
Index란?
1.색인(목차)를 의미한다.
만약에 어떤 자료에 목차가 없다면? → 모든 자료를 한번은 끝까지 읽어야 한다. → 비효율적
Index 사용하는 이유
- DB의 Index는 데이터 조회 성능 향상을 위해 사용된다.
- 원하는 데이터를 빠르게 찾기 위해서!
Index의 특장과 장점
- Index의 가장 큰 특징은 데이터들이 정렬 되어있다는 점.
- Where절의 효율성 증가
- Oreder by절의 효율성 증가
- MIN,MAX 값 획득의 효율성 증가
예시 : Data 라는 Column을 Index로 지정한 경우
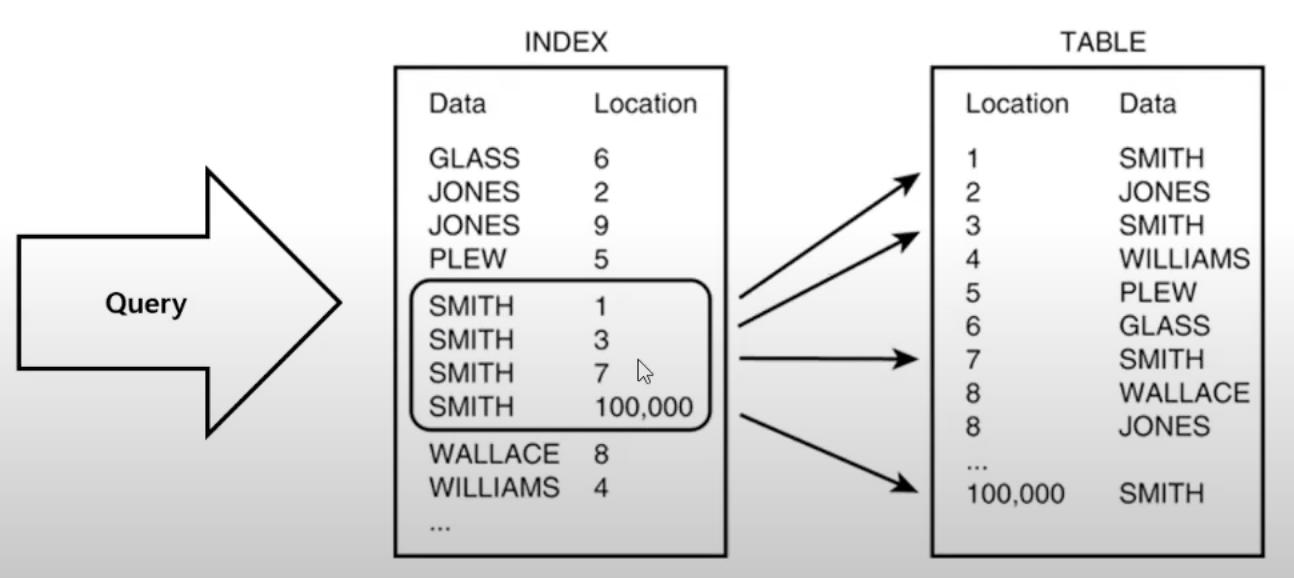
인덱스의 단점
- 정렬된 상태를 유지 시켜줘야 한다는 점이다.
- 인덱스는 결국 지정한 컬럼들을 기준으로 메모리 영역에 일종의 목차를 만드는 것.
- 기존에서는 insert, updatem delete 작업을 실제 테이블에서만 수행하면 되었으나 Index까지 갱신해야 하기 때문에 작업량과 시간이 증가.( 단 update와 delete를 위해서 조회할 경우에는 빠르게 가능하다 )
- select성능 향상을 위해 나머지 성능을 저하시킨 형태.
Index의 구조
Index는 B-Tree(Balanced-Tree)라는 자료구조를 택하고 있다.
Root/Branch/Leaf Node 로 구성되어 있다.
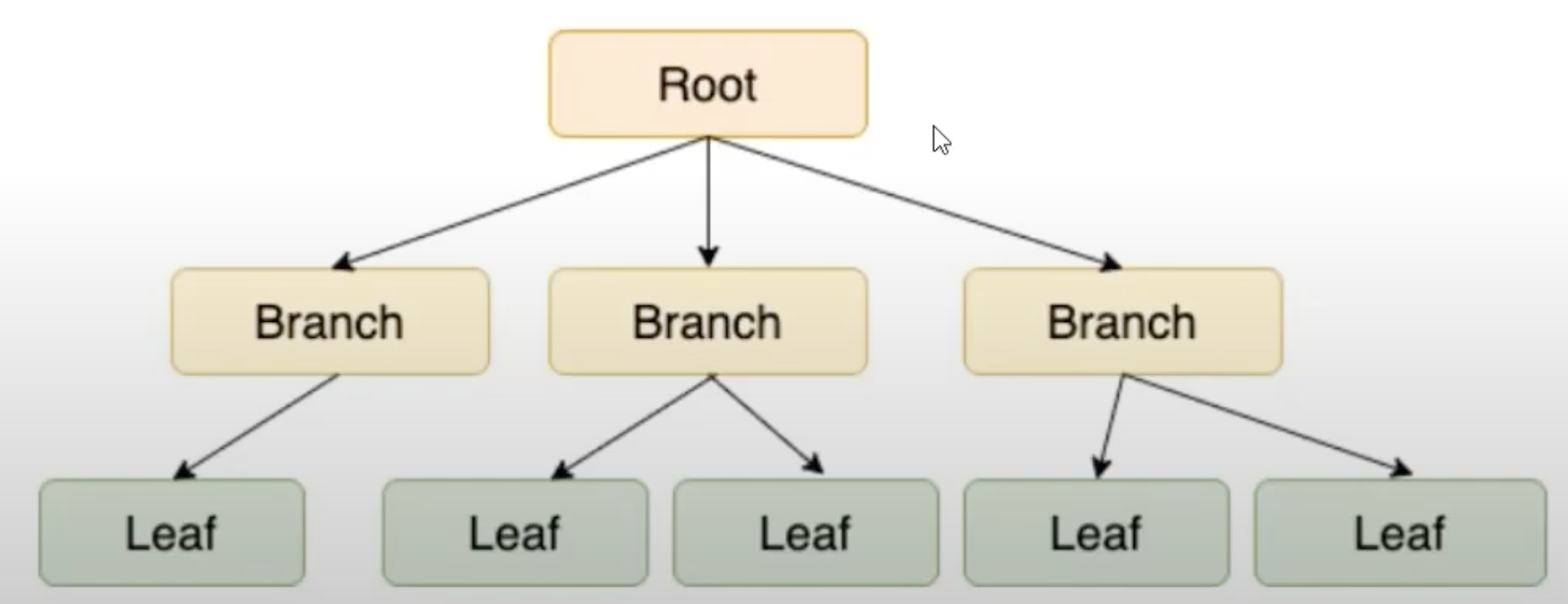
B-Tree란?
- Binary Search Tree에서 발전되어 모든 리프노드들이 같은 레벨을 가질 수 있도록 자동으로 균형을 맞추는 트리.
- B트리는 이진트리와 다르게 하나의 노드에 많은 수의 정보를 가질 수 있다.
- 최대 M개의 자식을 가질 수 있는 B트리는 M차 B트리라고 하며 다음과 같은 특징을 갖는다.
- 노드는 [M/2]개 부터 M개 까지의 자식을 가질 수 있다. M=3이라면 2~3개
- 노드에는 [M/2]-1개 부터 M-1개의 키가 포함될 수 있있다. M=3이라면 1~2개
- 노드의 키가 X개 라면 자식의 수는 X+1개 이다.
왜 B Tree를 사용하나? BST도 O(logN)인데?
Cumputer System에 대해서 먼저 알 필요가 있다.
- cpu : 프로그램 코드가 실제로 실행되는 곳
- Main memory(RAM) : 실행 중인 프로그램의 코드들과 코드 실행에 필요한 혹은 그 결과 데이터들이 상주하는 곳(휘발성 메모리)
- Secondary storage(SSD or HDD) : 프로그램과 데이터가 영구적으로 저장되는 곳, 실행 중인 프로그램의 데이터 일부가 임시 저장되는 곳(비휘발성 메모리)
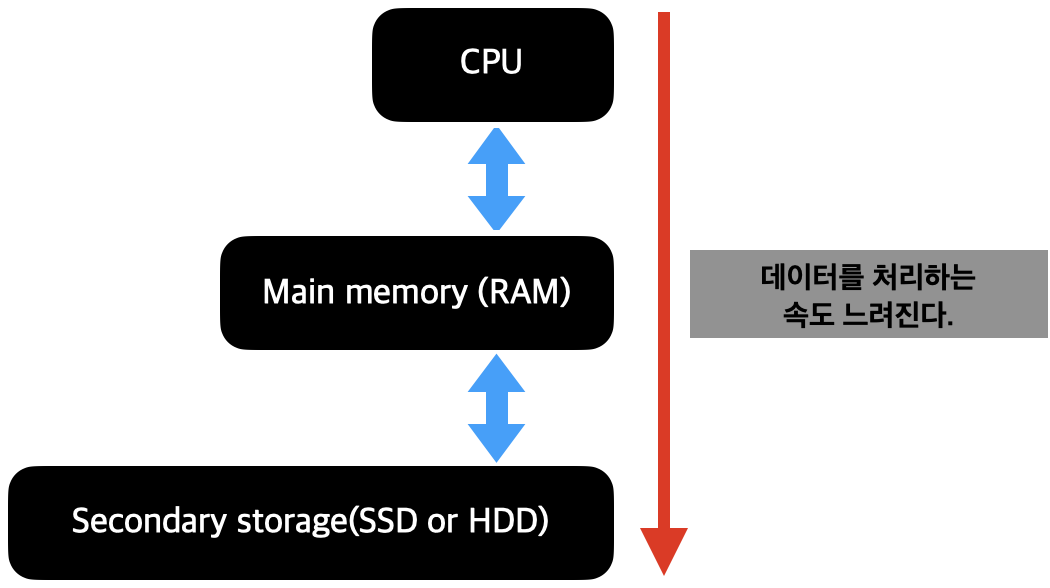
- DB는 Secondary storage에 저장된다.
- 최대한 적게 접근하는 것이 성능 면에서 좋다.
- block 단위로 읽고 쓰기 때문에 연관된 데이터를 모아서 저장하면 더 효율적으로 읽고 쓸 수 있다.
AVL tree index(b) vs B tree index(b)
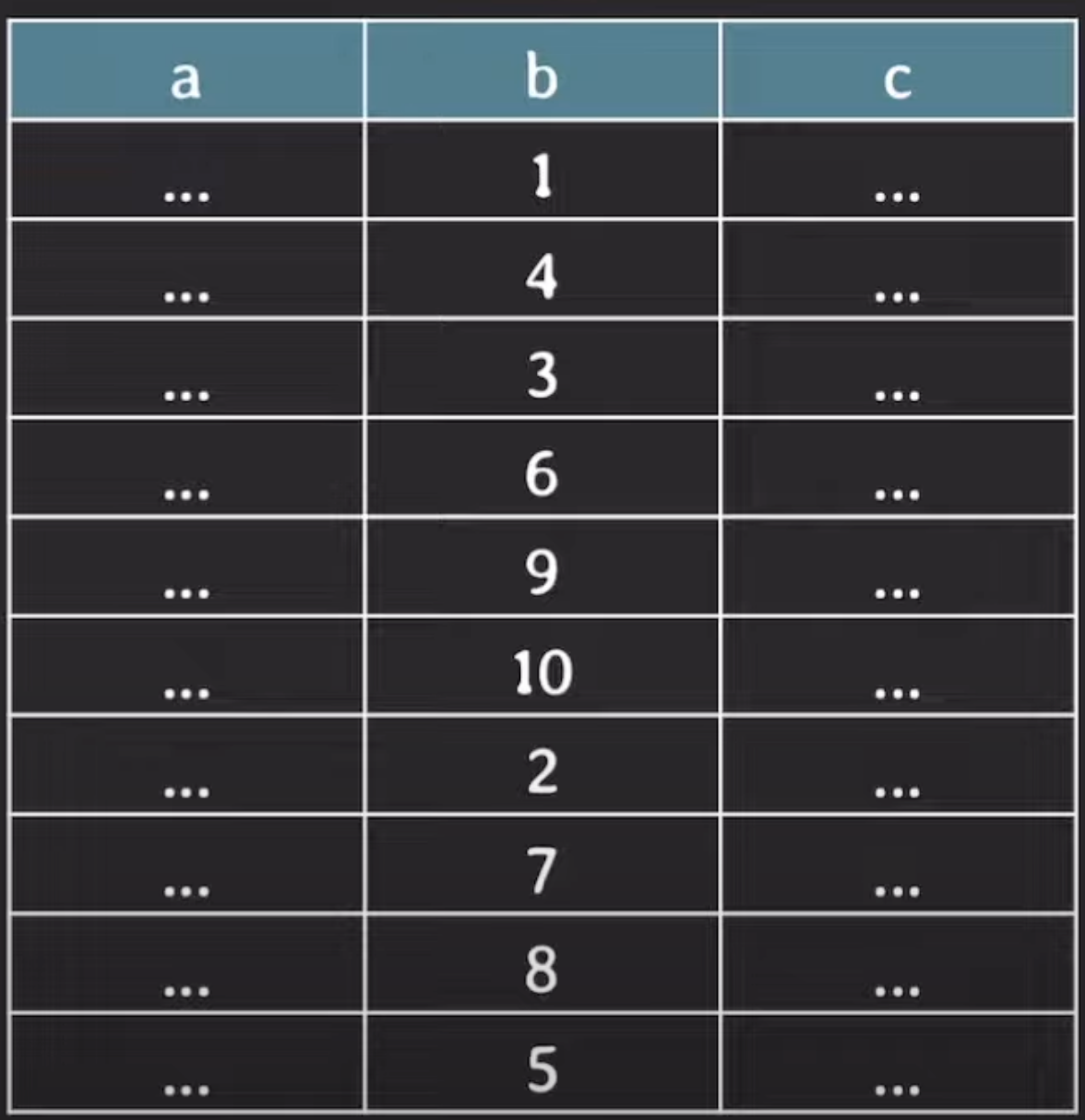
가정1 : tree의 각 노드는 서로 다른 block에 있다고 가정
가정2 : 초기에는 root노드를 제외한 모든 노드는 secondary storage에 있다고 가정
가정3 : 초기에는 데이터 자체도 모두 secondary storage에 있다고 가정.
1.AVL tree index(b)
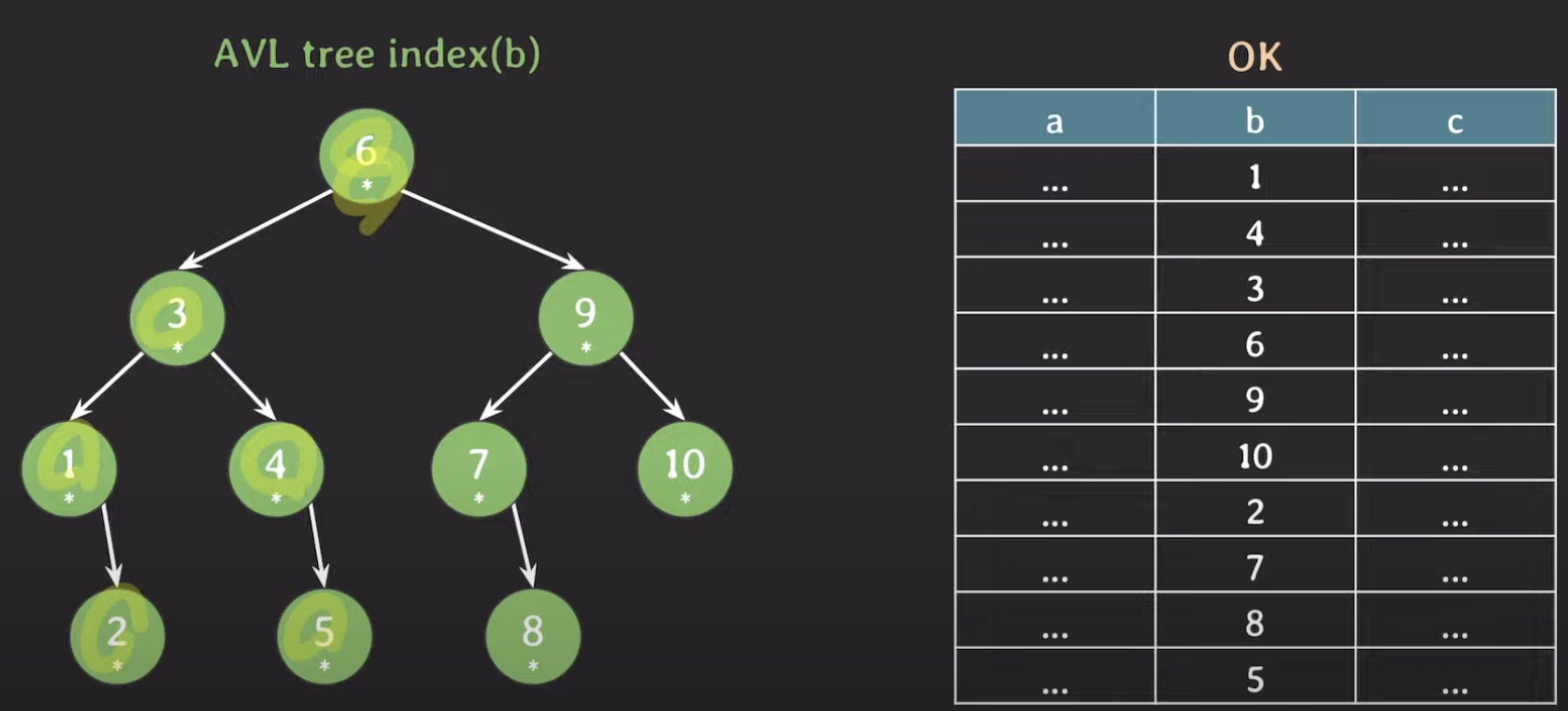
여기서 b=5인 데이터를 조회한다면?
1. 여기서 root Node인 6만 메모리상에 올라가있다. 즉 하위 노드정보는 Secondary strage에서 읽어와야 한다. 그 하위 노드로 이동하는 경우에도 마찬가지로 Secondary strage읽고 메모리상에 올린다.
6(Main) → 3(St) → 4(St) → 5(St) → DB(St) 즉 총 4번의 Secondary strage를 조회한다.
2.B tree index(b) 5차 B tree 사용
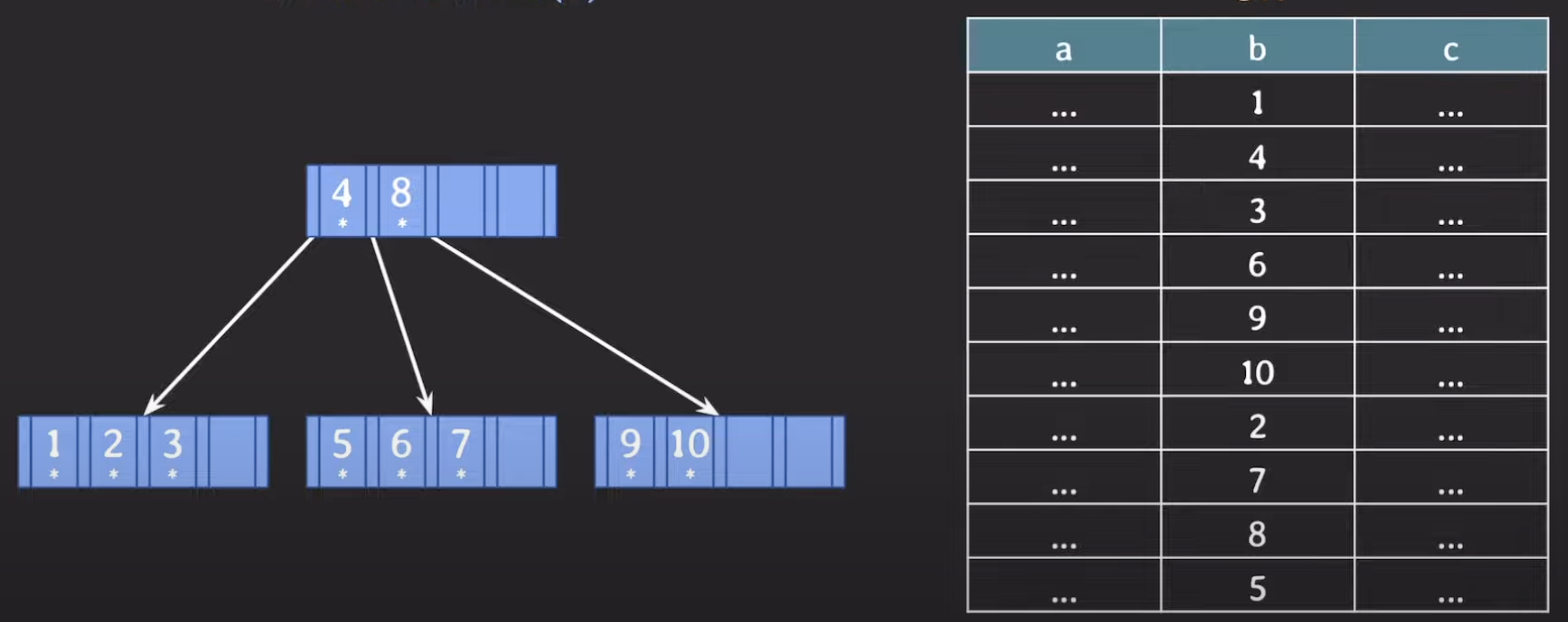
5차 B tree index는
- 자녀 노드 수 : 최소 3개 ~ 최대 5개
- 노드의 데이터 수 : 최소 2개 ~ 최대 4개
자녀 노드 수의 차이가 발생 → 데이터 탐색 범위를 빠르게 좁힐 수 있다.
시간복잡도가 같은 O(logN)이라고 하더라도 Secondary strage를 조회를 반복하는 횟수가 줄어들기 때문에 검색효율이 증가하게 된다.
프로젝트에 적용은?
프로젝트 내부에서 Post를 조회할때 카테고리별로 찾아와야한다.
Post테이블에서 Index를 category로 설정해주면 다음과 같은 메모리상에서의 정렬이 생긴다.
@Table(name = "post", indexes = {@Index(columnList = "category")})
public class Post extends Timestamped {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;생성되는 index는 다음과 같을것.

만약 인덱스를 지정하지 않는다면 흩어진 category를 선택하기위해서 모든 데이터를 조회해야 한다.
그러나 위와같이 index를 적용하면서 category를 정렬시켜서 필요한 부분만 빠르게 조회할 수 있다.
후기
어떻게보면 적용방법은 간단하나 그 원리와 왜 사용하는가? 를 고민하고 공부하니 자료를 정리하고 이애해는것도 시간이 제법 걸린것 같다. 이제는 index를 왜 해야하고 어떤 경우에 해야하는지 약간은 생각할 수 있을것 같다.
프로젝트에도 적용해보면서 메모리상에 index가 어떻게 만들어질지 알 수 있었다.
정리한 내용들은 사실 참고 영상이나 자료들을 거진 따라서 작성한것이나 그래도 일부분은 내가 이해한바로 정리하기 위해 작성하면서 내용을 다시 상기하는 시간이 될 수 있었다.
참고 사이트(영상)
B-Tree Test : B-Tree Visualization
인덱스의 개념과 사용이유 : 정윤오님의 영상
왜 B Tree를 사용하는가? : 쉬운코드 영상 : B tree가 왜 인덱스(Index)로 사용되는지를 설명합니다.감사합니다.
