
1. 임베딩
1.1 임베딩 소개
임베딩(Embedding)은 고차원 데이터를 저차원 벡터 공간으로 변환하는 기술로, 주로 자연어 처리(NLP)와 컴퓨터 비전(CV) 분야에서 많이 사용됩니다. 예를 들어, 단어를 수치 벡터로 변환하면, 단어 간의 유사성을 벡터 간의 거리로 측정할 수 있습니다. 임베딩은 주어진 데이터를 더 작은 차원의 벡터로 표현하면서도 그 안에 중요한 의미적, 패턴적 관계를 보존하려고 합니다. 대표적인 임베딩 방법으로는 Word2Vec, GloVe, BERT 등이 있으며, 이미지에서는 Convolutional Neural Network(CNN)의 중간 계층 출력이 임베딩으로 사용될 수 있습니다.
1.2 Word2Vec (Skip-Gram)
Word2Vec은 단어를 임베딩 벡터로 변환하는 방법 중 하나로, 특히 Skip-Gram 모델은 주어진 단어로부터 주변 단어들을 예측하는 방식으로 임베딩을 학습합니다. 예를 들어, "고양이가 창문을 넘었다"라는 문장에서 "고양이"라는 단어가 주어졌을 때, "창문"이나 "넘었다"와 같은 주변 단어들을 예측하는 방식입니다. 이 과정을 통해 비슷한 문맥에서 등장하는 단어들은 비슷한 임베딩을 얻게 되며, 이 임베딩 공간에서 단어 간의 유사성을 수치적으로 측정할 수 있습니다.
Word2Vec(Skip-Gram)은 다음과 같은 단계로 진행됩니다:
- 중앙 단어를 주어 주변 단어를 예측 (Skip-Gram 모델)
- 학습된 벡터는 단어 의미를 잘 반영하며, 벡터 연산으로 의미적 관계를 파악할 수 있음 (예: "왕 - 남자 + 여자 = 여왕").
1.3 t-SNE
t-SNE(t-distributed Stochastic Neighbor Embedding)는 고차원 데이터를 저차원(주로 2차원 또는 3차원) 공간으로 시각화하는 데 사용되는 기법입니다. 이는 비선형 차원 축소 방법으로, 특히 고차원 임베딩 벡터를 2D 또는 3D로 시각화하여 데이터 간의 구조적 관계를 확인할 때 유용합니다. Word2Vec으로 학습된 단어 벡터나 이미지 임베딩을 t-SNE를 통해 시각화하면, 의미적으로 유사한 단어들이 어떻게 군집을 이루는지 확인할 수 있습니다.
t-SNE는 다음과 같은 장점이 있습니다:
- 고차원 공간의 복잡한 데이터 구조를 저차원 공간에서 명확하게 시각화
- 특히 군집 및 클러스터링 분석에서 데이터 간의 유사성을 쉽게 이해할 수 있음
- 주로 텍스트 임베딩 또는 이미지 임베딩의 결과를 2D로 표현할 때 많이 사용됩니다.
2. Retrieval
2.1 Retrieval 개요
Retrieval(검색)은 대규모 데이터베이스에서 특정 데이터를 찾아내는 작업을 의미합니다. 검색 엔진이나 추천 시스템처럼, 사용자 입력(쿼리)에 가장 유사한 결과를 찾아 제공하는 것이 Retrieval의 기본적인 목표입니다. Retrieval 시스템에서는 주로 임베딩을 통해 입력과 데이터베이스에 있는 데이터 간의 유사성을 계산하고, 이를 바탕으로 가장 유사한 결과를 반환합니다. 예를 들어, 이미지 검색에서 사용자는 하나의 이미지를 쿼리로 제공하면, 시스템은 데이터베이스에서 가장 유사한 이미지를 찾아 반환합니다.
2.2 Distance Metrics
Retrieval에서는 데이터 간의 유사성을 측정하는 방법이 중요한 역할을 합니다. 거리 메트릭(Distance Metrics)은 이러한 유사성을 수치화하여 가까운 결과를 반환하는 방식입니다. 몇 가지 대표적인 거리 측정 방법은 다음과 같습니다:
- 유클리드 거리 (Euclidean Distance): 두 점 사이의 직선 거리를 측정합니다. 임베딩 공간에서 점들 간의 물리적 거리를 나타내는 기본적인 방법입니다.
- 코사인 유사도 (Cosine Similarity): 벡터 간의 각도를 기반으로 두 벡터의 유사성을 측정합니다. 특히 벡터의 크기보다는 방향에 주목하는 방식으로, 텍스트 임베딩에서 자주 사용됩니다.
- 맨해튼 거리 (Manhattan Distance): 좌표축을 따라 이동하는 방식으로 두 점 사이의 거리를 측정합니다. L1 정규화와 같은 경우에 활용되며, 유클리드 거리보다 이동 경로에 따라 유사성이 달라집니다.
이러한 메트릭들은 데이터의 특성과 문제 유형에 따라 선택되며, Retrieval 시스템의 성능을 좌우할 수 있습니다.
3. 딥러닝을 이용한 Retrieval
3.1 Arcface
Arcface는 얼굴 인식 및 인증에서 주로 사용되는 각도 기반의 손실 함수입니다. Arcface는 사람의 얼굴 이미지 간의 유사성을 각도로 측정하여, 같은 사람의 얼굴은 가까운 각도로, 다른 사람의 얼굴은 멀리 떨어진 각도로 학습합니다.
Arcface의 주요 개념은 softmax 손실 함수를 확장하여 각도 거리를 기반으로 클래스 간의 분리를 강화하는 것입니다. 기존의 softmax 손실 함수는 학습된 벡터들의 크기와 방향을 모두 고려하지만, Arcface는 벡터의 각도(angular distance)만을 기준으로 하여 학습합니다. 이를 통해 학습된 임베딩 벡터는 동일한 클래스는 각도가 유사하고, 다른 클래스는 각도가 더 멀어지도록 학습됩니다.
Arcface의 주요 특징:
- 각도 기반 학습: 데이터 간의 각도를 기준으로 학습하므로, 얼굴 이미지 간의 구분이 더 명확해집니다.
- 고성능 얼굴 인식: Arcface는 얼굴 인식에서 특히 뛰어난 성능을 보이며, 작은 각도 차이로 얼굴을 구분할 수 있습니다.
- 높은 일반화 능력: Arcface는 다양한 얼굴 이미지에서 높은 정확도를 보이며, 얼굴 인증 시스템에 널리 사용됩니다.
Arcface의 동작 원리:
- 입력 이미지가 신경망을 통과해 특징 벡터(embedding vector)로 변환됩니다.
- Arcface는 이 벡터의 각도를 이용해 학습하며, 학습 과정에서 클래스 간의 각도 거리를 벌림으로써 구분 능력을 높입니다.
- 이를 통해, 학습된 임베딩은 같은 클래스 내의 데이터는 더 가깝게, 다른 클래스는 더 멀리 위치하게 됩니다.
Arcface는 얼굴 인식 뿐만 아니라, 이미지 분류, 객체 인식 등 다양한 분야에서 활용될 수 있습니다.

(출처: https://norman3.github.io/papers/images/arcface/f03.png)
3.2 CLIP
CLIP(Contrastive Language-Image Pretraining)은 멀티모달 학습 모델로, 텍스트와 이미지를 동일한 임베딩 공간으로 매핑하여 텍스트-이미지 검색 작업을 수행할 수 있습니다. CLIP은 텍스트와 이미지의 연관성을 학습하기 위해 대규모 텍스트-이미지 쌍을 학습하며, 텍스트와 이미지 사이의 의미적 유사성을 임베딩 벡터로 변환합니다.
CLIP은 다음과 같은 방식으로 작동합니다:
1. 텍스트 임베딩: 주어진 텍스트는 텍스트 임베딩 모델(주로 Transformer 기반 모델)을 통해 벡터로 변환됩니다.
2. 이미지 임베딩: 이미지는 이미지 임베딩 모델(주로 CNN 기반 모델)을 통해 벡터로 변환됩니다.
3. 대조 학습: CLIP은 텍스트와 이미지의 임베딩 벡터를 대조(Contrastive)하는 방식으로 학습합니다. 즉, 텍스트와 이미지가 의미적으로 가까운 쌍은 임베딩 공간에서 가까운 벡터로, 의미적으로 다른 쌍은 멀리 떨어진 벡터로 학습합니다.
CLIP의 주요 특징:
- 멀티모달 학습: 텍스트와 이미지를 동시에 학습하여, 텍스트를 입력하면 관련된 이미지를 찾거나, 이미지를 입력하면 관련된 텍스트를 검색할 수 있습니다.
- 대규모 데이터 학습: CLIP은 대규모의 텍스트-이미지 쌍을 학습하며, 다양한 데이터에 대해 일반화 능력을 가지고 있습니다.
- 높은 검색 성능: CLIP을 통해 학습된 모델은 텍스트와 이미지 간의 유사성을 정확히 학습하여, 이미지 검색이나 추천 시스템에서 높은 성능을 발휘합니다.
CLIP의 활용 예시:
- 이미지 검색: "강아지가 뛰고 있는 이미지"라는 텍스트를 입력하면, CLIP은 그와 관련된 이미지를 검색할 수 있습니다.
- 텍스트 설명 생성: 이미지를 입력하면, CLIP은 그 이미지에 적합한 텍스트 설명을 생성할 수 있습니다. 이는 이미지 캡셔닝(image captioning)과도 연관이 있습니다.

(출처: https://img1.daumcdn.net/thumb/R1280x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Frs9Go%2Fbtq2Eg0naJd%2FWdF69Hy0QRQorvDYHI0eD1%2Fimg.png)
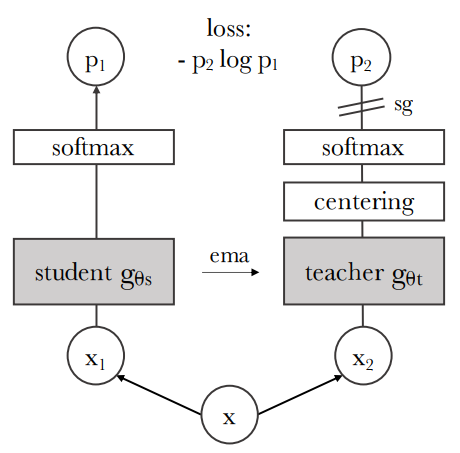
3.3 DINO
DINO(Self-Distillation with No Labels)는 비지도 학습(Self-Supervised Learning) 방식으로 이미지를 학습하는 딥러닝 모델입니다. DINO는 자기 지시 학습(self-distillation) 방식을 통해, 레이블 없이도 데이터를 학습할 수 있으며, 특히 이미지 임베딩 학습에서 높은 성능을 발휘합니다. DINO는 특히 이미지 간의 유사성을 학습하여, 이미지 검색과 같은 작업에서 우수한 성능을 보여줍니다.
DINO의 동작 방식:
DINO는 교사-학생 구조(teacher-student architecture)를 사용하여 이미지를 학습합니다. 이 구조에서:
- 교사 네트워크(teacher network)는 이미 학습된 모델로, 정적 상태에서 새로운 데이터를 처리합니다.
- 학생 네트워크(student network)는 교사 네트워크의 출력을 기반으로 스스로 학습하며, 이 과정에서 교사와 학생 네트워크 간의 예측 차이를 최소화하는 방식으로 진행됩니다.
DINO는 이 과정을 통해, 라벨 없이도 데이터를 학습하며, 이미지 간의 유사성을 잘 파악할 수 있습니다.
DINO의 주요 특징:
- 비지도 학습: 레이블 없이 데이터를 학습하는 방식으로, 라벨이 없는 대규모 데이터셋에서도 효과적으로 학습할 수 있습니다.
- 자기 지시 학습(Self-Distillation): 모델이 스스로 학습하고, 이미지를 더 잘 구분할 수 있도록 학습합니다.
- 이미지 임베딩 생성: DINO는 이미지의 임베딩을 생성하여, 이미지 검색, 객체 검출 등 다양한 비지도 학습 문제에 활용할 수 있습니다.
DINO의 활용 예시:
- 이미지 검색: DINO는 이미지 간의 유사성을 학습하므로, 이미지 검색 시스템에 적용하여, 유사한 이미지를 효과적으로 찾을 수 있습니다.
- 비지도 학습 기반 객체 탐지: DINO는 레이블이 없는 이미지에서도 중요한 객체를 구분할 수 있어, 비지도 방식의 객체 탐지(object detection)에도 활용될 수 있습니다.
(출처:https://kimjy99.github.io/assets/img/dino/dino-fig2.PNG)
