해당글은 작성중인 글이다. 임시저장 기능에 이상이 생겨, 이전 포스팅이 날아간 문제로 선 출간 > 업데이트를 반복할 예정
Keywords
- 단층 LSTM
- Lagging
- Univariate, Multivariate, Bivariate
- Diff, 선후관계, Spread, Seq2Seq
LSTM
LSTM has feedback connections. It can process not only single data points (such as images), but also entire sequences of data (such as speech or video). For example, LSTM is applicable to tasks such as unsegmented, connected handwriting recognition,[2] speech recognition[3][4] and anomaly detection in network traffic or IDSs (intrusion detection systems).
출처: https://en.wikipedia.org/wiki/Long_short-term_memory
LSTM(Long Short-Term Memory)는, Feedback 커넥션을 특징으로한다. 이미지와 같은 단일 데이터를 처리할뿐 아니라, Speech 또는 Video와 같은 Sequence 데이터를 처리할수 있다. 예를들어, 필기인식, 음성인식등에서 사용된다.
LSTM과 RNN의 차이점이라면, RNN은 하나의 Activation Function을 사용해서 이전 레이어()의 출력을 다음 입력레이어() 입력값으로만 사용하기에 레이어가 길어질수록 이전 Sequnce의 정보가 희미해지는 경향(장기의존성)이 존재한다.
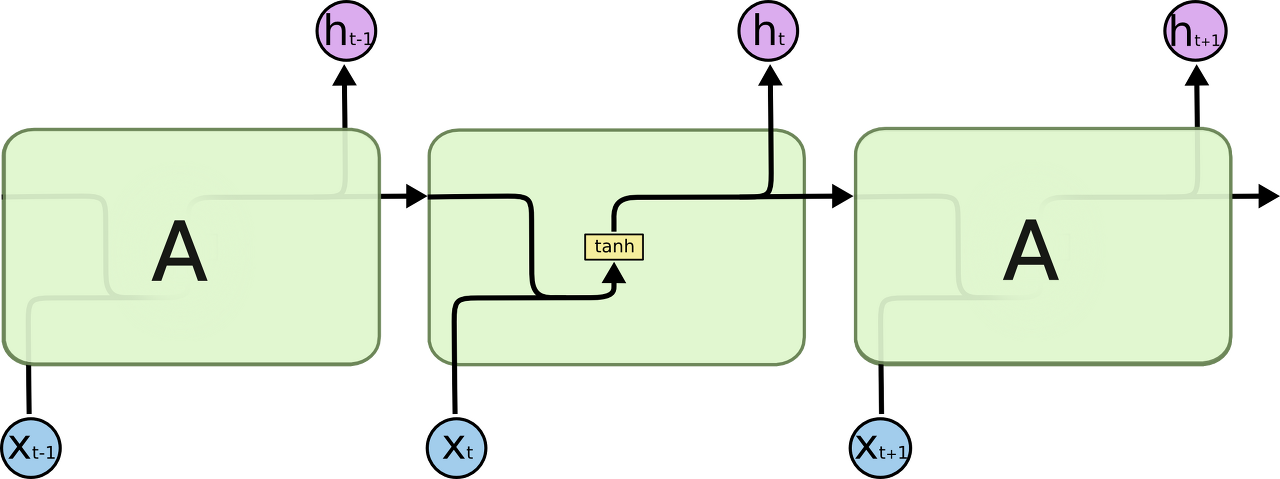
출처: https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
LSTM은, Cell이 가지는 Memory를 제어할수있는 3가지의 Gate를 통해 RNN의 장기의존성 이슈를 효과적으로 개선한 모델이다. 아래는 전체 LSTM의 동작 시퀀스 모델이다.
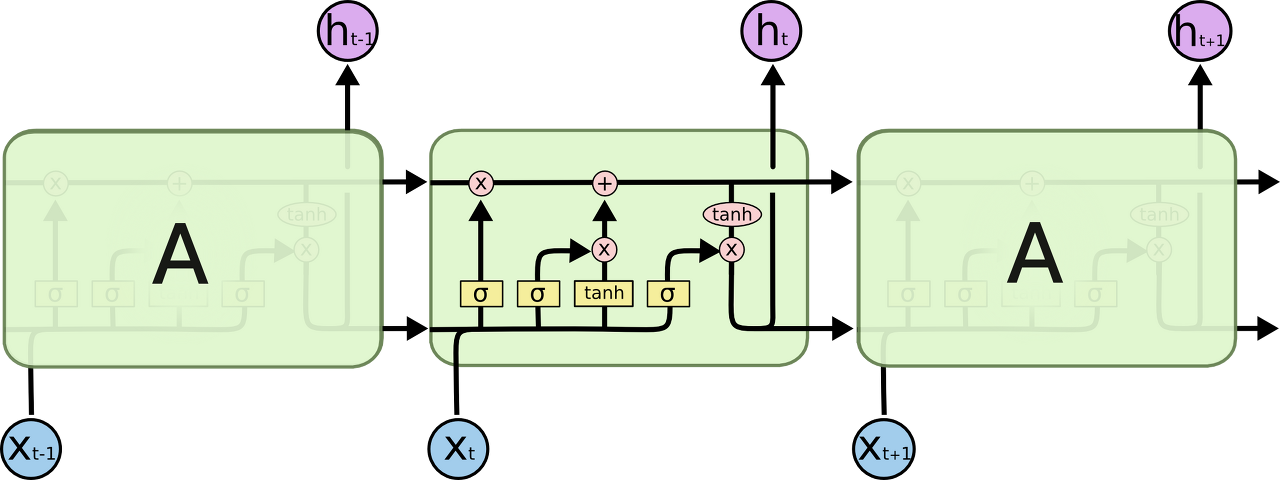
출처: https://dgkim5360.tistory.com/entry/understanding-long-short-term-memory-lstm-kr
특징
-
Cell: Memory Cell, 기억장치 역할. Input Gate와 Forget Gate에 의해 Cell State가 업데이트 된다.
-
Forget Gate: 망각 장치. Sigmoid 함수 (출력이 0 또는 1)의 특징을 이용해서, 이전 Layer의 입력을 현재 시점의 Cell State에 적용 여부를 결정한다.
-
Input Gate: 입력 장치. 현재 레이어의 입력값을 결정하며 Sigmoid와 Tahn(출력이 -1 to 1)으로 이루어져있다. 즉 현 시점의 Cell State에 입력값(Candidate)의 중요도를 반영하는 게이트이다.
-
Output Gate: 업데이트된 Cell State를 필터링해줌 (Tanh + Sigmoid)
Lagging Issue
LSTM의 특성으로, 예측값이 실제값을 추종하는 현상이 일어나서 학습이 되지 않는 이슈가 존재 할 수 있다. LSTM의 특성이라고 하는데 해당 방법을 해결하기위해서 Multivariate를 사용해야한다고 했던것 같다.
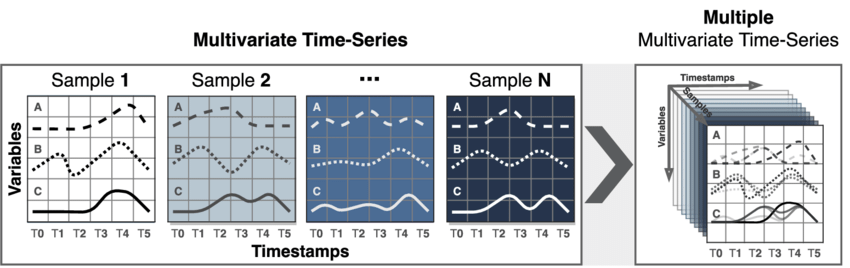
Variate (변량)
Univariate Analysis
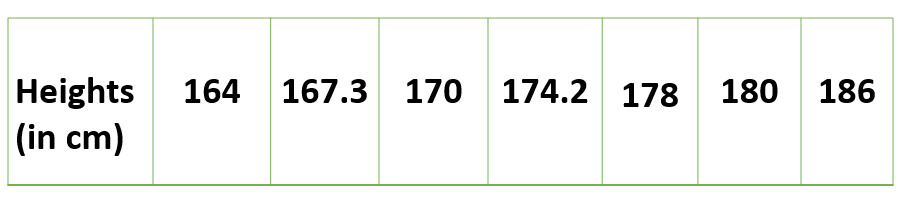
하나의 변수로 이루어져있는 데이터이며, 단일 변수의 변화량만을 분석하는 가장 간단한 형태의 분석기법을 가진다.
아래 사람들의 Discrete Variable에 대한 관측치이며, 변수간의 관계를 정의할 필요가 없다. Univariate Analysis는 평균, 최소/최대, 범위 값등을 히스토그램 및 막대차트등으로 표현.
Bivarate Analysis
두개의 서로 다른 변수들의 관계를 분석하는 분석법이다.
각 변수는 서로 독립적이거나 의존적이며, X (독립변수)에 해당하는 Y(종속변수)가 항상 존재한다.
아래는 Temperature의 변화에 따라, 아이스크림의 판매량을 나타낸것이며 직관적으로 온도가 높아질수록 판매량이 증가하는 형태의 관계를 가진다.

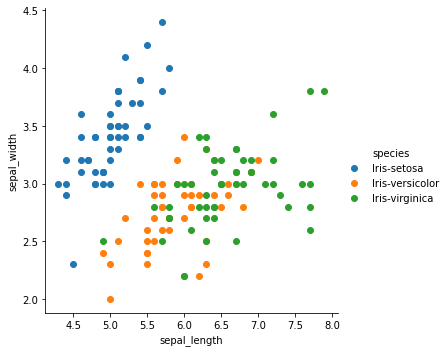
출처: https://www.kaggle.com/code/amrut11/iris-dataset-univariate-bivariate-multivariate/notebook
Multivariate Analysis
다중 시간 종속변수이며, 예측할 변수의 과거 데이터 및 데이터간의 의존성을 고려해야한다. (물론 Bivariate도 ^ㅁ^)
다변량 분석법으로, 2개이상의 변수간의 관계를 분석한다. 현업에서 자주 사용된다.
Diff
차분의 정의는, 연속된 관측값들의 차이를 계산하는것
Diff(차분)은 시계열 데이터의 추세(Trend)를 제거하여, Non-Stationarity를 가지는 시계열 데이터를 Stationarity로 변환한다.
아래는 간단히 diff의 동작을 보여준다.
- np.linspace를 통해, 0-100구간의 값을 리스트로 반환 (선형적)
- np.diff를 통해, 차분결과를 보여줌.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x = np.linspace(0,100,10)
print (x)
x = np.diff(x)
print (x)그 결과로, 0-10 인덱스들의 값이 차분된것을 확인할 수 있다.
[ 0. 11.11111111 22.22222222 33.33333333 44.44444444
55.55555556 66.66666667 77.77777778 88.88888889 100. ]
[11.11111111 11.11111111 11.11111111 11.11111111 11.11111111 11.11111111
11.11111111 11.11111111 11.11111111]아래는 Trend를 가진 시계열 데이터를 차분했을때, 정상성을 가지게되는 예시이다.
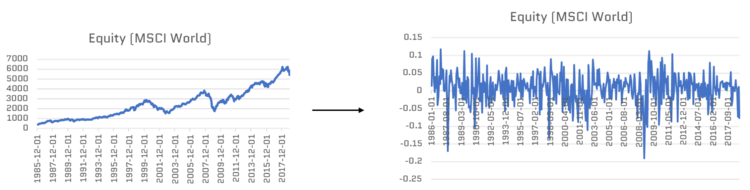
하지만, Diff를 하더라도 완벽하게 정상성(Stationarity)로 변환해주지 않을 경우 Seq2Seq 아키텍쳐를 사용하게된다.
참고: 시계열 데이터는 서로간의 선/후 관계 및 Spread가 존재한다. 또한 데이터의 Noise가 존재할수 있기에 차분은 필수적으로 사용됨
Seq2Seq Architecture
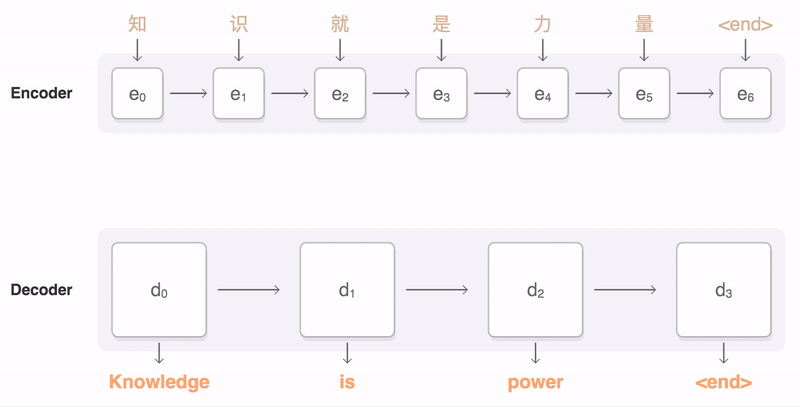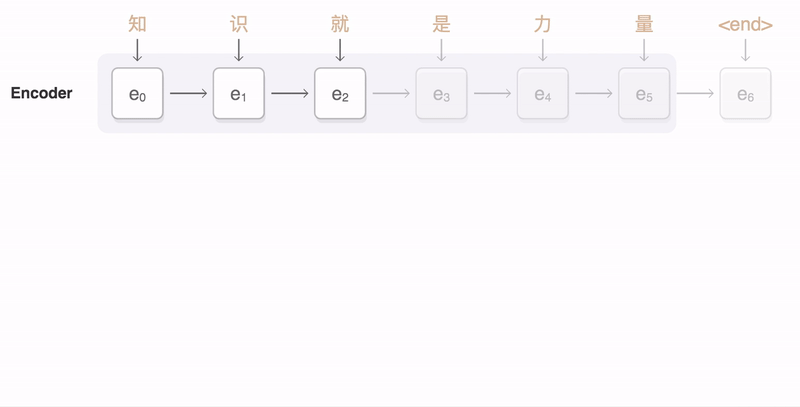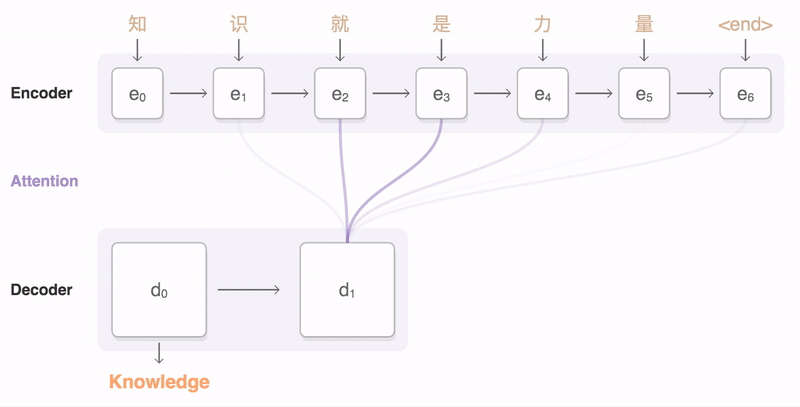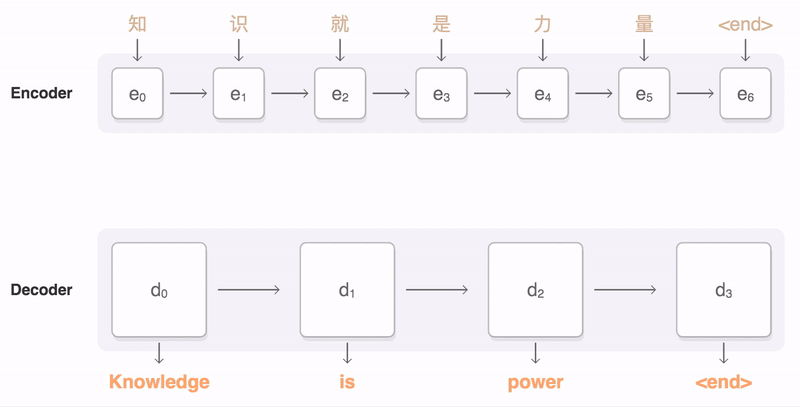
출처: https://google.github.io/seq2seq/
seq2seq 아키텍처는 번역기 등 NLP 처리를 위해 만들어진 구조이다. Encoder - Context - Decoder의 구조로 되어있으며,
Encoder를 통해, Sequence 입력 값을 벡터구조로 바꿔 Context를 Decoder로 전달한다.
- Encoder와 Decoder는 여러개의 RNN 층으로 구성되어 있다.
- Context는 Encoder의 마지막 은닉상태(엔코더 RNN의 최종 출력)를 넘겨주는 Context Vector를 Decoder의 입력 RNN으로 전달한다.
- Embeding Layer는 텍스트 데이터를 벡터로 변환한다
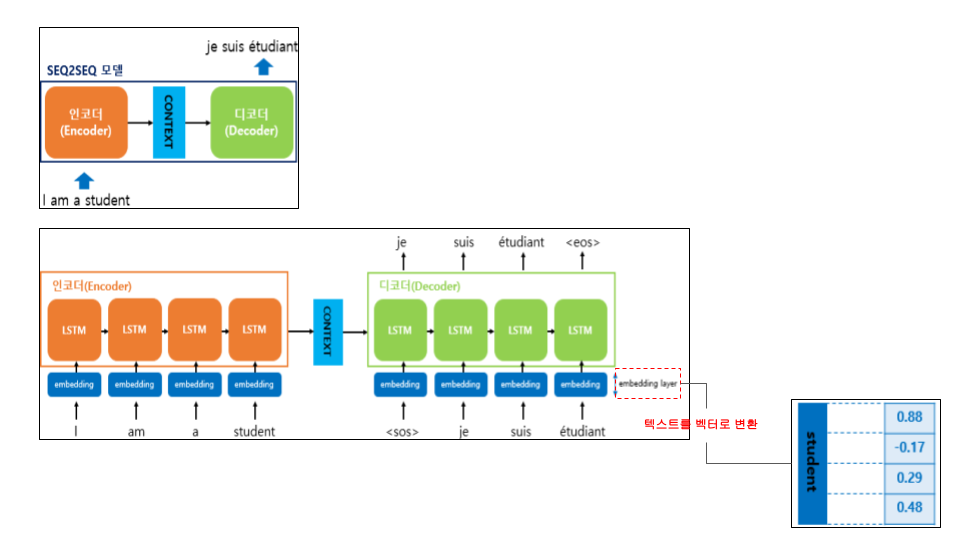
출처: https://wikidocs.net/24996
Q. 의문점이 있다. Diff(차분)을 통해 시계열 데이터를 정상화해주고 LSTM으로 전달하는것이 일반적인 프로세스라고 알고있는데, seq2seq 데이터는 내부 모듈에 LSTM이 여러개 존재한다. 그러면 차분과정을 거치지 않는다는 것 인데. 차분했을때 정상화 되지않는 시계열 데이터를 정상화 하기위해 seq2seq 아키텍처를 사용한다는 것 과 모순이다... 왜 그런걸까?
