인덱스
Set은 food가 겹치지 않는다는 가정하에서 쓸 수 있다. 대부분의 경우 쓸 수 있는데, 푸드가 중복 가능성이 없는 경우에 쓸 수 있다. 언제나 쓸 수 있는 이유는 db 자체가 이미 중복이 안되기 때문이다. 우리가 잘못 만들면 중복이 될 수 있지만.. 관계대수란 것 자체가 set theory의 확장이다.
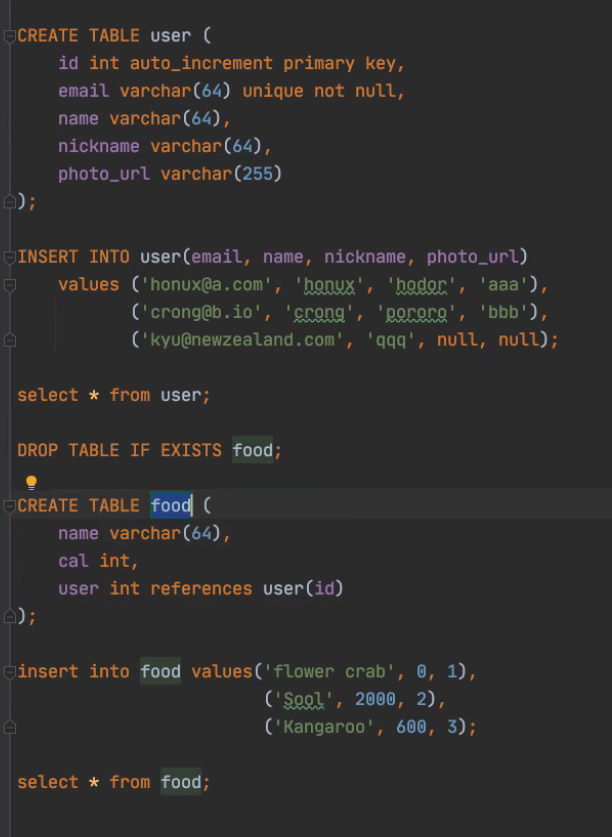
물리적으로 db가 테이블을 저장하는 방식을 무엇이라 했었나? pk는 비트리로 저장된다. 레코드는 pk 순서로 정렬되어 저장되어있다. pk 인덱스를 비+트리로 만들어 저장하는 것을 클러스터링 인덱스 자료구조라고 말한다.
비플러스 트리, 프라이머리 순서로 정렬되어 있고, 이걸 클러스터링 인덱스라고 한다. 관계형 db는 이러한 구조가 기본이다.
인덱스를 만드는 것이 인덱싱이고, 디폴트가 B+트리를 만드는 것이고, 다른 것도 가능하다. 인덱스를 만드는 것은 createIndex로 만드는 것이다. 푸드를 보니 푸드 이름으로 검색을 해야하는데, 칼럼에 대해 만든다.
CREATE INDEX food_idx on food(name);와 같이 인위적으로 인덱스를ㄹ 만들 수도 있다. count(*)할때 인덱스 사이즈로 바로 알 수 있다. O(log n) 이다.
복합인덱스란 것도 있따. create index food_idx on food(name, expiration_date); 네임 칼럼과 유통기한 을 합쳐서 인덱스를 만든다. 복합인덱스는 이 두개로 동시에 검색하고 싶을 떄 사용한다.
예를 들어, select * from food where name="마라탕" and expiration_date<="2021=05-21";이라고 하면, 마라탕이면서 유통기한이 해당 날짜보다 전인걸 찾고 싶은 의도일 것이다. 그런데 이렇게 쓰면 둘 중 인덱스가 하나만 선택되어 하나만으로 인덱스를 탈 수 있다. 둘 중 많이 걸러내는, 결과값이 적은 인덱스가 선택된다. 예를 들어 마라탕으로 10건 나오고, 유통기한으로 10만건 나오면, 마라탕을 선택해서 10개만 선택한다. 셀렉티비티는 selectivity, 쿼리 결과로 나오는게 몇퍼 필터링 되냐 문제이다. 셀렉티비티가 작을 수록 좋다. 레코드 결과가 적을수록 다음 쿼리 실행이 빠르기 떄문이다. 예를들면 성별의 셀렉티비티는 50%이므로, 여기 인덱스를 만들면 아무 의미 없다. 셀렉티비티가 높은(숫자로는 낮은) 아이템일수록 인덱스를 걸어야 효과가 있다. 셀렉티비티의 기준은 디스크립티브 밸류, 값에 따라 달라진다. 디비에선 카디널리티라고 한다. 디비는 내부적인 통계정보인 statistics를 갖고 있기에 마라탕 찾는 쿼리를 실행하기도 전에 개수를 알 수 있다. 좋은 디비는 이런데, mysql은 안 이렇다. 통계정보는 insert할 때 통계갱신하느라 늦어지는데, 주기적으로 갱신하면 된다. 앞의 자동, 수동갱신 모두 위험하다.
가장 저렴하게 트랜잭션을 만드는 방법은 디비를 만드는 것이다.
인덱스를 만들면 select 성능이 좋아지지만, insert할 시 인덱스를 갱신해야해서 insert 성능은 나빠진다. 비트리에 껴줘야한다.
쿼리를 살펴보니 where 에 user 검색있어서 food에 user int references user(id),가 있어야 검색이 된다.
user_key는 user가 food를 식별하는 대표키이다.
@MappedCollection(idColumn="your_column_name", keyColumn="your_key_column_name")
idColumn은 외래키, keyColumn은 name으로 해주면 된다. 이 애노테이션이 붙은 부분으느 키칼럼이 네임이 된다는 것이다. foods의 (map<String, Food> foods) 에다가 @MappedCollection으로 키칼럼을 name으로 지정하면, 우리가 원하는 특정 칼럼인 name을 키로 지정할 수 있따. O(n)에서 O(1)로 개선가능하다. (아무것도 안하면 user_key를 키칼럼으로 쓴다)
List, Set이 일반적이지만 key로 특정 밸류를 가져올 때, 맵을 쓴다.
List
git diff로 커밋 전에 변동사항 확인 가능하다.
unknown column ~ in field list -> ~란 칼럼을 추가하면 된다.
user_key는 array내에서 위치, 인덱스이다.
위 내용은 공식문서에서 확인 가능하다.
만약 user_key 값을 1, 500, 5000 식으로 지정하면, delete insert구조라서 가져올땐 저 인덱스만큼 생기고 중간엔 null 값 생기지않고, 삽입할 땐 다시 정리돼서 size가 3개로 된다. user_key값을 5000 이렇게 지정하면, 사이즈가 5000개 생기는게 아니며, user_key의 의미는 순서를 지정할 수 있는 장점이 있단 것이다. user_key는 리스트 위치를 직접 지정하는 게 아니라 순서비교를 위한 상대값이고, 0부터 올라간다. 크게 신경쓰지 말자.
테스트에 트랜잭션 지정해야 테스트 내용이 디비에 반영안된다.
도메인 무결성 조건??
스프링 data jdbc에선 N:1을 공식으로 지원하지 않는다. 예를 들어, User클래스 안에 user가 속한 group을 넣어도 안된다. (그룹 안에 N명의 user가 있다고 칠 때)
그룹에 외래키를 담을 수가 없다. 그룹안에 user_id int references user(id)로 한다고하면 1에 다수의 왜래키가 생기는 건데, 이럴 수 없다. 한 row에 여러 user가 들어가야하니까 안된다. 유저가 N이면 유저에 외래키 생기는건데,
JPA에서는 N:1, 1:N 다 된다. spring data jdbc에선 일부러 지원해주지 않는데, 엄격히 DDD를 지키기 우해서이다.
DD 컨셉 중에, N:1이란 관계가 있다면, 그룹이란 게 유저의 aggregate가 아니란 것이다. aggregate는 1:N 1:1만 aggregate이란 것이다. N:1관계는 같은 aggregate가 아니라, 그ㅡ럼 그룹은 다른 aggregate이어야한다는 주장이다. 즉 엄격하게 consistent할 필요가 없다. aggregate는 string consistency를 지켜야하는 데이터 집합이다. 배민 주문이라면 consistency 아주 필요하다. 주문과 재고사이에 strong consistency없다면, 주문한 후에 재고가 소진디었다는 메일이 온다.
aggregate로 묶는다면, strong consistency가 필요한 경우이다. 그룹을 어그리게잇 루트로 하고 유저를 포함시키면 개발자가 그룹과 유저 사이의 데이터 일관성이 즁요하다고 생각한것이다. 이런 생각으로 많은 연구를 한 결과, N:1은 aggregate으로 묶는 경우가 발생하지 않는다고 이들이 생각한 것이다. 유저를 루트로 묶었다면 이 그룹은 N:1관계이고, 이 그룹은 스토롱 일관성이 필요하지 않은 관계이다.만약 스트롱 ~가 필요했다면 그룹이 루트가 됐을 것이고, 1:N관계를 만들었을 것이다.
묶으면 묶을 수록 많이 복잡해진다. 쪼갤 수록 접근하기 편해진다.
강력하게 일관성을 지키려고 연관관계인 애들을 DELETE INSERT 하는 것이고, 상태를 모르기 떄문이기도 하다. 이전상태를 알고 있다면 바뀐 부분만 업데이트할면 되는데, 모르기 때문에 다 지우고 다시 insert하는 것이다. 데이터 일관성 vs 성능의 tradeoff관계?가 있는 것이다.
Repository가 interface인 이유는, 구현체는 프레임워크가 만들어주기 때문이다.
예약어로 사용할 때엔 백틱으로 감싸주기?
user클래스에 groupid추가해주고, 스키마에는 group id를 포린키로 넣어줘야한다. user에 group을 바로 넣을 수 없다. groupid를 통해서 N:1관계는 서로 다른 어그리게이트에 속할 가능성이 높기 때문이다.
user가져올때 food fruit은 같은 aggregate이라 한번에 가져와 주는데, grouop은 user와 다른 aggregate라 한번에 가져오지 않는다. strong consistency가 필요없을 경우, N:1을 써야한다면 이렇게 위와 설명한 방법으로.
M:N
별도의 테이블을 만든다. 직원-프로젝트를 엮는 works_on 테이블을 하나 만든다. 그러면 M명의 직원이N개의 프로젝트에 참여한다고 하면, 둘을 엮어주기 위한 테이블을 별도생성한다.
1:N과 N:1을 묶는데, 방향이 중요하기 때문이다. 직원이 플젝테 참여하는 것이다.
Emp안에 Set\<works_on> worksOn;으로 만들고, worksOn클래스에 Long projectId(M:1관계)를 넣는다. (worksOn에 자기 속성으로 hour도 가짐)
복합키 : primary key(id, project_id) 와 같이 함.
 한번에 여러개 넣기 가능
한번에 여러개 넣기 가능
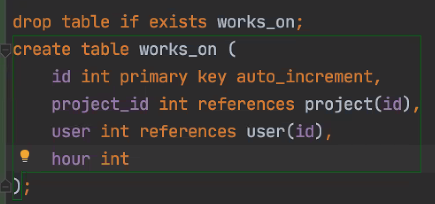
works_on이 user에 set으로 들어가있기 때문에 스키마에서 user로 들어가야한다.
