1. 스타벅스 매장 위치 데이터 가져오기
(1) 스타벅스 매장 위치 태그를 보면 beatifulsoup으로 바로 접근 불가하여 selenium으로 접근하기
from selenium import webdriver
import time
# 크롬드라이버로 스타벅스 접속
url = "https://www.starbucks.co.kr/store/store_map.do"
driver = webdriver.Chrome('../driver/chromedriver.exe')
driver.get(url)
# 지역 검색 클릭
xpath_one ='//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/header[2]'
some_tag_one = driver.find_element_by_xpath(xpath_one)
some_tag_one.click()
time.sleep(2)
# 서울 클릭
xpath_seoul ='//*[@id="container"]/div/form/fieldset/div/section/article[1]/article/article[2]/div[1]/div[2]/ul/li[1]/a'
some_tag_seoul = driver.find_element_by_xpath(xpath_seoul)
some_tag_seoul.click()
time.sleep(2)
# 서울_ 전체 클릭
xpath_seoul_all ='//*[@id="mCSB_2_container"]/ul/li[1]/a'
some_tag_seoul_all = driver.find_element_by_xpath(xpath_seoul_all)
some_tag_seoul_all.click()(2) selenium 접근 후 Beatifulsoup으로 태그 가져오기
# 서울 전지역 나타낸 후 Beatifulsoup으로 태그 가져오기
from urllib.request import urlopen, Request
from bs4 import BeautifulSoup
star_req = driver.page_source
star_soup = BeautifulSoup(star_req, "html.parser")
driver.quit()
print(star_soup.prettify())(3) DataFrame 으로 스타벅스 매장 데이터 정리
import pandas as pd
# 매장 정보 뽑아내기
test_soup = star_soup.find_all("li", {"class":"quickResultLstCon"})
seoul_star_name = []
seoul_star_lat = []
seoul_star_lng = []
for num in range(len(test_soup)):
seoul_star_name.append(test_soup[num]["data-name"].strip())
seoul_star_lat.append(test_soup[num]["data-lat"].strip())
seoul_star_lng.append(test_soup[num]["data-long"].strip())
# DataFrame 만들기
star_data = {
"매장" : seoul_star_name,
"lat" : seoul_star_lat,
"lng" : seoul_star_lng
}
star_df = pd.DataFrame(star_data)
# DataFrame에 구 데이터 넣기
import re
seoul_gu = []
for i in range(len(test_soup)):
seoul_gu.append(re.split(" ",test_soup[i].get_text())[5])
seoul_gu_one = []
for name in seoul_gu:
if name not in seoul_gu_one:
seoul_gu_one.append(name)
star_df["구"] = seoul_gu
# "구" 에 잘못들어간 데이터 수정
star_df[(star_df["구"] == '서울특별시') == True]
star_df["구"][407] = "영등포구"
star_df["구"][378] = "영등포구"
star_df["구"][364] = "양천구"
# DataFrame에 "갯수", "브랜드", "주소" 컬럼 추가
a = []
for num in range(len(star_df)):
a.append(test_soup[num].find("p").get_text()[0:len(test_soup[num].find("p").get_text())-9])
star_df["갯수"] = 1
star_df["브랜드"] = "스타벅스"
star_df["주소"] = a
star_df = star_df[star_df["구"] != "고양시" ](4) 최종 스타벅스 DataFrame
star_df = star_df[["매장","주소","구","lat","lng","갯수","브랜드"]]
star_df
2. 이디야 매장 위치 데이터 가져오기
(1) 이디야 매장 위치 태그를 보면 beatifulsoup으로 바로 접근 불가하여 selenium으로 접근하기
# 크롬드라이버로 이디야 접속
url = "https://www.ediya.com/contents/find_store.html#c"
driver = webdriver.Chrome('../driver/chromedriver.exe')
driver.get(url)
time.sleep(1)
# 주소 클릭
xpath_address = '//*[@id="contentWrap"]/div[3]/div/div[1]/ul/li[2]/a'
some_tag_address = driver.find_element_by_xpath(xpath_address)
some_tag_address.click()
# 구이름으로만 검색시 결과가 많아 에러가 발생하여 구 앞에 서울을 붙여서검색
for i in range(len(seoul_gu_one)):
seoul_gu_one[i] = "서울 " + seoul_gu_one[i]
seoul_gu_one
# 잘못 들어가있는 데이터 제거(고양시, 서울특별시)
del seoul_gu_one[0]
seoul_gu_one
for i in range(len(seoul_gu_one)):
if seoul_gu_one[i] =="서울 서울특별시":
del seoul_gu_one[i](2) seoul_gu_one를 이용하여 BeautifulSoup으로 태그 가져오기
# 이디야 주소에 모든 "구" 를 검색하여 각각의 데이터를 리스트로 저장
edi_name = []
edi_add = []
for num in seoul_gu_one:
some_tag = driver.find_element_by_xpath('//*[@id="keyword"]')
some_tag.send_keys(num)
time.sleep(1)
driver.find_element_by_xpath('//*[@id="keyword_div"]/form/button').click()
time.sleep(2)
edi_req = driver.page_source
edi_soup = BeautifulSoup(edi_req, "html.parser")
for i in range(len(edi_soup.find_all("li", {"class":"item"}))):
edi_name.append(edi_soup.find_all("li", {"class":"item"})[i].find("dt").text)
edi_add.append(edi_soup.find_all("li", {"class":"item"})[i].get_text())
some_tag.clear()
time.sleep(1)(3) DataFrame 으로 이디야 매장 데이터 정리
edi_data = {
"매장" : edi_name,
"주소" : edi_add,
}
edi_df = pd.DataFrame(edi_data)
edi_df(4) 이디야 주소로 lat, lng 구하기
import googlemaps
gmaps_key = "본인키"
gmaps = googlemaps.Client(key=gmaps_key)
# 받아온 주소로 실행하면 오류가 발생하여 오류가 나지 않도록 변경
for i in range(len(edi_add)):
if len(edi_add[i].split()) > 4:
edi_add[i] = edi_add[i].split()[1] + edi_add[i].split()[2] + edi_add[i].split()[3] + edi_add[i].split()[4]
else:
edi_add[i] = edi_add[i].split()[1] + edi_add[i].split()[2] + edi_add[i].split()[3] + edi_add[i].split()[0][0:len(edi_add[i].split()[0])-1]
# lat, lng 데이터 리스트로 저장 후 DataFrame에 추가
edi_lat = []
edi_lng = []
for row in range(len(edi_add)):
target_name = edi_add[row]
edi_lat.append(gmaps.geocode(target_name)[0].get("geometry")["location"]["lat"])
edi_lng.append(gmaps.geocode(target_name)[0].get("geometry")["location"]["lng"])
edi_df["lat"] = edi_lat
edi_df["lng"] = edi_lng
# DataFrame에 "갯수", "브랜드" "구" 컬럼 추가
edi_gu = []
for i in range(len(edi_add)):
if edi_add[i][2:4] =="서대" or edi_add[i][2:4] =="동대"or edi_add[i][2:4] =="영등":
edi_gu.append(edi_add[i][2:6])
elif edi_add[i][2:4] =="중구":
edi_gu.append("중구")
else:
edi_gu.append(edi_add[i][2:5])
edi_df["구"] = edi_gu
edi_df["갯수"] = 1
edi_df["브랜드"] = "이디야"(5) 최종 이디야 DataFrame
edi_df = edi_df[["매장", "주소","구","lat","lng","갯수","브랜드"]]
3. 데이터 시각화
# 한글 적용
import matplotlib.pyplot as plt
import platform
from matplotlib import font_manager, rc
get_ipython().run_line_magic("matplotlib", "inline")
path = "c:/Windows/Fonts/Malgun.ttf"
if platform.system() == "Darwin":
rc("font", family = "Arial Unicode MS")
elif platform.system() == "Windows":
font_name = font_manager.FontProperties(fname=path).get_name()
rc("font", family=font_name)
else:
print("Unkown")1. 스타벅스와 이디야 매장 위치
# 원의 크기를 50m로 나타내기위해서 Circle 사용
# 초록 : 스타벅스, 파랑 : 이디야
import folium
m = folium.Map(location=[37.5502, 126.982], zoom_start=12, tiles="Stamen Terrain" )
for idx, rows in star_df.iterrows():
folium.Circle(
location= [rows["lat"], rows["lng"] ],
radius= 50,
opacity = 0.7,
popup= rows.매장,
color = "green"
).add_to(m)
for idx, rows in edi_df.iterrows():
folium.Circle(
location= [rows["lat"], rows["lng"] ],
radius= 50,
opacity = 1,
popup= rows.매장,
color = "blue",
).add_to(m)
m
2.구별 매장 갯수
# 스타벅스와 이디야 DataFrame 합친 후 Pivot table로 만들기
star_edi_df_one = pd.concat([star_df,edi_df], axis= 0)
star_edi_df_one
import numpy as np
star_edi_df_one_pivot = star_edi_df_one.pivot_table(index= "구", columns="브랜드", values = "갯수", aggfunc=np.sum)
star_edi_df_one_pivot
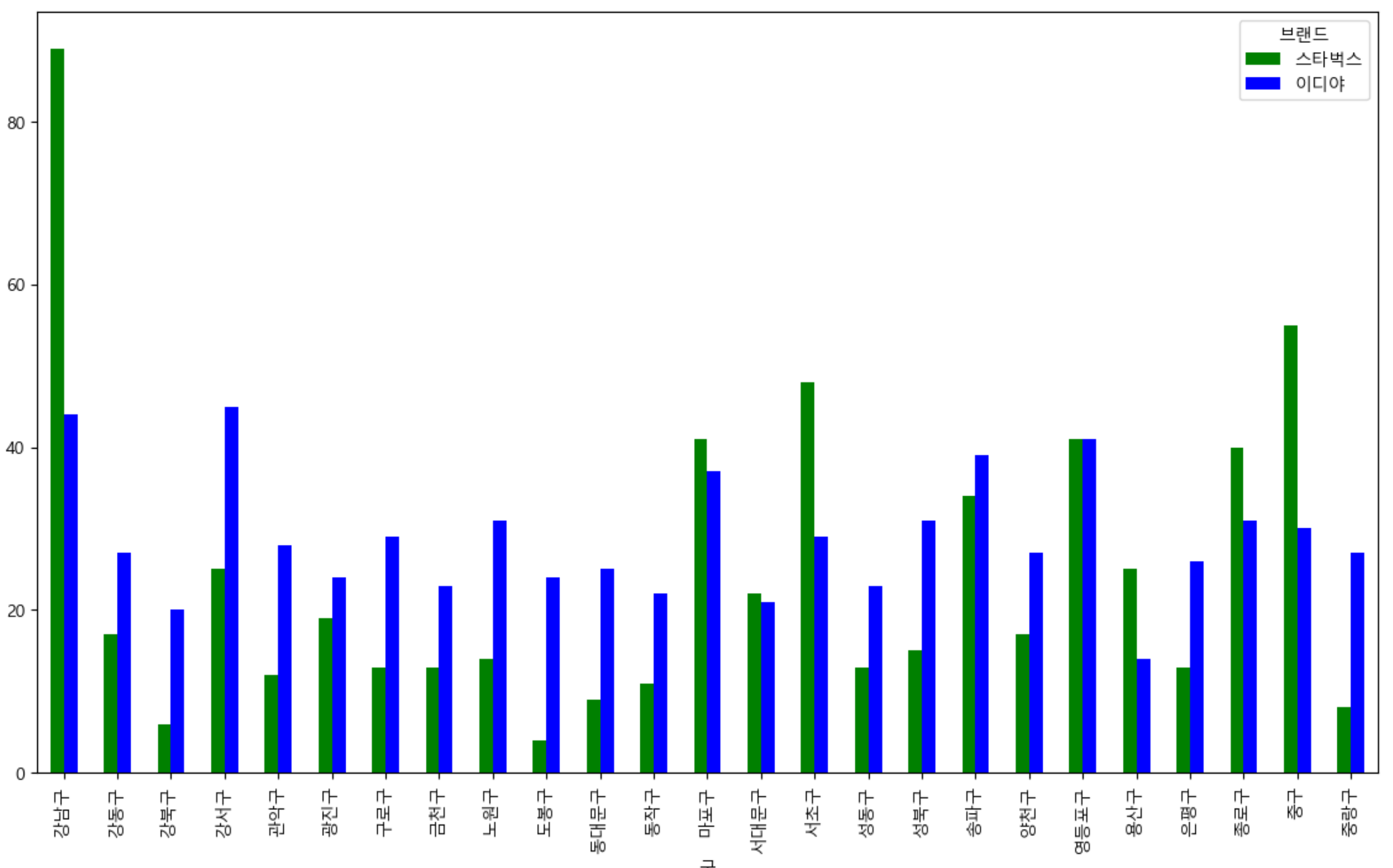
# 스타벅스와 이디야 구별 갯수 bar로 나타내기
star_edi_df_one_pivot.plot.bar(
figsize = (14,8),
color = ["green","blue"]
)
4. 이디야가 스타벅스 매장 근처에 있는지 분석해보기
1. 위 두 자료를 토대로 '스타벅스'와 '이디야' 비교
- '이디야'는 모든 구에 분산적으로 분포되어 있는것을 확인할 수 있다.
- '스타벅스'는 강남구, 중구, 서초구 등 특정 구에 집중적으로 분포되어있는것을 확인할 수 있다.
- 강북구, 도봉구, 중랑구 등 이디야의 입점 매장에 비해 스타벅스의 입점 매장이 현저히 낮다.
결론
- '이디야'가 '스타벅스' 인근 위치에 전략적으로 입점한다는 가설이 진실이라고 보여지지않는다.
5. 느낀점
- 처음 해본 EDA 분석이여서 분석단계에서 필요한 데이터를 얻기위해 전단계로 피드백하는 경우가 빈번하게 일어났다
- 다음 분석에는 분석을 하기위한 필요한 데이터를 꼼꼼히 확인한 후 프로젝트를 시작하여야겠다

스터디 노트