시작
이번 포스팅에서는 본격적으로 엘라스틱서치 용청과 응답 , 인덱스와 도큐먼트 정의 , 키바나 콘솔 사용법등을 다뤄볼 예정이다.
요청과 응답
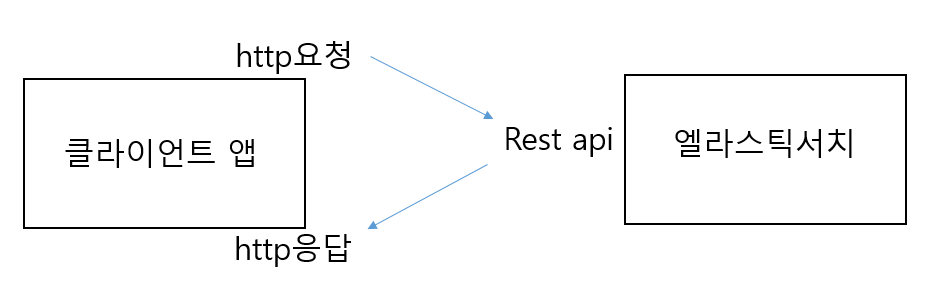
REST API
엘라스틱서치는 모든 요쳥과 응답을 REST API형태로 제공한다. REST는 웹의 장점을 이용해 리소스를 주고받는 형태이며 , REST API는 REST 기반으로 API를 서비스를 하는것을 의미한다. 기본적으로 REST API는 메소드(method)+경로(url) 형태인데 메소드는 총 4가지로 표현 가능하다. REST API는 네가지 메소드 타입을 가지고 리소스의 CRUD(생성/읽기/수정/삭제) 작업을 진행한다. 간단하게 말하자면 경로(url)로 리소스를 정의하고 메소드와 함께 서버에 요청하고 응답을 받는 구조이다.
mothod
- post : 해당 리소스를 추가한다.
- put : 해당 리소스를 수정한다.
- GET : 해당 리소스를 조회한다
- DELETE " 해당리소스를 삭제한다
키바나 콘솔 사용
먼저 웹사이트 홈에서 좌측 management -> Dev Tools에 들어가면 console창이 나온다. 여기에 엘라스틱서치에서 제공하는 REST API를 타이핑하고 실행 버튼을 누르면 HTTP요청문을 보낸다. 오른쪽 출력은 응답 결과를 확인 가능하다.
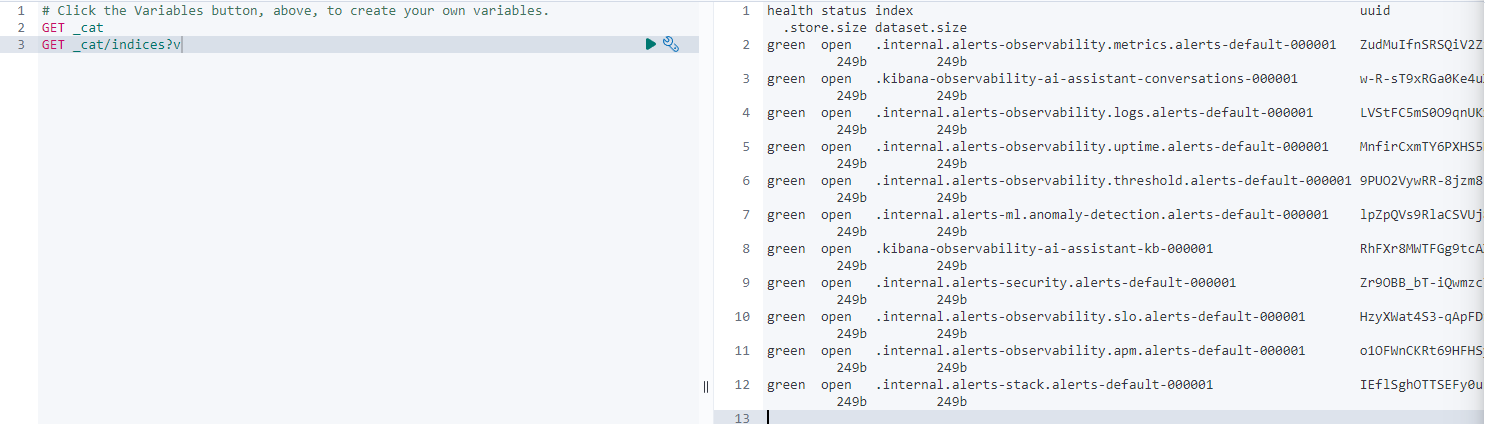
응답 결과가 잘못되엇을시 다양한 메시지와 4xx,404등 status코드를 알려주기 때문에 쉽게 오류 수정도 가능하다.

인덱스와 도큐먼트
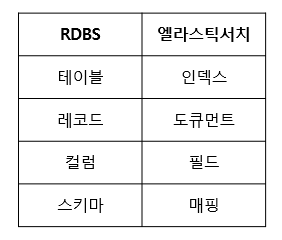
우선 위와 같은 키바나 콘솔을 사용하기 위해 요청문을 작성하는 방법을 알아야한다. 그전에 문서기반 nosql인 elasticsearch에 인덱스와 도큐먼트 개념에 대해 먼저 이해해야 한다. 인덱스는 도큐먼트를 저장하는 논리적 구분자 관계형 데이터베이스에 테이블과 비슷하다. 도큐먼트는 실제 데이터를 저장하는 단위로 관계형 데이터베이스로 따지면 레코드이다. 기본적으로 클러스터 > 인덱스(테이블) > json형태로 된 다수 도큐먼트(레코드=행) > 도큐먼트는 복수의 필드(값)으로 이루어진 구조를 가진다.
도큐먼트 CURD(생성,읽기,수정,삭제)
일반적으로 도큐먼트를 인덱스에 포함시키는것을 '인덱싱' 이라고 한다. 간단하게 인덱스를 생성하고 도큐먼트를 생성하는 방법은 아래와 같다.
생성
PUT index1 --> index1이름 인덱스생성
PUT index2/_doc/1 -->index2를 생성/엔드포인트 구분 예약어/도큐먼트 고유 아이디
{
"name": "John Doe",
"age": 30,
"city": "Seoul"
}인덱스 생성은 PUT으로 가능하다. 뒤에 엔드포인트 구분 예약어/도큐먼트 고유 아이디를 통해 각 인덱스를 구분시킨다.
확인 / 수정
GET index1 --> index1확인
GET index2/_doc/1 --> index2/_doc/1 수정
{
"name": "Park",
"age": 45
"city": jeonju
}
DELETE index2/_doc/1 --> ndex2/_doc/1 삭제확인 및 수정은 GET으로 가능하고 삭제는 DELETE로 가능하다. 참고로 도큐먼트 값 형식을 잘못입력시 자동으로 변환해주는 기능이 있다. 예를들면 숫자인데 '10'과 같이 string형식으로 입력시 자동으로 10같은 숫자로 바꿔준다.
bulk
POST _bulk
{"index":{"_index":"test", "_id":"1"}}
{"field":"value one"}
{"index":{"_index":"test", "_id":"2"}}
{"field":"value two"}
{"delete":{"_index":"test", "_id":"2"}}
{"create":{"_index":"test", "_id":"3"}}
{"field":"value three"}
{"update":{"_index":"test", "_id":"1"}}
{"doc":{"field":"value two"}}CURD 동작을 할때는 하나하나 도큐먼트를 요청하는것보다 bulk를 사용하면 한번에 빠르게 요청이 가능하다. bulk는 정해진 포멧이 있으며 json 문법과 유사하지만 조금 다르다.
post _bulk
{"index": {"_index": "index2", "_id": "6"}}
{"name":"hong", "age": 10, "gender": "female"}
{"index": {"_index": "index2", "_id": "7"}}
{"name":"choi", "age": 90, "gender": "male"}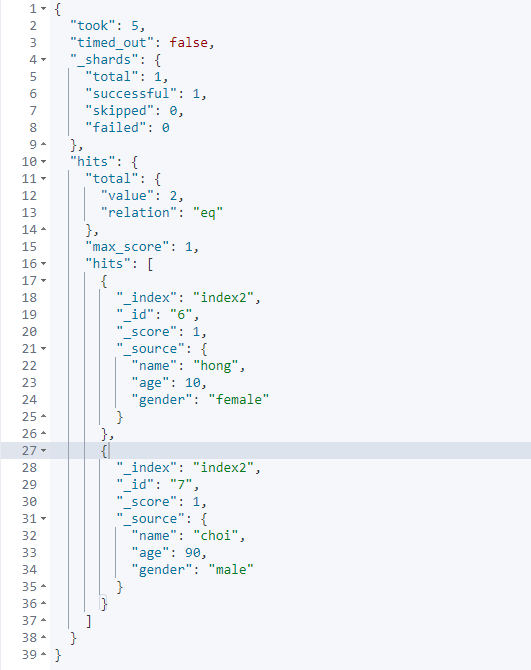
위와같이 두개의 다큐먼트를 가지는 벌크를 한번에 생성 가능하다. 형식은 꼭 맞춰줘야한다
매핑
get index2/_mapping -> index2의 매핑 상태를 확인한다Elasticsearch 매핑은 Elasticsearch 인덱스에 저장된 데이터의 구조를 정의하는 역할을 한다. 다양한 데이터 유형을 지정하고 각 필드에 적용될 분석기를 설정하는등 과정을 매핑 이라고 한다.
동적 매핑
위에서도 말했듯이 매핑을 설정하지 않아 elasticsearch에서는 자동으로 도큐먼트를 자료형으로 바꿔준다. 매핑 설정하지 않아도 자동으로 인덱싱되도록 해주는것을 다이내믹 매핑(자동으로 지정) 근데 이 방식은 메모리가 비 효율적일수도 있다.
명시적 매핑
{
"mappings":{
"properties":{
"city" : {"type":"short"},
"age":{"type":"short"},
"name":{"type":"short"},
"gender":{"type":"short"}
}
}
}
인덱스 매핑을 직접 정의하는 것을 명시적 매핑이라고 한다. 매핑을 직접 정의하기 위해서는 데이터 타입에 대한 이해가 필요하다. elasticsearch에 사용하는 타입들은 다음 사이트에 나와있다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-types.html
멀티 필드
PUT multifield_index
{
"mappings": {
"properties": {
"message":{"type": "text"},
"contents":{
"type":"text",
"fields":{
"keyword":{"type":"keyword"}
//멀티 인덱스 만들기 contents는 text이면서 keyword타입
}
}
}
}
}멀티 필드는 단일 필드 입력에 대해 어려 하위 필드를 정의하는 기능으로 예를들면 전문 검색이 필요하면서 집계또는 정렬도 필요한 경우같은 상황에 적합하다. 위처럼 contents라는 필드를 text 타입과 keyword 타입으로 동시에 사용 가능하다
//데이터 넣기 //
PUT multifield_index/_doc/1
{
"message":"1 documnet",
"contents":"beatufiul day"
}
PUT multifield_index/_doc/2
{
"message":"1 documnet",
"contents":"beatufiul day"
}
PUT multifield_index/_doc/3
{
"message":"1 documnet",
"contents":"wonderful day"
}
GET multifield_index/_search //키워드(day) 기준으로 집계
{
"query": {
"term": {
"contents.keyword": "day"
}
}
}
GET multifield_index/_search //키워드(day) 기준으로 집계
{
"size":0,
"aggs": {
"contents": {
"terms": {
"field": "contents.keyword"
}
}
}
}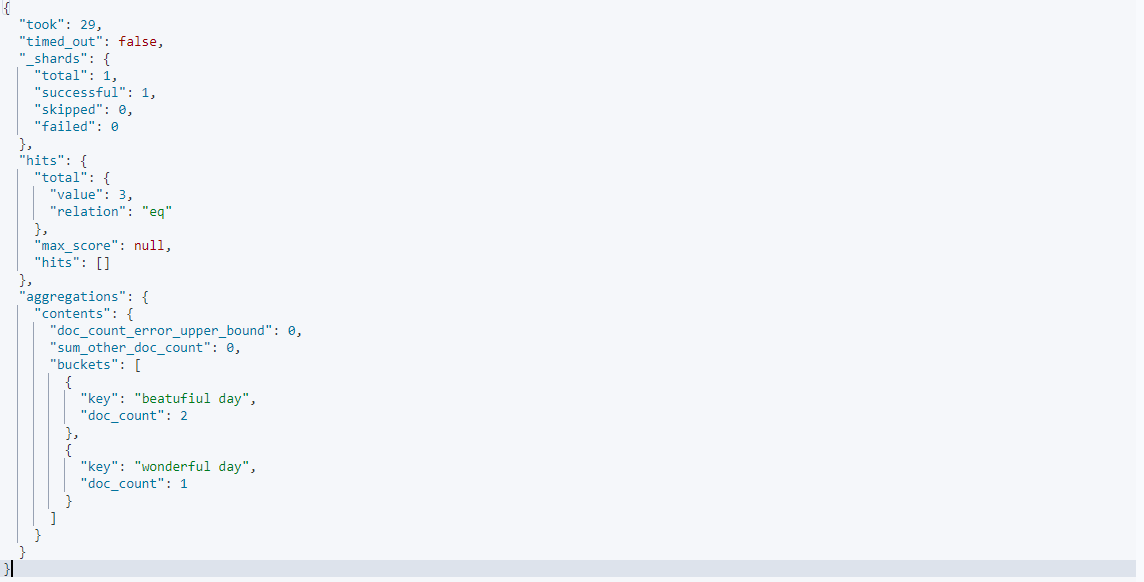
aggs는 집계를 해주는 쿼리이다. 위처럼 멀티인덱스로 생성된 multifield_index에 데이터를 넣고 contents.keyword기준으로 정렬하게 되면 위와같이 나온다.
템플릿
직접 지정 템플릿
PUT _index_template/test_template //인덱스 템플릿 생성
{
"index_patterns": ["test_*"],
"priority": 1,
"template": {
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": {"type": "text"},
"age": {"type": "short"},
"gender": {"type": "keyword"}
}
}
}
}템플릿은 일반적으로 생각하는 개념과 비슷하다. 인덱스를 새로 만들떄 그에 맞는 타입을 자동으로 지정할 수 있도록 미리 템플릿을 만들어 놓는거다. index_template이름의 템플릿을 만드는데 test를 포함한 이름으로 만들시 매핑값을 설정한다. 여러개의 템플릿을 만들시 priority를 추가해 템플릿의 우선순위를 줄 수도있다.
PUT test_index1/_doc/1
{
"name":"kim",
"age":10,
"gender":"male"
}
GET test_index1/_mapping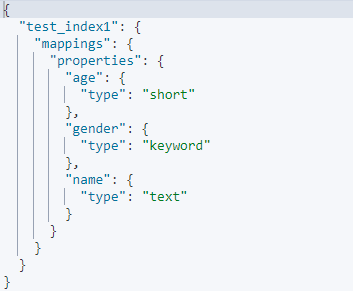
인덱스를 만들고 값을 넣으면 위와같이 템플릿에 맞게 데이터 구조가 매핑이 된다.
동적 템플릿
PUT dynamic_index1
{
"mappings":{
"dynamic_templates":[
{
"my_string_fields":{
"match_mapping_type":"string",
"mapping":{"type":"keyword"}
}
}
]
}
}매핑은 검색에서 매우 중요하기 때문에 신중하게 해야한다. 하지만 로그 시스템이나 비정형화된 데이터를 인덱싱하는경우 그 구조를 쉽게 알기가 어려우므로 필드 타입을 정확히 지정하기 어렵다. 따라서 대략적인 구조만 알 고 있을때 동적 템플릿을 활용하면 좋다.
위 처럼 match_mapping_type은 조건문이자 매핑 트리거로 조건을 만족할시 트리거링이 되고 즉 , string이 들어오면 type을 keyword로 매핑해라라는 뜻이다
PUT dynamic_index2
{
"mappings":{
"dynamic_templates":[
{
"my_long_fields":{
"match":"long_*",
"unmatch":"*_text",
"mapping":{"type":"long"}
}
}
]
}
}
PUT dynamic_index2/_doc/1
{
"long_num" : "5",
"long_text" : "170"
}
GET dynamic_index2또 다른 예시로 위처럼 동적 템플릿을 만들고 인덱싱을 진행하면 "long_num" 은 "match"에 부합하니까 나오고 "long_text" 는 "unmatch"에도 부합하니 제외된다
분석기

엘라스틱서치는 캐릭터 필터 , 토크나이저 , 토큰 필터로 구성되어 있는 분석기 모듈을 가지고 있다. 각 특징은 다음과 같다.
- 캐릭터 필터 : 입력받은 문자열을 변경하거나 불필요한 문자 제거
- 토크나이저 : 문자열을 토큰으로 분리
- 토큰 필터 : 분리된 토큰들의 필터 작업 (대소문자 구분 , 형태소 분석등)
POST _analyze
{
"tokenizer":"standard",
"filter":["uppercase"],
"text":"The 10 most loving dog breeds"
}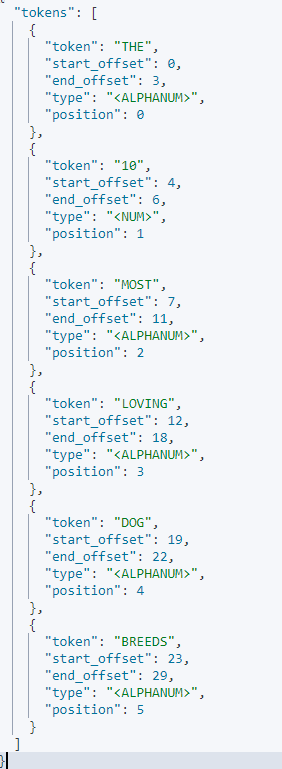
예를들면 위와같이 tokenizer선택과 filter를 선택하면 분석기 모듈이 분석을 진행해준다. 자주사용하는 토크나이저는 lowercase , stemmer(어간분석 예-loving,loved ->love) , stop(불용어 제거)이 있고 'PUT customer_analyzer'로 원하는 분석기를 만들수도 있다.
마무리
엘라스틱서치의 요청과 응답 방식 , 도큐먼트 CURD , 매핑 , 템플릿등 다양한 내용을 포스팅 해보았다. 이 내용은 현재 공부중인 책 3장에 해당하는 내용이 대부분이며 기초인만큼 확실하게 이해하고 넘어가려고 노력했다. 다행히 이전에 fastapi로 웹 backend를 구축하고 frontend작업을 해보면서 웹 통신을 경험해본적이 있기 때문에 이해가 더 빨리 되었다. 다음 포스팅에는 이제 본격적으로 엘라스틱서치 검색에 대해 깊게 다뤄볼 예정이다.
