💡 자료구조
자료 구조(데이터 구조)는 컴퓨터 메모리를 더 효율적으로 관리하기 위해 새로 정의하는 구조체로 일종의 메모리 레이아웃 또는 지도로 생각하면 된다.
자료 구조 중에는 연결 리스트, 해시 테이블, 스택, 큐, 딕셔너리 등이 존재한다.
💡 연결 리스트
연결 리스트는 저장되어있는 값들이 여러군데에 나누어져 존재하지만
바로 다음 값의 메모리 주소를 기억하고 있어 배열과 비슷하게 값을 연이어 읽을 수 있는 자료 구조이다.
-
배열: 각 값이 메모리 상에서 연이어 저장되어 있다.(인덱스가 연속적이다.)
-
연결 리스트: 각 값이 메모리 상에서 따로 따로 저장되어 있다.
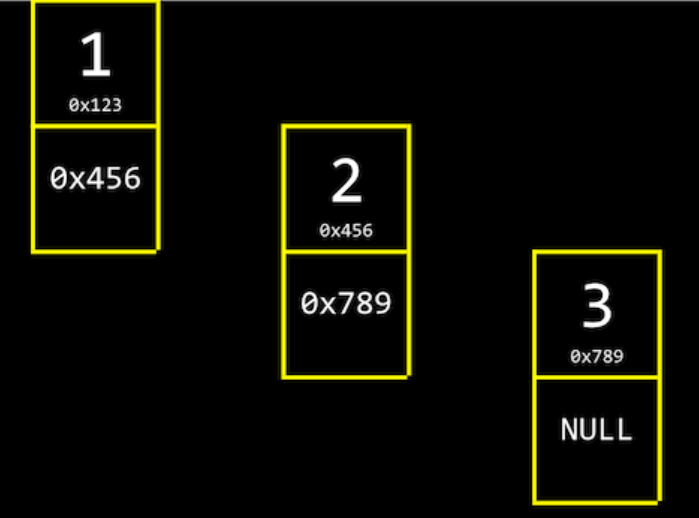
가장 첫번째 값인 1은 2의 메모리 주소를 저장 2는 3의 메모리 주소를 저장하는걸 확인할 수 있다. -
장점
- 연결 리스트는 다음 값이 저장된 메모리 주소만 알면 되기에 같은 자료형을 연결할 필요가 없다. 즉 여러 자료형 값을 이용할 수 있다.
- 배열은 고정된 개수만 저장할 수 있지만, 연결 리스트는 데이터를 유동적으로 추가할 수 있다.
-
단점
- 인덱스 사용이 불가능하기에 위치를 나타낼 때 순차적으로 접근해야한다.
- 배열과 비교하여 각 값에 접근하는데 오랜 시간이 걸린다.
- 데이터 저장 시 다음 값의 메모리 주소를 함께 저장하기에 메모리르 더 소비한다.
💡 트리
그래프의 일종으로 정점과 간선을 이용하여 데이터의 배치 형태를 추상화한 자료구조이다.
연결 리스트를 활용한 데이터 구조인 트리는 각 요소가 여러개의 요소를 가리킨다.
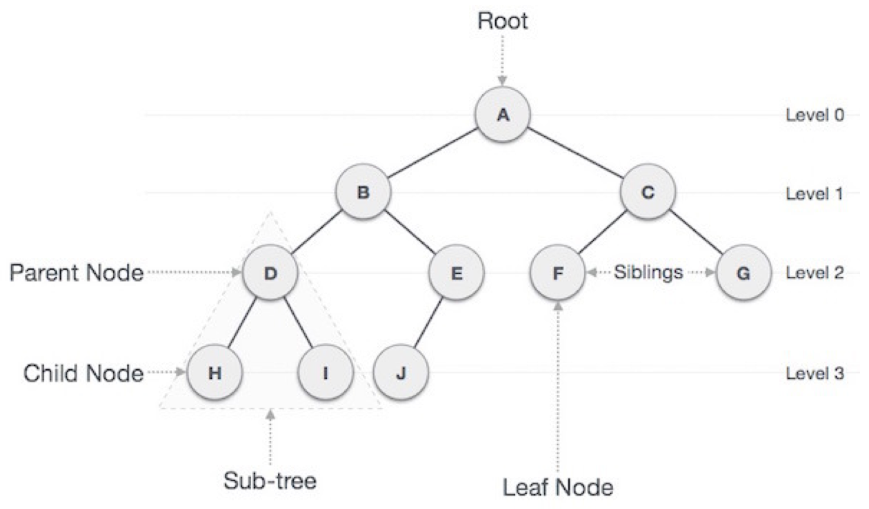
-
트리 자료구조는 일반적으로 대상 정보의 각 항목들을 계층적으로 구조화할 때 사용하는 비선형 자료구조이다.
-
트리의 구조는 '데이터의 저장'의 의미보다는 '저장된 데이터를 더 효과적으로 탐색' 하기 위해서 사용된다.
-
리스트와 다르게 부모 자식의 계층적인 관계로 표현된다.
-
트리는 사이클이 없다.
-
최상위 계층의 노드를 루트노드라고 부른다.
-
트리에서 루트노드를 제외한 모든 노드는 단 하나의 부모노드를 가진다.
이진 검색 트리
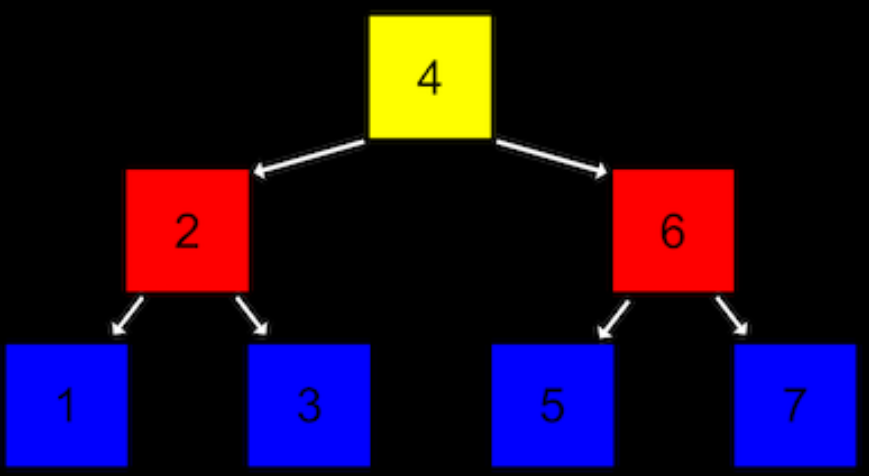
-
트리 자료구조는 여러 가지 유형이 있는데, 그중 가장 기본이 되는 트리는 이진 트리(Binary Tree) 구조이다.
-
이진 트리는 2개 이하의 자식노드를 가진다. 자식노드가 없거나 1개의 자식노드만 가지는 것도 가능하다.
-
2개의 자식 노드 중 왼쪽의 노드를 Left Node, 오른쪽의 노드를 Right Node라고 한다.
💡 해시 테이블
키(key)에 데이터(value)를 저장하는 데이터 구조이다.
인스타그램의 해쉬태그 원리도 바로 이 해쉬테이블에서 파생된것이다.
-
성능이 뛰어나기 때문에 해쉬라는 키를 확장한 여러가지 함수, 알고리즘 기반으로 최근 블록체인 기술에서 많이 사용된다.
-
키를 해쉬 함수에 넣으면 데이터가 저장되어야 할 위치를 알 수 있다.
-
보통 배열로 Hash Table 사이즈 만큼 생성 후에 사용한다.
-
key를 통해 바로 데이터를 가져올 수 있기 때문에 속도가 획기적으로 빨라진다.
해시 테이블이 빠른 검색속도롤 제공하는 이유는 다음과 같다.
- 내부적으로 배열(버킷)을 사용하여 데이터를 저장하기 때문
- 버킷(bucket)이란?
- 해시 테이블은 각각의 key값에 해시함수를 적용해 배열의 고유한 index를 생성하고, 이 index를 활용해 값을 검색하게 된다. 여기서 실제 값이 저장되는 장소를 버킷 또는 슬롯이라고 한다.
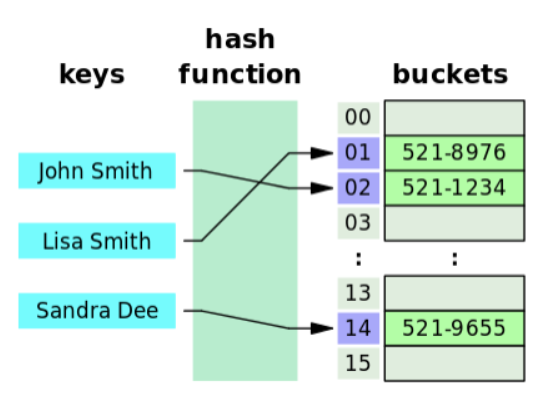
(Key, Value)가 ("John Smith", "521-1234")인 데이터를 크기가 16인 해시 테이블에 저장하는 과정
-
(1) index = hash_function("John Smith") % 16 연산을 통해 index 값을 계산한다.
-
(2) array[index] = "521-1234" 로 전화번호를 저장하게 된다.
이러한 구조로 데이터를 저장하면 Key값으로 데이터를 찾을 때 해시 함수를 1번만 수행하면 되므로 매우 빠르게 데이터를 저장/삭제/조회할 수 있다. 해시테이블의 평균 시간복잡도는 O(1)이다.
Reference
