
📌타입이란?
타입은 어떤 값의 유형 및 종류를 의미하며, 타입에 따라 값이 차지하는 메모리 공간의 크기와, 값이 저장되는 방식이 결정된다.
- 값이 차지하는 메모리 공간의 크기
- 예를 들어, 정수형 타입의 데이터는 4byte, 문자형 타입의 데이터는 1byte이다.
- 값이 저장되는 방식
- 타입은 저장하고자 하는 값을 그대로 저장하는 기본타입과, 저장하고자 하는 값을 임의의 메모리 공간에 저장한 후, 그 메모리 공간의 주소를 저장하는 참조타입으로 분류된다.
📌기본 타입과 참조 타입
- 기본 타입(primitive type)
- 정수 타입(byte, short, int, long), 실수 타입(float, double), 문자 타입(char), 논리 타입(boolean)
- 값을 저장할 때, 데이터의 실제 값이 저장된다.
- 참조 타입(reference type)
- 값을 저장할 때, 데이터가 저장된 곳을 나타내는 주소값이 저장된다.
- 객체의 주소를 저장, 8개의 기본형을 제외한 나머지 타입
예를 들어 책에서 '변수'라는 단어를 찾고 있다고 가정해보자.
이때, 책 어딘가에서 "변수는 ~이다"라고 직접적으로 의미를 알려준다면 기본 타입의 데이터라고 할 수 있다. 반면, 색인처럼 "변수는 102페이지에 설명되어 있다"라고 한다면 이는 참조 타입의 데이터라고 할 수 있다.
📌리터럴이란?
사전적으로 리터럴(Literal)은 '문자 그대로의'라는 뜻을 가진다. 프로그래밍에서 리터럴이란 문자가 가리키는 값 그 자체를 의미한다.
int num = 1;
여기서 num에 할당하고 있는 1이 바로 리터럴이다.
리터럴은 '값'이라고 생각하면 편하다.
📌정수 타입
정수 타입은 숫자를 나타내는 타입으로, byte, short, int, long의 총 4개의 타입으로 분류된다.
예전에는 메모리의 용량이 넉넉하지 않아 필요에 따라 변수의 자료 범위를 변경해야했다. 그래서 적은 메모리를 사용하는 short(2byte), 가장 많은 메모리를 사용하는 long(8byte), 중간 정도의 메모리를 사용하는 int(4byte)로 나누어 사용했다.
근래에는 메모리 용량이 부족한 경우가 거의 없기 때문에 정수형을 사용할 때에는 일반적으로 int 형을 사용한다.
| 타입 | 메모리 | 표현 범위 |
|---|---|---|
| byte | 1byte | -128(-2^7) ~ 127(2^7 - 1) |
| short | 2byte | -32,768(-2^15) ~ 2,137,483,647(2^15 - 1) |
| int | 4byte | -2,147,483,648(-2^31) ~ 2,147,483,647(2^31 - 1) |
| long | 8byte | -9,223,372,036,854,775,808(-2^63) ~ 9,223,372,036,854,775,807(2^63 - 1) |
long타입 리터럴의 경우에는 리터럴 뒤에 접미사 L또는 l을 붙여주어야한다.
일반적으로, 숫자 1과 혼동을 방지하기 위해 대문자 L을 붙인다.
// 각 데이터 타입의 표현 범위에 맞는 값을 할당하고 있습니다.
byte byteNum = 123;
short shortNum = 12345;
int intNum = 123456789;
long longNum = 12345678910L;
// 각 데이터 타입의 표현 범위에 벗어난 값을 할당하고 있어 에러가 발생합니다.
byte byteNum = 130;
short shortNum = 123456;
int intNum = 12345678910;
// 숫자가 길면 언더바로 구분할 수 있습니다.
int intNum = 12_345_678_910;
long longNum = 12_345_678_910L;📄 정수형의 오버플로우와 언더플로우
작성한 코드가 실행 중일 때 어떤 값이 실수로 작성한 코드에 의해 각 타입의 표현 범위를 넘어서는 경우가 발생할 수 있다.
예를 들어, byte형 값 120에 10을 더하면 130이 된다. 하지만 byte형의 표현 범위는 -128 ~ 127이므로, 130은 byte형의 표현 범위를 넘어서는 값이 된다. 이 때 오버플로우가 발생한다.
반대로 byte형 값 -120에서 10을 빼면 값은 -130이 된다. -130은 byte형의 표현범위 중 최소값을 넘어서는 값이므로, 언더플로우가 발생한다.

- 오버플로우
- 자료형이 표한할 수 있는 범위 중 최대값 이상의 값을 표현한 경우 발생한다.
- 최대값을 넘어가면 해당 데이터 타입의 최소값으로 값이 순환한다.
- 예 : 어떤 값이
byte형이고,byte형의 최대값인 127을 값으로 가지는 경우, 이 값에 1을 더하면 128이 되는게 아니라, 최소값인 -128이 된다.
- 언더플로우
- 자료형이 표현할 수 있는 범위 중 최소값 이하의 값을 표현한 경우 발생한다.
- 최소값을 넘어가면 해당 데이터 타입의 최대값으로 값이 순환한다.
- 예 : 어떤 값이
byte형이고,byte형의 최소값인 -128을 값으로 가지는 경우, 이 값에 1을 빼면 -129가 되는게 아니라, 최대값인 127이 된다.
오버플로우가 발생되면 최소값이 나오고, 반대로 언더플로우가 발생하면 최대값이 나온다.
📄 데이터 타입의 크기와 표현 범위
byte -> short -> int -> long으로 갈수록 데이터 타입의 크기도 커지고 표현 범위도 커진다. 즉, 데이터 타입의 크기가 데이터의 표현 범위를 결정한다.
컴퓨터는 0과 1로 데이터를 표현한다. 즉, 0과 1로 이루어진 이진수로 데이터를 표현한다. 이진수 한자리로는 0과 1만 표현할 수 있지만, 이진수를 두 자리, 세 자리로 늘리면 더 많은 데이터를 표현할 수 있다.
- 이진수 한 자리: 0,1 -> 2^1개 -> 2개
- 이진수 두 자리: 00, 01, 10, 11 -> 2^2개 -> 4개
- 이진수 세 자리: 000, 001, 010, 011, 100, 101, 110, 111 -> 2^3개 -> 8개
예를 들어 byte형은 말 그대로 1byte의 크기를 가진 정수형 데이터 타입이다. 1byte는 8bit이므로 따라서 8자리의 이진수를 표현할 수 있다. 즉, 2^8 = 256개의 데이터를 표현할 수 있다.
하지만 음수의 범위도 표현할 수 있어야하기에 8bit 중 맨 앞의 비트를 부호 비트로 사용한다. 즉, 맨 앞의 비트가 0이면 양수, 1이면 음수를 나타내게 된다. 이렇게 하나의 비트를 부호로 표현하고 나면 7개의 비트가 남는다. 결론적으로 2^7 = 128개의 숫자를 표현할 수있다.
그래서 byte형은 -128 ~ 127의 정수 범위를 표현할 수 있다.
📌정수 타입
실수는 소수점을 가지는 값을 의미하며, float형과 double형으로 분류된다.
| 타입 | 메모리 | 표현 범위 | 정밀도 |
|---|---|---|---|
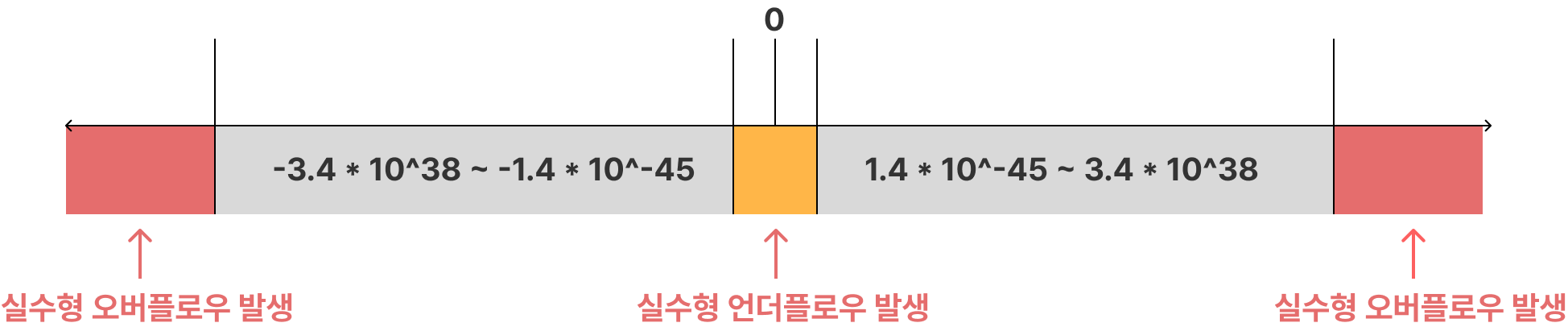
| float | 4byte | 음수 : -3.4 * 10^38 ~ -1.4 * 10^-45 | 7자리 |
| 양수 : 1.4 * 10^-45 ~ 3.4 * 10^38 | |||
| double | 8byte | 음수 : -1.8 * 10^308 ~ -4.9 * 10^-324 | 15자리 |
| 양수 : 4.9 * 10^-324 ~ 1.8 * 10^308 |
double형 리터럴에는 접미사 d를 붙여도, 붙이지 않아도 되지만, float형 리터럴에는 반드시 접미사 f를 붙여주어야 한다.
// float형 리터럴을 float형 변수에 할당
float num1 = 3.14f;
// double형 리터럴을 double형 변수에 할당
double num2 = 3.141592d;
double num2 = 3.141592;컴퓨터에서 실수를 저장할 때는 부동소수점 표현 방식으로 저장하는데, 이러한 방식은 효율적이지만 약간의 오차를 갖는다.
이 오차는 실수를 더 정밀하게 표현할 수록 줄어든다. 여기서 얼마나 실수를 정밀하게 나타낼 수 있는지를 정밀도라고하는데, 정밀도는 데이터 타입의 크기가 클수록 높아진다.
따라서 double형은 float형보다 정밀도가 더 높다.
double형은float형보다 더 큰 실수를 더 정확하게 저장할 수 있다.
📄 실수형의 오버플로우와 언더플로우
실수형에서도 오버플로우와 언더플로우가 발생한다. 다만, 오버플로우와 언더플로우가 발생했을 때의 결과가 다르다.
- 오버플로우
- 값이 음의 최소 범위 또는 양의 최대 범위를 넘어갔을 때 발생하며, 이 때 값은 무한대가 된다.
- 언더플로우
- 값이 음의 최대 범위 또는 양의 최소 범위를 넘어갔을 때 발생하며, 이 때 값은 0이 된다.
📌논리 타입
논리 타입의 종류는 boolean형 한가지 뿐이다. boolean형은 참 또는 거짓을 저장할 수 있는 데이터 타입으로, 오직 true 혹은 false를 값으로 가진다.
단순히 참과 거짓을 표현하기 위해서는 1bit만 있으면 되지만, JVM의 최소 데이터 단위가 1byte기 때문에 boolean형은 1byte(8bit)의 크기를 가진다.
boolean isRainy = true;
boolean isAdult = false;📌문자 타입
문자 타입은 2byte 크기의 char형 오직 하나만 있다.
문자형 리터럴을 작성할 때에는 반드시 큰 따옴표("")가 아닌 작은 따옴표('')를 사용해야 한다.
큰 따옴표를 사용한 리터럴은 문자형 리터럴이 아닌 문자열 리터럴로 인식되기 때문이다.
char letter1 = 'a';
char letter2 = 'ab'; // 에러 : 단 하나의 문자만 할당할 수 있습니다.
char letter3 = "a" // 에러 : 작은 따옴표를 사용해야 합니다. 문자 타입의 리터럴은 유니코드로 문자를 저장한다.
char letter = 65; System.out.print(letter); // 출력 결과 : A
📌타입 변환
변수를 선언할 때 타입을 명시해야한다. boolean을 제외한 기본 타입 7개는 서로 타입을 변환할 수 있으며, 자동으로 타입이 변환되는 경우도 있고, 수동으로 변환해주어야만 하는 경우도 있다.
📄 자동 타입 변환
- 바이트 크기가 작은 타입에서 큰 타입으로 변환할 때 (예 :
byte->int) - 덜 정밀한 타입에서 더 정밀한 타입으로 변환할 때 (예 :
정수->실수)
byte(1) -> short(2)/char(2) -> int(4) -> long(8) -> float(4) -> double(8)
위 순서도에서 float은 4byte인데 int와 long보다 더 뒤쪽에 있다. 이는 float이 표현할 수 있는 값이 모든 정수형보다 더 정밀하기 때문이다.
// float이 long보다 정밀하므로, 자동으로 타입이 변환된다. long longValue = 12345L; float floatValue = longValue; System.out.println(floatValue); // 12345.0이 출력된다.
📄 수동 타입 변환
차지하는 메모리 용량이 더 큰 타입에서 작은 타입으로는 자동으로 타입이 변환되지 않는다.
이 때 큰 데이터 타입을 작은 데이터 타입의 변수에 저장하기 위해서는 수동으로 타입을 변환해주어야만 한다. 이를 캐스팅(casting)이라고 한다.
수동으로 타입을 변환할 때에는 캐스팅 연산자 () 를 사용한다. 캐스팅 연산자의 괄호 안에 변환하고자 하는 타입을 적어주면 된다.
//int 타입으로 선언된 변수 intValue를 더 작은 단위인 byte로 변환한다.
int intValue = 128;
byte byteValue = (byte)intValue;
System.out.println(byteValue); // -128int형의 값 128을 byte형으로 캐스팅하여 byte형 변수 byteValue에 할당해주었다.
byte형의 표현 범위는 -128 ~ 127이므로, 128을 byte형으로 변환하면 오버플로우가 발생한다. 따라서 최종적으로 저장되는 값은 -128이 된다.
📌문자열
📄 String 타입의 변수 선언과 할당
기본적으로 String 타입은 큰 따옴표("")로 감싸진 문자열을 의미한다.
String 타입의 변수를 선언하고, 문자열 리터럴을 할당하는 방법은 다음과 같다.
// 문자열 리터럴을 String 타입의 변수 name에 할당하는 방법
String name1 = "Java Coding";
// String 클래스의 인스턴스를 생성하는 방법
String name2 = new String("Java Coding");여기서 클래스는 일종의 거푸집이며, 그 거푸집을 통해서 찍어낸 것이 인스턴스다.
그리고 클래스로 인스턴스를 찍어내고자 할 때 new연산자를 사용한다.
String name1 = "Java Coding";
String name2 = "Java Coding";
String name3 = new String("Java Coding");
String name4 = new String("Java Coding");
boolean comparison1 = name1 == "Java Coding"; // true
boolean comparison2 = name1 == name2; // true
boolean comparison3 = name1 == name3; // false
boolean comparison4 = name3 == name4; // false
boolean comparison5 = name1.equals("Java Coding"); // true
boolean comparison6 = name1.equals(name3); // true
boolean comparison7 = name3.equals(name4); // true여기서 equals() 메서드는 .앞의 변수가 저장하고 있는 문자열의 내용과 ()안의 문자열의 내용이 같은지 비교하여 같으면 true를, 다르면 false를 반환해준다.
name1과 name2는 문자열 리터럴을 String 타입의 변수에 직접 할당하는 방법을 사용하고 있다. 이처럼 동일한 문자열 리터럴을 두 변수에 할당하는 경우, 두 변수는 같은 문자열의 참조값을 공유한다. 즉, name1과 name2가 저장하게 되는 문자열의 주소값은 같다.
반면, name3과 name4는 String 클래스의 인스턴스를 생성하여 String 타입의 변수와 할당하는 방법을 사용하고 있다. 이처럼 String 클래스의 인스턴스를 생성하게 되면 문자열의 내용이 같을지라도, 별개의 인스턴스가 따로 생성된다. 따라서, name3과 name4가 할당받게 되는 인스턴스의 참조값은 서로 다르다. 즉, name3과 name4는 서로 다른 인스턴스의 주소값을 저장한다.
결론적으로 동일한 문자열 리터럴을 여러 변수에 할당하는 경우 문자열의 참조값을 공유하지만
인스턴스를 생성하여 저장하는 경우 내용이 같아도 별개의 인스턴스가 따로 생성된다.
📄 String 클래스의 메서드
charAt() 메서드
charAt()메서드는 해당 문자열의 특정 인덱스에 해당하는 문자를 반환한다.
만약 해당 문자열의 길이보다 큰 인덱스나 음수를 전달하면, 오류가 발생한다.String str = new String("Java"); System.out.println("문자열 : " + str); // "문자열 : Java" System.out.println(str.charAt(0)); // 'J' System.out.println(str.charAt(1)); // 'a' System.out.println(str.charAt(2)); // 'v' System.out.println(str.charAt(3)); // 'a' System.out.println("\ncharAt() 메서드 호출 후 문자열 : " + str);
compareTo() 메서드
compareTo()메서드는 해당 문자열을 인수로 전달된 문자열과 사전 편찬 순으로 비교한다.
이 메서드는 대소문자를 구분하여 비교한다. 만약 두 문자열이 같다면 0을 반환하고, 해당 문자열이 인수로 전달된 문자열보다 작으면 음수, 크면 양수를 반환한다.
문자열을 비교할 때 대소문자를 구분하지 않으려면,compareToIgnoreCase()메서드를 사용하면 된다.예제 String str = new String("abcd"); System.out.println("문자열 : " + str); System.out.println(str.compareTo("bcef")); System.out.println(str.compareTo("abcd") + "\n"); System.out.println(str.compareTo("Abcd")); System.out.println(str.compareToIgnoreCase("Abcd")); System.out.println("compareTo() 메서드 호출 후 문자열 : " + str);
concat() 메서드
concat()메서드는 해당 문자열의 뒤에 인수로 전달된 문자열을 추가한 새로운 문자열을 반환한다. 만약 인수로 전달된 문자열의 길이가 0이면, 해당 문자열을 그대로 반환한다.예제 String str = new String("Java"); System.out.println("문자열 : " + str); System.out.println(str.concat("블로그")); System.out.println("concat() 메서드 호출 후 문자열 : " + str);
indexOf() 메서드
indexOf()메서드는 해당 문자열에서 특정 문자나 문자열이 처음으로 등장하는 위치의 인덱스를 반환한다.
만약 해당 문자열에 전달된 문자나 문자열이 포함되어있지 않으면 -1을 반환한다.예제 String str = new String("Oracle Java"); System.out.println("문자열 : " + str); System.out.println(str.indexOf('o')); System.out.println(str.indexOf('a')); System.out.println(str.indexOf("Java")); System.out.println("indexOf() 메서드 호출 후 원본 문자열 : " + str);
trim() 메서드
trim()메서드는 해당 문자열의 맨 앞과 맨 뒤에 포함된 모든 공백 문자를 제거해준다.예제 String str = new String(" Java "); System.out.println("문자열 : " + str); System.out.println(str + '|'); System.out.println(str.trim() + '|'); System.out.println("trim() 메서드 호출 후 문자열 : " + str);
toLowerCase()와 toUpperCase() 메서드
toLowerCase()메서드는 해당 문자열의 모든 문자를 소문자로 변환시켜준다.
toUpperCase()메서드는 해당 문자열의 모든 문자를 대문자로 변환시켜준다.
StringTokenizer
StringTokenizer()는 문자열을 우리가 지정한 구분자로 문자열을 쪼개주는 클래스이다.
여기서 쪼개어진 문자열을 토큰(token)이라고 부른다.
StringTokenizer을 사용하기 위해서는java.util.StringTokenizer을 import해야한다.예제 import java.util.StringTokenizer; public class Main { public static void main(String[] args){ String str = "This is a string example using StringTokenizer"; StringTokenizer tokenizer = new StringTokenizer(str); System.out.println(str); System.out.println(); System.out.println("total tokens:"+tokenizer.countTokens()); while(tokenizer.hasMoreTokens()){ System.out.println(tokenizer.nextToken()); } System.out.println("total tokens:"+tokenizer.countTokens()); } }자주 사용하는 메서드
- int countTokens()
- 남아있는 token의 개수를 반환한다. 전체 token의 개수가 아닌 현재 남아있는 token의 개수이다.
- boolean hasMoreElements(), boolean hasMoreTokens()
- 두 메서드의 성능적인 차이는 없다. 둘 다 동일한 값을 반환한다. 문자열에서 하나 이상의 토큰을 사용할 수 있는 경우
true, 그렇지 않으면false를 반환한다.
- Object nextElement(), String nextToken()
- 이 두 메서드는 다음의 토큰을 반환한다. nextElement()는 Object를, nextToken은 String을 반환한다.
StringBuilder
한 번 생성된 String 클래스의 인스턴스는 여러 개의 문자열을 더할 때 매번 새로운 인스턴스를 생성해야한다.
그래서 비효율적인 문제를 해결하기 위해 StringBuilder를 사용한다.예제 public class Main { public static void main(String[] args) { StringBuilder stringBuilder = new StringBuilder(); stringBuilder.append("문자열 ").append("연결"); String str = stringBuilder.toString(); System.out.println(stringBuilder); System.out.println(str); } }먼저 StringBuilder의 객체를 생성한 후,
append()의 인자로 연결하고자하는 문자열을 넣어서 StringBuilder의 객체를 통해 호출한다.
또한 문자열을 출력할 때, 그리고 변수에 문자열을 할당할 때toString()메서드를 사용하면 된다.
StringBuffer
String 클래스의 인스턴스는 한 번 생성되면 그 값을 읽기만 할 수 있고, 변경할 수 없다.
하지만 StringBuffer 클래스의 인스턴스는 그 값을 변경할 수도 있고, 추가할 수도 있다.
이를 위해 StringBuffer 클래스는 내부적으로 버퍼(buffer)라고 하는 독립적은 공간을 가진다.
버퍼 크기의 기본 값은 16개의 문자를 저장할 수 있는 크기이다.
- append()
append()메서드는 인수로 전달된 값을 문자열로 변환한 후, 해당 문자열의 마지막에 추가한다.concat()메서드와 같은 결과를 반환하지만, 내부적인 처리 속도가 훨씬 빠르다.예제 StringBuffer str = new StringBuffer("Java"); System.out.println("문자열 : " + str); System.out.println(str.append(" programming")); System.out.println("append() 메서드 호출 후 문자열 : " + str);
- capacity()
capacity()메서드는 StringBuffer 인스턴스의 현재 버퍼 크기를 반환한다.
기본적인 str01의 크기는 16이고, str02는 문자의길이인 4를 더해 총 20개의 문자를 저장할 수 있는 버퍼가 생성된다.예제 StringBuffer str01 = new StringBuffer(); StringBuffer str02 = new StringBuffer("Java"); System.out.println(str01.capacity()); //16 System.out.println(str02.capacity()); //20
- delete()
delete()메서드는 전달된 인덱스에 해당하는 부분 문자열을 해당 문자열에서 제거한다.
deleteChatAt()메서드를 사용하면 특정 위치의 문자 한 개만 제거할 수도 있다.예제 StringBuffer str = new StringBuffer("Java Oracle"); System.out.println("문자열 : " + str); System.out.println(str.delete(4, 8)); System.out.println(str.deleteCharAt(1)); System.out.println("deleteCharAt() 메소드 호출 후 문자열 : " + str);
- insert()
insert()메서드는 인수로 전달된 값을 문자열로 변환한 후, 해당 문자열의 지정된 인덱스 위치에 추가한다.
이때 전달된 인덱스가 해당 문자열의 길이와 같으면,append()메서드와 같은 결과를 반환한다.예제 StringBuffer str = new StringBuffer("Java Programming!!"); System.out.println("문자열 : " + str); System.out.println(str.insert(4, "Script")); System.out.println("insert() 메서드 호출 후 문자열 : " + str);
