Convolutional Neural Network for Image Recognition
이미지 인식에서 사용되는 여러가지 데이터 셋과 알고리즘을 소개한다.
What is Dataset?
예측 및 분석의 용도로 사용되어지는 컴퓨터가 이해가능한 데이터 집합을 의미한다. 대표적인 데이터셋은,
ImageNet, Mnist, Cifar-10이 있다.
MNIST
손으로 작성된 10 (0-9)개의 숫자이다.
- 60,000개 훈련 이미지
- 10,000개의 테스트 이미지
- 50 MB의 작은 용량으로, 간단하게 학습한 모델의 성능을 평가하기에 좋다.

CIFAR-10
일반적인 사물을 모아놓은 데이터셋이다.
- 10개의 클래스를 가지며, 각 클래스당 60,000장의 이미지(32x32) 가 포함된다.
- 데이터셋의 크기가 작아, MNIST와 같이 이미지 인식 모델을 Benchmarking하는데 사용될수 있다.

ImageNet
ILSVRC 대회에서 사용되는 대용량 이미지 데이터셋이다.
- 14,197,122개의 이미지, 1000개의 클래스

참고: 대회에서 준수한 성능을 내는 알고리즘은 대세 알고리즘이 되기도 한다. (AlexNet, ResNet, VGGNet 및 기타)
참고2: 2012년 AlexNet 등장 이후, 대부분의 알고리즘의 대세가 Deep Architecture로 학습을 시킨다.
Popular Algorithm
이미지 인식 및 여러 논문에서 사용되던 알고리즘을 소개한다.
AlexNet
ILSVR에 2012년에 등장한 AlexNet은 최초로 GPU를 사용하여, 처음으로 성능을 많이 올린 알고리즘이다. 해당 알고리즘의 등장으로, Image Recognition의 성능이 사람을 초월했다.
- 5 Convolutional Layer, 3 Max Pooling, 2 Normalization Layer, 3 Fully Connected Layer
- 각 Conv Layer에는 Non-linearity를 더하기위해 ReLU함수가 사용되었다.
- Stride를 조절하여, Overlapping Maxpooling을 사용했다.
- Conv Layer의 깊이가 학습 성능에 영향이 있는것을 증명
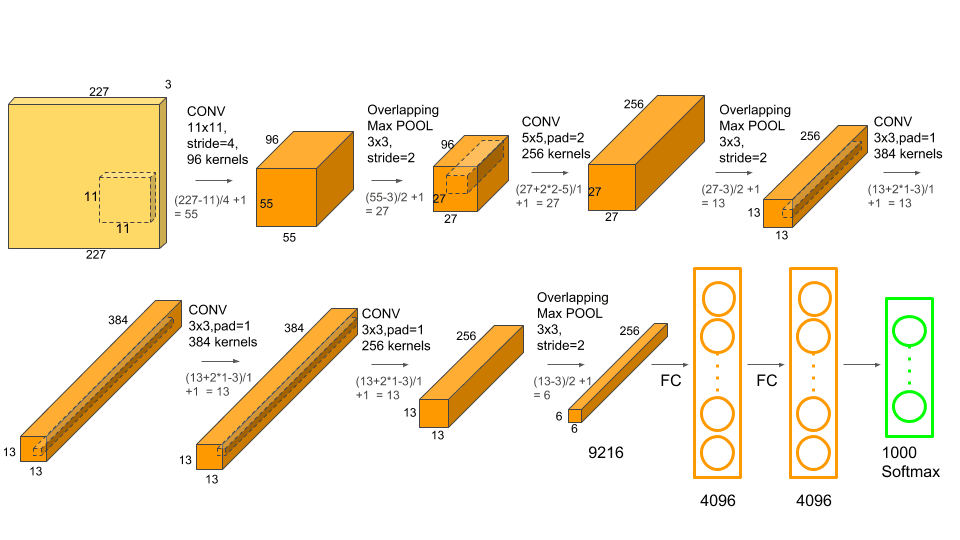
- 첫번째와 두번째 layer에 Maxpooling이 사용되고, 나머지 3개의 Conv layer 3개는 Maxpooling없이 연결된다.
- 첫번째와 두번째 Fully Connected Layer는 4096개의 뉴런으로 연결되며, 마지막은 1000개의 뉴런과 Softmax를 통해 이미지의 클래스를 분류한다.
ReLU vs Tahn
주목할 점은, ReLU 함수이다.
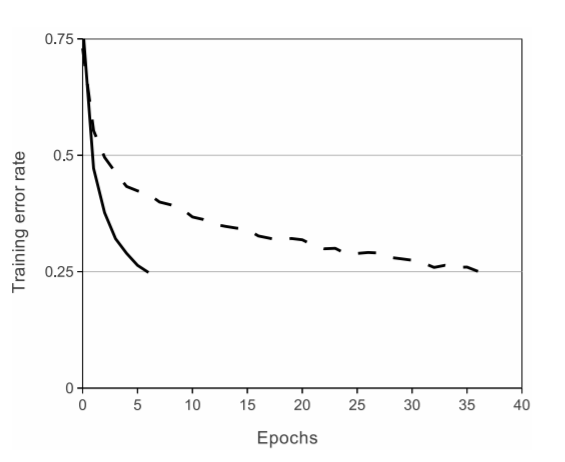
해당 그래프는, CIFAR-10 데이터셋을 학습시킨 비교 결과이다. Epoch를 기준으로 Tahn vs ReLU 함수를 Training Rate를 비교했는데, ReLU 함수가 0.25라는 수치에 도달할때까지 6배 정도 빠른 성능을 보여준다.
Sigmoid나 Tahn 함수는 Gradient Vanishing 에 대한 이슈가 존재했지만, ReLU함수를 통해 미분하는 값을 0 아니면 1로 기준을 두었기에 Gradient Vanishing 이슈를 해소했다.
- 포화 구간이라 함은, 독립변수(x값)의 변화로 종속변수(함수값, y값)의 변화가 없는곳을 말한다. 아래의 그래프는, Sigmoid 함수의 그래프를 보여주는데 x값이 커지거나 작아질수록 값이 y값이 발산하는것을 보여준다. x값이 커진다 함은, 레이어가 깊어진다는 의미(포화구간 진입)로 점차 Gradient 값이 작아지며 학습이 불가능한 상태로 변한다는것이다.

Fully Connected Layer에서는 Drop-Out 테크닉을 통해 오버피팅을 예방했다.
참고: Drop-Out은 학습노드를 랜덤하게 드랍한다.
잡설: ReLU가 사용되기전, Sigmoid를 기반으로한 Tahn 함수가 많이 사용되었다.
Overlapping MaxPooling
Overlapping Maxpooling이란, Stride값을 Pooling Window 사이즈보다 작게하여 값이 겹치게 만드는 것이다.
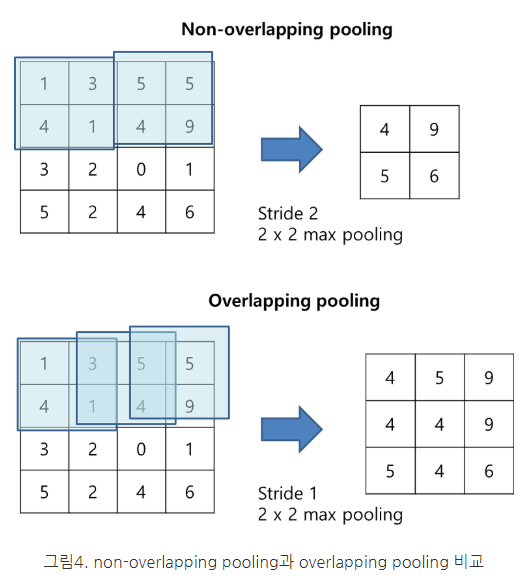
출처 - https://oi.readthedocs.io/en/latest/computer_vision/cnn/alexnet.html
LRN (Local Response Normalization)
LRN은 사람의 시각 정보가 특정 물체의 영역에서 강한 자극이 일어나, 특정영역의 주변 값으로 부터는 자극을 억제하는 lateral inhibitation (측면억제)에서 영향을 받은 기법이다.
한 블로그에서는 LRN이 사용되는 이유가, 다음과 같다고 한다.
ReLU함수를 사용하면, x값이 양수일때 입력값을 그대로 사용하기에 Conv또는 Pooling을 사용할때, 특정 영역의 값이 매우 크게되면 주변 값도 영향을 받기때문에 값들을 정규화 하여 특정값만 강조되는 현상을 제한하기 위함이라고 한다. 하지만 최근에는 LRN이 아닌, Batch Normalization이 사용된다.
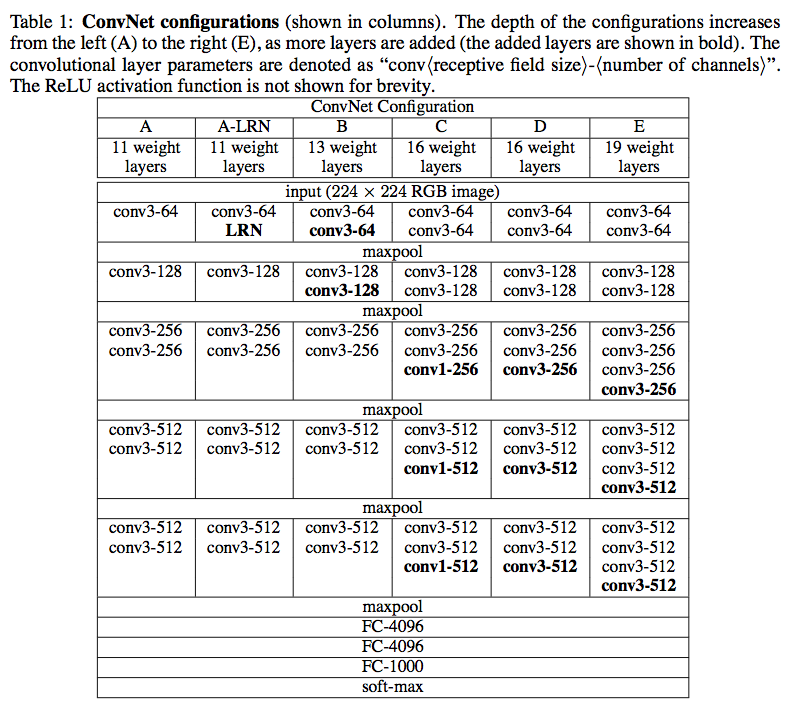
VGGNet (OxfordNet)
기존 AlexNet에 비해, Convolutional Layer의 깊이를 더 깊게 만든 알고리즘이다. 레이어의 깊이에 따라, VGG-16 / 19으로 불린다.
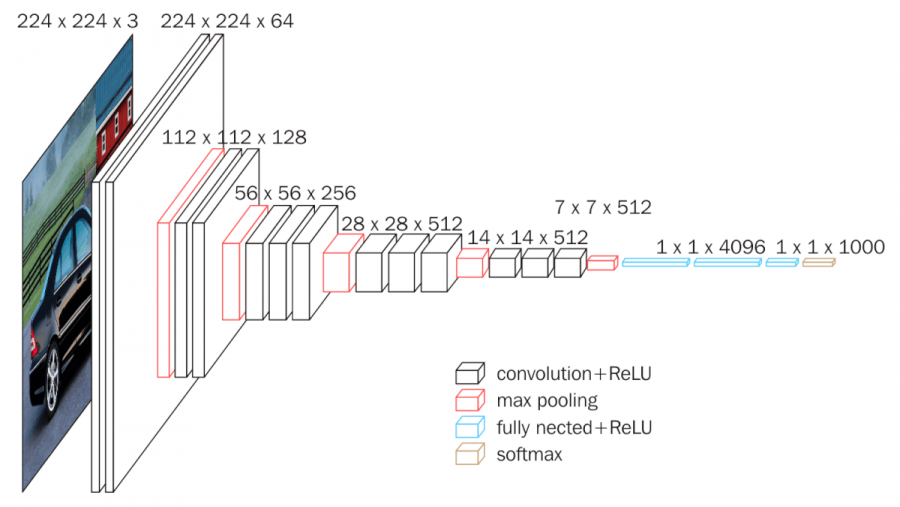
VGGNet의 주요목적으로, 성능↔레이어의 관계를 A - E 까지의 단계로 비교했다.
Maxpooling 하기전까지 레이어의 깊이와 파라미터(Parameters)를 conv < receptive field size >-< number of channels> 로 표현한다. 예를 들어, conv3-64 = 64개의 파라미터와 3개의 Conv Layer를 사용했음을 의미한다.
Less Parameter, More Non Linearity
주목할만한 특징으로는 Convolutional Operation에서 사용한 Kernel의 크기가 3x3 이라는 점이다. 이는 7x7 커널보다는 크기가 작지만, 3x3 커널을 여러개 사용함으로써, Non-linearity를 더 부여하고, 파라미터의 개수도 줄인다. ICLR 에서 투고된, Very Deep Convolutional Network For Large-Scale Image Recognition의 2.3 Discussion을 살펴보면, 아래와 같이 나와있다.
요약하자면, 이전에는 7x7(Stride2), 11x11(Stride4)의 비교적 큰 Receptive Field를 사용했지만 3x3 (Stride1) Receptive Field를 통해, 입력의 모든 픽셀을 Convolution Operation 하였다.
Our ConvNet configurations are quite different from the ones used in the top-performing entries
of the ILSVRC-2012 (Krizhevsky et al., 2012) and ILSVRC-2013 competitions (Zeiler & Fergus,
2013; Sermanet et al., 2014). Rather than using relatively large receptive fields in the first conv. layers (e.g. 11×11 with stride 4 in (Krizhevsky et al., 2012), or 7×7 with stride 2 in (Zeiler & Fergus,
2013; Sermanet et al., 2014)), we use very small 3 × 3 receptive fields throughout the whole net,
which are convolved with the input at every pixel (with stride 1).
3개의 3x3 필터를 사용했을때, 7x7 필터가 가지는 Receptive Field와 동일한 Receptive Field를 가지게되는데, 아래 계산 따라 3x3 파라미터의 개수가 더 작으므로, 같은 이미지의 특징을 학습할때 파라미터가 더 적어 학습 효율측면에서 더 이득이라 볼수 있다.
- 3x3필터의 파라미터 = 3(32C2) = 27C2
- 7x7필터의 파라미터 = 7(72C2) = 49C2
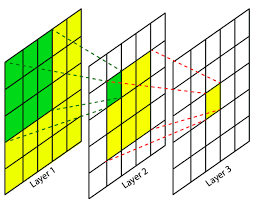
Receptive Field
수용성 필드라는뜻으로, 다음 계층 하나의 계수가 바라보는 원본 이미지들이 픽셀이다. 즉 각 필터가 가지는 값 하나를 뉴런으로 볼때 해당 뉴런이 담당하는 범위를 Receptive Field라고한다. 말이 엄청 어려우니, 아래 그림을 보면
Layer3이의 노란색 타일이 가지는 본래의 값은 Layer2의 3x3, Layer1의 전체 필드이다.
Feature Map Calculation
Feature Map 사이즈를 계산하는법을 잠깐 정리해야겠다.
K = Convolution Layer의 깊이 (채널)
W = 입력 이미지의 사이즈
P = Padding
S = Stride
연습으로, 첫번째 Feature Map의 사이즈를 확인해보자
K = 64
W = 224
P = 1
S = 1
해당 공식은, 입력 이미지의 Width Height가 동일한 정방행렬일 경우를 고려한 계산법이다. 만약 Width Height가 서로 다르다면, 각각 적용해주면 된다.
ResNet
ResNet은 VGG-19의 성능을 개선한 알고리즘이다.
[VGG-19]((#vggnet-oxfordnet)은, 학습 성능과 네트워크의 깊이가 서로 관련이 있는걸 증명하는 과정이었다면, ResNet은 망이 깊어질수록 성능이 과연 더 좋아질까? 라는 증명이 되었다.
아래는, 논문에서 설명하는 데이터로, 56 vs 20 layer의 모델 학습능력을 비교한 그래프이다.

Deep Residual Learning for Image Recognition
그래프의 결과로, 레이어가 깊다고, 모델의 성능을 향상 시킨다고 보장할수 없다.
Gradient Vanishing & Exploding
머신러닝의 궁극적인 목적은, 입력 데이터와 타겟 데이터의 오차를 최소값을 최소로 만드는것이다. 오차값을 줄이기 위해서는 편미분 또는 미분을 사용하여 임의의 그래프의 기울기값을 0에 가깝거나 0에 만드는 것이다.
하지만 망이 깊어짐에 따라, 미분값이 극히 작아지거나 커지면서 0 또는 무한대의 값을 가지게 되면서 Gradient Vanishing 및 Exploding 현상 때문에, 학습이 진행되지 않거나, 학습능력이 떨어지게 되는 현상 및 오버피팅 이슈가 발생한다. (위의 그래프 참조) 이를, Degradiation이라고 말한다.
ResNet 구조
이를, ResNet에서는 Shortcut 및 Skip을 사용하여, 출력값에 입력값을 더해주는 방식으로 Gradient Vanishing / Exploding 이슈를 해결했다.

Skipping / Short Cut
기본 VGG-19와 차이점은 아래와 같다.
- VGG-19: F(X) = x >> F(x)값을 x 값에 가깝도록 만듬
- ResNet: H(X) = x + F(x) >> 0에 가깝게 만듬
ResNet의 경우, 최적화가 훨씬 쉽기때문에 VGG-19에 비해 더 많은 레이어를 쌓을수 있었고, 이 결과 모델의 학습 능력이 VGG-19에 비해 더 좋아졌다고 말할수 있다.
[Structure of ResNet)(#structure-of-resnet)
아래는 Skipping과 ShortCut을 사용한 ResNet의 구조이다.
VGG-19과 다르게 입력값이 출력값으로 Forwarding되는것을 확인할수 있다.

