M1에서 Oracle 설치하는 방법
이번에 DBMS을 mysql, postgresql 이 아닌 oracle을 사용하게 되었는데, Oracle은 기본적으로 macOS를 정식 지원하지 않는다. 특히 M1/M2와 같은 ARM 아키텍처에서는 Oracle을 직접 설치하거나 실행하는 것이 거의 불가능에 가깝다. 하지만 Docker와 QEMU를 이용한 x86_64 에뮬레이션 환경을 구성하면, M1 Mac에서도 Oracle Database를 실행할 수 있다.
M1/M2 Mac에서 Oracle을 사용하기 위한 필수 도구 소개
우리는 macOS환경에서 Oracle을 실행하기 위해서는 Docker, QEMU, Colima, 그리고 Lima라는 네 가지 도구를 활용해야 한다. 각 도구가 어떤 역할을 하는지 간단히 살펴보겠다.
🐳 Docker – 격리된 환경에서 애플리케이션 실행
Docker는 컨테이너 기술을 기반으로, 애플리케이션을 격리된 환경에서 실행할 수 있게 해주는 플랫폼입니다. Oracle 역시 Docker 이미지를 통해 간단하게 실행할 수 있다. 하지만, 대부분의 Oracle 이미지는 x86_64 아키텍처를 기반으로 만들어졌기 때문에, ARM 아키텍처인 M1/M2 Mac에서는 Docker만으로는 제대로 실행되지 않는다.
🧠 QEMU – CPU 아키텍처 에뮬레이션
QEMU는 다양한 CPU 아키텍처를 에뮬레이션할 수 있는 오픈소스 가상화 도구다. M1 Mac처럼 ARM 기반 기기에서도, QEMU를 통해 x86 기반 프로그램을 실행할 수 있게 된다. 즉, Oracle과 같은 x86 전용 Docker 이미지를 ARM 환경에서 사용하려면, QEMU가 중간에서 CPU 아키텍처를 바꿔주는 역할을 한다.
🔧 Colima – M1 Mac에서 Docker 실행 환경 구성
Colima는 macOS에서 Docker를 보다 쉽게 사용할 수 있도록 도와주는 툴이다. 특히 M1/M2 Mac에서의 Docker 실행을 위한 우회 솔루션으로 매우 유용하다. Colima는 내부적으로 QEMU와 Lima를 활용하여, macOS 위에 경량 리눅스 가상 머신을 띄우고 그 안에 Docker 환경을 구성한다. 이 덕분에 M1 Mac에서도 Oracle처럼 x86 전용 이미지를 실행할 수 있게 된다.
🐧 Lima – Colima의 기반이 되는 리눅스 VM 매니저
Lima는 Linux virtual machines on macOS의 줄임말로, macOS(특히 ARM 기반)에서 리눅스 가상 머신을 실행할 수 있게 해주는 도구다. Colima는 Lima를 내부적으로 활용하며, 실제 Docker가 작동하는 가상 머신도 Lima를 통해 실행된다. QEMU는 그 안에서 아키텍처를 에뮬레이션한다.
🧩 도구 간 관계 정리
M1/M2 Mac (ARM) └─ Colima └─ Lima (리눅스 VM 생성) └─ QEMU (x86_64 에뮬레이션) └─ Docker (Oracle 컨테이너 실행)
Oracle 설치
대부분의 macOS 유저라면 homebrew가 설치되어있을 것이다.
설치가 되지 않았다면?
brew 공식홈페이지# terminal에 설정값 변경해주기 echo 'export PATH="/opt/homebrew/bin:$PATH"' >> ~/.zshrc source ~/.zshrc
이후 brew를 통해 위에 설명한 패키지들을 install해야한다.
brew install lima
brew install lima-additional-guestagents
brew install qemu
brew install colimadocker를 설치하지 않았다고요?
Download for Mac - Apple Sllicon
docker 공식 홈페이지
다음으로는 colima라는 VM를 실행시켜준다.
# 4GB Memory Arm 환경이 아닌 x86환경으로 가상머신 실행
colima start --memory 4 --arch x86_64
## docker가 정상적으로 실행되었는지 확인하기 위해서
docker info
done처리가 완료되면 colima VM이 정상적으로 올라간 것을 알 수 있다.
docker run --restart unless-stopped --name oracle -e ORACLE_PASSWORD=1234 -p 1521:1521 -d gvenzl/oracle-xe--name (컨테이너이름) / ORACLE_PASSWORD=(비밀번호)
' -- restart unless stopeed ' 로 colima 를 실행하면 자동으로 컨테이너가 시작됨.
현재 docker image가 존재하지 않는다면, image가 pull 될 것이고 done이후 실제로 docker에 Oracle이 올라갔는 지 확인하고 싶다면, docker ps를 통해 확인하면 된다.
docker ps

DBeaver 연결하기
MacOS for Apple Sillicon(dmg)를 다운로드 한 이후 왼쪽 상단에 New Database Connection(control + shift + N)을 클릭하면 아래와 같은 이미지가 보일 것이다.
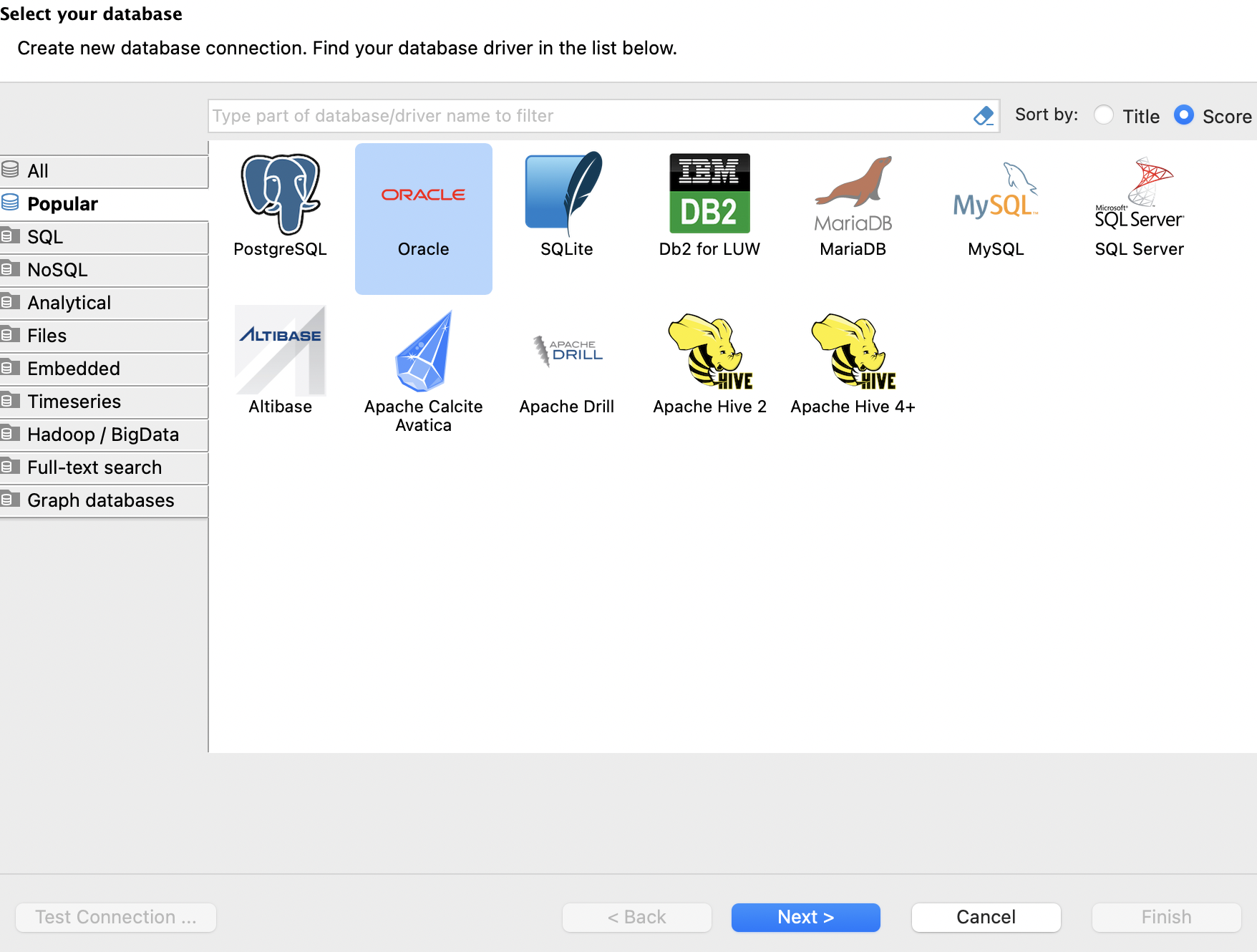
Setting Value
Host : localhost
Port : 1521
Database : xe
UserName : system
Password : 1234
Oracle과 연결 문제가 없는지 확인하기 위해서 왼쪽 하단에 Test Connection을 클릭한 후 connected 라는 문구가 나면 정상적으로 연결이 가능한 상태가 된다. 만약 다른 화면이 보인다면 Oracle을 다운로드가 되지 않는 상태여서 다운로드를 클릭하면 된다.
Mysql VS Oracle VS Postgresql
항목 MySQL Oracle DB PostgreSQL 라이선스 GPL (오픈소스, 일부 상업용 제한) 상용 (유료) PostgreSQL 라이선스 (완전 오픈소스) 개발사 Oracle (MySQL AB → Sun → Oracle) Oracle Corporation PostgreSQL Global Development Group 표준 준수 비교적 낮음 (기능 단순) 매우 높음 (SQL 표준+자체 확장) 매우 높음 성능 읽기 성능 빠름 대용량 트랜잭션/엔터프라이즈에 최적화 복잡한 쿼리와 쓰기 성능에 강점 확장성 수직 확장 위주 수직/수평 확장 모두 가능 수평 확장 기능 (예: Citus 등) 트랜잭션 지원 InnoDB 사용 시 ACID 지원 고급 트랜잭션 처리 기능 제공 기본적으로 ACID 완벽 지원 JSON 지원 있음 (제한적) 있음 (Oracle 12c 이상) 매우 우수 (JSONB 등) 사용 용도 웹 서비스, 스타트업, 빠른 개발 대기업, ERP, 금융, 미션 크리티컬 분석, 리서치, 고급 기능 필요 환경 도구 및 GUI MySQL Workbench 등 SQL Developer, Enterprise Manager pgAdmin, DBeaver 등 커뮤니티/지원 활발, 자료 많음 상용 지원 중심 활발, 기여자 많음
SQL(Structured Query Language)
SQL이란 DBMS에서 자료 처리를 위한 용도로 사용되는 구조적 데이터 질의 언어로서, DDL, DML, DCL로 구성되어있다.
DDF, DML, DCL, TCL
관련된 내용 - SQL
- DDL(Data Definition Language, 데이터 정의어) : database의 각종 구조를 생성, 수정 관리하는 언어로 주로 데이터베이스를 생성하거나, 데이터베이스를 수정할 때 사용한다.
- DML(Data Manipulation Language, 데이터 조작어) : 데이터를 입력(Insert, Create), 수정(Update), 삭제(Delete), 조회(Select)를 할 때 사용한다.
- DCL(Data Control Language, 데이터 제어어) : data의 권한을 제어할 때 사용한다.
- TCL(Transaction Control Language) : Transaction의 완전한 적용(commit) 및 취소(rollback)
SQL 데이터 타입 - Oracle 기준
문자형(Character/String Types)
| 데이터 타입 | 설명 | 예시 |
|---|---|---|
CHAR(n) | 고정 길이 문자 | CHAR(5) → 'ABC ' |
VARCHAR(n) 또는 VARCHAR2(n) | 가변 길이 문자 | VARCHAR(10) → 'ABC' |
TEXT (MySQL에서 사용) | 긴 텍스트 (최대 64KB) | 게시글 본문 등 |
숫자형(Numeric Types)
| 데이터 타입 | 설명 | 예시 |
|---|---|---|
NUMBER(p, s) 또는 DECIMAL(p, s) | 정밀 숫자. p는 전체 자리수, s는 소수점 이하 | NUMBER(5,2) → 999.99 |
INT 또는 INTEGER | 정수 (MySQL/PG/Oracle 공통) | 123, -456 |
FLOAT 또는 REAL | 부동소수점 (정밀도 낮음) | 3.14, -2.71 |
날짜/시간형(Date/Time Types)
| 데이터 타입 | 설명 | 예시 |
|---|---|---|
DATE | 날짜 (년, 월, 일) | 2025-07-09 |
DATETIME | 날짜 + 시간 | 2025-07-09 14:30:00 |
TIMESTAMP | 날짜 + 시간 + 타임존 지원 | 2025-07-09 14:30:00 +09:00 |
INTERVAL (Oracle/PostgreSQL) | 두 날짜 간의 간격 표현 | INTERVAL '3' DAY |
논리형(Boolean Types)
| 데이터 타입 | 설명 | 예시 |
|---|---|---|
BOOLEAN | TRUE 또는 FALSE | TRUE, FALSE |
TINYINT(1) (MySQL 대체) | 0 또는 1 | 0 = FALSE, 1 = TRUE |
기타 데이터 타입
| 데이터 타입 | 설명 | 예시 |
|---|---|---|
BLOB | Binary Large Object, 이미지/동영상 등 | 프로필 사진, 첨부파일 |
CLOB | Character Large Object, 대용량 텍스트 | 대형 기사, 보고서 |
JSON (MySQL/PG 지원) | JSON 형식의 구조화 데이터 | {"name": "John"} |
UUID (PostgreSQL) | 고유 식별자 | 550e8400-e29b-41d4-a716-446655440000 |
SQL 연산자
산술 연산자(Arithmetic Operators)
연산자 설명 예시 +더하기 salary + 1000-빼기 salary - 500*곱하기 salary * 1.1/나누기 salary / 12%나머지 (MySQL) salary % 2비교 연산자(Comparison Operators)
연산자 설명 예시 =같다 salary = 3000!=또는<>같지 않다 department_id != 10>크다 salary > 5000<작다 salary < 5000>=크거나 같다 salary >= 3000<=작거나 같다 salary <= 3000BETWEEN범위 안에 있는지 salary BETWEEN 3000 AND 5000IN여러 값 중에 있는지 job_id IN ('IT_PROG', 'HR_REP')LIKE패턴 매칭 first_name LIKE 'A%'IS NULLNULL 여부 commission_pct IS NULL논리 연산자(Logical Operators)
연산자 설명 예시 AND모두 참일 때 salary > 3000 AND department_id = 10OR하나라도 참일 때 job_id = 'IT_PROG' OR job_id = 'HR_REP'NOT부정 NOT (salary > 5000)
SELECT
SELECT 문은 SQL에서 데이터를 조회하는 가장 기본이자 핵심적인 명령어이다. 데이터베이스에서 원하는 데이터를 추출할 때 사용한다. 실질적으로 CREATE, ALTER, INSERT, DELETE, UPDATE, ROLLBACK, COMMIT 명령어보다 훨씬 더 많이 쓰는 명령어다.
기본적인 SELECT
SELECT문에서 SELECT와 FROM은 필수적으로 들어가야한다. FROM 같은 경우 어떤 테이블을 들고올 지 결정한다.
SELECT * FROM EMPLOYEES;
즉 위에 SQL은 EMPLOYEES라는 테이블에서 * - (Wildcard - 모든 열) 해당 테이블에 있는 모든 열을 조회한다는 의미이다.
전체 columns를 불러오는 게 아닌 특정 column만 불러오고 싶다면 SELECT 뒤에 원하는 Column 명을 기입하면 된다.
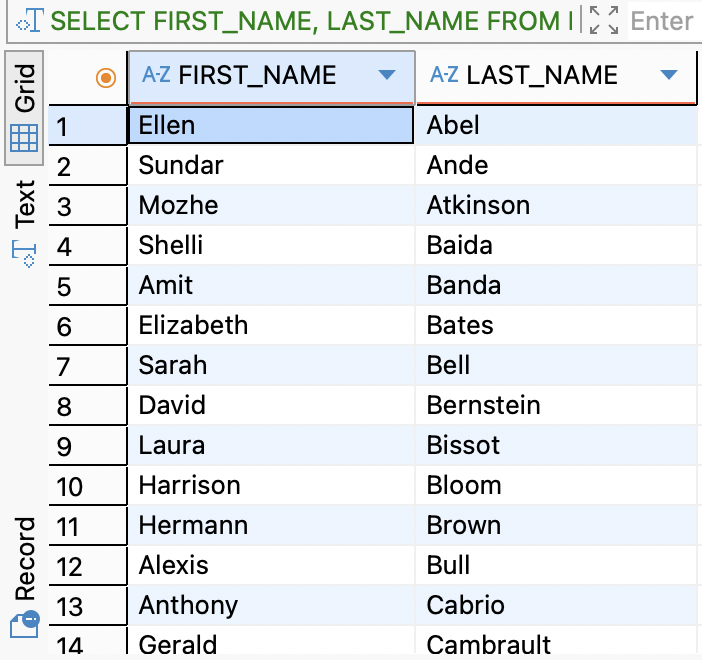
SELECT FIRST_NAME, LAST_NAME FROM EMPLOYEES;
AS
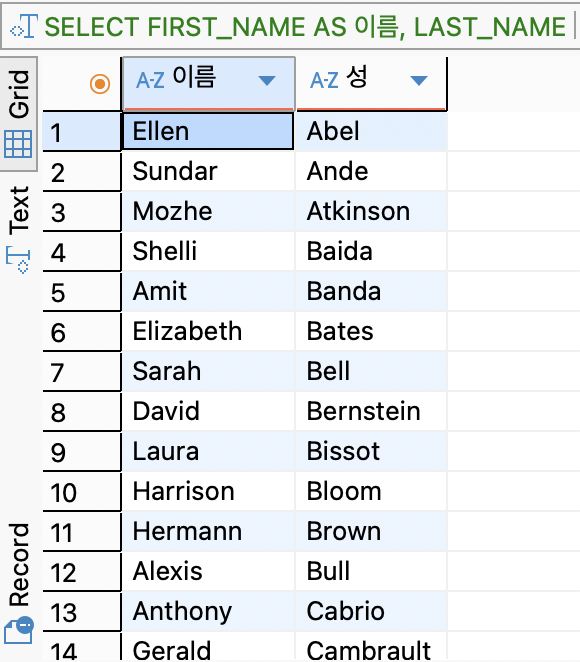
column을 선택해서 불러왔지만 column 명을 변경하고 싶을 때가 있을 것이다. 이때는 column 명 뒤에 AS 000를 붙어 원하는 column 명으로 변경하면 된다.
SELECT FIRST_NAME AS 이름, LAST_NAME AS 성 FROM EMPLOYEES;

DISTINCT
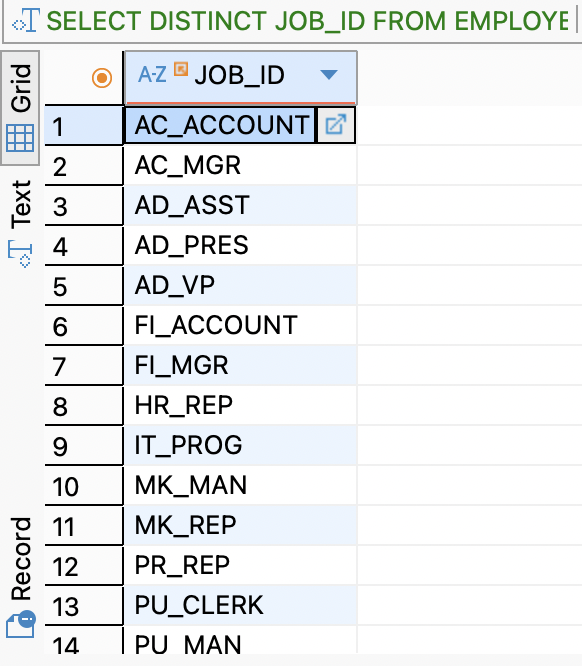
중복된 값을 제거하고 싶을 때는 DISTINCT를 이용하여 중복된 값을 제거할 수 있다.
SELECT DISTINCT JOB_ID FROM EMPLOYEES;
집계함수 - Aggregate Functions
SQL에서 자주 사용되는 집계 함수(Aggregate Functions)는 데이터를 요약하거나 집계할 때 사용된다.
자주 쓰이는 SQL 집계 함수
함수 설명 예시 COUNT()행의 개수를 셈 SELECT COUNT(*) FROM EMPLOYEES;SUM()총합 계산 SELECT SUM(SALARY) FROM EMPLOYEES;AVG()평균 계산 SELECT AVG(SALARY) FROM EMPLOYEES;MAX()최대값 반환 SELECT MAX(SALARY) FROM EMPLOYEES;MIN()최소값 반환 SELECT MIN(SALARY) FROM EMPLOYEES;SELECT COUNT(*) AS 총직원수, SUM(SALARY) AS 총급여, AVG(SALARY) AS 평균급여, MAX(SALARY) AS 최고급여, MIN(SALARY) AS 최저급여 FROM EMPLOYEES;

CASE WHEN ... THEN
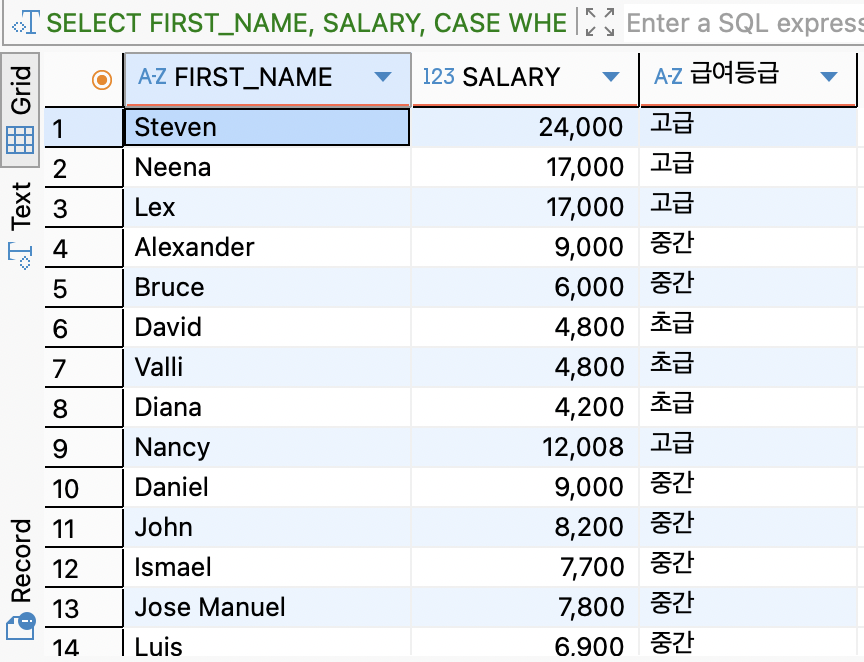
CASE WHEN ... THEN ... 구문은 SQL에서 조건문을 작성할 때 사용하는 조건식 함수다.
SELECT FIRST_NAME, SALARY, CASE WHEN SALARY >= 10000 THEN '고급' WHEN SALARY >= 5000 THEN '중간' ELSE '초급' END AS 급여등급 FROM EMPLOYEES;
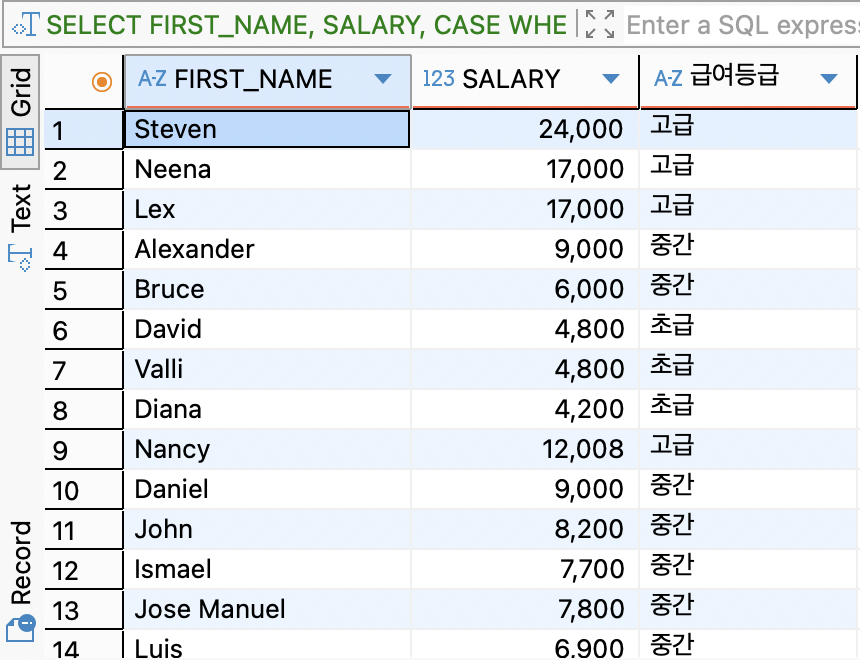
WHERE
WHERE 절은 데이터를 조회할 때 조건을 지정하는 구문이다. 테이블의 모든 행이 아닌, 조건을 만족하는 행만 필터링할 수 있게 해준다. SELECT문에서 필수가 아니며 참고사항으로 SELECT문에서 필수로 들어가야할 명령어는 SELECT, FROM이다. WHERE 절에는 주로 비교 연산자, 논리 연산자, 특수 조건 연산자을 사용하여 filter 기능을 처리한다.
비교 연산자
| 연산자 | 의미 | 예시 |
|---|---|---|
| = | 같다 | salary = 5000 |
| <> 또는 != | 같지 않다 | department_id != 10 |
| > | 초과 | salary > 10000 |
| >= | 이상 | salary >= 5000 |
| < | 미만 | hire_date < '2020-01-01' |
| <= | 이하 | salary <= 8000 |
SELECT EMPLOYEE_ID, LAST_NAME, JOB_ID , SALARY , COMMISSION_PCT , MANAGER_ID FROM EMPLOYEES WHERE SALARY >= 5000
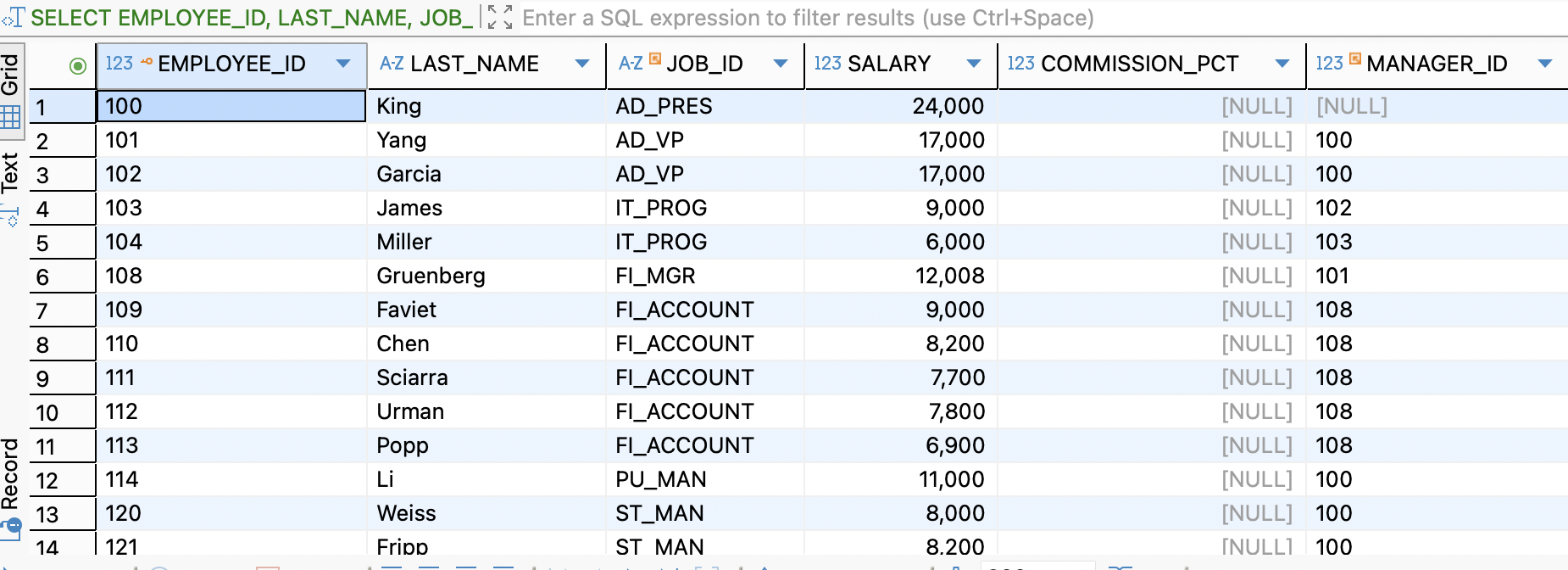
논리 연산자
| 연산자 | 설명 | 예시 |
|---|---|---|
AND | 모든 조건 만족 | salary > 5000 AND department_id = 30 |
OR | 하나라도 만족 | department_id = 10 OR department_id = 20 |
NOT | 조건 반대 | NOT job_id = 'IT_PROG' |
SELECT EMPLOYEE_ID, LAST_NAME, JOB_ID , SALARY , COMMISSION_PCT , MANAGER_ID FROM EMPLOYEES WHERE SALARY >= 5000 AND JOB_ID = 'IT_PROG' ;

특수 조건 연산자
IN 연산자 - 집합 안에 있는지 확인
집합 비교 연산자라고 불리며, AND 조건이 여러개인 경우 IN 연산자를 사용하면 편리하게 Query를 처리할 수 있다.-- IN: 부서가 10, 20, 30 중 하나인 직원 조회 SELECT * FROM employees WHERE department_id IN (10, 20, 30);
BETWEEN 연산자 - 범위 내 포함 여부 확인
범위 비교 연산자라고 불리며BETWEEN A AND B형식으로 사용한다. A 와 B 사이에 있는 ROW를 전부 추출하는 연산자이다.-- BETWEEN: 급여가 5000 이상 10000 이하 SELECT * FROM employees WHERE salary BETWEEN 5000 AND 10000;
LIKE 연산자 - 문자열 패턴 매칭 (와일드카드 %, _ 등 사용)
패턴 매칭 연산자라고 불리며 문자열이 특정 패턴과 일치하는 지를 확인한다. 와일드카드(%, _)를 함께 사용해 유연하게 매칭할 수 있다.-- LIKE: 'S'로 시작하는 이름 SELECT * FROM employees WHERE first_name LIKE 'S%'; -- LIKE : 이름에 'an'이 포함된 모든 직원 SELECT * FROM employees WHERE first_name LIKE '%an%'; -- LIKE : 이름이 'A'로 시작하고 두 번째 문자가 아무거나이며, 세 글자인 이름 SELECT * FROM employees WHERE first_name LIKE 'A__';IS NULL 연산자
SQL에서 NULL은 정의되지 않는 상태를 의미한다. 즉, 값이 없는 상태가 아닌 값이 없는 게 아닌 있을 예정인 데이터를 의미하는데, 해당 값이 NULL인 데이터들을 조회할 떄 IS NULL을 사용한다.SELECT * FROM employees WHERE manager_id IS NULL;
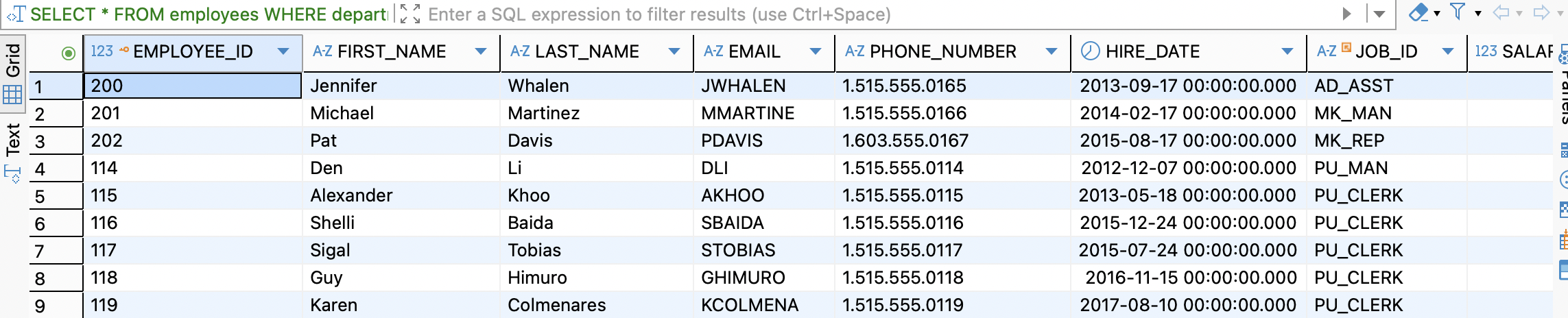
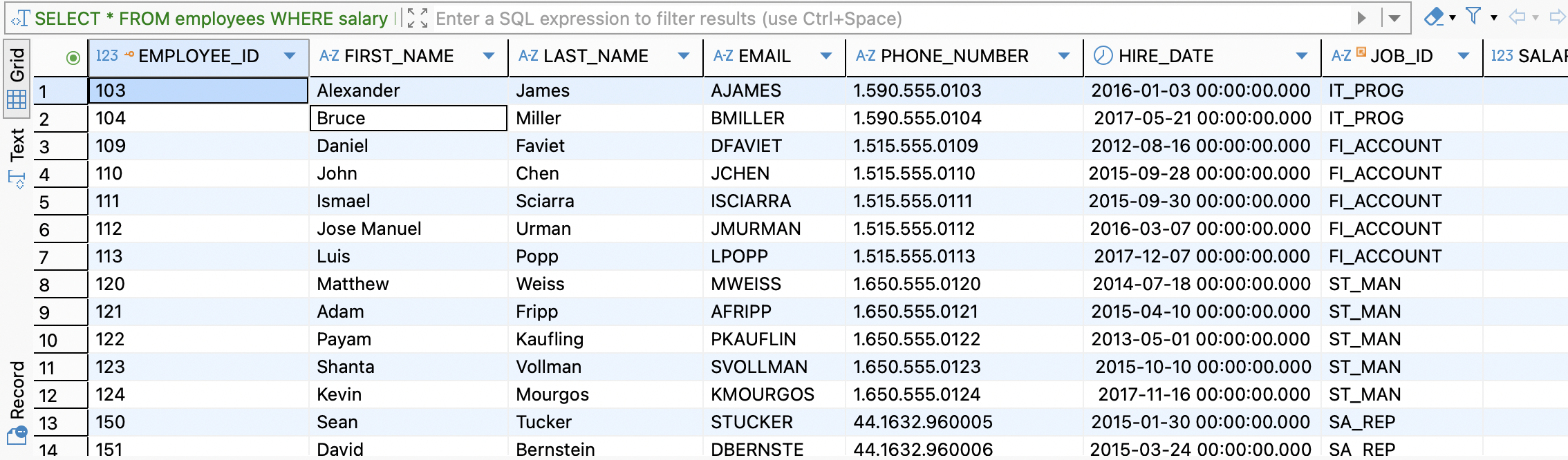

GROUP BY
GROUP BY는 SQL에서 데이터를 그룹화할 때 사용되는 절로, 집계 함수(Aggregate Function)와 함께 자주 사용된다. 데이터를 특정 컬럼의 값에 따라 묶고, 그 그룹별로 SUM, AVG, COUNT 등을 계산하고 싶을 때 필요하다.
-- DEPARTMENT_ID를 GROUP 기준으로 묶고, 그룹별 평균 연봉을 계산 SELECT DEPARTMENT_ID, AVG(salary) AS AVG_SALARY FROM employees GROUP BY DEPARTMENT_ID;
다중 Column GROUP BY
SELECT JOB_ID , DEPARTMENT_ID, COUNT(*) AS 개수 FROM employees GROUP BY JOB_ID , DEPARTMENT_ID;
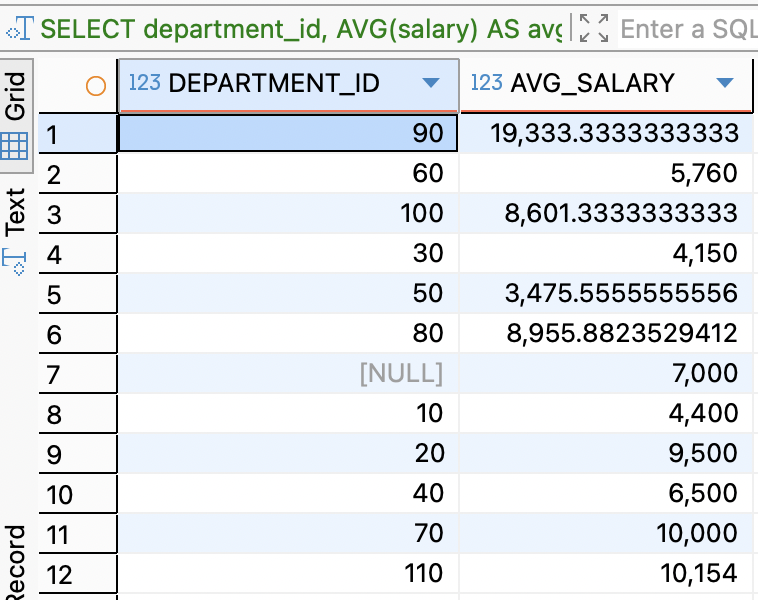
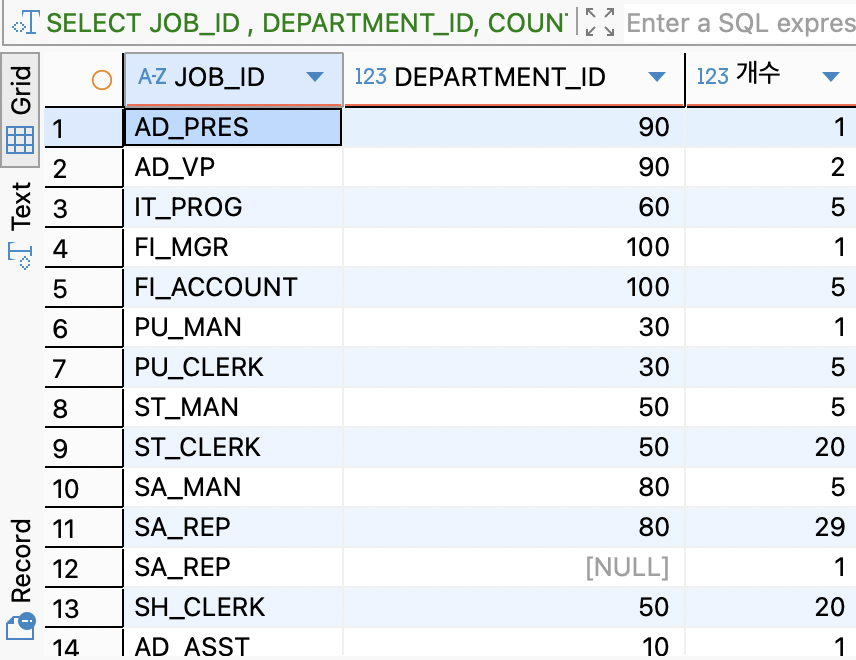
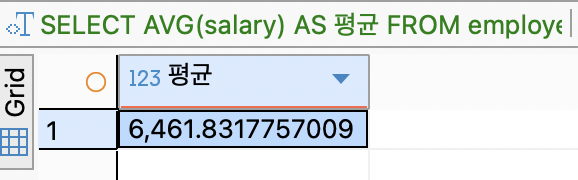
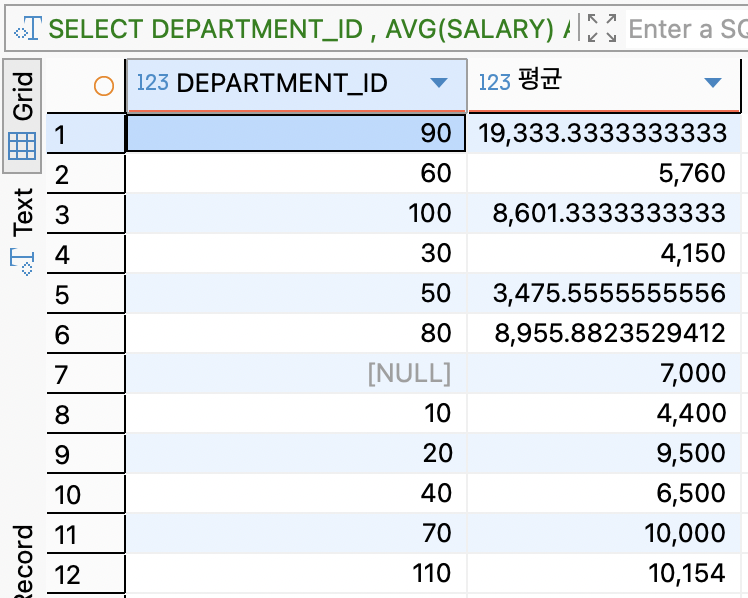
GROUP BY유무 비교전체 연봉 평균
SELECT AVG(salary) AS 평균 FROM employees;
부서 그룹별 연봉 평균
SELECT DEPARTMENT_ID , AVG(SALARY) AS 평균 FROM employees GROUP BY DEPARTMENT_ID ;
HAVING
SQL에서 집계 함수(SUM, AVG, COUNT 등)를 사용해 데이터를 그룹화(GROUP BY)한 후, 그 결과에 조건을 걸고 싶을 때 사용하는 것이 바로 HAVING 절이다. SQL에서는 WHERE 절로 행(Row)을 필터링할 수 있지만, 집계 함수가 적용된 결과에는 사용할 수 없다. 이럴 때 HAVING 절을 이용하면 그룹화된 데이터 중에서 조건을 만족하는 그룹만 선택할 수 있다.
EMPLOYEES 테이블에서 DEPARTMENT_ID로 그룹화한 뒤, 그 중 평균 급여가 5000 이상인 부서만 추출
SELECT DEPARTMENT_ID, AVG(SALARY) AS 평균 FROM EMPLOYEES GROUP BY DEPARTMENT_ID HAVING AVG(SALARY) > 5000;
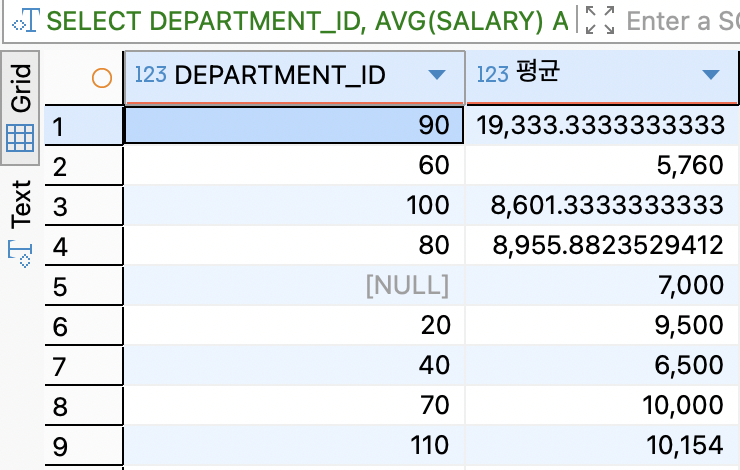
필자는 SQL을 공부하면서 헷갈렸던 것 중 하나가 WHERE과 HAVING이다. 둘 다 filtering을 걸어서 특정 데이터만 불러오는 거라 같은 역할을 한다고 생각할 수 있다. 헷갈린다면 먼저 SQL 실행순서를 알면 좀 더 이해하기가 편하다.
| 단계 | 절 (Clause) | 설명 |
|---|---|---|
| ① | FROM | 테이블 또는 조인된 데이터를 불러옴 |
| ② | WHERE | 조건에 따라 행(Row) 필터링 |
| ③ | GROUP BY | 특정 컬럼 기준으로 그룹화 |
| ④ | HAVING | 그룹화된 결과에서 집계 조건 필터링 |
| ⑤ | SELECT | 최종적으로 출력할 컬럼 선택 |
| ⑥ | ORDER BY | 정렬 기준에 따라 결과 정렬 |
| ⑦ | LIMIT / OFFSET | (선택) 일부 결과만 반환할 때 사용 |
모든 SELECT 문은 먼저 FROM 절을 통해 데이터를 불러온다. 이후 조건에 따라 필터링을 하는 친구가 WHERE 절이다. 그 이후 필터를 거친 데이터를 GROUP BY 절을 통해 그룹화한 후, 그룹화된 결과를 필터링 하는 친구가 HAVING 절이다. 즉, WHERE 절은 GROUP BY 절 이전에 먼저 필터하며, HAVING 절은 GROUP BY 절 이후에 집계 조건들을 필터링을 처리한다고 생각하면 편하다.
SELECT department_id, AVG(salary) AS avg_sal FROM employees WHERE job_id != 'IT_PROG' AND department_id IS NOT NULL GROUP BY department_id HAVING AVG(salary) > 6000 ORDER BY avg_sal DESC;1. FROM: employees 테이블에서 시작
2. WHERE: job_id가 'IT_PROG'가 아닌 행만 남김
3. GROUP BY: department_id 기준으로 그룹화
4. HAVING: 평균 급여가 6000 초과인 부서만 선택
5. SELECT: 선택된 컬럼만 출력
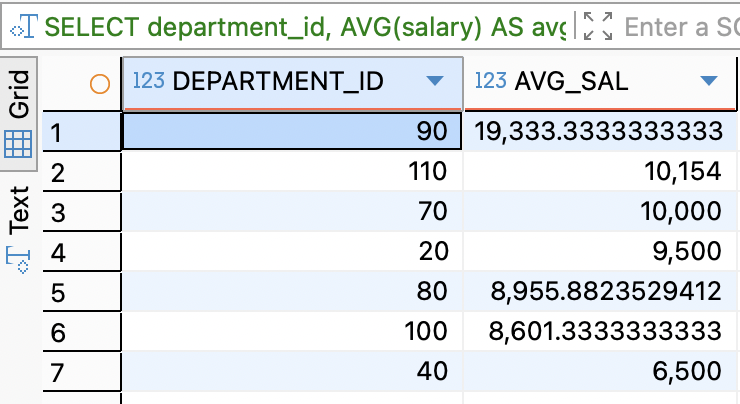
ORDER BY
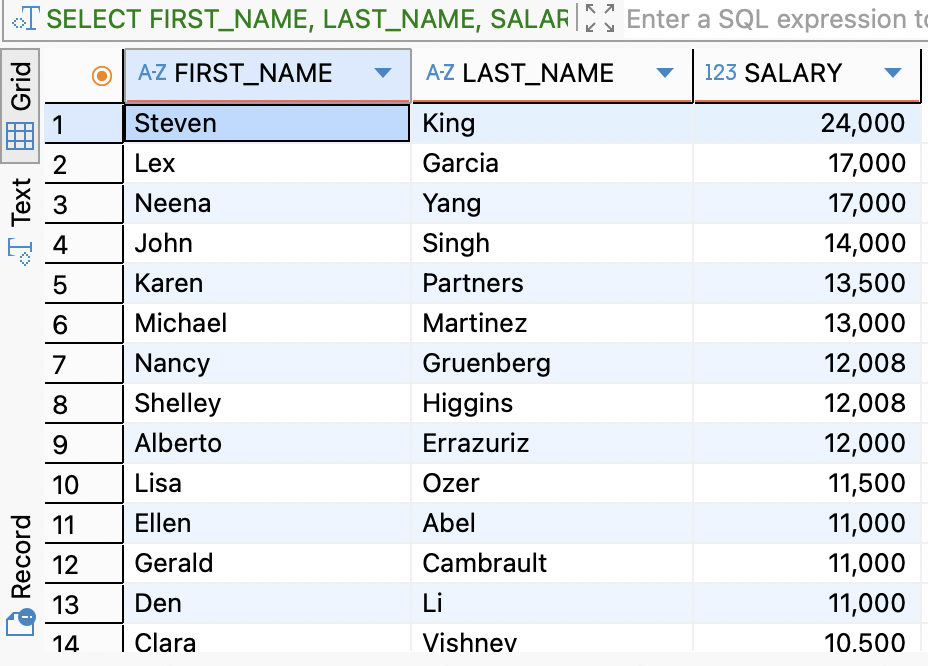
ORDER BY는 SQL에서 결과 행들을 원하는 컬럼 기준으로 정렬할 때 사용하는 절이다. 기본적으로 오름차순(ASC)이 기본이며, 내림차순(Descending)은 DESC 키워드를 붙여서 지정한다.
SELECT FIRST_NAME, LAST_NAME, SALARY FROM EMPLOYEES ORDER BY SALARY DESC, LAST_NAME ASC;
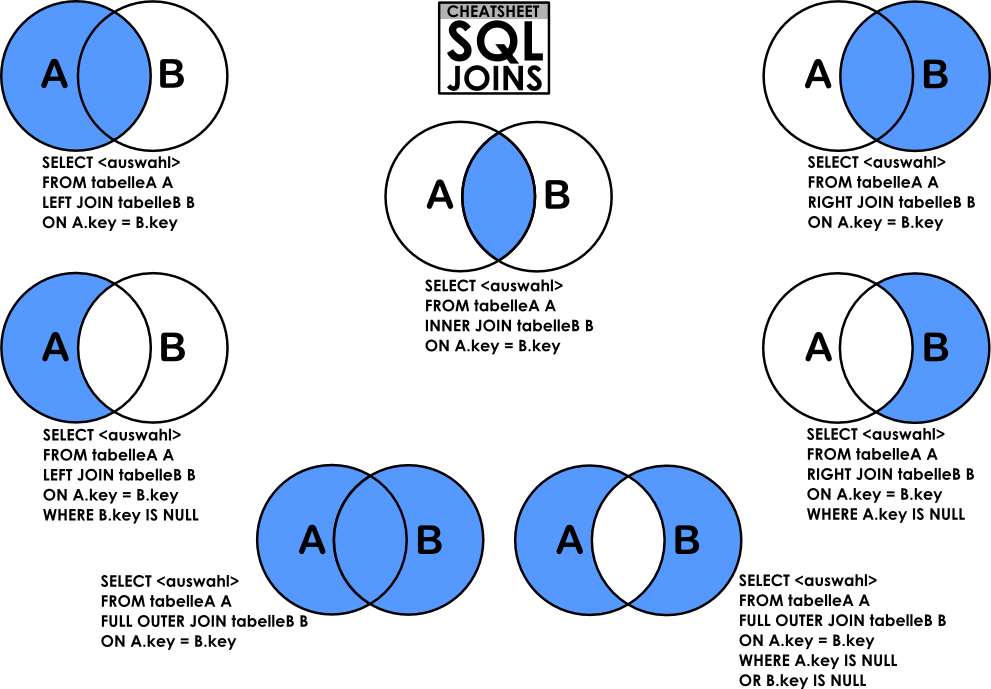
JOIN
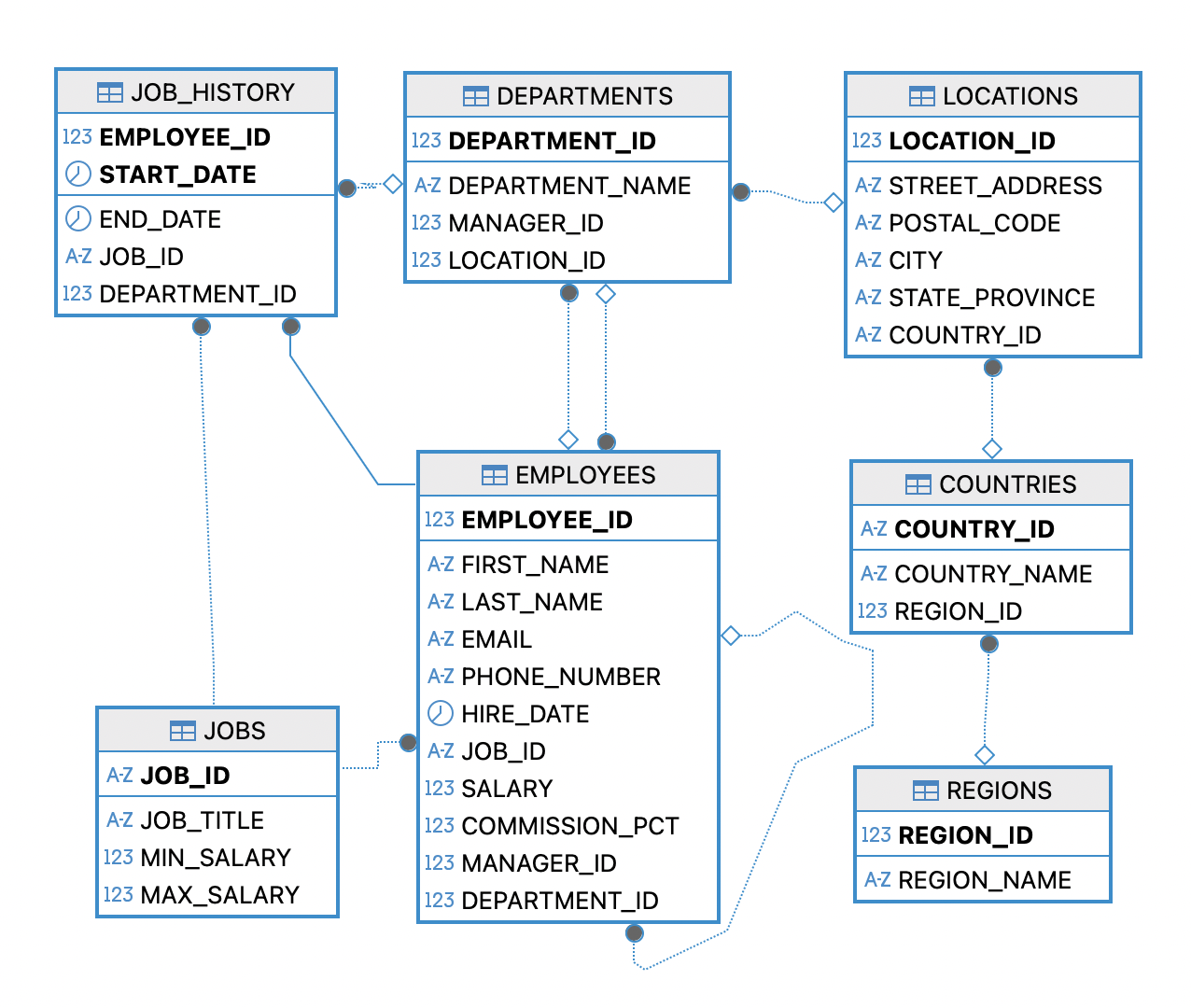
관계형 데이터베이스(RDB)에서는 데이터가 여러 테이블에 나누어 저장된다. JOIN은 두 개 이상의 테이블을 연결하여 원하는 데이터를 하나로 합쳐서 조회할 수 있게 해주는 SQL 기능입니다. 예를 들어 EMPLOYEES 테이블에는 직원 정보만 있고, DEPARTMENTS 테이블에는 부서 정보만 있는 경우, “어느 부서에 속한 직원인지” 확인하려면 두 테이블을 연결해야한다. 이때 사용하는 것이 바로 JOIN입니다.
INNER JOIN(교집합)
INNER JOIN은 두 테이블 간에 조건이 일치하는 행만 결과로 반환하는 조인 방식이다. 즉 두 양쪽 테이블 모두에 존재하는 데이터의 교집합만 보여준다. 즉, 조인 조건에서 NULL이나 값이 존재하지 않는다면 데이터를 가져오지 않는다. 특이사항으로는 JOIN할 때 성능 최적화를 위해서 Index가 있는 Column으로 조인하면 조회속도가 빠르다.
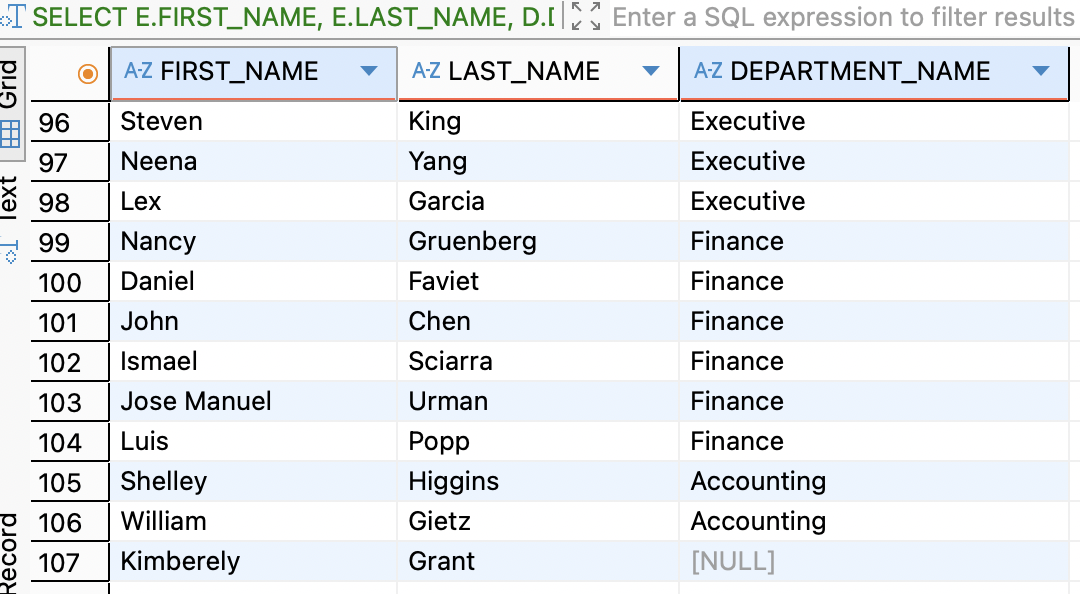
SELECT E.FIRST_NAME, E.LAST_NAME, D.DEPARTMENT_NAME FROM EMPLOYEES E INNER JOIN DEPARTMENTS D ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;
OUTER JOIN
OUTER JOIN은 조인 대상 테이블 간 일치하지 않는 행도 포함해서 조회할 수 있도록 해주는 조인 방식이다. 즉 두 테이블을 조인할 때 한쪽에는 값이 있고 다른 쪽에는 값이 없는 경우도 포함하고 싶다면 OUTER JOIN을 사용한다.
| 조인 종류 | 설명 |
|---|---|
LEFT OUTER JOIN | 왼쪽 테이블을 기준으로, 오른쪽 테이블에 매칭이 없어도 결과에 포함 |
RIGHT OUTER JOIN | 오른쪽 테이블을 기준으로, 왼쪽 테이블에 매칭이 없어도 결과에 포함 |
FULL OUTER JOIN | 양쪽 모두 포함. 어느 쪽이든 매칭이 없어도 결과에 포함 |
LEFT OUTER JOIN
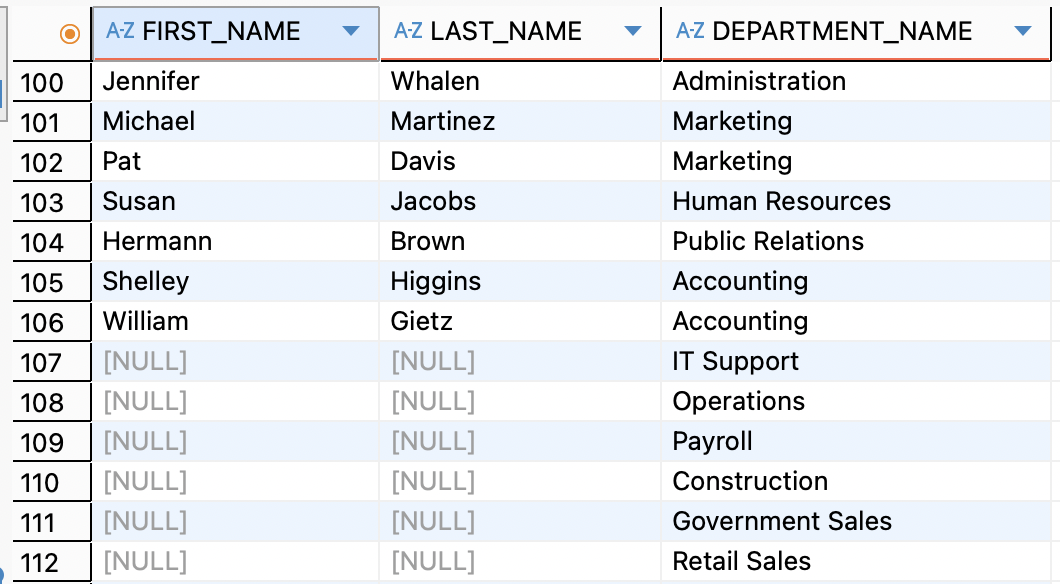
SELECT E.FIRST_NAME, E.LAST_NAME, D.DEPARTMENT_NAME FROM EMPLOYEES E LEFT OUTER JOIN DEPARTMENTS D ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;
RIGHT OUTER JOIN
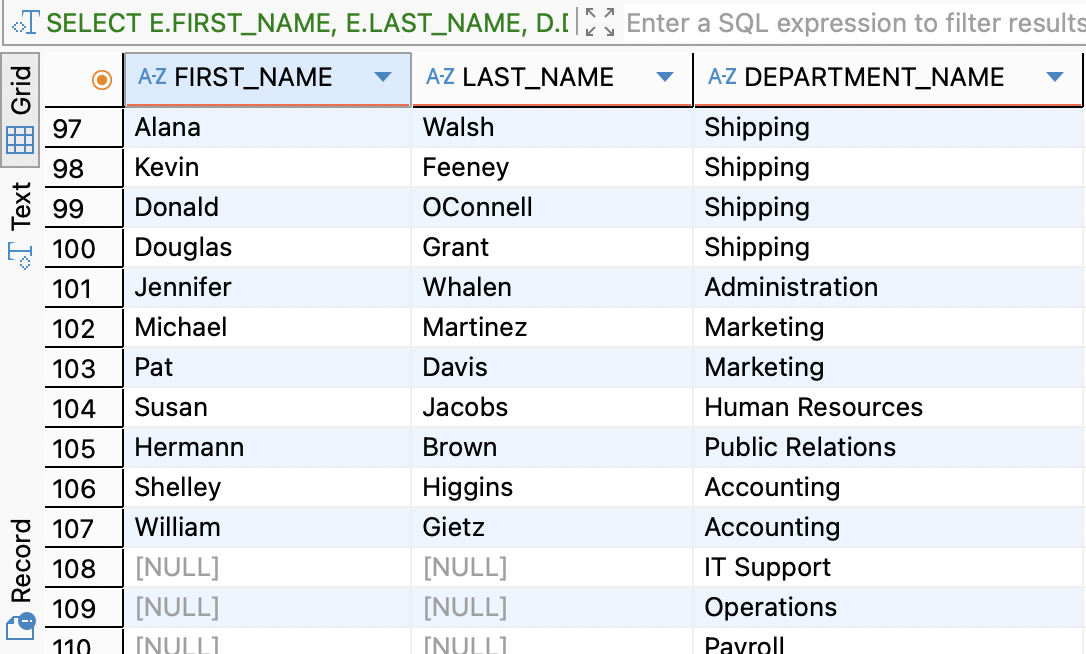
SELECT E.FIRST_NAME, E.LAST_NAME, D.DEPARTMENT_NAME FROM EMPLOYEES E RIGHT OUTER JOIN DEPARTMENTS D ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;
FULL OUTER JOIN
-- Oracle SELECT E.FIRST_NAME, E.LAST_NAME, D.DEPARTMENT_NAME FROM EMPLOYEES E FULL OUTER JOIN DEPARTMENTS D ON E.DEPARTMENT_ID = D.DEPARTMENT_ID; -- Mysql SELECT E.FIRST_NAME, E.LAST_NAME, D.DEPARTMENT_NAME FROM EMPLOYEES E LEFT JOIN DEPARTMENTS D ON E.DEPARTMENT_ID = D.DEPARTMENT_ID UNION SELECT E.FIRST_NAME, E.LAST_NAME, D.DEPARTMENT_NAME FROM EMPLOYEES E RIGHT JOIN DEPARTMENTS D ON E.DEPARTMENT_ID = D.DEPARTMENT_ID;