RateLimitFilter는 악의적으로(DDoS 공격) 혹은 실수로(무한 루프 코드 등) API를 초당 수천 번씩 호출하는 공격을 막어하는 목적으로 사용하는 보안 코드이다.
코드를 보고 상세 설명을 작성하겠다.
public class RateLimitFilter extends OncePerRequestFilter {
// 경로별 IP → Bucket 매핑 (ConcurrentHashMap으로 스레드 안전 보장)
private final ConcurrentHashMap<String, Bucket> loginBuckets = new ConcurrentHashMap<>();
private final ConcurrentHashMap<String, Bucket> registerBuckets = new ConcurrentHashMap<>();
private final ConcurrentHashMap<String, Bucket> refreshBuckets = new ConcurrentHashMap<>();
private final ObjectMapper objectMapper = new ObjectMapper();
// 요청 경로와 IP를 확인해 해당 버킷에서 토큰을 소비한다
// 토큰 소비 실패 시 429 응답을 반환하고 필터 체인을 중단한다
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain) throws ServletException, IOException {
String path = request.getRequestURI();
String ip = extractIp(request);
Bucket bucket = resolveBucket(path, ip);
if (bucket == null) {
// 제한 대상 경로가 아니면 그냥 통과
filterChain.doFilter(request, response);
return;
}
if (bucket.tryConsume(1)) {
filterChain.doFilter(request, response);
} else {
response.setStatus(HttpStatus.TOO_MANY_REQUESTS.value());
response.setContentType(MediaType.APPLICATION_JSON_VALUE);
response.setCharacterEncoding("UTF-8");
objectMapper.writeValue(response.getWriter(),
Map.of("code", "RATE_LIMIT_EXCEEDED",
"message", "요청이 너무 많습니다. 잠시 후 다시 시도해주세요."));
}
}
// 경로에 따라 알맞은 버킷 맵에서 IP별 버킷을 반환한다
// 처음 요청하는 IP라면 새 버킷을 생성해 저장한다
private Bucket resolveBucket(String path, String ip) {
if (path.equals("/api/auth/login")) {
// 로그인: IP당 10회/분
return loginBuckets.computeIfAbsent(ip, k ->
Bucket.builder()
.addLimit(Bandwidth.builder()
.capacity(10)
.refillGreedy(10, Duration.ofMinutes(1))
.build())
.build());
}
if (path.equals("/api/auth/register")) {
// 회원가입: IP당 5회/분
return registerBuckets.computeIfAbsent(ip, k ->
Bucket.builder()
.addLimit(Bandwidth.builder()
.capacity(5)
.refillGreedy(5, Duration.ofMinutes(1))
.build())
.build());
}
if (path.equals("/api/auth/refresh")) {
// 토큰 재발급: IP당 30회/분
return refreshBuckets.computeIfAbsent(ip, k ->
Bucket.builder()
.addLimit(Bandwidth.builder()
.capacity(30)
.refillGreedy(30, Duration.ofMinutes(1))
.build())
.build());
}
return null;
}
// 클라이언트 IP 추출: 프록시 환경에서는 X-Forwarded-For 헤더를 우선 사용한다
private String extractIp(HttpServletRequest request) {
String forwarded = request.getHeader("X-Forwarded-For");
if (forwarded != null && !forwarded.isBlank()) {
// X-Forwarded-For는 "실제IP, 프록시IP, ..." 형태이므로 첫 번째 값이 원본 IP
return forwarded.split(",")[0].trim();
}
// 프록시 없으면 그냥 직접 연결 IP
return request.getRemoteAddr();
}
}
RateLimitFilter에선 'HashMap' 대신 'ConcurrentHashMap'를 사용한다.
이유 1.
속도면에서 'ConcurrentHashMap'가 더 좋다.
'HashMap' 이든 'ConcurrentHashMap' 이든 put(key, value) 하는 순간 Java가 내부적으로 자동으로 계산해서 슬롯을 배정한다.
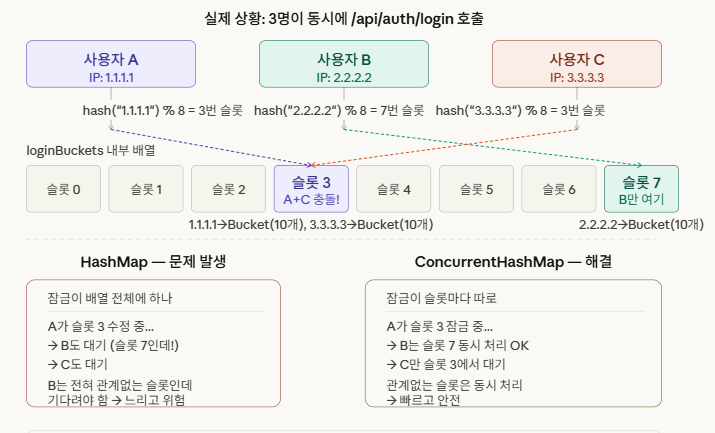
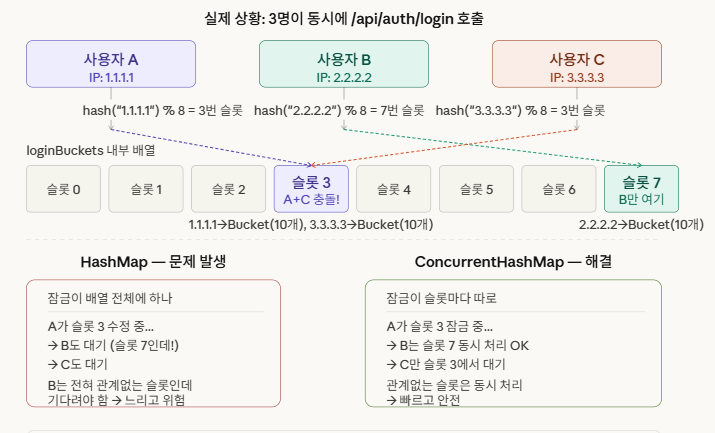
만약 A,B,C IP에서 동시 호출을 했을때 같은 슬롯에 여러 IP가 같은 슬롯에 배정될 수가 있다.
이걸 '해시 충돌'이라고 한다.
만약 해시 충돌이 일어나서 A,C는 3슬롯에 배정받고 B는 5슬롯에 배정 받았을때,
'HashMap'을 사용했다면 A IP를 처리하는 동안 다른 슬롯에 있는 B와 같은 슬롯에 있는 C는 대기 해야한다.
하지만 'ConcurrentHashMap' 를 사용했다면 A IP를 처리하는 동안 같은 슬롯의 C 만 대기하고 다른 슬롯의 B는 동시에 처리하게된다.
그렇기 때문에 속도면에서 'ConcurrentHashMap'가 더 좋다.
이유 2.
'ConcurrentHashMap'는 안전하다.
'ConcurrentHashMap'와 'HashMap' 둘 다 해시 충돌은 일어날 수 있다.
하지만 같은 슬롯에 배정된 후 Buckets.computeIfAbsent(ip, k -> 코드를 탈때
'HashMap'는 A,C IP에서 동시에 버킷을 생성하기 때문에 데이터가 꼬일 수 있다.
'ConcurrentHashMap'는 슬롯 단위를 원자적으로 실행한다. A와 C가 Buckets.computeIfAbsent(ip, k ->를 동시에 탈때
A를 먼저 처리 한 후 C를 처리하기 때문에 'ConcurrentHashMap'가 더 안전하다.
EX)
1단계 — 해시 충돌
A IP(1.1.1.1) → 해시 계산 → 3번 슬롯
C IP(2.2.2.2) → 해시 계산 → 3번 슬롯 (우연히 같은 슬롯)
2단계 — computeIfAbsent 동시 접근
(같은 슬롯이지만 키가 다르기 때문에 각자 자신의 버킷을 따로 생성해야 한다)
A: 3번 슬롯에 "1.1.1.1 없네" → 버킷 생성하려는 순간
C: 3번 슬롯에 "2.2.2.2 없네" → 버킷 생성하려는 순간
HashMap
→ 둘 다 동시에 생성 → 데이터 꼬임
ConcurrentHashMap
→ A 먼저 잠금 → 생성 → 해제
→ C 대기 → 순서대로 처리doFilterInternal에서 'extractIp' 함수를 호출한다.
'extractIp' 에선 헤더에서 'X-Forwarded-For'의 값을 가지고 와서 빈값이면 request.getRemoteAddr()로
빈값이 아니면 'X-Forwarded-For'의 값을 잘라서 IP로 사용한다.
그 이유는 AWS 같은 서버를 사용할때 request.getRemoteAddr()로 IP를 추출하면
실제 사용자의 IP가 아니라 프록시IP를 추출하게 된다.
그렇기 때문에 'X-Forwarded-For'가 빈 값이 아니라면 실제IP와 프록시IP 중 실제 IP 값을 추출해서 사용하고
빈 값이라면 request.getRemoteAddr()로 실제 IP를 추출해서 사용한다.그 다음 'resolveBucket'함수를 호출한다.
'resolveBucket' 함수에선 특정 API를 호출 했을때 버킷등록, 버킷의 토큰을 채우는 역할을 한다.
버킷과 토큰의 관계는 자판기와 음료수를 생각하면 쉽다.
Bandwidth는 자판기 용량 규칙이다.
자판기(버킷) 안에 음료수(토큰)가 있다.
요청 1번 = 음료수 1개 소비
음료수 다 떨어지면 → 429 차단
1분(Bandwidth 내용에 따라 다름) 지나면 → 음료수 다시 채워짐
이걸 생각하면서 코드를 보겠다.
~Buckets.computeIfAbsent(ip, k ->
위에서 만든 Buckets가 null 값인지 판단하고 null 이면 IP를 키값으로 한 ConcurrentHashMap를 새로 생성한다.
'.computeIfAbsent'가 '없으면 만들어서 넣어라'라는 기능을 한다.
Bucket.builder() :
버킷을 만듦(자판기 설치)
.addLimit(Bandwidth.builder() :
뒷 내용으로 Bandwidth 만듦(자판기 용량 설정)
.capacity(30) :
토큰 용량 최대 30으로 설정(자판기 음료수 최대 용량 30개)
.refillGreedy(30, Duration.ofMinutes(1)) :
1분이 지나면 토큰을 가득(30개) 채운다. (1분이 지나면 자판기에 음료를 가득 채운다.)
.build()) :
Bandwidth를 만듦
여기서 헷갈렸던건 'resolveBucket' 함수는 호출할때마다 타는건데
'시간이 지났을때 채워지는건 1분이 지날때마다 일까 호출할때 일까?' 였다.
찾아보니 시간만 지나면 토큰은 논리적으로 계속 충전되고 있다가
호출이 되면 그동안 쌓인 토큰이 채워지는 것이었다.'resolveBucket'함수에서 리턴받은 버킷의 토큰 수를 판단해 요청을 처리할지 팅겨낼지를 판단한다.
if (bucket == null) { 에서 버킷이 null이면 버킷이 필요한 경로의 호출이 아니기 때문에 요청을 처리한다.
if (bucket.tryConsume(1)) { :
'.tryConsume(1)'는 버킷의 토큰을 한개 사용한 후
토큰이 1개 이상 남아있으면 소비하고 true, 토큰이 0개면 소비하지 않고 false를 리턴한다.
true 일때는 정상적으로 호출을 처리하고
false 일땐 미리 정해놓은 429 응답을 리턴한다.

신생아 개발자