
PCA (Principal Component Analysis)
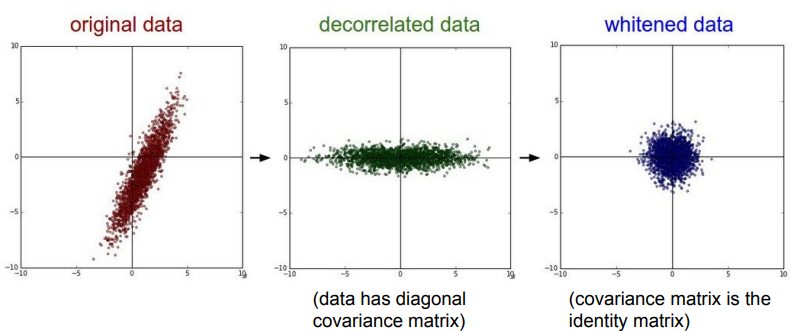
PCA는 고차원의 데이터를 저차원으로 변환하는 기법으로, 데이터의 분산을 최대화하는 방향으로 주성분(principal components)을 찾아 그 축을 따라 데이터를 투영합니다. 주로 데이터의 차원을 축소하거나, 데이터의 중요한 특징을 추출하는 데 사용됩니다.
핵심 개념
분산 최대화
데이터의 분산(variability)을 최대한 보존하는 방향으로 새로운 축을 정의합니다.
직교 변환
새롭게 정의된 축(주성분들)은 서로 직교(orthogonal)합니다.
차원 축소
고차원의 데이터를 몇 개의 주성분만으로 표현해도, 데이터의 중요한 정보가 보존될 수 있습니다.
PCA 수행 절차
데이터 정규화
각 feature의 평균을 0으로 맞추는 정규화를 합니다.
공분산 행렬 계산
정규화된 데이터의 공분산 행렬을 계산합니다.
고유벡터 및 고유값 계산
공분산 행렬의 고유벡터(eigenvectors)와 고유값(eigenvalues)을 계산합니다.
주성분 선택
고유값이 큰 순서대로 대응되는 고유벡터를 선택하여 주성분을 정의합니다.
데이터 변환
데이터를 선택된 주성분 축에 투영하여 새로운 저차원 데이터를 얻습니다.
장점
- 고차원 데이터의 주요 패턴을 파악할 수 있습니다.
- 차원 축소를 통해 계산 효율성을 높이고, 시각화하기 쉽게 만듭니다.
단점
- 선형 변환만 가능하므로 복잡한 비선형 패턴을 다루는 데는 한계가 있습니다.
- 해석 가능한 주성분을 만들기 어려울 수 있습니다.
Whitening
Whitening은 PCA를 수행한 후, 주성분들의 스케일(크기)을 표준화하는 과정을 말합니다. 이는 각 주성분의 분산을 동일하게 맞추는 작업으로, 결과적으로 변환된 데이터의 공분산 행렬이 단위 행렬(identity matrix)이 되도록 합니다.
Whitening의 목적
독립적이고 등분산적인 특성
주성분들이 서로 독립적이고, 분산이 동일하게 되도록 만듭니다.
Preprocessing
Whitening은 종종 신경망이나 머신러닝 알고리즘에 데이터를 입력하기 전의 전처리 단계로 사용됩니다. 데이터의 분포를 표준화하면 학습이 더 빠르게 수렴할 수 있습니다.
Whitening 수행 절차
PCA 수행
먼저 PCA를 통해 데이터를 주성분으로 변환합니다.
주성분의 분산 조정
각 주성분을 해당 고유값의 제곱근으로 나눕니다. 이는 각 주성분이 동일한 분산을 가지도록 만듭니다.
데이터 변환
이렇게 분산을 동일하게 맞춘 주성분들로 데이터를 재구성합니다.
공식
PCA로 변환된 데이터 에 대해 whitening을 수행한 데이터 는 다음과 같이 계산됩니다.
여기서 Λ는 PCA의 고유값들의 대각 행렬입니다.
장점
- Whitening을 하면 주성분들이 독립적이고, 분산이 동일하게 되므로 특정 패턴을 쉽게 학습할 수 있습니다.
- 학습 알고리즘의 성능을 높일 수 있는 데이터의 균일화 작업입니다.
단점
- 데이터를 과도하게 변형할 수 있으며, 오히려 유용한 패턴을 제거할 위험이 있습니다.
- Whitening의 계산이 복잡하고 시간이 걸릴 수 있습니다.
PCA와 Whitening 비교
- PCA는 데이터의 주요 축을 따라 차원을 축소하는 데 중점을 둡니다. 데이터의 분산을 최대화하는 주성분을 찾아 데이터를 투영함으로써 중요한 특징을 추출합니다.
- Whitening은 PCA를 적용한 후, 각 주성분의 분산을 동일하게 맞추는 과정입니다. 데이터를 더 균일하게 만들고, 각 특성이 독립적이도록 보장하는 데 목적이 있습니다.
- Whitening은 종종 PCA 이후의 추가적인 처리 단계로, PCA로부터 얻어진 주성분을 정규화하여 주성분들이 독립적이고 균일한 분산을 가지도록 만듭니다.
