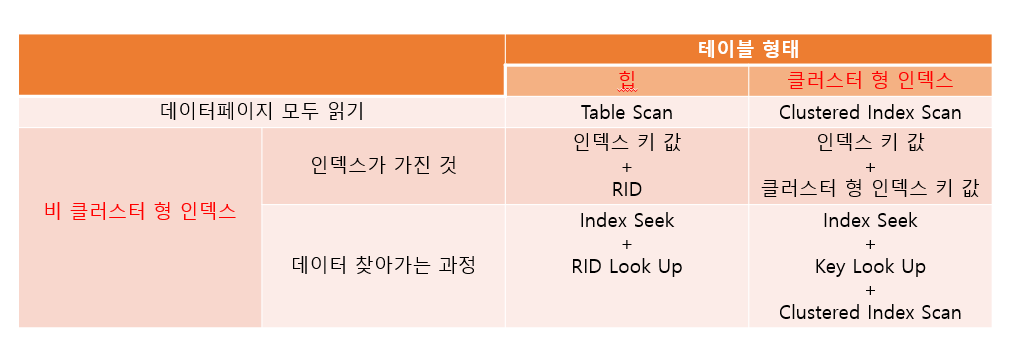
TABLE SCAN
- 힙에서 데이터를 찾을 수 있는 유일한 방법
- 모든 데이터 페이지를 다 읽어야 함
- SCAN - 전부 ~~ 쫙 ~
즉, 힙을 관리를 해줘야 함
누가 좀 도와주세요
- 대부분의 쿼리문은 SELECT 문임
- 대량의 데이터에 대한 검색 시 도움이 필요
- 도움이 없으면 세월아 네월아
- 결국 성능 저하 및 잠금의 원인이 됨
- 데이터의 존재 형태를 바꾸든지
- 데이터가 어디 있나 알려주든지 해야 함
클러스터 형 인덱스
부자 인덱스 이야기
클러스터 형 인덱스
부자인 이유 - 데이터를 가지고 있기 때문
힙 → 클러스터형 인덱스
로 형태를 바꿔버리자!
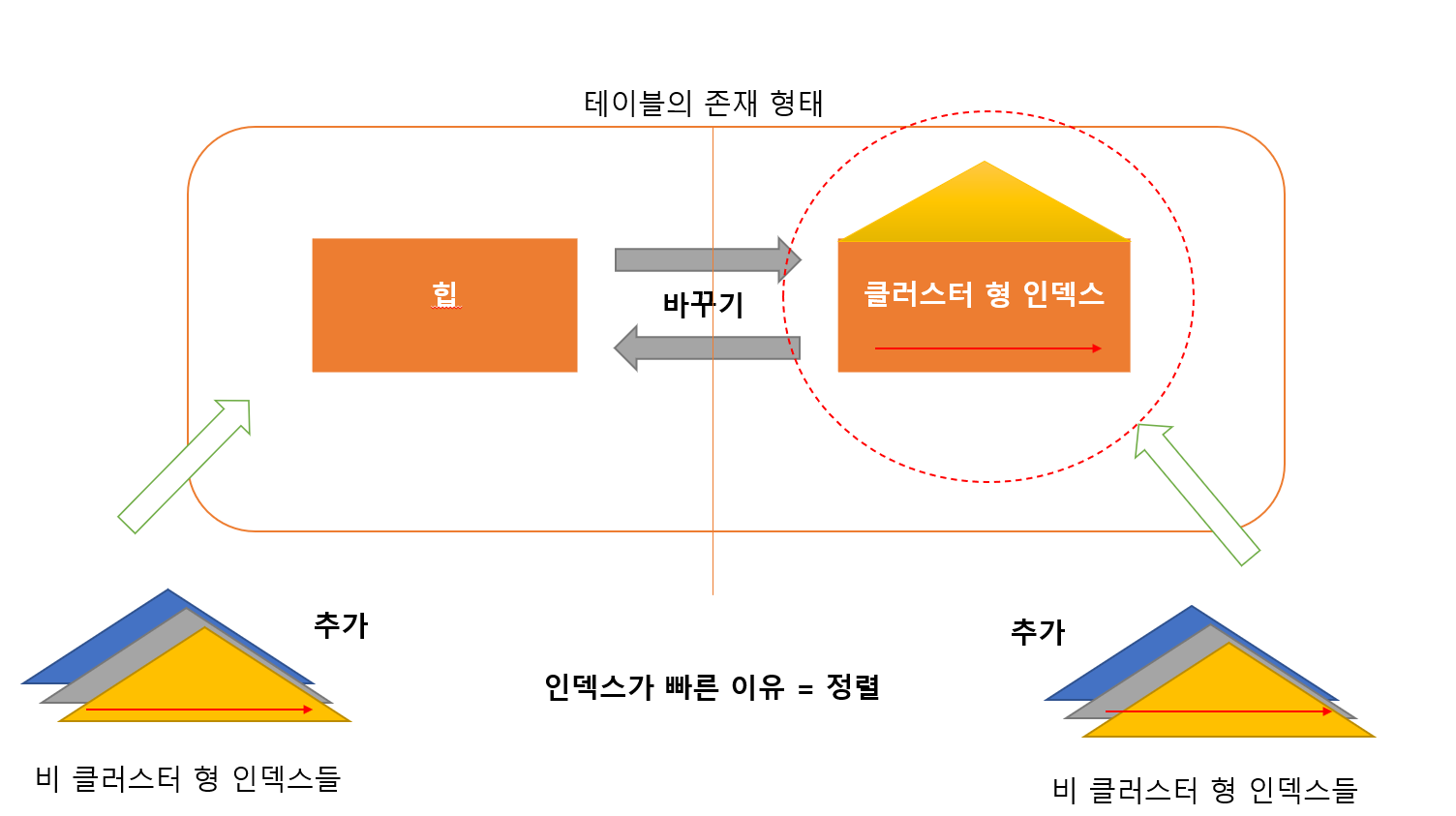
클러스터 형 인덱스란
- 특정 열을 기준으로 데이터가 정렬 됨
- 물리적 정렬
- 정렬 기준의 열로 찾는데 빠른 성능을 보여줌
- 테이블 당 하나의 클러스터 형 인덱스 설정 가능
- 실제 데이터를 가지므로 하나만 존재
- 테이블을 여러개 만들면 여러개 존재 가능
클러스터형 인덱스가 정말 강력한 이유
- 정렬되있음
- 데이터를 가지고 있음
힙 테이블들을 클러스터 형 인덱스로 바꾼다면 ?
그러면 SQL 서버는 힙 데이터들을 다 없애고 다른 공간에 새로운 데이터를 만듦
클러스터가 다른곳에 만들어짐
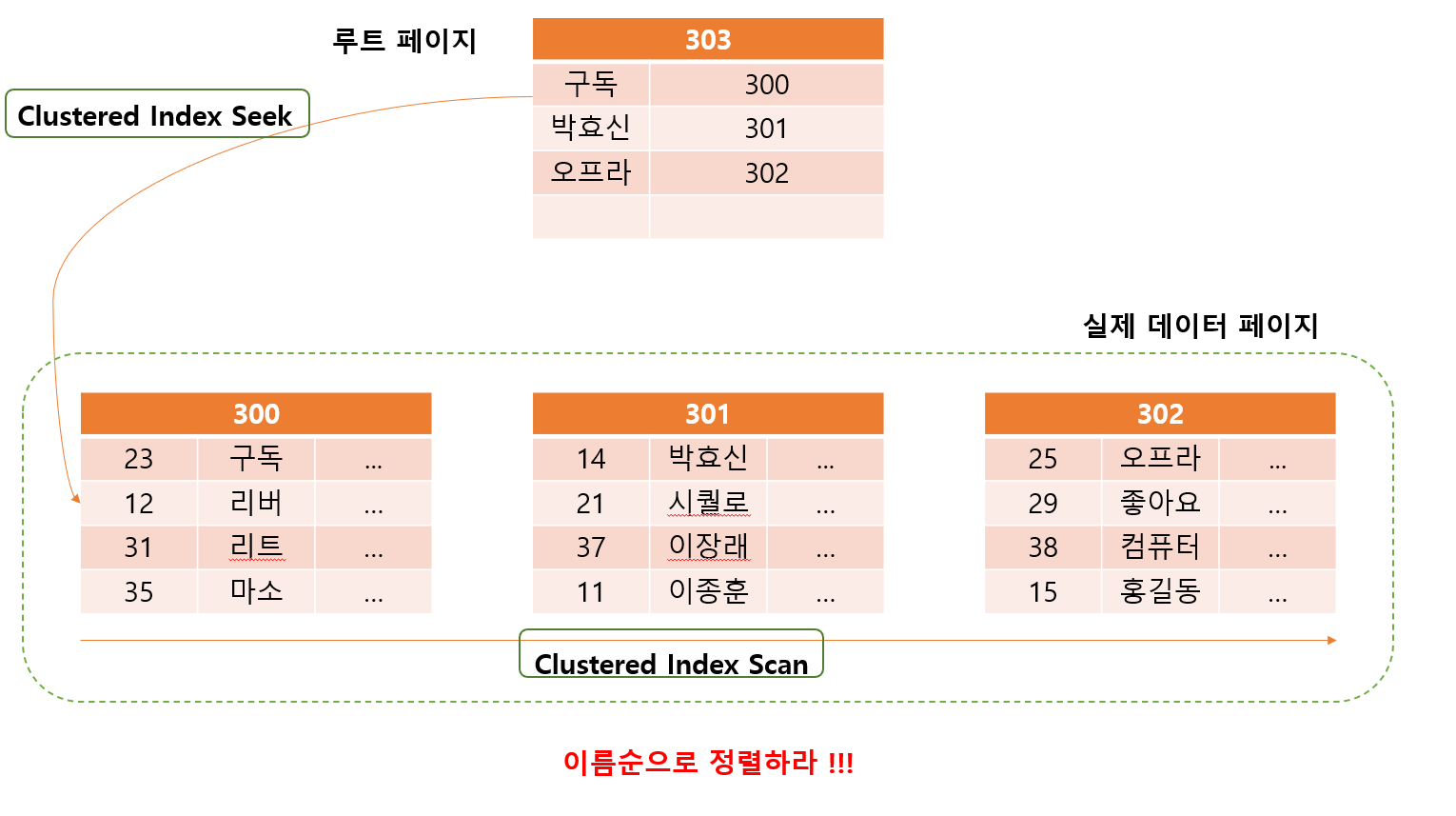
힙 테이블을 이름 컬럼 기준으로 클러스터형 인덱스로 바꾼다면 ?
아래와 같이 바뀜
리버를 찾는다면 ?
Clustered Index Seek가 발생하면서 바로 찾아낼 수 있음
테이블 존재 형태의 문제
힙 테이블 VS 클러스터형 테이블
회사에 100개 테이블 중
70개 테이블이 힙형태이고 30개가 클러스터형 인덱스 테이블이라면 ?
이유가 있다면 좋겠지만 그게 아니라면 고민을 해봐야 함
만약 변경 비용이 많이 들더라도 이후의 SELECT를 위해서는 변경해야할 수도 있음
절반은 힙, 절반은 클러스터인 형태의 테이블들을 없음
둘중 하나만을 선택해야함 - 이유가 뭘까 ?
- 인덱스로 찾는것 Clustered Index Seek
- 힙을 다 스캔하는 것은 Full Table Scan
- 클러스터를 다 스캔하는 것은 Clustered Index Scan
SCAN은 같은 것, 결국 다 읽는 것
좋은 것은 Seek임
Clustered Index Seek
- Root 페이지 부터 찾아가기
- 아주 빠른 성능을 보여줌
- 정렬되어 있기 때문에 루트페이지부터 바로 찾아갈 수 있음
Clustered Index Scan
- 모든 데이터 페이지를 쫙 읽음
- Table Scan과 크게 다를 바가 없음
- 데이터가 많은 경우 성능 문제 발생
Seek 딱 / Scan : 쫙~~
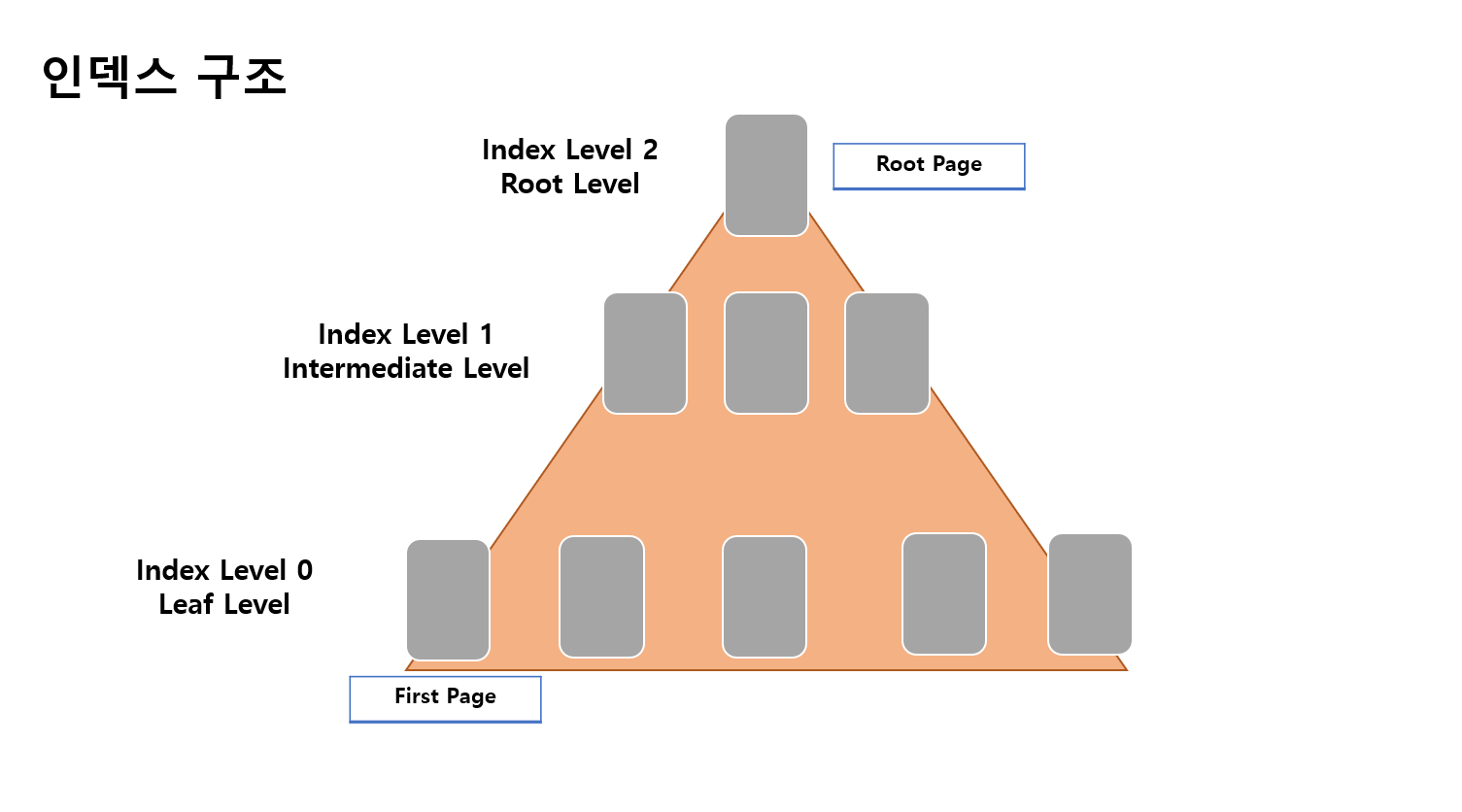
참고 : 인덱스 구조
인덱스는 아래처럼 트리 형태의 구조를 가지고 있다
삼각형의 끝을 루트페이지 아래를 리프 페이지라 부른다
클러스터 형 인덱스의 유일성(UNIQUE) 지정
UNIQUE CLUSTERED INDEX
- 인덱스 키 열에 중복된 데이터가 추가 되는 것을 차단함
UNIQUE 여부를 명확히 설정
- 인덱스 키 열의 유일성을 우리가 아는것이 중요한게 아님
- SQL Server 가 아는 것이 중요함
- 왜냐하면 우리가 데이터를 관리하는 것이 아니고 서버가 관리하기 때문
만약 인덱스를 만들때 중복된 값을 신경쓰지 않고 UNIQUE를 주지 않으면
클러스터는 내부적으로 데이터를 정렬해야 하므로 유일성 확보하기 위한 값들을 할당함 = 공간 낭비
예를 들어 동일한 테이블 두개를 만들때 1번은 클러스터형 테이블을 만들고 2번은 클러스터형 UNIQUE 를 만든다면
두 테이블의 사이즈가 다르다
UNIQUE를 안다면 UNIQUE 속성을 부여하자 !!
클러스터형 인덱스는 만능이 아님
- 인명 전화번호부에서 공릉동 주민을 찾으려면 ?
- 전화번호부는 주소지로 정렬이 된 것이 아니므로 처음부터 끝까지 다 찾아야 함
- A(전화번호)열을 기준으로 정렬된 데이터에서
- A로만 찾으면 날라다님
- 하지만 B, C로 찾으면 ? 해당 테이블에서는 의미가 없음 - 다 찾아봐야 함
- 위를 해결하기 위해 추가적인 도움이 있어야 함
- 비 클러스터형 인덱스
- 비 클러스터형 인덱스를 테이블에 999개까지 허용한 이유가 뭘까 ?
- 그만큼 다양한 요구사항이 있기 때문임
가난한 클러스터 이야기
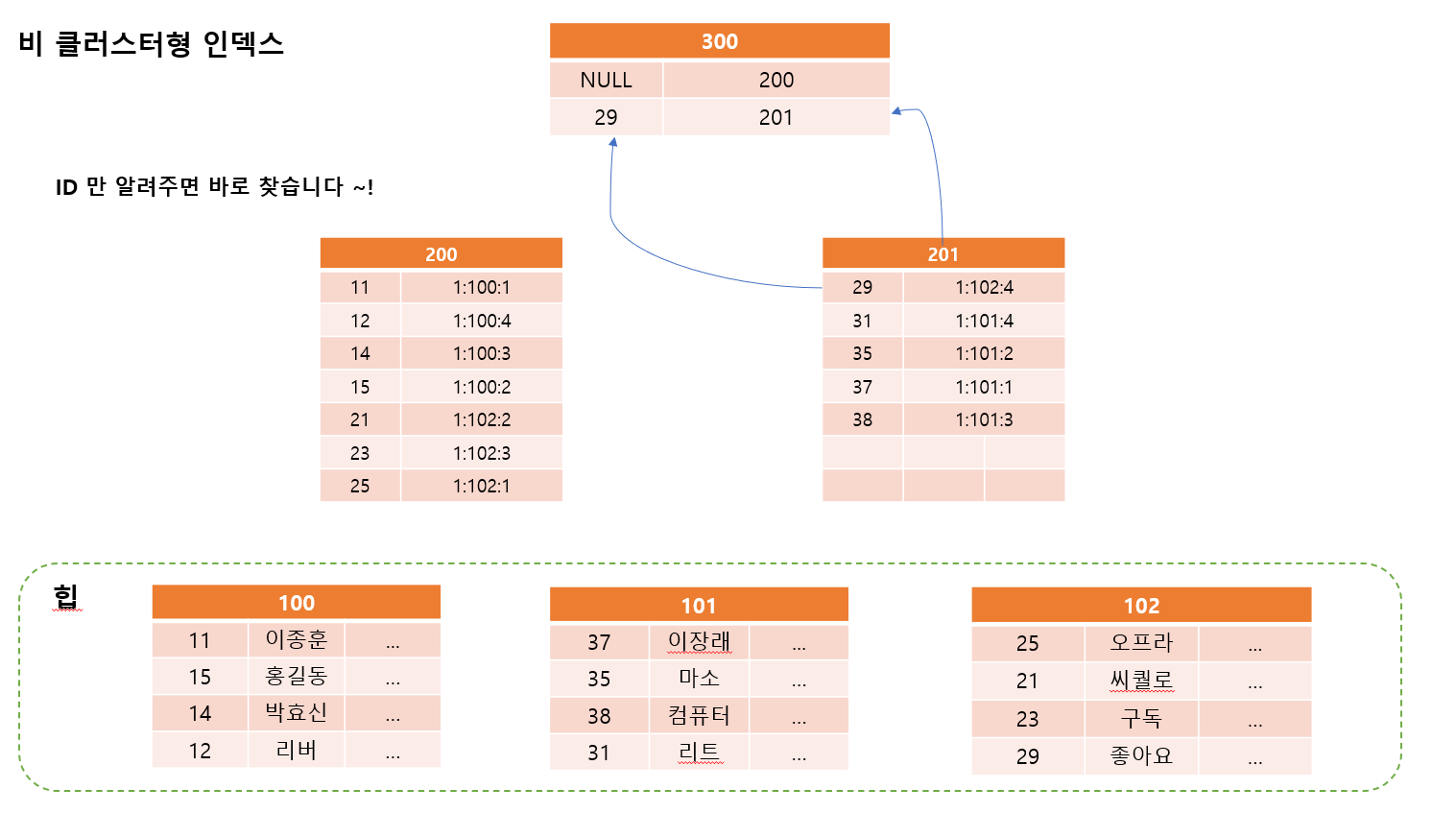
만약 WHERE절에 이메일이 많이 언급이 된다면 이메일 컬럼에 Non Clustered를 만들면 됨
그렇게 되면 이메일 데이터를 해당 비 클러스터 인덱스가 다 가지고 있는 것임
힙은 무작위로 데이터들이 존재하기 때문에 가장 좋은것은 주소를 딱! 찍어주는 것이 좋음
몇번째 파일에 몇번째 페이지에 몇번째 행인지를 알아야함
RID 란 데이터의 행의 주소
ID : 35 번을 찾는다고 가정하면
1:101:2
이므로 1의 101페이지의 2번째 행 으로 바로 찾을 수 있으므로 매우 빠르게 찾을 수 있다.
- 비 클러스터 형 인덱스가 가진것
- 인덱스 키 열의 모든 데이터
- RID : 행의 주소
- RID를 갖는 이유
- 주소 딱! 찍어주니 좋음
- RID 는 거의 변하지 않음
- RID 값이 크지도 않음
- 999개 만들 수 있음
하지만 만약 데이터를 1000개 찾아야 한다면 ?
- 1000번을 매번 찾아야 하므로 이 또한 해결책이 필요하다
여기서 1:101:4 에서 1이 의미하는 것이 mdf
원하는 데이터 찾아가기
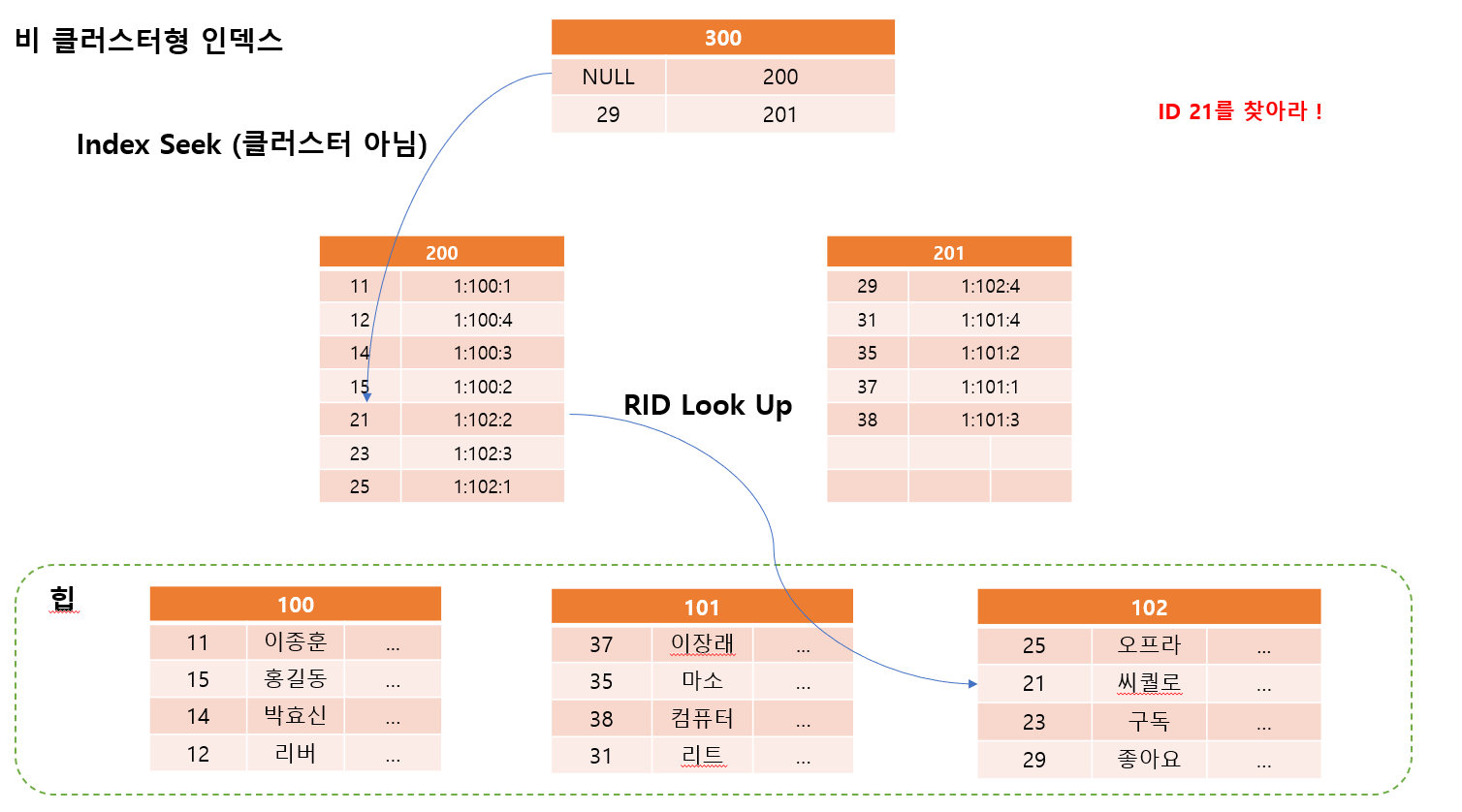
찾을때는 힙의 주소를 알고 있기 때문에 빠르게 찾을 수 있음
21번 을 찾기 위해서는?
- 1번 파일에 102 페이지에 2번행
하지만 위에서도 언급하였지만 바로 찾는것은 좋지만 만약에 찾는 개수가 100개 라면 ?
저 딱! (Index Seek) 과정을 100번 반복해야하므로 비용이 크다는 점을 알고가자
데이터를 바로 찾는 것을 Index Seek라고 함
RID를 가지고 찾아가는 과정을 RID Look Up 이라고 함
RID를 찾는데 왜 테이블이 힙이지 ?
- 당연히 RID를 찾아서 가는것은 힙 테이블에서 하기 때문
클러스터형 인덱스 테이블에서는 클러스터 인덱스를 활용하면 되지만
힙 테이블에서는 비 클러스터 인덱스 RID를 활용하기 때문에
Index Seek, Clustered Index Seek, RID Look Up, Full Table Scan, Clustered Index Scan, 등등
용어속에 테이블 구조가 들어가 있음
만약 회사에서 전부 클러스터 인덱스 테이블을 사용한다면 RID LooK Up이라는 용어를 사용할 일은 절대 없음
이런 예시가 가능
우리 회사는 테이블 구조가 힙이기 때문에 빈번한 RID Look Up 으로 인해 성능에 문제가 생길 수 있다
Index Seek 를 통해서 찾는건 좋은데 RID Look Up 이 문제다
왜냐하면 위에서 설명한 100개 데이터를 찾을 때 딱! 을 100번 반복해야 하므로
- Index Seek
- Root 페이지부터 찾아가기
- 아주 빠른 성능을 보여 줌
- RID LookUp
- 힙을 찾아가는 머나먼 여행
- 비 클러스터 형 인덱스가 가지지 못한 데이터를 찾아가는 과정
- Index Seek보단 느리고 Index Scan 보다는 빠름
- Index Scan
- 리프 수준의 모든 인덱스 페이지를 쫙 읽음
- Index Scan이 사용되는 경우는 이 테이블의 레코드 개수를 구할 때
- Select count all from table
- SQL Server는 Index Scan을 하면서 record Count를 다 더해보는 것임
클러스터형 인덱스 + 비 클러스터 형 인덱스
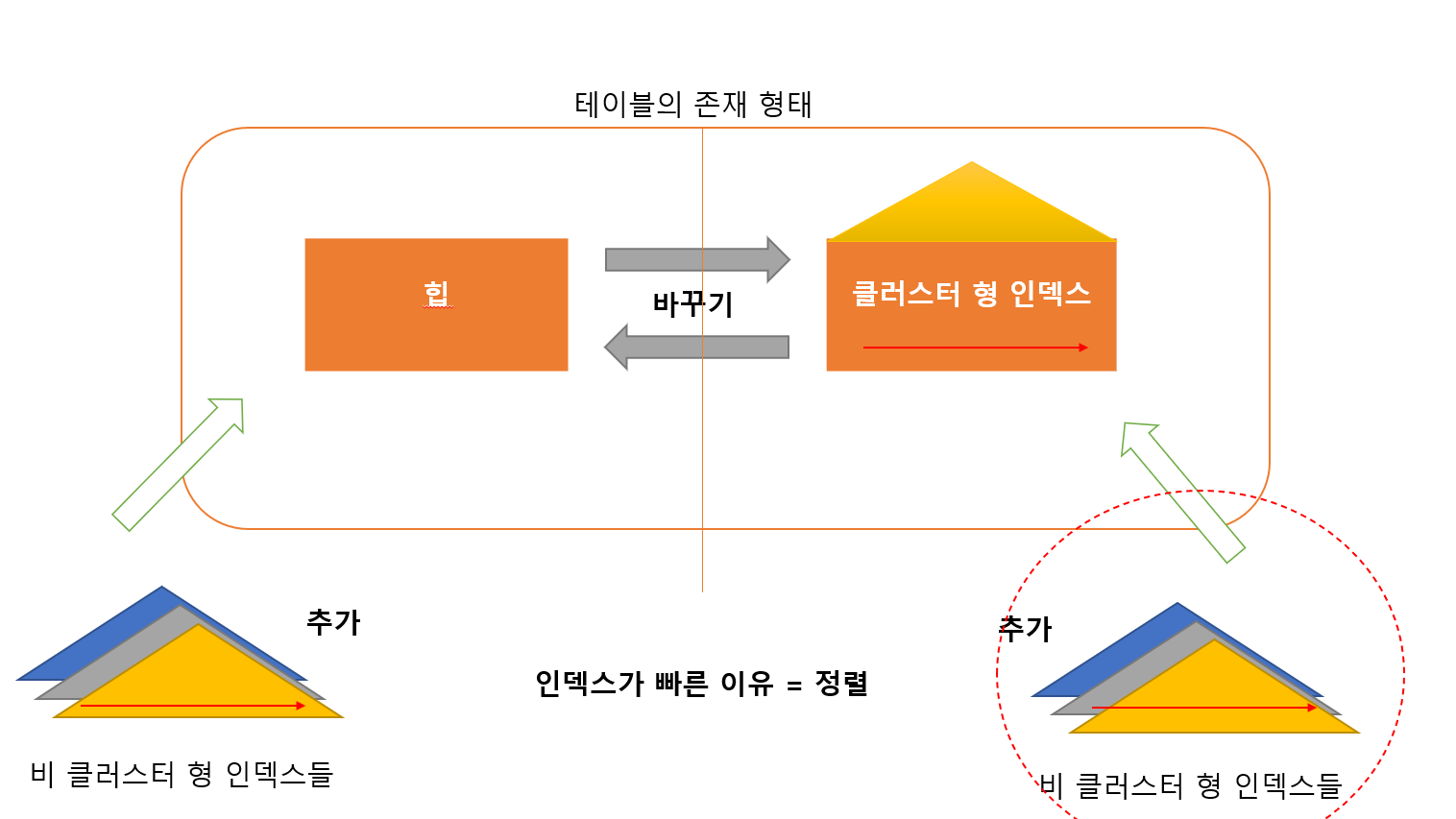
비 클러스터 형 인덱스가 가진것
- 인덱스 키 열의 모든 데이터
- 클러스터 형 인덱스 키 열
클러스터형 키 열을 갖는 이유
- RID 값은 변할 가능성이 높음
- 클러스터형 인덱스의 키 열은 거의 변하지 않음
999개 까지 만들수 있음
- 데이터와 별개로 저장되기 때문
힙은 연결되어있지 않아서 주소를 찍어줘야 하지만
클러스터형 인덱스는 정렬되어 있음
전화번호부(클러스터형 인덱스)에서 이종훈을 찾는다고 가정하면
몇번째 페이지에 몇번째 행에 이종훈이 있다고 알려주는 것이 아님
전화번호부는 이미 이름순으로 정렬이 되어있으므로 이종훈을 찾아보라고 말한다
다시 말해, 비 클러스터형 인덱스가 RID를 알려줄 이유가 없는 것이다
그리고 새로운 데이터를 넣을때
클러스터형 인덱스는 정렬 기준이 있기때문에 특정 페이지에 들어가야 하는 경우 다 차있으면 그 페이지를 분할하게 됨 그러면 나머지 데이터들은 옮겨가게 되고 그러면서 주소 RID가 계속 바뀌게 되는 점이 존재한다
이런 복잡한 과정이 있으므로 클러스터형 인덱스는 RID를 포기하고 인덱스 키 값을 받는 것이다
데이터가 정렬되어 있으므로 !
클러스터는 이름을 기준으로 정렬되어 있음 - 이름에 클러스터가 걸려있음
비 클러스터는 ID과 이름을 가지고 있음 - RID가 없음
비 클러스터형 인덱스가 언제 왜 사용되는지 알아보자
클러스터형 인덱스의 엄청난 테이블이 있고 쿼리가 이 테이블에 엑세스 한다
그런데 갑자기 엄청난 테이블이 하나 만들어 졌다 (비 클러스터형 인덱스, 2개의 컬럼만 가지고 있는 별도의 테이블)
왜냐하면 이 테이블은 ID로 정렬되어있으며마치 ID 와 이름을 가진 클러스터형 인덱스 같다
이 테이블은 ID로 정렬된 테이블이고 레코드 길이는 8KB로 제한되어 있으므로 한 번 레코드를 조회할 때
- 클러스터 인덱스 테이블에서는 1000개를 읽어야 할 페이지들을
- 비 클러스터에서는 10개만 읽어도 비슷한 효율이 나올 수 있다
이 차이가 매우 크기때문에 인덱스를 사용해야 한다
원하는 데이터를 찾아라
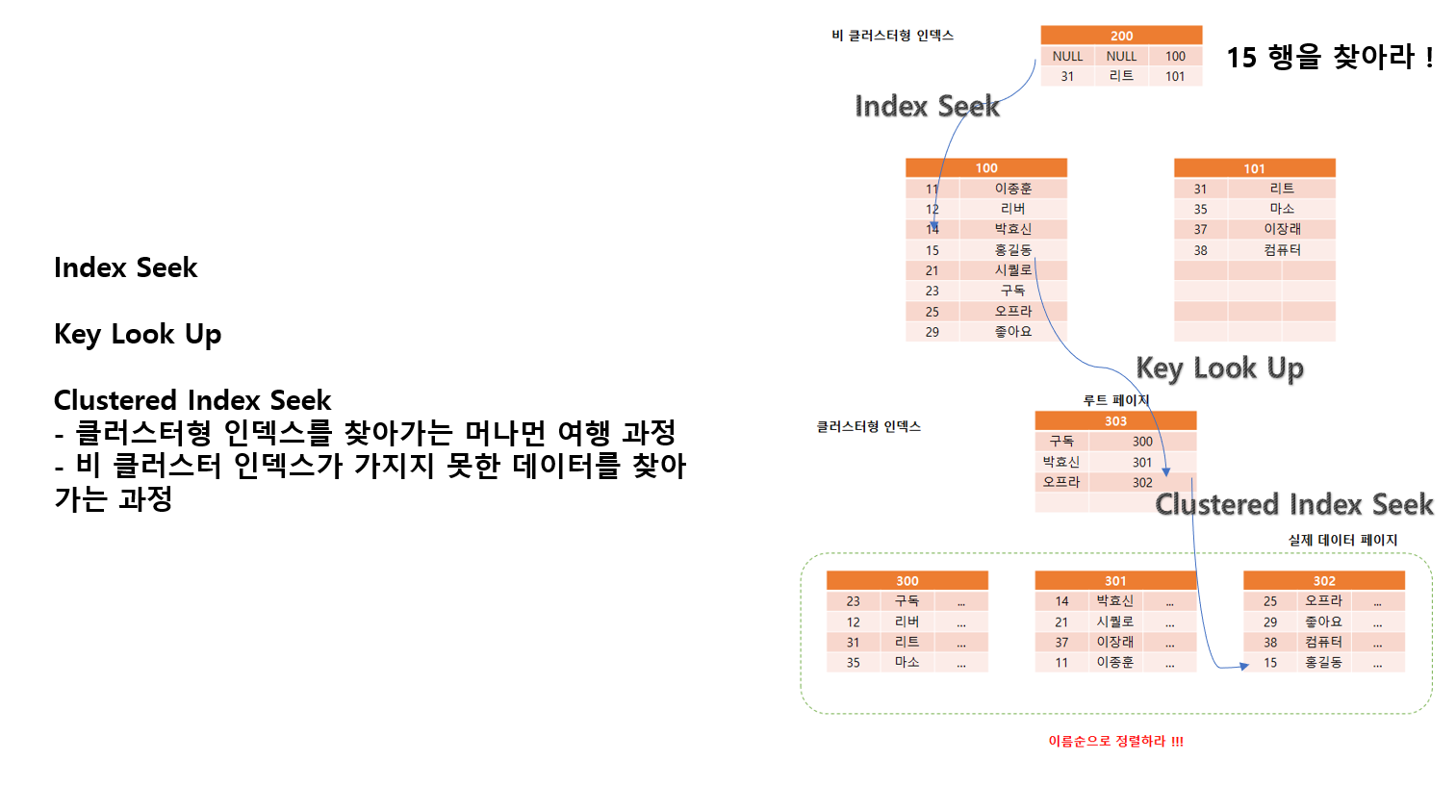
Index Seek
- ID를 가지고 바로 찾아감
Key LookUp
- Key를 가지고 찾아감
Clustered Index Seek
- 정렬된 데이터를 가지고 찾아감
클러스터 인덱스 리프 페이지를 다 읽으면 ?
- 클러스터 인덱스 스캔
비 클러스터 인덱스 리프 페이지를 다 읽으면 ?
- 인덱스 스캔
클러스터형 인덱스 생성 및 구조
USE bigdata
CREATE TABLE cluster_table
(
id int not null,
name varchar(17) not null
);
go
insert into cluster_table values (1, '이종훈1');
insert into cluster_table values (2, '이종훈2');
insert into cluster_table values (3, '이종훈3');
insert into cluster_table values (11, '이종훈4');
insert into cluster_table values (12, '이종훈5');
insert into cluster_table values (21, '이종훈6');
insert into cluster_table values (22, '이종훈7');
insert into cluster_table values (31, '이종훈8');
insert into cluster_table values (32, '이종훈9');
go
ALTER TABLE cluster_table ADD CONSTRAINT PK_cluster_table_id PRIMARY KEY (id)';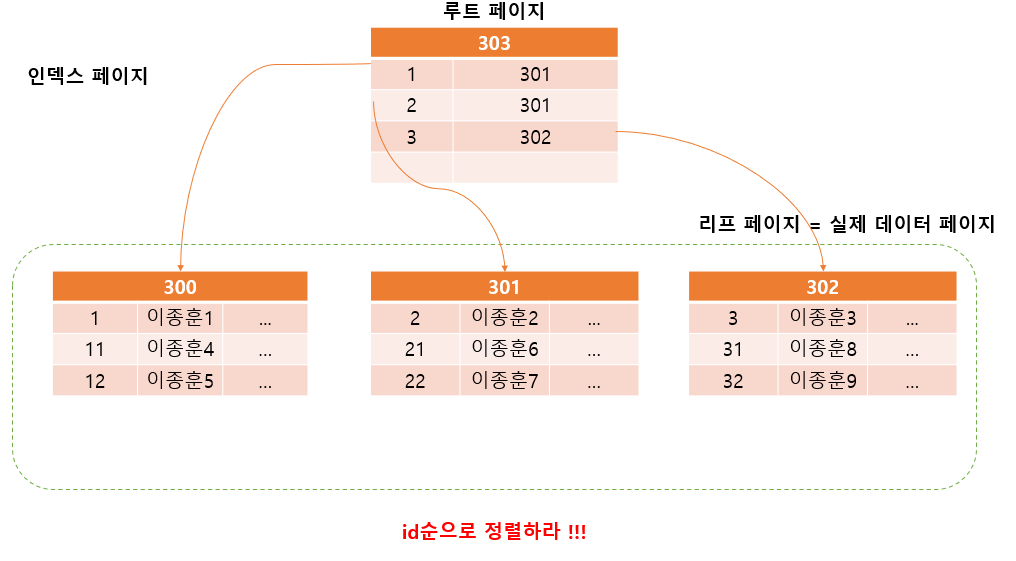
- 클러스터형 인덱스를 구성하기 위해서 행 데이터를 해당 id열로 정렬한 후, 루트 페이지를 만든다
- 클러스터형 인덱스는 루트 페이지와 리프 페이지로 구성되며, 리프 페이지는 데이터 그 자체이다
- 클러스터형 인덱스는 검색 속도가 비 클러스터형 인덱스 보다 더 빠르다
비 클러스터형 인덱스 생성 및 구조
USE bigdata
CREATE TABLE cluster_table
(
id int not null,
name varchar(17) not null
);
go
insert into cluster_table values (1, '이종훈1');
insert into cluster_table values (2, '이종훈2');
insert into cluster_table values (3, '이종훈3');
insert into cluster_table values (11, '이종훈4');
insert into cluster_table values (12, '이종훈5');
insert into cluster_table values (21, '이종훈6');
insert into cluster_table values (22, '이종훈7');
insert into cluster_table values (31, '이종훈8');
insert into cluster_table values (32, '이종훈9');
go
ALTER TABLE cluster_table ADD CONSTRAINT PK_cluster_table_id PRIMARY KEY (id)';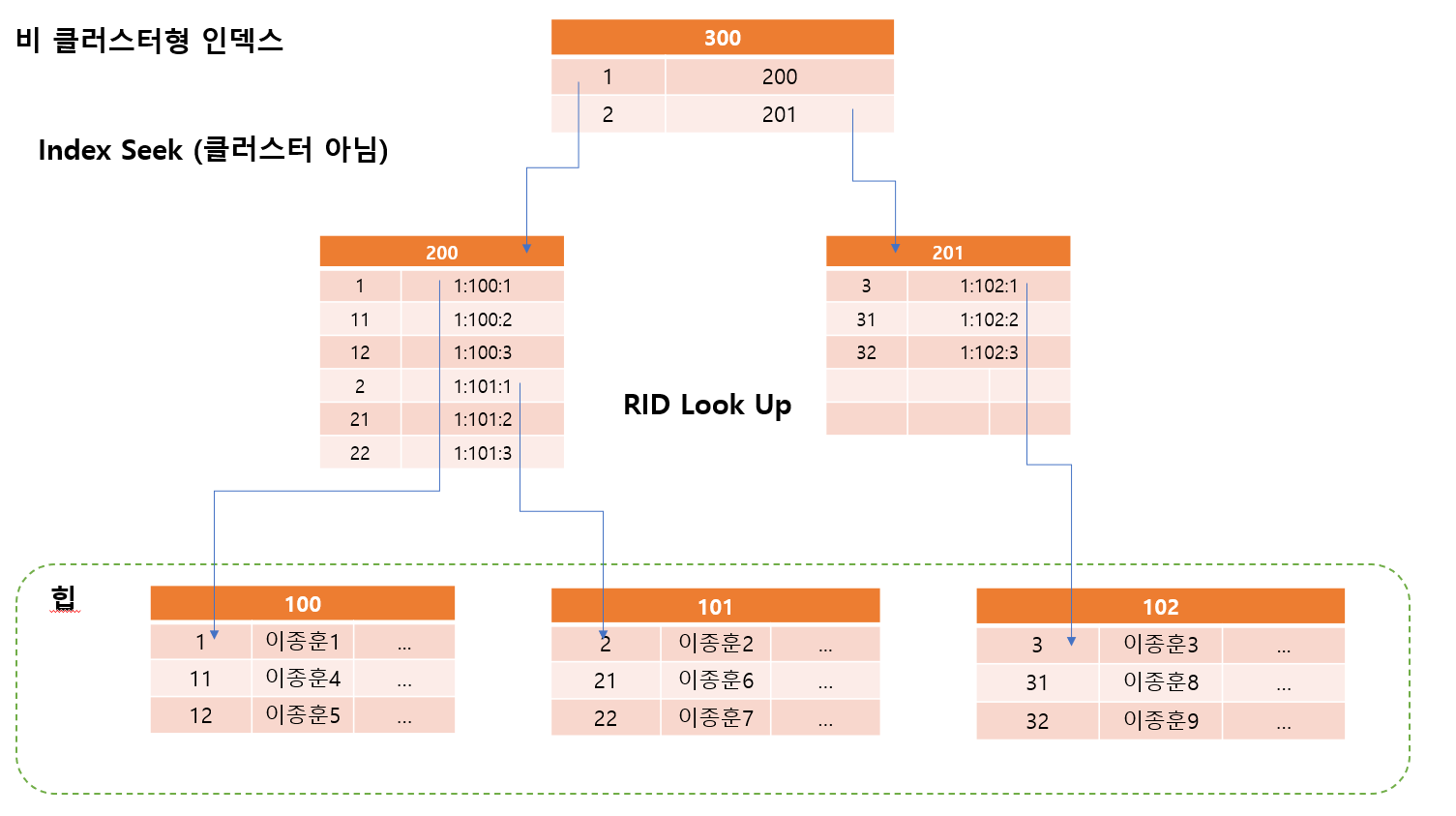
- 비 클러스터형 인덱스는 데이터 페이지를 건들지 않고, 별도의 장소에 인덱스 페이지를 생성한다
- 인덱스 페이지의 리프 페이지에 인덱스로 구성항 열을 정렬한 후 위치 포인터(RID)를 생성한다
정리
테이블과 인덱스
알 품 인
RID를 품은 인덱스
힙 형태의 테이블에 만들어진 비 클러스터형 인덱스
키 품 인
Key를 품은 인덱스
클러스터 형 인덱스가 있는 테이블 위에 만들어진 비 클러스터형 인덱스
즉 클러스터가 만든 비 클러스터 인덱스
각자 RID, KEY를 가지고 있음 왜 ? 변하지 않을거라 생각하기 때문에
그런데 만약 클러스터의 Key컬럼을 UPDATE를 통해 바꾼다면 ?
그러면 키품인이 난리가 남
RID가 바뀔 것 같아서 KEY를 품었더니 이제 KEY가 바뀌네 ?
- 인덱스에서 SELECT를 제외한 나머지 연산(CRUD중 C,U,D) 에서 좋지 않다는 이유가 여기에 있다
여기서 RID가 바뀔 것 같은 이유는 ?
- 인덱스 테이블은 정렬 기준이 있으므로 데이터가 들어올때마다 RID가 바뀌기 때문이다
- RID가 바뀐다는 것은 페이지 내에서 데이터의 위치가 바뀌는 것이고 페이지가 분할된다는 의미
인덱스는 데이터를 가진 테이블이다 !!
쿼리는 테이블이 아닌 인덱스로 날려라!
쿼리를 테이블이 아닌 인덱스로 날리면
인덱스에서 먼저 찾고 인덱스에 없다면 테이블로 가게된다
참고 - SQL Unplugged 2013
