-
탐캣은 was지 웹서버가 아니라서 정적 페이지 캐싱 등 많은 ~를 담당할 준비가 되어있다. 탐캣만으로 서비스를 돌릴 수 없고, 앞단에는 엔진엑스, 아파치 같은 것을 붙여놔야한다. 웹이 엔진X이다.
-
log level: 디버그로 해두면 잘 보인다.
logging.level.net.honux=DEBUG
logging.level.sql=DEBUG -
스프링 데이터 세팅을
spring.datasource.url=jdbc:mysql://localhost:3306/tigerdb?serverTimezone이런 식으로 소스를 세팅한다.
spring.datasource.username=scott
spring.datasource.password=tiger -
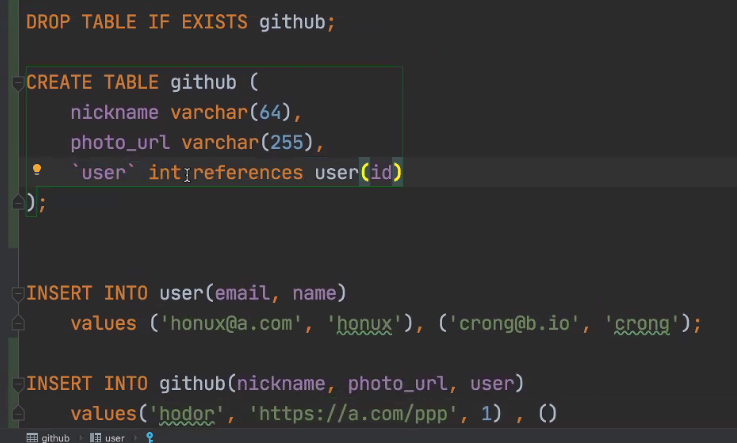
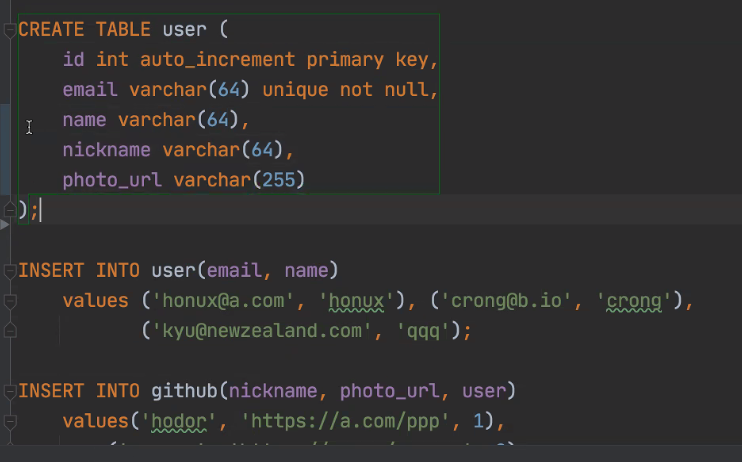
JPA와 달리 테이블 직접 만들어줘야한다. .sql에
CREATE TABLE IF NOT EXITS USER {
ID INT AUTO_INCREMENT PRIMARY KEY,
EMAIL VARCHAR(64)UNIQUE
}
INSERT INTO user(email)
대소문자 구분 잘해야한다. JDBC에선 기본 네이밍 strategy를 따라야한다.
- logger.info("User ID 1: {}" , user);하면 {}안에 user 인포가 다 넣어져서 출력된다.
- repository 에 findUserBy~~ 로 적어주면 자동으로 찾아준다. 이것을 derived queries라고 한다. 옛날에는 @Query로 쿼리문 다 직접 작성해서 찾아와야했다. 로그 확인하면(loggingLevel설정) JDBC에서 대신 작성해준 쿼리문이 실제로 어떤지 확인할 수 있다.
- 복잡한 조인이 들어가면 findBy~ 안된다. Query derivation is limitied to properties that can be used in a WHERE clause without using joins. where 절에 join이 들어가면 안된다. 만약 안된다면, @Query로 직접 써주면 된다.
- 쿼리는 한번에 한쿼리만 가능하다.
- 실서버가 mySql이면 로컬, 테스트서버도 mySql로 하자.. JPA이론상으론 mySql, h2 호환성이 가능하지만 실제론 그렇지 않다. mySql 모드로 하면 괜찮을 수 있다. 쿼리 변환해서 인식해주는 모드가 있다. 테스트할 땐 로컬 mySql로 하고, 서버로 하면 안된다. 테스트 클래스에 @Transactional달면 실행 후 취소한다.
- DDD 철학으로 인해, N:1, M:N 등을 지원해주지 않는다. 단방향 1:N 만 쓸 수 있다.
- jpa N+1 창천향 아저씨? page query에서 n+1성능 개선하기 검색해보기
- pk참조는 index로..
Jpa 1:N 문제점: - GitHub하면 GIT_HUB로 인식하는 문제가 있다. 커스텀 네이밍하면 되긴하는데, GITHUB로 하고 싶으면 Github로 소문자 h써라.
1:1
- User가 Github을 갖는 1대1관계이다. DB설계를 했으면 아마도 테이블 하나로 만들었을 것이다. 1대1 join이 필요하기 때문이다. 근데 우리는 ORM을 쓰니까 User Github가 1대1 매핑이 된다.
- left outer join: github이 없어도 user나오도록한다.
- @Embedded.Nullable : ORM에선 객체로 인식하는데, 객체는 두개지만 테이블은 하나이다. github이 속성들이 테이블 안으로 편입된다. 테이블 스키마가가 변화하는데, nickname varchar(64)와 같이 user안에 들어가는 듯? user 테이블의 id, email은 user것이고, nickname은 github것이다. 필드 네임으로 (nickname) 매칭을 해서 @Embedded된 github에 편입해준다.
- 칼럼 이름 잘 지어주면 알아서 넣어준다.
- 결론: 1대1일 때 @Embedded를 써준다.
1:N
Set
- 1:N은 JDBC에선 Set이 가장 쉽다. User Game이 1:N이고, 한 User은 여러개의 게임을 할 수 있다. User클래스 안에
private Set<Game> games = new HashSet();갖고, 각종 addGame 등 메소드를 User안에 갖는다. - game(N)쪽에 user(1)을 fk로 갖는다.
- Set은 한꺼번에 몽땅 다 가져온다는 의미를 내포한다. USer을 가져오면 유저가 좋아하는 게임목록을 한꺼번에 셋으로 취급하겠다는 것이다. 유저가 했던 게임중에 몬헌이 있니? 식으로 보지않겠다. 한꺼번에 가져오고나서, 그러고 나서야 생각하겠다는 것이다. 그렇지 않을 경우에 맵, 리스트를 쓸 수도 있다.
Map
- Map은 key value가 필요하다. 테이블에
부모테이블이름_key 적당한 타입칼럼을 만들어줘야한다.
Map<String, Game> gamesaddGame(String title){gaems.put(title, newGame(title));}한 타이틀만 가져오고 싶다면, 내가 지정한 게임만 가져오도록 이렇게 한다. 일반적인 맵이었다면, 많은 게임 중 타이틀값이 key였을 것이므로. 쿼리보다는 프로그램에서 로지글 처리하는게 성능상 좋다는 ㅓㄳ이고, 쿼리 자체의 성능도 좋아질 수 있다. user와 game은 다른 aggregate일 수도 있지만, 둘이 같은 aggregate이고, root가 user란 가정 하에는, 이와 같이 map으로 가능하다.
title을 이용해 game 오브젝트를 가져오는 것이 자연스럽다. 게임이 서너개이고, 몬헌 백개샀다고 하면, 리스트로 관리할 것이다. 중복허용하면 set이고, 중복허용안되지만 key로 검색하겠다하면 map으로 한다.
- 우리가 원하는 key를 설정가능하므로 이걸 참조하는 칼럼을 만들어줘야한다.
List :
- schema.sql 에 user_key int 가 들어간다. 아까는 이것을 우리 마음대로 지정하지만, 여기선 user pk타입이 그대로 들어간다. 클래스 안에
List<Game> games넣어주고, 스키마에도 user_key(user 테이블의 key) 넣어줘야 제대로 작동한다. 외래키가 이미 있는데도.
210420 복습
-
repository 여러 개 만드는 아키텍쳐 고민
-
엔진엑스 cdm에 넣기
-
테이블 자동생성해주지 않는다. 당연히 테이블은 .sql로 만든다. erd만드는 이유가 테이블 자동으로 만들기 위한 이유다. dialect세팅하고 datasouce 세팅해서
-
로그레벨 디버그로 설정해줘서 쿼리가 보인다.
-
findAll()은 디비에서 풀스캔이라고 한다. 디비 전체를 뒤진다.
-
userRepository.count()메서드로 사이즈 알 수 있다. 디비로 가면 select count(*) from user 이 된다.
-
데이터가 있고 데이터 검색을 위해 인덱스를 만든다. 인덱스는 데이터보다 크기가 작다. 데이타가 1기가면 인덱스는 10메가정도뿐이다.
-
explain 으로 쿼리 플랜을 볼 수 있다. explain select count(*) from user;를 실행하면
 와 같이 나온다.
와 같이 나온다.
email은 unique이므로 이걸 확인하기 위해 , id는 primary key이기 때문에 인덱스가 두개이다. explain select * from user; 과는 다르다. -
sql.debug로 설정 꼭 해주기.
-
repository에 save하더라도 새로운 user이면 INSERT, 기존 user 수정된 젖ㅇ보이면 UPDATE로 쿼리가 바뀐다.
-
mysql 예약어를 써서 안될땐 백틱 `으로 감싸주면 된다.
-
-
aggregate root 를 통해 access할때 루트를 통해 전부 갖고 옴. 성능이 조금 떨어질 수 있지만, 무시할만하다.
-
left outer join하는 경우: 종속관계에 있는 애가 null 이 될 수 있기 때문에.
1대1
- erd에서 1대1이면 github의 속성들을 user에 넣을수도 있다. embedded 애노테이션을 넣고 생성자에 추가하면 된다(?)

- 근데 깃헙 관련이 전부 null이면 user의 Github 객체가 null이 되나요? 아니면 값이 null인 Github가 되나요? -> github.isNull() 이 true인 것이랑, github.getName().isNull()인것이 다르다.
1대N
- 유저가 여러 개 가져갈 수 있는 객체로, Food를 만들고.
- jpa에서는 list가 제일 쉬운데, jdbc에서 제일 쉬운 것은 set이다.
- jpa엔 lazy Loading, session이 있다. 있던 것 다 삭제하고 insert하니까 개수가 유지된다. 100만건에 1건 추가하면 100만건삭제하고 100만1건 추가한다. 실제로는 이렇게하지 않는다. 이런게 문제되는 일이 잘 생기지 않는다. jpa 복잡함으로 인한 sideeffect때문에 이것을 선호하는 분들도 실제로 계신다. 그렇기 때문에 aggregate root잘써야한다. user에 게시글 달아주면 헤비유저가 만개 글에 하나 추가하면 만개 삭제하고 다시 한다..
